I den här artikeln kommer vi att lära oss hur du distribuerar och använder GPT4All-modellen på din dator med endast CPU (Jag använder en Macbook Pro utan GPU!)

Använd GPT4All på din dator — Bild av författaren
I den här artikeln kommer vi att installera på vår lokala dator GPT4All (en kraftfull LLM) och vi kommer att upptäcka hur man interagerar med våra dokument med python. En samling PDF-filer eller onlineartiklar kommer att utgöra kunskapsbasen för våra frågor/svar.
Från officiella webbplats GPT4All det beskrivs som en gratis att använda, lokalt kör, integritetsmedveten chatbot. Ingen GPU eller internet krävs.
GTP4All är ett ekosystem att träna och distribuera den mäktigaste och kundanpassad stora språkmodeller som körs lokalt på konsumentklassade processorer.
Vår GPT4All-modell är en 4GB-fil som du kan ladda ner och koppla in i GPT4Alls ekosystemprogramvara med öppen källkod. Nomisk AI underlättar högkvalitativa och säkra mjukvaruekosystem, driver ansträngningarna att göra det möjligt för individer och organisationer att utan ansträngning träna och implementera sina egna stora språkmodeller lokalt.
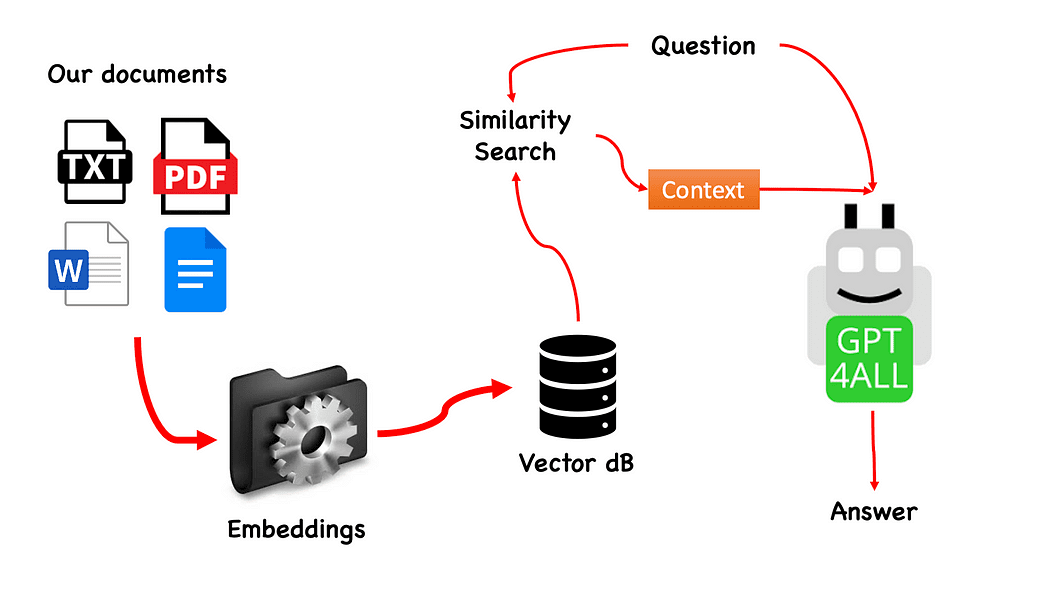
Arbetsflöde för QnA med GPT4All — skapat av författaren
Processen är väldigt enkel (när du vet det) och kan upprepas med andra modeller också. Stegen är som följer:
- ladda GPT4All-modellen
- användning Långkedja för att hämta våra dokument och ladda dem
- dela upp dokumenten i små bitar som kan smältas av Embeddings
- Använd FAISS för att skapa vår vektordatabas med inbäddningarna
- Utför en likhetssökning (semantisk sökning) på vår vektordatabas baserat på frågan vi vill skicka till GPT4All: detta kommer att användas som en sammanhang för vår fråga
- Mata frågan och sammanhanget till GPT4All med Långkedja och vänta på svaret.
