Beskrivning
Föreställ dig en livlig flygplats med flyg som startar och landar varje minut. Precis som flygledare prioriterar flygningar baserat på brådskande, hjälper heaps oss att hantera och bearbeta data baserat på specifika kriterier, vilket säkerställer att den mest "brådskande" eller "viktiga" databiten alltid är tillgänglig överst.
I den här guiden ger vi oss ut på en resa för att förstå högar från grunden. Vi börjar med att avmystifiera vad heaps är och deras inneboende egenskaper. Därifrån kommer vi att dyka in i Pythons egen implementering av heaps, den
heapqmodul och utforska dess rika uppsättning funktioner. Så om du någonsin har undrat hur man effektivt hanterar en dynamisk uppsättning data där det högsta (eller lägsta) prioriterade elementet ofta behövs, har du en upplevelse.
Vad är en heap?
Det första du vill förstå innan du dyker in i användningen av heaps är vad är en hög. En hög sticker ut i en värld av datastrukturer som ett trädbaserat kraftpaket, särskilt skickligt på upprätthålla ordning och hierarki. Även om det kan likna ett binärt träd för det otränade ögat, skiljer nyanserna i dess struktur och styrande regler det tydligt åt.
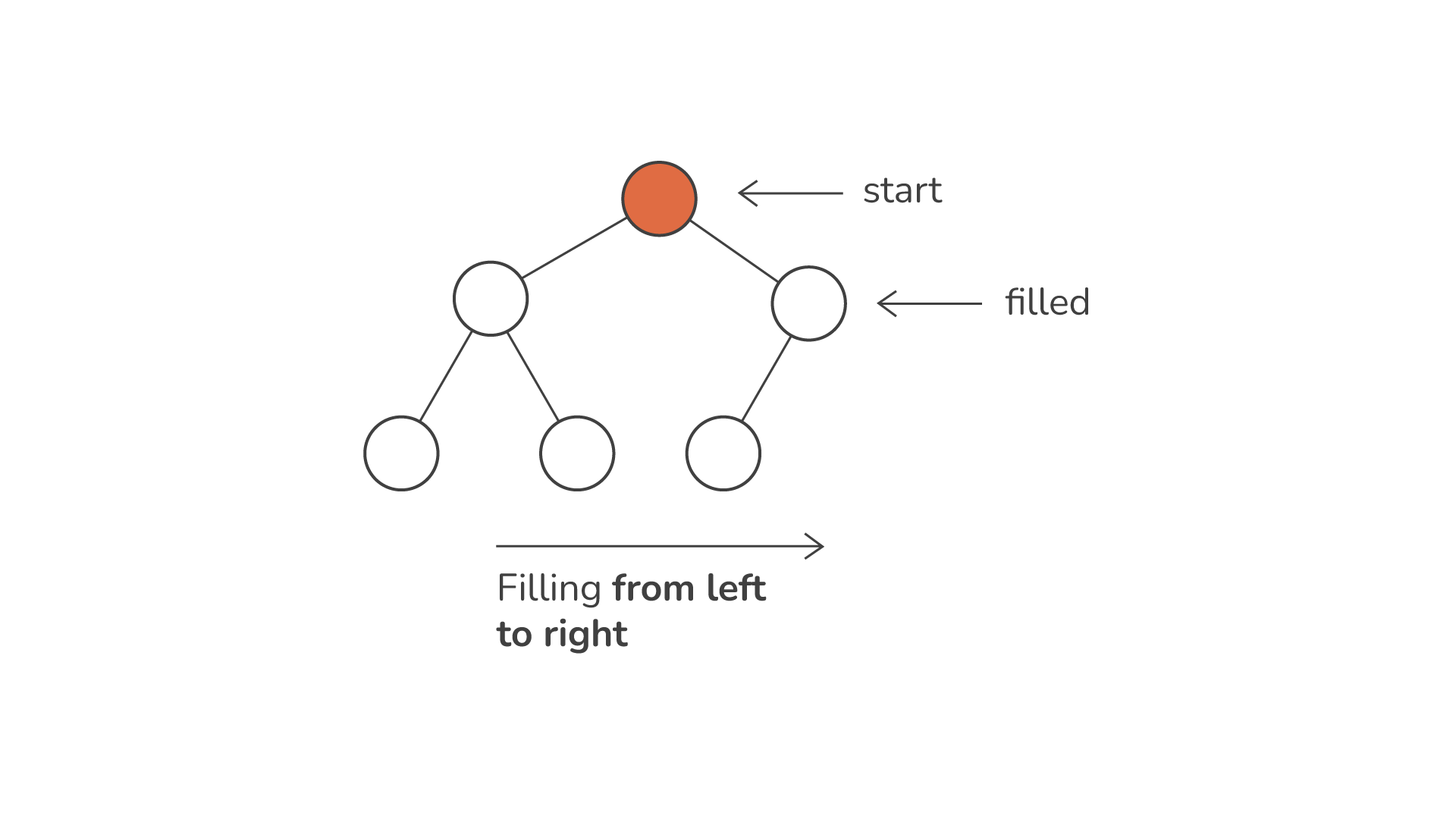
En av de definierande egenskaperna hos en hög är dess natur som en komplett binärt träd. Det betyder att varje nivå i trädet, utom kanske den sista, är helt fylld. Inom denna sista nivå fylls noder från vänster till höger. En sådan struktur säkerställer att högar effektivt kan representeras och manipuleras med hjälp av arrayer eller listor, där varje elements position i arrayen speglar dess placering i trädet.
