Beskrivning
När vi hör datavetenskap är det första som kommer att tänka på att bygga en modell på bärbara datorer och träna data. Men detta är inte läget i verklig datavetenskap. I den verkliga världen bygger datavetare modeller och sätter dem i produktion. Produktionsmiljön har en klyfta mellan utvecklingen, driftsättningen och tillförlitligheten av modellen och för att underlätta effektiva och skalbara operationer. Det är här datavetare använder MLOps (Machine Learning Operations) för att bygga och distribuera ML-applikationer i en produktionsmiljö. I den här artikeln kommer vi att bygga och distribuera ett projekt för kundförlust med hjälp av MLOps.

Inlärningsmål
I den här artikeln lär du dig:
- Översikt över projektet
- Vi kommer att introducera grunderna i ZenML och MLOPS.
- Lär dig hur du distribuerar modellen lokalt för förutsägelse
- Gå in på dataförbearbetning och ingenjörskonst, utbildning och utvärdering av modellen
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Översikt över projektet
Först och främst måste vi förstå vad vårt projekt är. För det här projektet har vi en datauppsättning från ett telekomföretag. Nu, att bygga en modell för att förutsäga om användaren sannolikt kommer att fortsätta tjänsten för företaget eller inte. Vi kommer att bygga denna ML-applikation med hjälp av ZenmML och MLFlow. Detta är arbetsflödet i vårt projekt.
Arbetsflödet i vårt projekt
- Datainsamling
- Förbehandling av data
- Utbildningsmodell
- Utvärdera modellen
- konfiguration
Vad är MLOps?
MLOps är en heltäckande livscykel för maskininlärning, från utveckling till driftsättning och löpande underhåll. MLOps är metoden att effektivisera och automatisera hela livscykeln för maskininlärningsmodeller, allt samtidigt som skalbarhet, tillförlitlighet och effektivitet säkerställs.
Låt oss förklara det med ett enkelt exempel:
Föreställ dig att du bygger en skyskrapa i din stad. Byggnaden av byggnaden är klar. Men den saknar el, vatten, avloppssystem etc. Skyskrapan kommer att vara ofunktionell och opraktisk.
Detsamma gäller för maskininlärningsmodeller. Om dessa modeller utformas utan att ta hänsyn till implementeringen av modellen, skalbarhet och långsiktigt underhåll, kan de bli ineffektiva och opraktiska. Detta utgör ett stort hinder för datavetare när de bygger maskininlärningsmodeller för användning i produktionsmiljöer.
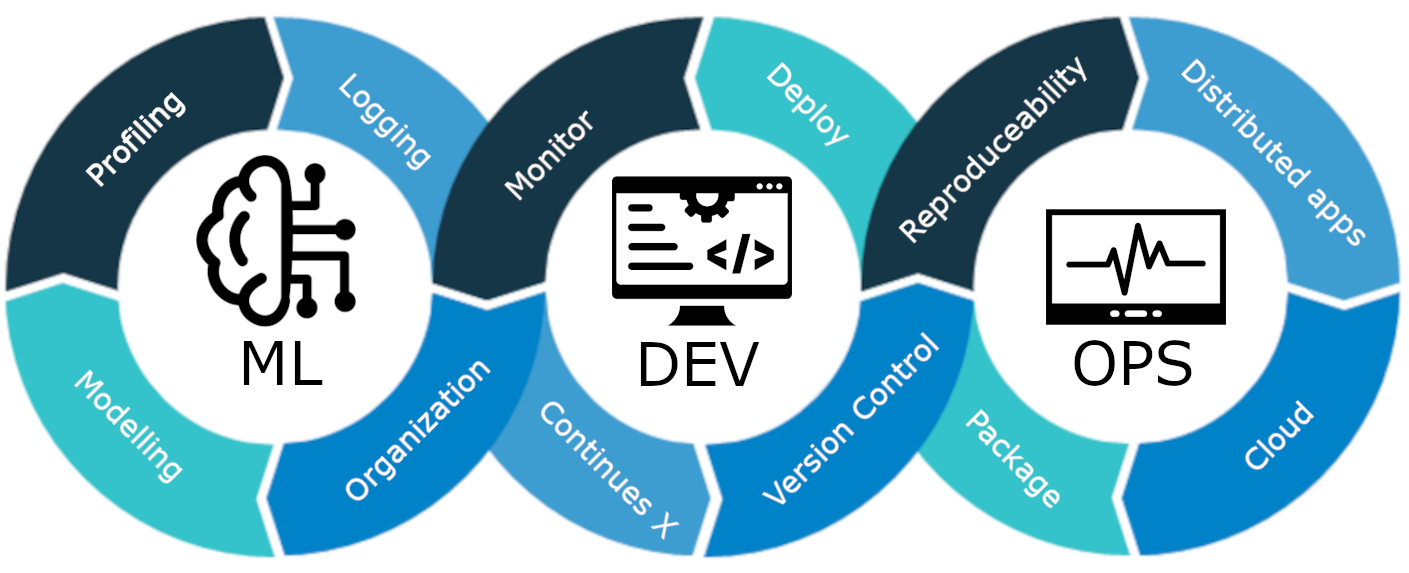
MLOps är en uppsättning bästa praxis och strategier som styr produktion, driftsättning och långsiktigt underhåll av maskininlärningsmodeller. Det säkerställer att dessa modeller inte bara ger korrekta förutsägelser utan också förblir robusta, skalbara och värdefulla tillgångar för företag. Så utan MLOps kommer det att vara en mardröm att göra alla dessa uppgifter effektivt, vilket är utmanande. I det här projektet kommer vi att förklara hur MLOps fungerar, olika stadier och ett heltäckande projekt om hur man bygger en kund churn-förutsägelse modell.
Vi introducerar ZenML
ZenML är ett MLOPS-ramverk med öppen källkod som hjälper till att bygga bärbara och produktionsklara pipelines. ZenML Framework kommer att hjälpa oss att göra detta projekt med hjälp av MLOPS.
⚠️ Om du är en Windows-användare, försök att installera wsl på en PC. Zenml stöds inte i Windows.
Innan vi går vidare till projekten.
Grundläggande begrepp för MLOPS
- Steg: Steg är enskilda enheter av uppgifter i en pipeline eller ett arbetsflöde. Varje steg representerar en specifik åtgärd eller operation som måste utföras för att utveckla ett arbetsflöde för maskininlärning. Till exempel är datarensning, dataförbearbetning, träningsmodeller etc. vissa steg i utvecklingen av en maskininlärningsmodell.