Så vad vi behöver är inbäddningar. En inbäddning är en numerisk representation av en bit information, till exempel text, dokument, bilder, ljud etc. Representationen fångar den semantiska innebörden av det som bäddas in, och det är precis vad vi behöver. För det här projektet kan vi inte förlita oss på tunga GPU-modeller: så vi kommer att ladda ner den inbyggda Alpaca-modellen och använda från Långkedja d LlamaCppInbäddningar. Oroa dig inte! Allt förklaras steg för steg
Skapa en virtuell miljö
Skapa en ny mapp för ditt nya Python-projekt, till exempel GPT4ALL_Fabio (skriv ditt namn...):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioSkapa sedan en ny virtuell Python-miljö. Om du har mer än en pythonversion installerad, ange önskad version: i det här fallet kommer jag att använda min huvudinstallation, kopplad till python 3.10.
python3 -m venv .venvKommandot python3 -m venv .venv skapar en ny virtuell miljö med namnet .venv (punkten kommer att skapa en dold katalog som heter venv).
En virtuell miljö tillhandahåller en isolerad Python-installation, som låter dig installera paket och beroenden bara för ett specifikt projekt utan att påverka den systemomfattande Python-installationen eller andra projekt. Denna isolering hjälper till att upprätthålla konsekvens och förhindra potentiella konflikter mellan olika projektkrav.
När den virtuella miljön har skapats kan du aktivera den med följande kommando:
source .venv/bin/activate 
Aktiverad virtuell miljö
Biblioteken att installera
För projektet vi bygger behöver vi inte för många paket. Vi behöver bara:
- python-bindningar för GPT4All
- Langchain för att interagera med våra dokument
LangChain är ett ramverk för att utveckla applikationer som drivs av språkmodeller. Det låter dig inte bara anropa en språkmodell via ett API, utan också koppla en språkmodell till andra datakällor och låta en språkmodell interagera med sin omgivning.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4För LangChain ser du att vi även angav versionen. Det här biblioteket tar emot många uppdateringar nyligen, så för att vara säker på att vår installation kommer att fungera även imorgon är det bättre att ange en version som vi vet fungerar bra. Ostrukturerad är ett nödvändigt beroende för pdf-laddaren och pytesserakt och pdf2bild också.
ANMÄRKNINGAR: på GitHub-förvaret finns en requirements.txt-fil (föreslagen av jl adcr) med alla versioner som är kopplade till detta projekt. Du kan göra installationen i en enda gång, efter att ha laddat ner den till huvudprojektets filkatalog med följande kommando:
pip install -r requirements.txtI slutet av artikeln skapade jag en avsnitt för felsökning. GitHub-repo har också en uppdaterad READ.ME med all denna information.
Tänk på att vissa biblioteken har tillgängliga versioner beroende på python-versionen du kör på din virtuella miljö.
Ladda ner modellerna på din PC
Detta är ett riktigt viktigt steg.
För projektet behöver vi verkligen GPT4All. Processen som beskrivs på Nomic AI är riktigt komplicerad och kräver hårdvara som inte alla av oss har (som jag). Så här är länken till modellen redan konverterad och redo att användas. Klicka bara på nedladdning.

Ladda ner modellen GPT4All
Som beskrivs kortfattat i inledningen behöver vi också modellen för inbäddningarna, en modell som vi kan köra på vår CPU utan att krossa. Klicka på länk här för att ladda ner alpaca-native-7B-ggml redan konverterad till 4-bitars och redo att användas för att fungera som vår modell för inbäddningen.