Den sanna essensen av en hög ligger dock i dess beställning. I en max hög, varje given nods värde överstiger eller är lika med värdena för dess underordnade, vilket placerar det största elementet precis vid roten. Å andra sidan, a min hög fungerar enligt den motsatta principen: någon nods värde är antingen mindre än eller lika med dess barns värden, vilket säkerställer att det minsta elementet sitter vid roten.
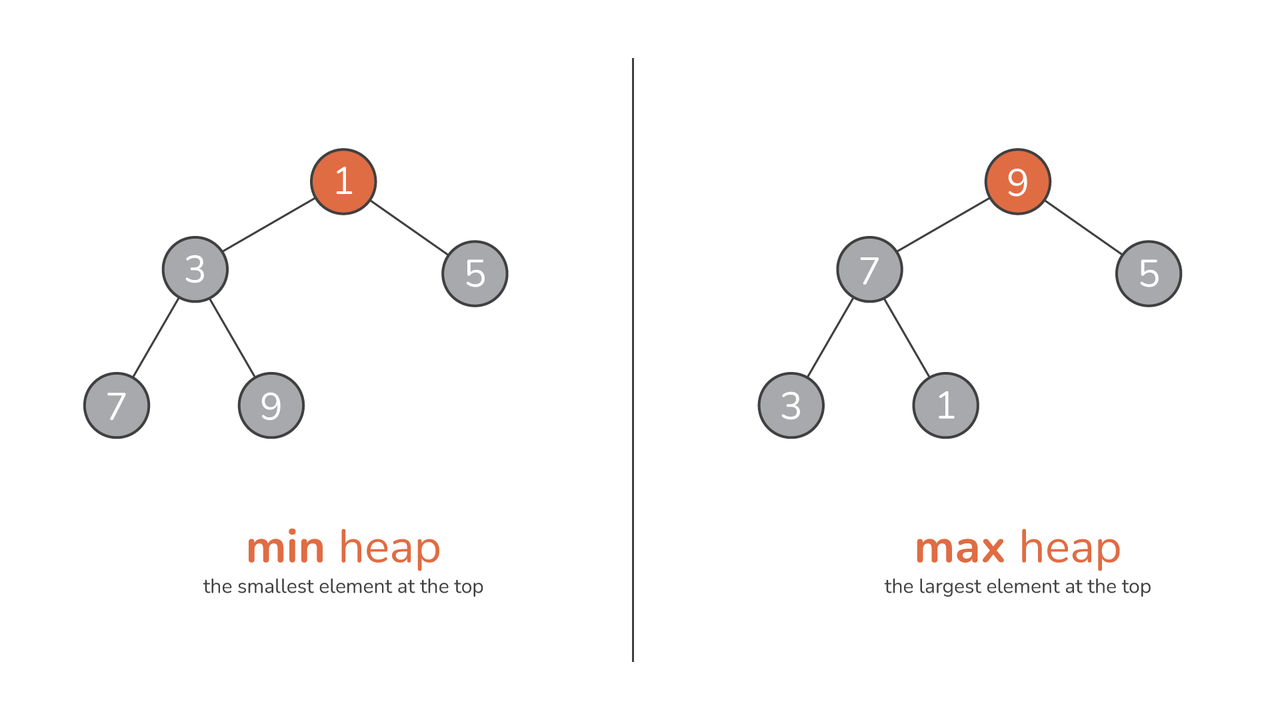
Råd: Du kan visualisera en hög som en pyramid av siffror. För en maxhög, när du stiger från basen till toppen, ökar siffrorna, vilket kulminerar i det maximala värdet på toppen. Däremot börjar en min-hög med minimivärdet på sin topp, med siffror som eskalerar när du rör dig nedåt.