- Rörledningar: De kopplar samman flera steg för att skapa en strukturerad och automatiserad process för maskininlärningsuppgifter. för t.ex. databehandlingspipeline, modellutvärderingspipeline och modellutbildningspipeline.
Komma igång
Skapa en virtuell miljö för projektet:
conda create -n churn_prediction python=3.9Installera sedan dessa bibliotek:
pip install numpy pandas matplotlib scikit-learnNär du har installerat detta, installera ZenML:
pip install zenml["server"]Initiera sedan ZenML-förrådet.
zenml init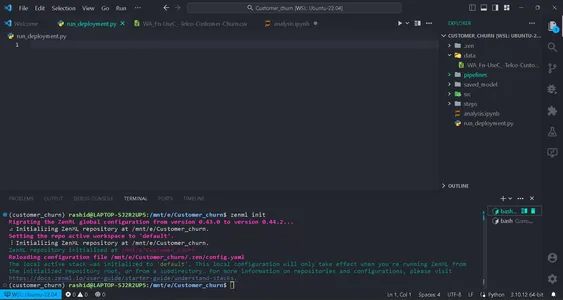
Du kommer att få en grön flagga att gå vidare om din skärm visar detta. Efter initialisering kommer en mapp .zenml att skapas i din katalog.
Skapa en mapp för data i katalogen. Få uppgifterna här länk:
Skapa mappar enligt denna struktur.
Datainsamling
I det här steget kommer vi att importera data från vår csv-fil. Dessa data kommer att användas för att träna modellen efter rengöring och kodning.
Skapa en fil ingest_data.py inuti mappen steg.
import pandas as pd
import numpy as np
import logging
from zenml import step class IngestData: """ Ingesting data to the workflow. """ def __init__(self, path:str) -> None: """ Args: data_path(str): path of the datafile """ self.path = path def get_data(self): df = pd.read_csv(self.path) logging.info("Reading csv file successfully completed.") return df @step(enable_cache = False)
def ingest_df(data_path:str) -> pd.DataFrame: """ ZenML step for ingesting data from a CSV file. """ try: #Creating an instance of IngestData class and ingest the data ingest_data = IngestData(data_path) df = ingest_data.get_data() logging.info("Ingesting data completed") return df except Exception as e: #Log an error message if data ingestion fails and raise the exception logging.error("Error while ingesting data") raise eHär är projektet länk.
I den här koden skapade vi först klassen IngestData för att kapsla in datainmatningslogiken. Sedan skapade vi en ZenML steg, ingest_df, som är en individuell enhet i datainsamlingspipelinen.
Skapa en fil training_pipeline.py inuti mappen pipeline.
Skriv koden
from zenml import pipeline from steps.ingest_data import ingest_df #Define a ZenML pipeline called training_pipeline. @pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' df = ingest_df(data_path=data_path)Här skapar vi en utbildningspipeline för att träna en maskininlärningsmodell med hjälp av en serie steg.
Skapa sedan en fil med namnet run_pipeline.py i baskatalogen för att köra rörledning.
from pipelines.training_pipeline import train_pipeline if __name__ == '__main__': #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Denna kod används för att köra pipeline.
Så nu har vi avslutat pipelinen för dataintag. Låt oss köra det.
Kör kommandot i din terminal:
python run_pipeline.py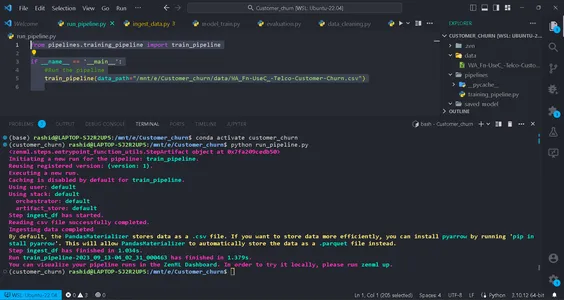
Sedan kan du se kommandona som indikerar att training_pipeline har slutförts.
Förbehandling av data
I detta steg kommer vi att skapa olika strategier för rengöring av data. De oönskade kolumnerna tas bort, och kategoriska kolumner kommer att kodas med Label-kodning. Slutligen kommer data att delas upp i tränings- och testdata.
Skapa en fil som heter clean_data.py i src-mappen.
I den här filen kommer vi att skapa klasser av strategier för att rensa data.
import pandas as pd
import numpy as np
import logging
from sklearn.model_selection import train_test_split
from abc import abstractmethod, ABC
from typing import Union
from sklearn.preprocessing import LabelEncoder class DataStrategy(ABC): @abstractmethod def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame,pd.Series]: pass # Data Preprocessing strategy
class DataPreprocessing(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df['TotalCharges'] = df['TotalCharges'].replace(' ', 0).astype(float) df.drop('customerID', axis=1, inplace=True) df['Churn'] = df['Churn'].replace({'Yes': 1, 'No': 0}).astype(int) service = ['PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies'] for col in service: df[col] = df[col].replace({'No phone service': 'No', 'No internet service': 'No'}) logging.info("Length of df: ", len(df.columns)) return df except Exception as e: logging.error("Error in Preprocessing", e) raise e # Feature Encoding Strategy
class LabelEncoding(DataStrategy): def handle_data(self, df: pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: df_cat = ['gender', 'Partner', 'Dependents', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod'] lencod = LabelEncoder() for col in df_cat: df[col] = lencod.fit_transform(df[col]) logging.info(df.head()) return df except Exception as e: logging.error(e) raise e # Data splitting Strategy
class DataDivideStrategy(DataStrategy): def handle_data(self, df:pd.DataFrame) -> Union[pd.DataFrame, pd.Series]: try: X = df.drop('Churn', axis=1) y = df['Churn'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) return X_train, X_test, y_train, y_test except Exception as e: logging.error("Error in DataDividing", e) raise e
Denna kod implementerar en modulär dataförbearbetningspipeline för maskininlärning. Det inkluderar strategier för dataförbehandling, funktionskodning och datakodningssteg för datarensning för prediktiv modellering.
1. Dataförbehandling: Den här klassen är ansvarig för att ta bort oönskade kolumner och hantera saknade värden (NA-värden) i datamängden.
2. Etikettkodning: Klassen LabelEncoding är utformad för att koda kategoriska variabler till ett numeriskt format som maskininlärningsalgoritmer kan arbeta med effektivt. Den omvandlar textbaserade kategorier till numeriska värden.
3. DataDivideStrategy: Denna klass separerar datasetet i oberoende variabler (X) och beroende variabler (y). Sedan delar den upp data i tränings- och testuppsättningar.