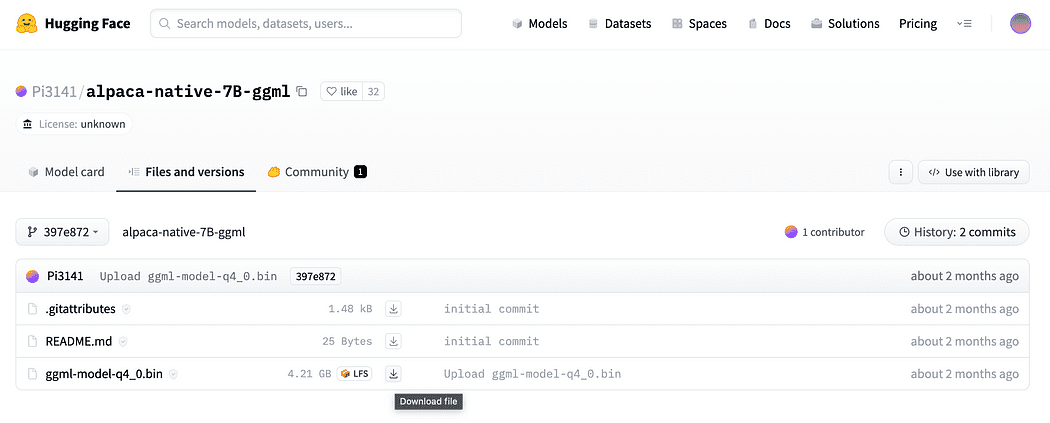
Klicka på nedladdningspilen bredvid ggml-model-q4_0.bin
Varför behöver vi inbäddningar? Om du kommer ihåg från flödesdiagrammet är det första steget som krävs, efter att vi samlat in dokumenten för vår kunskapsbas, att embed dem. LLamaCPP-inbäddningarna från denna Alpaca-modell passar jobbet perfekt och den här modellen är också ganska liten (4 Gb). Förresten kan du också använda Alpaca-modellen för din QnA!
Uppdatering 2023.05.25: Mani Windows-användare har problem med att använda llamaCPP-inbäddningar. Detta sker främst för att under installationen av pythonpaketet llama-cpp-python med:
pip install llama-cpp-pythonpip-paketet kommer att kompileras från källbiblioteket. Windows har vanligtvis inte CMake eller C-kompilator installerad som standard på maskinen. Men oroa dig inte, det finns en lösning
Att köra installationen av llama-cpp-python, som krävs av LangChain med llamaEmbeddings, på Windows CMake C-kompliator är inte installerad som standard, så du kan inte bygga från källkod.
På Mac-användare med Xtools och på Linux är C-komplianten vanligtvis redan tillgänglig på operativsystemet.
För att undvika problemet du MÅSTE använda föranpassade hjul.
Gå hit https://github.com/abetlen/llama-cpp-python/releases
och leta efter det överensstämmande hjulet för din arkitektur och pythonversion — du MÅSTE ta Weels version 0.1.49 eftersom högre versioner inte är kompatibla.