När vi går framåt kommer vi att dyka djupare in i hur dessa inneboende egenskaper hos högar möjliggör effektiva operationer och hur Pythons heapq modulen integrerar sömlöst högar i våra kodningssträvanden.
Karakteristika och egenskaper hos högar
Heaps, med sin unika struktur och ordningsprinciper, tar fram en uppsättning distinkta egenskaper och egenskaper som gör dem ovärderliga i olika beräkningsscenarier.
Först och främst är högar i sig effektiv. Deras trädbaserade struktur, närmare bestämt det kompletta binära trädformatet, säkerställer att operationer som infogning och extrahering av prioritetselement (maximal eller minimum) kan utföras i logaritmisk tid, vanligtvis O (log n). Denna effektivitet är en välsignelse för algoritmer och applikationer som kräver frekvent tillgång till prioriterade element.
En annan anmärkningsvärd egenskap hos heaps är deras minneseffektivitet. Eftersom högar kan representeras med hjälp av arrayer eller listor utan behov av explicita pekare till underordnade eller överordnade noder, är de utrymmesbesparande. Varje elements position i arrayen motsvarar dess placering i trädet, vilket möjliggör förutsägbar och okomplicerad övergång och manipulation.
Beställningsegenskapen för heaps, oavsett om det är en max-hög eller en min-hög, säkerställer detta roten har alltid elementet med högsta prioritet. Denna konsekventa ordning är det som möjliggör snabb åtkomst till det högsta prioriterade elementet utan att behöva söka igenom hela strukturen.
Dessutom är högar mångsidig. Medan binära heaps (där varje förälder har högst två barn) är de vanligaste, kan heaps generaliseras till att ha mer än två barn, kända som d-ary högar. Denna flexibilitet möjliggör finjustering baserat på specifika användningsfall och prestandakrav.
Slutligen är högar självjusterande. Närhelst element läggs till eller tas bort, arrangerar strukturen sig själv för att behålla sina egenskaper. Denna dynamiska balansering säkerställer att högen förblir optimerad för dess kärnverksamhet hela tiden.
Råd: Dessa egenskaper gjorde att högdatastrukturen passade bra för en effektiv sorteringsalgoritm – högsortering. För att lära dig mer om heapsortering i Python, läs vår "Högsortering i Python" artikel.
När vi går djupare in i Pythons implementering och praktiska tillämpningar kommer den sanna potentialen hos heaps att vecklas ut inför oss.
Typer av högar
Alla högar är inte skapade lika. Beroende på deras beställning och strukturella egenskaper kan högar kategoriseras i olika typer, var och en med sin egen uppsättning applikationer och fördelar. De två huvudkategorierna är max hög och min hög.
Den mest utmärkande egenskapen hos en max hög är att värdet på en given nod är större än eller lika med värdena för dess underordnade. Detta säkerställer att det största elementet i högen alltid finns vid roten. En sådan struktur är särskilt användbar när det finns ett behov av att ofta komma åt maxelementet, som i vissa implementeringar av prioriterade köer.
Motsvarigheten till maxhögen, en min hög säkerställer att värdet på en given nod är mindre än eller lika med värdena för dess underordnade. Detta placerar den minsta delen av högen vid roten. Minsta högar är ovärderliga i scenarier där det minsta elementet är av största vikt, som i algoritmer som hanterar databehandling i realtid.
Utöver dessa primära kategorier kan högar också särskiljas baserat på deras förgreningsfaktor:
Medan binära högar är vanligast, där varje förälder har högst två barn, kan begreppet heap utvidgas till noder som har fler än två barn. I en d-ary hög, varje nod har högst d barn. Denna variation kan optimeras för specifika scenarier, som att minska höjden på trädet för att påskynda vissa operationer.