Vi kommer att implementera dem steg för steg för att förbereda vår data för maskininlärningsuppgifter.
Dessa strategier säkerställer att data struktureras och formateras korrekt för modellutbildning och utvärdering.
Skapa data_cleaning.py i steg mapp.
import pandas as pd
import numpy as np
from src.clean_data import DataPreprocessing, DataDivideStrategy, LabelEncoding
import logging
from typing_extensions import Annotated
from typing import Tuple
from zenml import step # Define a ZenML step for cleaning and preprocessing data
@step(enable_cache=False)
def cleaning_data(df: pd.DataFrame) -> Tuple[ Annotated[pd.DataFrame, "X_train"], Annotated[pd.DataFrame, "X_test"], Annotated[pd.Series, "y_train"], Annotated[pd.Series, "y_test"],
]: try: # Instantiate the DataPreprocessing strategy data_preprocessing = DataPreprocessing() # Apply data preprocessing to the input DataFrame data = data_preprocessing.handle_data(df) # Instantiate the LabelEncoding strategy feature_encode = LabelEncoding() # Apply label encoding to the preprocessed data df_encoded = feature_encode.handle_data(data) # Log information about the DataFrame columns logging.info(df_encoded.columns) logging.info("Columns:", len(df_encoded)) # Instantiate the DataDivideStrategy strategy split_data = DataDivideStrategy() # Split the encoded data into training and testing sets X_train, X_test, y_train, y_test = split_data.handle_data(df_encoded) # Return the split data as a tuple return X_train, X_test, y_train, y_test except Exception as e: # Handle and log any errors that occur during data cleaning logging.error("Error in step cleaning data", e) raise eI det här steget implementerade vi de strategier vi skapade i clean_data.py
Låt oss genomföra detta steg in training_pipeline.py
from zenml import pipeline #importing steps from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df)Det är allt; vi har slutfört vårt dataförbehandlingssteg i utbildningspipelinen.
Modellutbildning
Nu ska vi bygga modellen för detta projekt. Här förutsäger vi ett binärt klassificeringsproblem. Vi kan använda logistisk återgång. Vårt fokus kommer inte att ligga på modellens noggrannhet. Det kommer att baseras på MLOps-delen.
För den som inte känner till logistisk regression kan du läsa om det här. Vi kommer att implementera samma steg som vi gjorde i dataförbehandlingssteget. Först skapar vi en fil training_model.py i src mapp.
import pandas as pd
from sklearn.linear_model import LogisticRegression
from abc import ABC, abstractmethod
import logging #Abstract model
class Model(ABC): @abstractmethod def train(self,X_train:pd.DataFrame,y_train:pd.Series): """ Trains the model on given data """ pass class LogisticReg(Model): """ Implementing the Logistic Regression model. """ def train(self, X_train: pd.DataFrame, y_train: pd.Series): """ Training the model Args: X_train: pd.DataFrame, y_train: pd.Series """ logistic_reg = LogisticRegression() logistic_reg.fit(X_train,y_train) return logistic_regVi definierar en abstrakt modellklass med en 'tåg'-metod som alla modeller måste implementera. LogisticReg-klassen är en specifik implementering som använder logistisk regression. Nästa steg innebär att konfigurera en fil med namnet config.py i mappen steg. Skapa en fil med namnet config.py i mappen steg.
Konfigurera modellparametrar
from zenml.steps import BaseParameters """
This file is used for used for configuring
and specifying various parameters related to your machine learning models and training process """ class ModelName(BaseParameters): """ Model configurations """ model_name: str = "logistic regression"I filen som heter config.py, inuti steg mapp, konfigurerar du parametrar relaterade till din maskininlärningsmodell. Du skapar en ModelName-klass som ärver från Basparametrar för att ange modellnamnet. Detta gör det enkelt att byta modelltyp.
import logging import pandas as pd
from src.training_model import LogisticReg
from zenml import step
from .config import ModelName #Define a step called train_model
@step(enable_cache=False)
def train_model(X_train:pd.DataFrame,y_train:pd.Series,config:ModelName): """ Trains the data based on the configured model """ try: model = None if config == "logistic regression": model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) return trained_model except Exception as e: logging.error("Error in step training model",e) raise eI filen som heter model_train.py i mappen steg, definiera ett steg som heter train_model med ZenML. Syftet med detta steg är att träna en maskininlärningsmodell utifrån namnet på modellen i Modellnamn.
I programmet
Kontrollera det konfigurerade modellnamnet. Om det är "logistisk regression" skapade vi en instans av LogisticReg-modellen och tränade den med den tillhandahållna träningsdatan (X_train och y_train). Om modellnamnet inte stöds visas ett felmeddelande. Eventuella fel under denna process loggas och felet uppstår.
Efter detta kommer vi att implementera detta steg in training_pipeline.py
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train)Nu har vi implementerat steget train_model i pipelinen. Så steget model_train.py är slutfört.
Utvärdering av modell
I detta steg kommer vi att utvärdera hur effektiv vår modell är. För det kommer vi att kontrollera noggrannhetspoängen när vi förutsäger testdata. Så först ska vi skapa de strategier vi ska använda i pipelinen.
Skapa en fil med namnet evaluate_model.py i mappen src.
import logging
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
from abc import ABC, abstractmethod
import numpy as np # Abstract class for model evaluation
class Evaluate(ABC): @abstractmethod def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Abstract method to evaluate a machine learning model's performance. Args: y_true (np.ndarray): True labels. y_pred (np.ndarray): Predicted labels. Returns: float: Evaluation result. """ pass #Class to calculate accuracy score
class Accuracy_score(Evaluate): """ Calculates and returns the accuracy score for a model's predictions. """ def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: try: accuracy_scr = accuracy_score(y_true=y_true, y_pred=y_pred) * 100 logging.info("Accuracy_score:", accuracy_scr) return accuracy_scr except Exception as e: logging.error("Error in evaluating the accuracy of the model",e) raise e
#Class to calculate Precision score
class Precision_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray) -> float: """ Generates and returns a precision score for a model's predictions. """ try: precision = precision_score(y_true=y_true,y_pred=y_pred) logging.info("Precision score: ",precision) return float(precision) except Exception as e: logging.error("Error in calculation of precision_score",e) raise e class F1_Score(Evaluate): def evaluate_model(self, y_true: np.ndarray, y_pred: np.ndarray): """ Generates and returns an F1 score for a model's predictions. """ try: f1_scr = f1_score(y_pred=y_pred, y_true=y_true) logging.info("F1 score: ", f1_scr) return f1_scr except Exception as e: logging.error("Error in calculating F1 score", e) raise e Nu när vi har byggt upp utvärderingsstrategierna kommer vi att använda dem för att utvärdera modellen. Låt oss implementera koden i steg evaluate_model.py i mappen steg. Här är återkallelsepoäng, noggrannhetspoäng och precisionspoäng de strategier vi använder som mått för att utvärdera modellen.