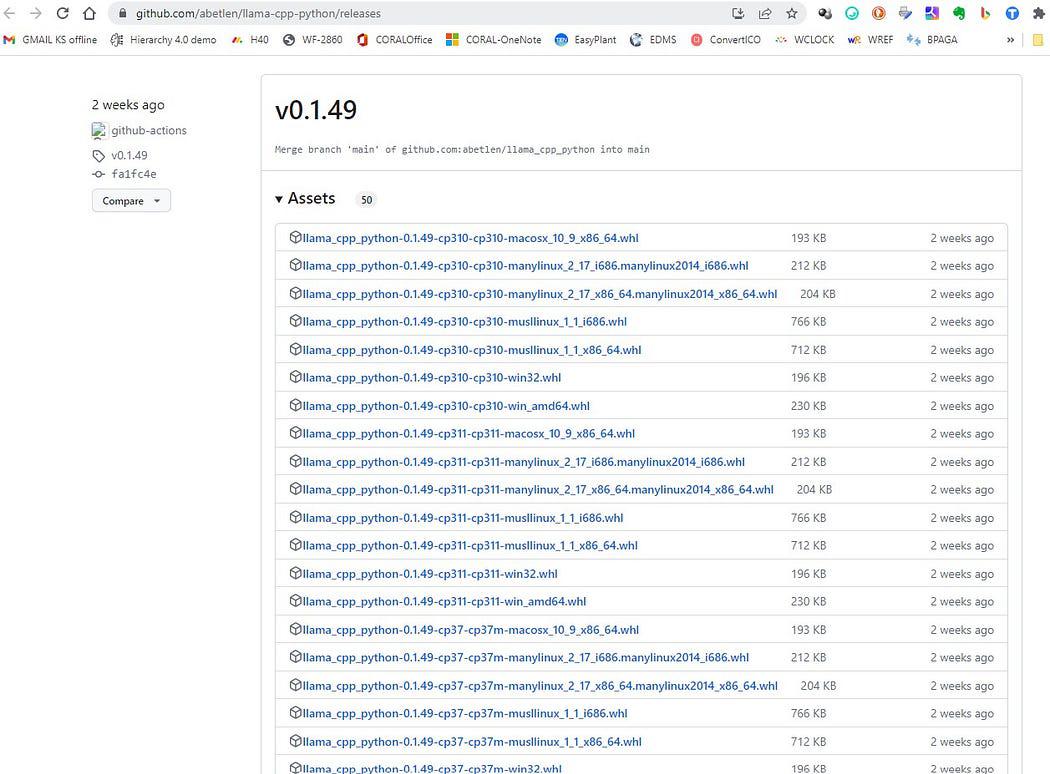
Skärmdump från https://github.com/abetlen/llama-cpp-python/releases
I mitt fall har jag Windows 10, 64 bitar, python 3.10
så min fil är llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Denna problemet spåras på GitHub-förvaret
Efter nedladdning måste du lägga de två modellerna i modellkatalogen, som visas nedan.

Katalogstruktur och var modellfilerna ska placeras
Eftersom vi vill ha kontroll över vår interaktion med GPT-modellen måste vi skapa en python-fil (låt oss kalla det pygpt4all_test.py), importera beroenden och ge instruktionen till modellen. Du kommer att se att det är ganska enkelt.
from pygpt4all.models.gpt4all import GPT4AllDetta är pytonbindningen för vår modell. Nu kan vi ringa den och börja fråga. Låt oss prova en kreativ.
Vi skapar en funktion som läser återuppringningen från modellen, och vi ber GPT4All att slutföra vår mening.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)Det första uttalandet talar om för vårt program var man kan hitta modellen (kom ihåg vad vi gjorde i avsnittet ovan)
Det andra påståendet är att be modellen att generera ett svar och att slutföra vår uppmaning "Det var en gång".
För att köra det, se till att den virtuella miljön fortfarande är aktiverad och kör helt enkelt:
python3 pygpt4all_test.pyDu bör se en laddningstext av modellen och kompletteringen av meningen. Beroende på dina hårdvaruresurser kan det ta lite tid.
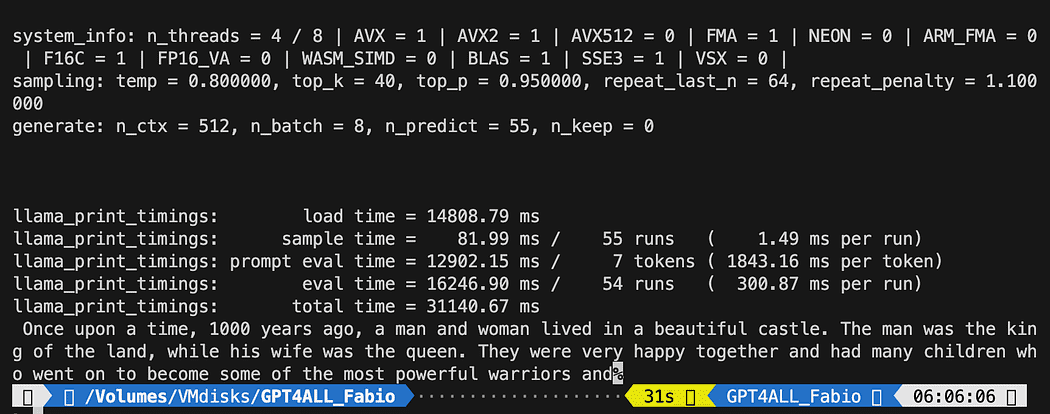
Resultatet kan skilja sig från ditt... Men för oss är det viktiga att det fungerar och vi kan fortsätta med LangChain för att skapa några avancerade saker.