Binomial Heap är en uppsättning binomialträd som definieras rekursivt. Binomialhögar används i implementeringar av prioriterade köer och erbjuder effektiva sammanslagningsoperationer.
Uppkallad efter den berömda Fibonacci-sekvensen Fibonacci-hög erbjuder bättre amorterade körtider för många operationer jämfört med binära eller binomala högar. De är särskilt användbara i nätverksoptimeringsalgoritmer.
Pythons Heap-implementering – The heapq Modulerna
Python erbjuder en inbyggd modul för heap-operationer – den heapq modul. Den här modulen tillhandahåller en samling av heap-relaterade funktioner som gör att utvecklare kan omvandla listor till heaps och utföra olika heap-operationer utan behov av en anpassad implementering. Låt oss dyka in i nyanserna i den här modulen och hur den ger dig kraften i högar.
Smakämnen heapq modulen tillhandahåller inte en distinkt högdatatyp. Istället erbjuder den funktioner som fungerar på vanliga Python-listor, transformerar och behandlar dem som binära högar.
Detta tillvägagångssätt är både minneseffektivt och integreras sömlöst med Pythons befintliga datastrukturer.
Det betyder att högar representeras som listor in heapq. Det fina med denna representation är dess enkelhet – det nollbaserade listindexsystemet fungerar som ett implicit binärt träd. För varje givet element vid position i, det är:
- Vänster barn är på plats
2*i + 1 - Höger barn är på plats
2*i + 2 - Föräldernoden är på plats
(i-1)//2
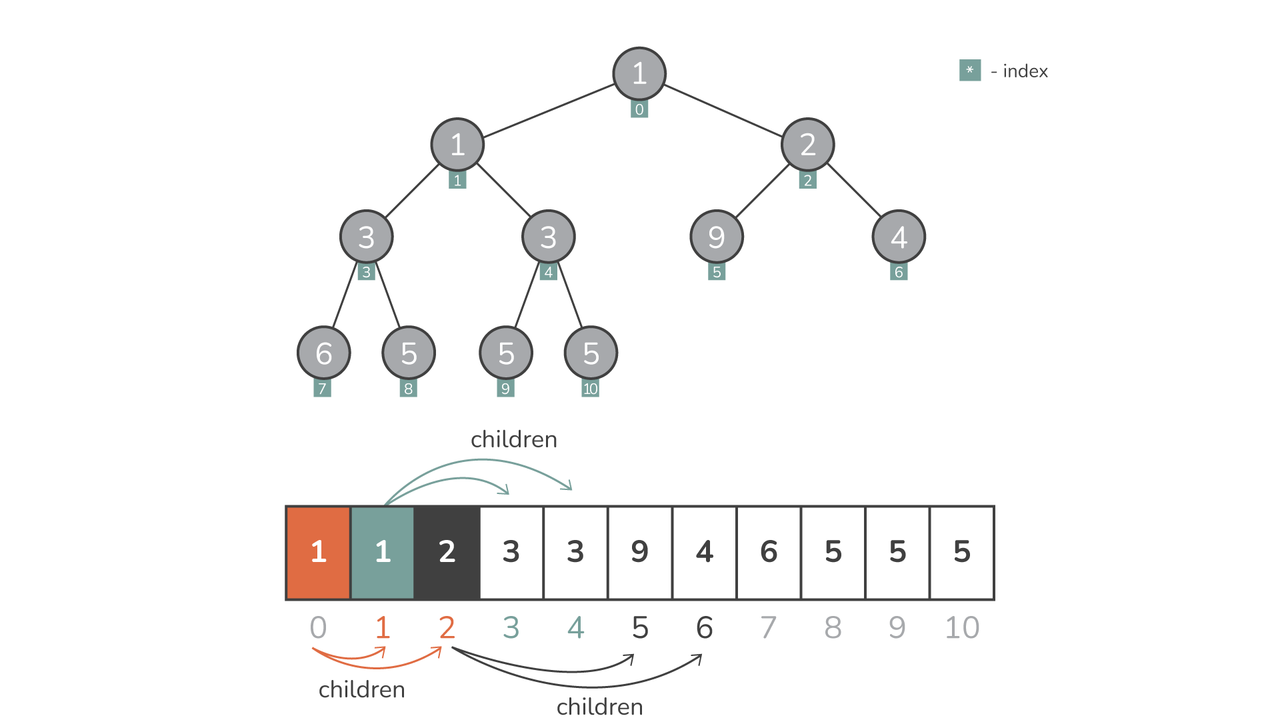
Denna implicita struktur säkerställer att det inte finns något behov av en separat nodbaserad binär trädrepresentation, vilket gör operationerna enkla och minnesanvändningen minimal.