Låt oss implementera dessa i steg. Skapa en fil med namnet evaluation.py i steg:
import logging
import pandas as pd
import numpy as np
from zenml import step
from src.evaluate_model import ClassificationReport, ConfusionMatrix, Accuracy_score
from typing import Tuple
from typing_extensions import Annotated
from sklearn.base import ClassifierMixin @step(enable_cache=False)
def evaluate_model( model: ClassifierMixin, X_test: pd.DataFrame, y_test: pd.Series
) -> Tuple[ Annotated[np.ndarray,"confusion_matix"], Annotated[str,"classification_report"], Annotated[float,"accuracy_score"], Annotated[float,"precision_score"], Annotated[float,"recall_score"] ]: """ Evaluate a machine learning model's performance using common metrics. """ try: y_pred = model.predict(X_test) precision_score_class = Precision_Score() precision_score = precision_score_class.evaluate_model(y_pred=y_pred,y_true=y_test) mlflow.log_metric("Precision_score ",precision_score) accuracy_score_class = Accuracy_score() accuracy_score = accuracy_score_class.evaluate_model(y_true=y_test, y_pred=y_pred) logging.info("accuracy_score:",accuracy_score) return accuracy_score, precision_score except Exception as e: logging.error("Error in evaluating model",e) raise eLåt oss nu implementera detta steg i pipelinen. Uppdatera training_pipeline.py:
Denna kod definierar en utvärdera_modell steg i en pipeline för maskininlärning. Det kräver en utbildad klassificeringsmodell (modell), oberoende testdata (X_test), och sanna etiketter för testdata (y_test) som indata. Den utvärderar sedan modellens prestanda med hjälp av vanliga klassificeringsmått och returnerar resultaten, till exempel precision_score och precision_score.
Låt oss nu implementera detta steg i pipelinen. Uppdatera training_pipeline.py:
from zenml import pipeline from steps.ingest_data import ingest_df
from steps.data_cleaning import cleaning_data
from steps.model_train import train_model
from steps.evaluation import evaluate_model
import logging #Define a ZenML pipeline called training_pipeline.
@pipeline(enable_cache=False)
def train_pipeline(data_path:str): ''' Data pipeline for training the model. Args: data_path (str): The path to the data to be ingested. ''' #step ingesting data: returns the data. df = ingest_df(data_path=data_path) #step to clean the data. X_train, X_test, y_train, y_test = cleaning_data(df=df) #training the model model = train_model(X_train=X_train,y_train=y_train) #Evaluation metrics of data accuracy_score, precision_score = evaluate_model(model=model,X_test=X_test, y_test=y_test)Det är allt. Nu har vi slutfört utbildningspipen. Springa
python run_pipeline.py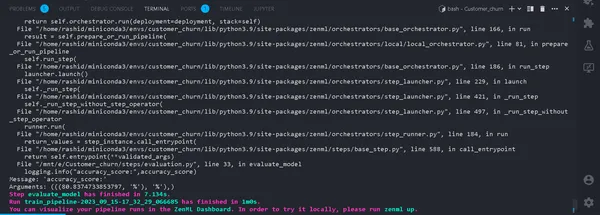
I terminalen. Om det körs framgångsrikt. Nu när vi har genomfört en träningspipeline lokalt kommer det att se ut så här:
Vad är en experimentspårare?
En experimentspårare är ett verktyg inom maskininlärning som används för att spela in, övervaka och hantera olika experiment i utvecklingsprocessen för maskininlärning.
Dataforskare experimenterar med olika modeller för att få bästa resultat. Så de måste fortsätta spåra data och använda olika modeller. Det kommer att vara mycket svårt för dem om de registrerar det manuellt med hjälp av ett Excel-ark.
MLflow
MLflow är ett värdefullt verktyg för att effektivt spåra och hantera experiment inom maskininlärning. Det automatiserar experimentspårning, övervakning av modelliterationer och tillhörande data. Detta effektiviserar modellutvecklingsprocessen och ger ett användarvänligt gränssnitt för att visualisera resultat.
Att integrera MLflow med ZenML förbättrar experimentets robusthet och hantering inom ramverket för maskininlärning.
För att ställa in MLflow med ZenML, följ dessa steg:
- Installera MLflow integration:
- Använd följande kommando för att installera MLflow-integrationen:
zenml integration install mlflow -y2. Registrera MLflow experiment tracker:
Registrera en experimentspårare i MLflow med det här kommandot:
zenml experiment-tracker register mlflow_tracker --flavor=mlflow3. Registrera en stack:
I ZenML är en stack en samling komponenter som definierar uppgifter i ditt ML-arbetsflöde. Det hjälper till att organisera och hantera ML pipeline steg effektivt. Registrera en stack med:
Du kan hitta mer information i dokumentation.
zenml model-deployer register mlflow --flavor=mlflow
zenml stack register mlflow_stack -a default -o default -d mlflow -e mlflow_tracker --setDetta associerar din stack med specifika inställningar för artefaktlagring, orkestratorer, distributionsmål och experimentspårning.
4. Visa stackdetaljer:
Du kan se komponenterna i din stack med:
zenml stack describeDetta visar komponenterna som är associerade med "mlflow_tracker"-stacken.
Låt oss nu implementera en experimentspårare i träningsmodellen och utvärdera modellen:
Du kan se namnet på komponenterna som mlflow_tracker.