OBS (uppdaterad 2023.05.23): om du stöter på ett fel relaterat till pygpt4all, kolla felsökningsavsnittet om detta ämne med lösningen som ges av Rajneesh Aggarwal or av Oscar Jeong.
LangChain framework är ett riktigt fantastiskt bibliotek. Det ger Komponenter att arbeta med språkmodeller på ett lättanvänt sätt, och det ger också Kedjor. Kedjor kan ses som sammansättning av dessa komponenter på särskilda sätt för att på bästa sätt uppnå ett visst användningsfall. Dessa är avsedda att vara ett gränssnitt på högre nivå genom vilket människor enkelt kan komma igång med ett specifikt användningsfall. Dessa kedjor är också designade för att kunna anpassas.
I vårt nästa pythontest kommer vi att använda en Snabbmall. Språkmodeller tar text som input - den texten kallas vanligtvis för en uppmaning. Vanligtvis är detta inte bara en hårdkodad sträng utan snarare en kombination av en mall, några exempel och användarinmatning. LangChain tillhandahåller flera klasser och funktioner för att göra det enkelt att konstruera och arbeta med uppmaningar. Låt oss se hur vi kan göra det också.
Skapa en ny python-fil och anropa den my_langchain.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])Vi importerade från LangChain klassen Prompt Template and Chain och GPT4All llm för att kunna interagera direkt med vår GPT-modell.
Sedan, efter att ha ställt in vår llm-väg (som vi gjorde tidigare) instansierar vi återuppringningshanterarna så att vi kan fånga svaren på vår fråga.
Att skapa en mall är väldigt enkelt: följa dokumentation handledning vi kan använda något sånt här...
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])Smakämnen mall variabel är en flerradssträng som innehåller vår interaktionsstruktur med modellen: i hängslen infogar vi de externa variablerna i mallen, i vårt scenario är vår fråga.
Eftersom det är en variabel kan du bestämma om det är en hårdkodad fråga eller en användarinmatningsfråga: här de två exemplen.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")För vår testkörning kommer vi att kommentera användarens input en. Nu behöver vi bara länka ihop vår mall, frågan och språkmodellen.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Kom ihåg att verifiera att din virtuella miljö fortfarande är aktiverad och kör kommandot:
python3 my_langchain.pyDu kan få ett annat resultat än mitt. Vad som är fantastiskt är att du kan se hela resonemanget följt av att GPT4All försöker få ett svar åt dig. Om du justerar frågan kan du också få bättre resultat.

Langkedja med promptmall på GPT4All
Här börjar vi den fantastiska delen, eftersom vi kommer att prata med våra dokument med GPT4All som en chatbot som svarar på våra frågor.
Sekvensen av steg, med hänvisning till Arbetsflöde för QnA med GPT4All, är att ladda våra pdf-filer, göra dem i bitar. Efter det kommer vi att behöva en Vector Store för våra inbäddningar. Vi måste mata in våra bitar av dokument i ett vektorlager för informationshämtning och sedan bäddar vi in dem tillsammans med likhetssökningen i denna databas som ett sammanhang för vår LLM-fråga.