Rymdkomplexitet: Högar implementeras vanligtvis som binära träd men kräver inte lagring av explicita pekare för underordnade noder. Detta gör dem utrymmeseffektiva med en utrymmeskomplexitet på O (n) för lagring av n element.
Det är viktigt att notera att heapq modul skapar min heaps som standard. Det betyder att det minsta elementet alltid är vid roten (eller den första positionen i listan). Om du behöver en maxhög, måste du invertera ordningen genom att multiplicera element med -1 eller använd en anpassad jämförelsefunktion.
Pythons heapq modulen tillhandahåller en uppsättning funktioner som gör det möjligt för utvecklare att utföra olika heap-operationer på listor.
Notera: Att använda heapq modul i din applikation, måste du importera den med enkel import heapq.
I följande avsnitt kommer vi att dyka djupt in i var och en av dessa grundläggande operationer och utforska deras mekanik och användningsfall.
Hur man förvandlar en lista till en hög
Smakämnen heapify() funktion är utgångspunkten för många heap-relaterade uppgifter. Det tar en iterabel (vanligtvis en lista) och ordnar om dess element på plats för att tillfredsställa egenskaperna hos en min hög:
Kolla in vår praktiska, praktiska guide för att lära dig Git, med bästa praxis, branschaccepterade standarder och medföljande fuskblad. Sluta googla Git-kommandon och faktiskt lära Det!
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
heapq.heapify(data)
print(data)
Detta kommer att mata ut en omordnad lista som representerar en giltig minhög:
[1, 1, 2, 3, 3, 9, 4, 6, 5, 5, 5]
Tidskomplexitet: Konvertera en oordnad lista till en hög med hjälp av heapify funktion är en O (n) drift. Detta kan verka kontraintuitivt, som man kan förvänta sig att det är O (nlogn), men på grund av trädstrukturens egenskaper kan det uppnås i linjär tid.
Hur man lägger till ett element i högen
Smakämnen heappush() funktionen låter dig infoga ett nytt element i högen samtidigt som högens egenskaper bibehålls:
import heapq heap = []
heapq.heappush(heap, 5)
heapq.heappush(heap, 3)
heapq.heappush(heap, 7)
print(heap)
Genom att köra koden får du en lista över element som upprätthåller min heap-egenskapen:
[3, 5, 7]
Tidskomplexitet: Insättningsoperationen i en hög, som innebär att ett nytt element placeras i högen samtidigt som högegenskapen bibehålls, har en tidskomplexitet på O (logn). Detta beror på att elementet i värsta fall kan behöva resa från bladet till roten.
Hur man tar bort och returnerar det minsta elementet från högen
Smakämnen heappop() funktion extraherar och returnerar det minsta elementet från högen (roten i en min hög). Efter borttagning säkerställer det att listan förblir en giltig hög:
import heapq heap = [1, 3, 5, 7, 9]
print(heapq.heappop(heap))
print(heap)
Notera: Smakämnen heappop() är ovärderlig i algoritmer som kräver bearbetningselement i stigande ordning, som Heap Sort-algoritmen, eller vid implementering av prioriterade köer där uppgifter exekveras baserat på deras brådska.
Detta kommer att mata ut det minsta elementet och den återstående listan:
1
[3, 7, 5, 9]
Här, 1 är det minsta elementet från heap, och den återstående listan har bibehållit heap-egenskapen, även efter att vi tog bort 1.
Tidskomplexitet: Att ta bort rotelementet (som är det minsta i en minhög eller störst i en maxhög) och omorganisera högen tar också O (logn) tid.
Hur man trycker på ett nytt föremål och poppar det minsta föremålet
Smakämnen heappushpop() funktion är en kombinerad operation som skjuter in ett nytt föremål på högen och sedan poppar upp och returnerar det minsta föremålet från högen:
import heapq heap = [3, 5, 7, 9]
print(heapq.heappushpop(heap, 4)) print(heap)
Detta kommer att matas ut 3, det minsta elementet, och skriv ut det nya heap lista som nu omfattar 4 samtidigt som högegenskapen bibehålls:
3
[4, 5, 7, 9]
Notera: Använda heappushpop() funktionen är effektivare än att utföra operationer med att trycka ett nytt element och poppa det minsta separat.