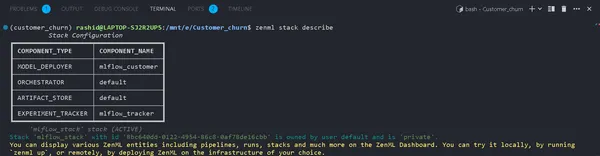
Konfigurera ZenML Experiment Tracker
Börja först med att uppdatera train_model.py:
import logging
import mlflow
import pandas as pd
from src.training_model import LogisticReg
from sklearn.base import ClassifierMixin
from zenml import step
from .config import ModelName
#import from zenml.client import Client # Obtain the active stack's experiment tracker
experiment_tracker = Client().active_stack.experiment_tracker #Define a step called train_model
@step(experiment_tracker = experiment_tracker.name,enable_cache=False)
def train_model( X_train:pd.DataFrame, y_train:pd.Series, config:ModelName ) -> ClassifierMixin: """ Trains the data based on the configured model Args: X_train: pd.DataFrame = Independent training data, y_train: pd.Series = Dependent training data. """ try: model = None if config.model_name == "logistic regression": #Automatically logging scores, model etc.. mlflow.sklearn.autolog() model = LogisticReg() else: raise ValueError("Model name is not supported") trained_model = model.train(X_train=X_train,y_train=y_train) logging.info("Training model completed.") return trained_model except Exception as e: logging.error("Error in step training model",e) raise eI den här koden ställer vi in experimentspåraren med hjälp av mlflow.sklearn.autolog(), som automatiskt loggar alla detaljer om modellen, vilket gör det lättare att spåra och analysera experiment.
I evaluation.py
from zenml.client import Client experiment_tracker = Client().active_stack.experiment_tracker @step(experiment_tracker=experiment_tracker.name, enable_cache = False)Kör rörledningen
Uppdatera din run_pipeline.py skript enligt följande:
from pipelines.training_pipeline import train_pipeline
from zenml.client import Client
if __name__ == '__main__': #printimg the experiment tracking uri print(Client().active_stack.experiment_tracker.get_tracking_uri()) #Run the pipeline train_pipeline(data_path="/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv")Kopiera det och klistra in det här kommandot.
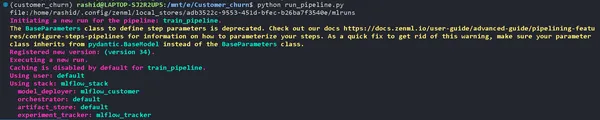
mlflow ui --backend-store-uri "--uri on the top of "file:/home/ "Utforska dina experiment
Klicka på länken som genereras av kommandot ovan för att öppna MLflow UI. Här hittar du en skattkammare av insikter:
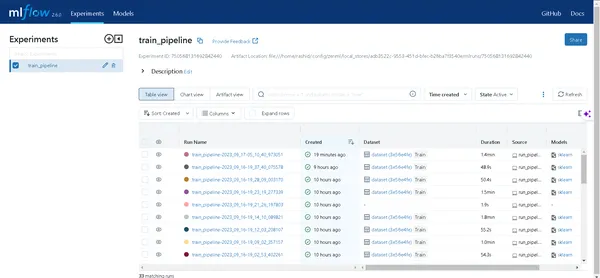
- Rörledningar: Få lätt åtkomst till alla pipelines du har kört.
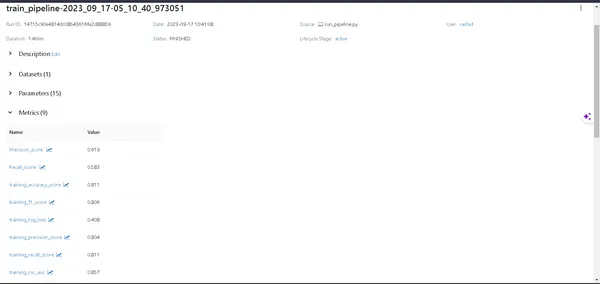
- Modellinformation: Klicka på en pipeline för att avslöja varje detalj om din modell.
- Metrics: Dyk in i statistiksektionen för att visualisera din modells prestanda.
Nu kan du erövra din spårning av maskininlärningsexperiment med ZenML och MLflow!
konfiguration
I nästa avsnitt kommer vi att distribuera den här modellen. Du måste känna till dessa begrepp:
a). Pipeline för kontinuerlig utbyggnad
Denna pipeline kommer att automatisera modelldistributionsprocessen. När en modell klarar utvärderingskriterierna distribueras den automatiskt till en produktionsmiljö. Det börjar till exempel med dataförbearbetning, datarensning, utbildning av data, modellutvärdering etc.
b). Slutledningsutbyggnadspipeline
Inference Deployment Pipeline fokuserar på att distribuera maskininlärningsmodeller för realtids- eller batch-inferens. Inference Deployment Pipeline är specialiserad på att distribuera modeller för att göra förutsägelser i en produktionsmiljö. Till exempel ställer den in en API-slutpunkt där användare kan skicka text. Den säkerställer modellens tillgänglighet och skalbarhet och övervakar dess prestanda i realtid. Dessa pipelines är viktiga för att upprätthålla effektiviteten och effektiviteten hos system för maskininlärning. Nu ska vi implementera den kontinuerliga pipelinen.
Skapa en fil som heter deployment_pipeline.py i pipelines-mappen.
import numpy as np
import json
import logging
import pandas as pd
from zenml import pipeline, step
from zenml.config import DockerSettings
from zenml.constants import DEFAULT_SERVICE_START_STOP_TIMEOUT
from zenml.integrations.constants import MLFLOW
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer,
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService
from zenml.integrations.mlflow.steps import mlflow_model_deployer_step
from zenml.steps import BaseParameters, Output
from src.clean_data import FeatureEncoding
from .utils import get_data_for_test
from steps.data_cleaning import cleaning_data
from steps.evaluation import evaluate_model
from steps.ingest_data import ingest_df # Define Docker settings with MLflow integration
docker_settings = DockerSettings(required_integrations = {MLFLOW}) #Define class for deployment pipeline configuration
class DeploymentTriggerConfig(BaseParameters): min_accuracy:float = 0.92 @step def deployment_trigger( accuracy: float, config: DeploymentTriggerConfig,
): """ It trigger the deployment only if accuracy is greater than min accuracy. Args: accuracy: accuracy of the model. config: Minimum accuracy thereshold. """ try: return accuracy >= config.min_accuracy except Exception as e: logging.error("Error in deployment trigger",e) raise e # Define a continuous pipeline
@pipeline(enable_cache=False,settings={"docker":docker_settings})
def continuous_deployment_pipeline( data_path:str, min_accuracy:float = 0.92, workers: int = 1, timeout: int = DEFAULT_SERVICE_START_STOP_TIMEOUT
): df = ingest_df(data_path=data_path) X_train, X_test, y_train, y_test = cleaning_data(df=df) model = train_model(X_train=X_train, y_train=y_train) accuracy_score, precision_score = evaluate_model(model=model, X_test=X_test, y_test=y_test) deployment_decision = deployment_trigger(accuracy=accuracy_score) mlflow_model_deployer_step( model=model, deploy_decision = deployment_decision, workers = workers, timeout = timeout )ZenML Framework for Machine Learning Project
Den här koden definierar en kontinuerlig distribution för ett maskininlärningsprojekt som använder ZenML Framework.