För detta ändamål kommer vi att använda FAISS direkt från Långkedja bibliotek. FAISS är ett bibliotek med öppen källkod från Facebook AI Research, designat för att snabbt hitta liknande föremål i stora samlingar av högdimensionell data. Det erbjuder indexering och sökmetoder för att göra det enklare och snabbare att hitta de mest liknande objekten i en datamängd. Det är särskilt bekvämt för oss eftersom det förenklar informationsinhämtning och tillåt oss att lokalt spara den skapade databasen: detta betyder att efter den första skapandet kommer den att laddas mycket snabbt för vidare användning.
Skapande av vektorindex db
Skapa en ny fil och anropa den my_knowledge_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeDe första biblioteken är desamma som vi använde tidigare: dessutom använder vi Långkedja för skapande av vektorlagerindex, den LlamaCppInbäddningar att interagera med vår Alpaca-modell (kvantiserad till 4-bitars och kompilerad med cpp-biblioteket) och PDF-laddaren.
Låt oss också ladda våra LLM:er med sina egna vägar: en för inbäddningar och en för textgenerering.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)För test, låt oss se om vi lyckades läsa alla pfd-filer: det första steget är att deklarera 3 funktioner som ska användas på varje enskilt dokument. Den första är att dela upp den extraherade texten i bitar, den andra är att skapa vektorindex med metadata (som sidnummer etc...) och den sista är för att testa likhetssökningen (jag kommer att förklara bättre senare).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesNu kan vi testa indexgenereringen för dokumenten i docs katalog: vi måste lägga alla våra pdf-filer där. Långkedja har också en metod för att ladda hela mappen, oavsett filtyp: eftersom det är komplicerat efterprocessen kommer jag att ta upp det i nästa artikel om LaMini-modeller.

min docs-katalog innehåller 4 pdf-filer
Vi kommer att tillämpa våra funktioner på det första dokumentet i listan