Hur man byter ut det minsta föremålet och trycker på ett nytt föremål
Smakämnen heapreplace() funktionen öppnar det minsta elementet och trycker ett nytt element på högen, allt i en effektiv operation:
import heapq heap = [1, 5, 7, 9]
print(heapq.heapreplace(heap, 4))
print(heap)
Detta trycker 1, det minsta elementet, och listan innehåller nu 4 och bibehåller heap-egenskapen:
1
[4, 5, 7, 9]
Anmärkningar: heapreplace() är fördelaktigt i streaming-scenarier där du vill ersätta det nuvarande minsta elementet med ett nytt värde, till exempel vid rullande fönsteroperationer eller databearbetningsuppgifter i realtid.
Hitta flera ytterligheter i Python's Heap
nlargest(n, iterable[, key]) och nsmallest(n, iterable[, key]) funktioner är designade för att hämta flera största eller minsta element från en iterabel. De kan vara effektivare än att sortera hela iterablen när du bara behöver några få extrema värden. Säg till exempel att du har följande lista och du vill hitta tre minsta och tre största värden i listan:
data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
Här, nlargest() och nsmallest() funktioner kan komma till användning:
import heapq data = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print(heapq.nlargest(3, data)) print(heapq.nsmallest(3, data)) Detta kommer att ge dig två listor – en innehåller de tre största värdena och den andra innehåller de tre minsta värdena från data lista:
[9, 6, 5]
[1, 1, 2]
Hur du bygger din anpassade hög
Medan Python är heapq modulen ger en robust uppsättning verktyg för att arbeta med heaps, det finns scenarier där standard min heap-beteende kanske inte räcker. Oavsett om du vill implementera en maxhög eller behöver en hög som fungerar baserat på anpassade jämförelsefunktioner, kan att bygga en anpassad hög vara svaret. Låt oss utforska hur man skräddarsyr högar efter specifika behov.
Implementera en Max Heap med hjälp av heapq
Som standard heapq skapar min högar. Men med ett enkelt knep kan du använda det för att implementera en maxhög. Tanken är att invertera ordningen på element genom att multiplicera dem med -1 innan du lägger till dem i högen:
import heapq class MaxHeap: def __init__(self): self.heap = [] def push(self, val): heapq.heappush(self.heap, -val) def pop(self): return -heapq.heappop(self.heap) def peek(self): return -self.heap[0]
Med detta tillvägagångssätt blir det största antalet (i termer av absolut värde) det minsta, vilket tillåter heapq fungerar för att upprätthålla en maxhögstruktur.
Massor med anpassade jämförelsefunktioner
Ibland kan du behöva en hög som inte bara jämförs baserat på den naturliga ordningen av element. Om du till exempel arbetar med komplexa objekt eller har specifika sorteringskriterier, blir en anpassad jämförelsefunktion viktig.
För att uppnå detta kan du slå in element i en hjälpklass som åsidosätter jämförelseoperatorerna:
import heapq class CustomElement: def __init__(self, obj, comparator): self.obj = obj self.comparator = comparator def __lt__(self, other): return self.comparator(self.obj, other.obj) def custom_heappush(heap, obj, comparator=lambda x, y: x < y): heapq.heappush(heap, CustomElement(obj, comparator)) def custom_heappop(heap): return heapq.heappop(heap).obj
Med den här inställningen kan du definiera vilken anpassad komparatorfunktion som helst och använda den med heapen.
Slutsats
Heaps erbjuder förutsägbar prestanda för många operationer, vilket gör dem till ett pålitligt val för prioriterade uppgifter. Det är dock viktigt att ta hänsyn till de specifika kraven och egenskaperna hos den aktuella applikationen. I vissa fall kan justering av högens implementering eller till och med välja alternativa datastrukturer ge bättre verkliga prestanda.
Högar, som vi har gått igenom, är mer än bara en annan datastruktur. De representerar ett sammanflöde av effektivitet, struktur och anpassningsförmåga. Från deras grundläggande egenskaper till deras implementering i Pythons heapq modul erbjuder heaps en robust lösning på en myriad av beräkningsutmaningar, särskilt de som är centrerade kring prioritet.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://stackabuse.com/guide-to-heaps-in-python/