1. Importera nödvändiga bibliotek: Importera nödvändiga bibliotek för driftsättning av modellen.
2. Docker-inställningar: Genom att konfigurera Docker-inställningarna för användning med MLflow hjälper Docker till att paketera och köra dessa modeller konsekvent.
3. DeploymentTriggerConfig: Det är den klass där den lägsta noggrannhetströskeln är konfigurerad för en modell att distribuera.
4. deployment_trigger: Det här steget kommer tillbaka om modellens noggrannhet överskrider miniminoggrannheten.
5. continuous_deployment_pipeline: Denna pipeline består av flera steg: inmatning av data, rengöring av data, utbildning av modellen och utvärdering av modellen. Och modellen kommer bara att distribueras om den når tröskeln för minsta noggrannhet.
Därefter ska vi implementera slutledningspipelinen i deployment_pipeline.py
import logging
import pandas as pd
from zenml.steps import BaseParameters, Output
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import MLFlowModelDeployer
from zenml.integrations.mlflow.services import MLFlowDeploymentService class MLFlowDeploymentLoaderStepParameters(BaseParameters): pipeline_name: str step_name: str running: bool = True @step(enable_cache=False)
def dynamic_importer() -> str: data = get_data_for_test() return data @step(enable_cache=False)
def prediction_service_loader( pipeline_name: str, pipeline_step_name: str, running: bool = True, model_name: str = "model",
) -> MLFlowDeploymentService: model_deployer = MLFlowModelDeployer.get_active_model_deployer() existing_services = model_deployer.find_model_server( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, model_name=model_name, running=running, ) if not existing_services: raise RuntimeError( f"No MLflow prediction service deployed by the " f"{pipeline_step_name} step in the {pipeline_name} " f"pipeline for the '{model_name}' model is currently " f"running." ) return existing_services[0] @step
def predictor(service: MLFlowDeploymentService, data: str) -> np.ndarray: service.start(timeout=10) data = json.loads(data) prediction = service.predict(data) return prediction @pipeline(enable_cache=False, settings={"docker": docker_settings})
def inference_pipeline(pipeline_name: str, pipeline_step_name: str): batch_data = dynamic_importer() model_deployment_service = prediction_service_loader( pipeline_name=pipeline_name, pipeline_step_name=pipeline_step_name, running=False, ) prediction = predictor(service=model_deployment_service, data=batch_data) return prediction
Den här koden skapar en pipeline för att göra förutsägelser med hjälp av en utplacerad maskininlärningsmodell genom MLflow. Den importerar data, laddar den distribuerade modellen och använder den för att göra förutsägelser.
Vi måste skapa funktionen get_data_for_test() in utils.py i pipelines-mappen. Så vi kan hantera vår kod mer effektivt.
import logging import pandas as pd from src.clean_data import DataPreprocessing, LabelEncoding # Function to get data for testing purposes
def get_data_for_test(): try: df = pd.read_csv('./data/WA_Fn-UseC_-Telco-Customer-Churn.csv') df = df.sample(n=100) data_preprocessing = DataPreprocessing() data = data_preprocessing.handle_data(df) # Instantiate the FeatureEncoding strategy label_encode = LabelEncoding() df_encoded = label_encode.handle_data(data) df_encoded.drop(['Churn'],axis=1,inplace=True) logging.info(df_encoded.columns) result = df_encoded.to_json(orient="split") return result except Exception as e: logging.error("e") raise eLåt oss nu implementera pipelinen vi skapade för att distribuera modellen och förutsäga den distribuerade modellen.
Skapa run_deployment.py fil i projektkatalogen:
import click # For handling command-line arguments
import logging from typing import cast
from rich import print # For console output formatting # Import pipelines for deployment and inference
from pipelines.deployment_pipeline import (
continuous_deployment_pipeline, inference_pipeline
)
# Import MLflow utilities and components
from zenml.integrations.mlflow.mlflow_utils import get_tracking_uri
from zenml.integrations.mlflow.model_deployers.mlflow_model_deployer import ( MLFlowModelDeployer
)
from zenml.integrations.mlflow.services import MLFlowDeploymentService # Define constants for different configurations: DEPLOY, PREDICT, DEPLOY_AND_PREDICT
DEPLOY = "deploy"
PREDICT = "predict"
DEPLOY_AND_PREDICT = "deploy_and_predict" # Define a main function that uses Click to handle command-line arguments
@click.command()
@click.option( "--config", "-c", type=click.Choice([DEPLOY, PREDICT, DEPLOY_AND_PREDICT]), default=DEPLOY_AND_PREDICT, help="Optionally you can choose to only run the deployment " "pipeline to train and deploy a model (`deploy`), or to " "only run a prediction against the deployed model " "(`predict`). By default both will be run " "(`deploy_and_predict`).",
)
@click.option( "--min-accuracy", default=0.92, help="Minimum accuracy required to deploy the model",
)
def run_main(config:str, min_accuracy:float ): # Get the active MLFlow model deployer component mlflow_model_deployer_component = MLFlowModelDeployer.get_active_model_deployer() # Determine if the user wants to deploy a model (deploy), make predictions (predict), or both (deploy_and_predict) deploy = config == DEPLOY or config == DEPLOY_AND_PREDICT predict = config == PREDICT or config == DEPLOY_AND_PREDICT # If deploying a model is requested: if deploy: continuous_deployment_pipeline( data_path='/mnt/e/Customer_churn/data/WA_Fn-UseC_-Telco-Customer-Churn.csv', min_accuracy=min_accuracy, workers=3, timeout=60 ) # If making predictions is requested: if predict: # Initialize an inference pipeline run inference_pipeline( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", ) # Print instructions for viewing experiment runs in the MLflow UI print( "You can run:n " f"[italic green] mlflow ui --backend-store-uri '{get_tracking_uri()}" "[/italic green]n ...to inspect your experiment runs within the MLflow" " UI.nYou can find your runs tracked within the " "`mlflow_example_pipeline` experiment. There you'll also be able to " "compare two or more runs.nn" ) # Fetch existing services with the same pipeline name, step name, and model name existing_services = mlflow_model_deployer_component.find_model_server( pipeline_name = "continuous_deployment_pipeline", pipeline_step_name = "mlflow_model_deployer_step", ) # Check the status of the prediction server: if existing_services: service = cast(MLFlowDeploymentService, existing_services[0]) if service.is_running: print( f"The MLflow prediciton server is running locally as a daemon" f"process service and accepts inference requests at: n" f" {service.prediction_url}n" f"To stop the service, run" f"[italic green] zenml model-deployer models delete" f"{str(service.uuid)}'[/italic green]." ) elif service.is_failed: print( f"The MLflow prediciton server is in a failed state: n" f" Last state: '{service.status.state.value}'n" f" Last error: '{service.status.last_error}'" ) else: print( "No MLflow prediction server is currently running. The deployment" "pipeline must run first to train a model and deploy it. Execute" "the same command with the '--deploy' argument to deploy a model." ) # Entry point: If this script is executed directly, run the main function
if __name__ == "__main__": run_main()Den här koden är ett kommandoradsskript för att hantera och distribuera maskininlärningsmodellen med MLFlow och ZenMl.