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)På de första raderna använder vi os library för att få lista över pdf-filer inuti docs-katalogen. Vi laddar sedan det första dokumentet (doc_list[0]) från dokumentmappen med Långkedja, dela upp i bitar och sedan skapar vi vektordatabasen med Lama inbäddningar.
Som du såg använder vi pyPDF-metoden. Den här är lite längre att använda, eftersom du måste ladda filerna en efter en, men laddar PDF med hjälp av pypdf i array av dokument kan du ha en array där varje dokument innehåller sidinnehåll och metadata med page siffra. Detta är verkligen praktiskt när du vill veta källorna till sammanhanget vi kommer att ge till GPT4All med vår förfrågan. Här är exemplet från readthedocs:
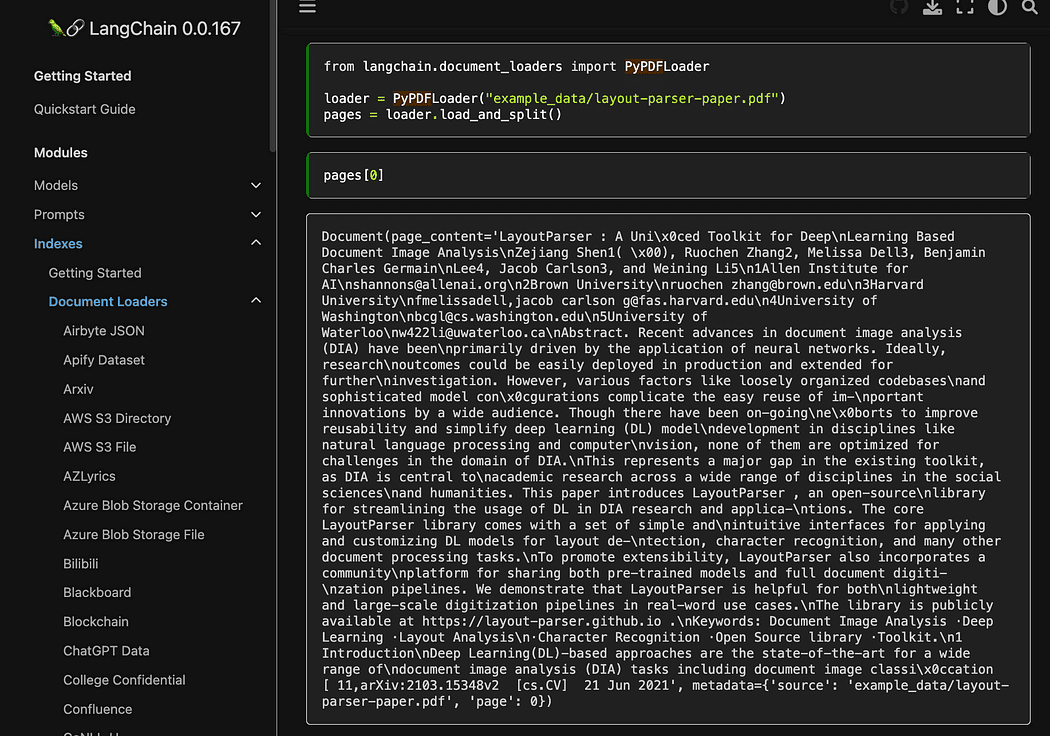
Skärmdump från Langchain dokumentation
Vi kan köra python-filen med kommandot från terminalen:
python3 my_knowledge_qna.pyEfter laddningen av modellen för inbäddningar kommer du att se tokens som fungerar för indexeringen: bli inte rädd eftersom det kommer att ta tid, speciellt om du bara kör på CPU, som jag (det tog 8 minuter).
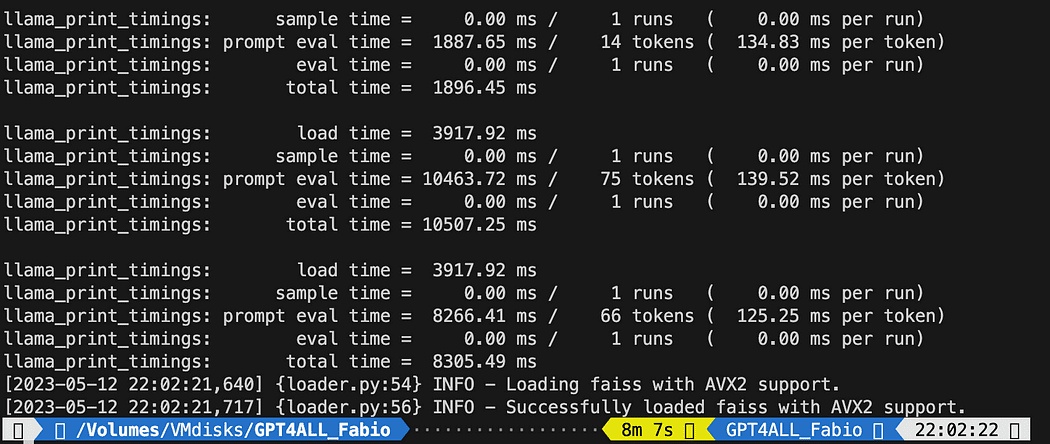
Färdigställande av den första vektorn db
Som jag förklarade är pyPDF-metoden långsammare men ger oss ytterligare data för likhetssökningen. För att iterera igenom alla våra filer kommer vi att använda en bekväm metod från FAISS som gör att vi kan SLÄNTA ihop olika databaser. Vad vi gör nu är att vi använder koden ovan för att generera den första db (vi kommer att kalla den db0) och med en for-loop skapar vi indexet för nästa fil i listan och slår samman det omedelbart med db0.
Här är koden: observera att jag har lagt till några loggar för att ge dig status på framstegen med hjälp av datetime.datetime.now() och skriva ut delta för sluttid och starttid för att beräkna hur lång tid operationen tog (du kan ta bort det om du inte gillar det).
Sammanfogningsinstruktionerna är så här
# merge dbi with the existing db0
db0.merge_from(dbi)En av de sista instruktionerna är att spara vår databas lokalt: hela generationen kan ta jämna timmar (beror på hur många dokument du har) så det är riktigt bra att vi bara måste göra det en gång!