Låt oss nu distribuera modellen.
Kör detta kommando på din terminal.
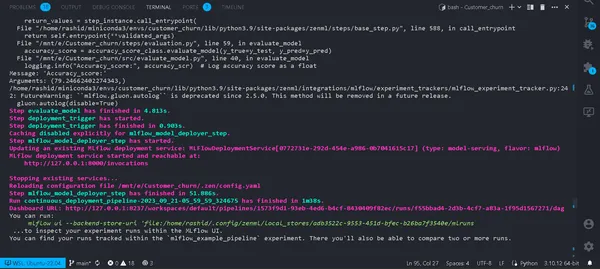
python run_deployment.py --config deploy
Nu har vi implementerat vår modell. Din pipeline kommer att köras och du kan se dem i zenml-instrumentpanelen.
python run_deployment.py --config predictStarta förutsägelseprocessen
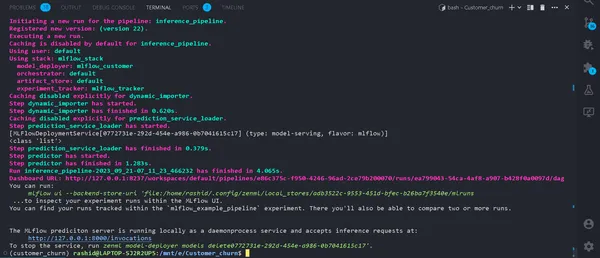
Nu kör vår MLFlow-prediktionsserver.
Vi behöver en webbapp för att mata in data och se resultaten. Du måste undra varför vi måste skapa en webbapp från grunden.
Inte riktigt. Vi kommer att använda Streamlit, som är ett frontend-ramverk med öppen källkod som hjälper till att bygga en snabb och enkel frontend-webapp för vår maskininlärningsmodell.
Installera biblioteket
pip install streamlitSkapa en fil med namnet streamlit_app.py i din projektkatalog.
import json
import logging
import numpy as np
import pandas as pd
import streamlit as st
from PIL import Image
from pipelines.deployment_pipeline import prediction_service_loader
from run_deployment import main def main(): st.title("End to End Customer Satisfaction Pipeline with ZenML") st.markdown( """ #### Problem Statement The objective here is to predict the customer satisfaction score for a given order based on features like order status, price, payment, etc. I will be using [ZenML](https://zenml.io/) to build a production-ready pipeline to predict the customer satisfaction score for the next order or purchase. """ ) st.markdown( """ Above is a figure of the whole pipeline, we first ingest the data, clean it, train the model, and evaluate the model, and if data source changes or any hyperparameter values changes, deployment will be triggered, and (re) trains the model and if the model meets minimum accuracy requirement, the model will be deployed. """ ) st.markdown( """ #### Description of Features This app is designed to predict the customer satisfaction score for a given customer. You can input the features of the product listed below and get the customer satisfaction score. | Models | Description | | ------------- | - | | SeniorCitizen | Indicates whether the customer is a senior citizen. | | tenure | Number of months the customer has been with the company. | | MonthlyCharges | Monthly charges incurred by the customer. | | TotalCharges | Total charges incurred by the customer. | | gender | Gender of the customer (Male: 1, Female: 0). | | Partner | Whether the customer has a partner (Yes: 1, No: 0). | | Dependents | Whether the customer has dependents (Yes: 1, No: 0). | | PhoneService | Whether the customer has dependents (Yes: 1, No: 0). | | MultipleLines | Whether the customer has multiple lines (Yes: 1, No: 0). | | InternetService | Type of internet service (No: 1, Other: 0). | | OnlineSecurity | Whether the customer has online security service (Yes: 1, No: 0). | | OnlineBackup | Whether the customer has online backup service (Yes: 1, No: 0). | | DeviceProtection | Whether the customer has device protection service (Yes: 1, No: 0). | | TechSupport | Whether the customer has tech support service (Yes: 1, No: 0). | | StreamingTV | Whether the customer has streaming TV service (Yes: 1, No: 0). | | StreamingMovies | Whether the customer has streaming movies service (Yes: 1, No: 0). | | Contract | Type of contract (One year: 1, Other: 0). | | PaperlessBilling | Whether the customer has paperless billing (Yes: 1, No: 0). | | PaymentMethod | Payment method (Credit card: 1, Other: 0). | | Churn | Whether the customer has churned (Yes: 1, No: 0). | """ ) payment_options = { 2: "Electronic check", 3: "Mailed check", 1: "Bank transfer (automatic)", 0: "Credit card (automatic)" } contract = { 0: "Month-to-month", 2: "Two year", 1: "One year" } def format_func(PaymentMethod): return payment_options[PaymentMethod] def format_func_contract(Contract): return contract[Contract] display = ("male", "female") options = list(range(len(display))) # Define the data columns with their respective values SeniorCitizen = st.selectbox("Are you senior citizen?", options=[True, False],) tenure = st.number_input("Tenure") MonthlyCharges = st.number_input("Monthly Charges: ") TotalCharges = st.number_input("Total Charges: ") gender = st.radio("gender:", options, format_func=lambda x: display[x]) Partner = st.radio("Do you have a partner? ", options=[True, False]) Dependents = st.radio("Dependents: ", options=[True, False]) PhoneService = st.radio("Do you have phone service? : ", options=[True, False]) MultipleLines = st.radio("Do you Multiplines? ", options=[True, False]) InternetService = st.radio("Did you subscribe for Internet service? ", options=[True, False]) OnlineSecurity = st.radio("Did you subscribe for OnlineSecurity? ", options=[True, False]) OnlineBackup = st.radio("Did you subscribe for Online Backup service? ", options=[True, False]) DeviceProtection = st.radio("Did you subscribe for device protection only?", options=[True, False]) TechSupport =st.radio("Did you subscribe for tech support? ", options=[True, False]) StreamingTV = st.radio("Did you subscribe for TV streaming", options=[True, False]) StreamingMovies = st.radio("Did you subscribe for streaming movies? ", options=[True, False]) Contract = st.radio("Duration of contract: ", options=list(contract.keys()), format_func=format_func_contract) PaperlessBilling = st.radio("Do you use paperless