# Save the databasae locally
db0.save_local("my_faiss_index")Här är hela koden. Vi kommer att kommentera många delar av det när vi interagerar med GPT4All och laddar indexet direkt från vår mapp.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Att köra python-filen tog 22 minuter
Att köra python-filen tog 22 minuter
Ställ frågor till GPT4All om dina dokument
Nu är vi här. Vi har vårt index, vi kan ladda det och med en promptmall kan vi be GPT4All att svara på våra frågor. Vi börjar med en hårdkodad fråga och sedan går vi igenom våra ingångsfrågor.
Lägg in följande kod i en python-fil db_loading.py och kör det med kommandot från terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])Den tryckta texten är listan över de 3 källor som bäst matchar frågan, och ger oss även dokumentnamnet och sidnumret.
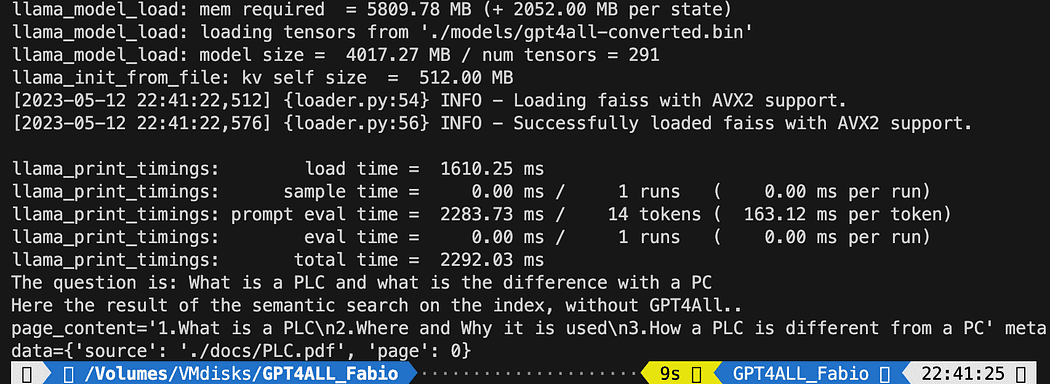
Resultat av den semantiska sökningen som kör filen db_loading.py
Nu kan vi använda likhetssökningen som sammanhanget för vår fråga med hjälp av promptmallen. Efter de 3 funktionerna ersätter du bara all kod med följande:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Efter att ha kört får du ett resultat som detta (men kan variera). Underbart nej!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Om du vill att en användarinmatningsfråga ska ersätta raden
question = "What is a PLC and what is the difference with a PC"med något så här:
question = input("Your question: ")Det är dags för dig att experimentera. Ställ olika frågor om alla ämnen relaterade till dina dokument och se resultatet. Det finns ett stort utrymme för förbättringar, verkligen på uppmaningen och mallen: du kan ta en titt här för lite inspiration. Men Långkedja dokumentationen är verkligen fantastisk (jag skulle kunna följa den!!).
Du kan följa koden från artikeln eller kontrollera den mitt github-repo.
Fabio Matricardi en utbildare, lärare, ingenjör och inlärningsentusiast. Han har undervisat i 15 år för unga studenter och nu utbildar han nya medarbetare på Key Solution Srl. Han började min karriär som industriell automationsingenjör 2010. Han har passionerat för programmering sedan han var tonåring och upptäckte skönheten i att bygga mjukvara och mänskliga maskingränssnitt för att få något till liv. Undervisning och coachning är en del av min dagliga rutin, liksom att studera och lära sig att vara en passionerad ledare med uppdaterade ledaregenskaper. Följ med mig på resan mot en bättre design, en förutsägande systemintegration med hjälp av maskininlärning och artificiell intelligens under hela tekniska livscykeln.
Ursprungliga. Skickas om med tillstånd.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free