billing? ", options=[True, False]) PaymentMethod = st.selectbox("Payment method:", options=list(payment_options.keys()), format_func=format_func) # You can use PaymentMethod to get the selected payment method's numeric value if st.button("Predict"): service = prediction_service_loader( pipeline_name="continuous_deployment_pipeline", pipeline_step_name="mlflow_model_deployer_step", running=False, ) if service is None: st.write( "No service could be found. The pipeline will be run first to create a service." ) run_main() try: data_point = { 'SeniorCitizen': int(SeniorCitizen), 'tenure': tenure, 'MonthlyCharges': MonthlyCharges, 'TotalCharges': TotalCharges, 'gender': int(gender), 'Partner': int(Partner), 'Dependents': int(Dependents), 'PhoneService': int(PhoneService), 'MultipleLines': int(MultipleLines), 'InternetService': int(InternetService), 'OnlineSecurity': int(OnlineSecurity), 'OnlineBackup': int(OnlineBackup), 'DeviceProtection': int(DeviceProtection), 'TechSupport': int(TechSupport), 'StreamingTV': int(StreamingTV), 'StreamingMovies': int(StreamingMovies), 'Contract': int(Contract), 'PaperlessBilling': int(PaperlessBilling), 'PaymentMethod': int(PaymentMethod) } # Convert the data point to a Series and then to a DataFrame data_point_series = pd.Series(data_point) data_point_df = pd.DataFrame(data_point_series).T # Convert the DataFrame to a JSON list json_list = json.loads(data_point_df.to_json(orient="records")) data = np.array(json_list) for i in range(len(data)): logging.info(data[i]) pred = service.predict(data) logging.info(pred) st.success(f"Customer churn prediction: {'Churn' if pred == 1 else 'No Churn'}") except Exception as e: logging.error(e) raise e if __name__ == "__main__": main()Den här koden definierar en StreamLit som kommer att tillhandahålla frontend för att förutsäga kundförlust i ett telekomföretag baserat på kunddata och demografiska detaljer.
Användare kan mata in sin information via ett användarvänligt gränssnitt, och koden använder en utbildad maskininlärningsmodell (distribuerad med ZenML och MLflow) för att göra förutsägelser.
Det förutsagda resultatet visas sedan för användaren.
Kör nu detta kommando:
⚠️ se till att din förutsägelsemodell körs
streamlit run streamlit_app.pyKlicka på länken.
Det är allt; vi har avslutat vårt projekt.

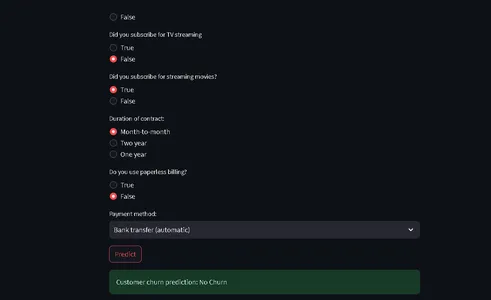
Det är allt; vi har framgångsrikt avslutat vårt maskininlärningsprojekt från slut till slut, hur proffs närmar sig hela processen.
Slutsats
I den här omfattande utforskningen av maskininlärningsoperationer (MLOps) genom utveckling och implementering av en modell för förutsägelse av kundförlust, har vi bevittnat den transformerande kraften hos MLOps när det gäller att effektivisera livscykeln för maskininlärning. Från datainsamling och förbearbetning till modellträning, utvärdering och implementering, vårt projekt visar upp MLO:s viktiga roll för att överbrygga klyftan mellan utveckling och produktion. Eftersom organisationer i allt högre grad förlitar sig på datadrivet beslutsfattande, framhäver de effektiva och skalbara metoder som visas här den avgörande betydelsen av MLO:er för att säkerställa framgången för maskininlärningstillämpningar.
Key Takeaways
- MLOps (Machine Learning Operations) är avgörande för att effektivisera hela livscykeln för maskininlärning, vilket säkerställer effektiv, pålitlig och skalbar verksamhet.
- ZenML och MLflow är kraftfulla ramverk som underlättar utveckling, spårning och distribution av maskininlärningsmodeller i verkliga applikationer.
- Korrekt förbearbetning av data, inklusive rengöring, kodning och delning, är grunden för att bygga robusta maskininlärningsmodeller.
- Utvärderingsmått som noggrannhet, precision, återkallelse och F1-poäng ger en omfattande förståelse av modellens prestanda.
- Experimentspårningsverktyg som MLflow förbättrar samarbete och experimenthantering i datavetenskapliga projekt.
- Kontinuerliga pipelines och slutledningsutbyggnader är avgörande för att upprätthålla modelleffektivitet och tillgänglighet i produktionsmiljöer.
Vanliga frågor
MLOPS betyder Machine Learning Operations är en livscykel för maskininlärning från utveckling till datainsamling. Det är en uppsättning metoder för att designa och automatisera hela maskininlärningscykeln. Den omfattar alla steg, från utveckling och utbildning av modeller för maskininlärning till deras implementering, övervakning och löpande underhåll. MLOps är avgörande eftersom det säkerställer skalbarhet, tillförlitlighet och effektivitet hos maskininlärningsapplikationer. Det hjälper datavetare att skapa robusta maskininlärningsapplikationer som ger korrekta förutsägelser.
MLOps och DevOps har liknande mål att effektivisera och automatisera processer inom sina respektive domäner. DevOps fokuserar främst på mjukvaruutveckling, mjukvaruleveranspipelinen. Det syftar till att påskynda mjukvaruutvecklingen, förbättra kodkvaliteten och förbättra driftsäkerheten. MLOps tillgodoser de specialiserade behoven av maskininlärningsprojekt, vilket gör det till en avgörande praxis att utnyttja AI och datavetenskap.
Detta är ett vanligt fel du kommer att möta i projektet. Bara spring
'zenml ner'
sedan
'zenml koppla bort'
kör rörledningen igen. Det kommer att lösas.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/10/a-mlops-enhanced-customer-churn-prediction-project/

