Beskrivning
I det spännande ämnet datorseende, där bilder innehåller många hemligheter och information, är det avgörande att särskilja och framhäva föremål. Bildsegmentering, processen att dela upp bilder i meningsfulla regioner eller objekt, är väsentlig i olika applikationer, allt från medicinsk bildbehandling till autonom körning och objektigenkänning. Noggrann och automatisk segmentering har länge varit utmanande, med traditionella metoder som ofta saknar precision och effektivitet. Gå in i UNET-arkitekturen, en intelligent metod som har revolutionerat bildsegmenteringen. Med sin enkla design och uppfinningsrika tekniker har UNET banat väg för mer exakta och robusta segmenteringsresultat. Oavsett om du är en nykomling inom det spännande området datorseende eller en erfaren utövare som vill förbättra dina segmenteringsförmåga, kommer denna djupgående bloggartikel att reda ut komplexiteten hos UNET och ge en fullständig förståelse för dess arkitektur, komponenter och användbarhet.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Förstå Convolution Neural Network
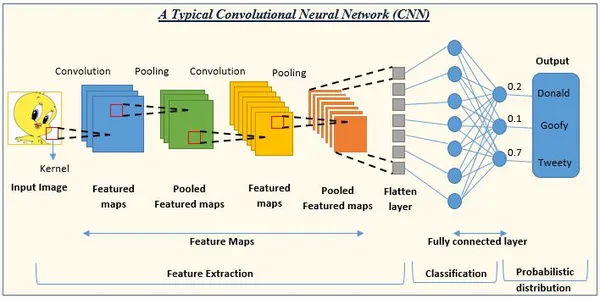
CNN är en modell för djupinlärning som ofta används i datorseendeuppgifter, inklusive bildklassificering, objektigenkänning och bildsegmentering. CNN är främst för att lära sig och extrahera relevant information från bilder, vilket gör dem extremt användbara i visuell dataanalys.
De kritiska komponenterna i CNN
- Konvolutionella lager: CNN:er består av en samling inlärbara filter (kärnor) som är hopkopplade med ingångsbilden eller funktionskartor. Varje filter tillämpar elementvis multiplikation och summering för att producera en funktionskarta som framhäver specifika mönster eller lokala funktioner i inmatningen. Dessa filter kan fånga många visuella element, som kanter, hörn och texturer.
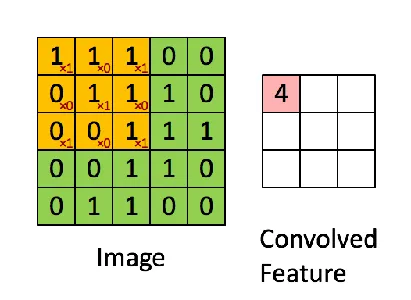
- Samla lager: Skapa funktionskartorna efter de faltningslagren som nedsamplas med hjälp av poollager. Pooling minskar de rumsliga dimensionerna av funktionskartorna samtidigt som den mest kritiska informationen bibehålls, sänker beräkningskomplexiteten för efterföljande lager och gör modellen mer motståndskraftig mot indatafluktuationer. Den vanligaste poolningsoperationen är max pooling, som tar det mest betydande värdet inom en given stadsdel.
- Aktiveringsfunktioner: Introducera icke-linjäriteten i CNN-modellen med hjälp av aktiveringsfunktioner. Tillämpa dem på utdata från faltnings- eller poollager element för element, så att nätverket kan förstå komplicerade associationer och fatta icke-linjära beslut. På grund av dess enkelhet och effektivitet när det gäller att ta itu med problemet med försvinnande gradient, är aktiveringsfunktionen Rectified Linear Unit (ReLU) vanlig i CNN.
- Fullt anslutna lager: Fullständigt anslutna lager, även kallade täta lager, använder de hämtade funktionerna för att slutföra den slutliga klassificeringen eller regressionsoperationen. De kopplar samman varje neuron i ett lager med varje neuron i nästa, vilket gör att nätverket kan lära sig globala representationer och göra bedömningar på hög nivå baserat på de tidigare lagrens kombinerade input.
Nätverket börjar med en bunt faltningslager för att fånga funktioner på låg nivå, följt av poolande lager. Djupare faltningslager lär sig egenskaper på högre nivå när nätverket utvecklas. Använd slutligen ett eller flera fullständiga lager för klassificerings- eller regressionsoperationen.
Behov av ett helt uppkopplat nätverk
Traditionella CNN:er är i allmänhet avsedda för bildklassificeringsjobb där en enda etikett tilldelas hela inmatningsbilden. Å andra sidan har traditionella CNN-arkitekturer problem med finare uppgifter som semantisk segmentering, där varje pixel i en bild måste sorteras i olika klasser eller regioner. Fully Convolutional Networks (FCN) kommer in i bilden här.
Begränsningar för traditionella CNN-arkitekturer i segmenteringsuppgifter
Förlust av rumslig information: Traditionella CNN:er använder poolande lager för att gradvis minska den rumsliga dimensionaliteten hos funktionskartor. Även om denna nedsampling hjälper till att fånga funktioner på hög nivå, resulterar det i förlust av rumslig information, vilket gör det svårt att exakt upptäcka och dela objekt på pixelnivå.
Fast ingångsstorlek: CNN-arkitekturer är ofta byggda för att acceptera bilder av en viss storlek. Ingångsbilderna kan dock ha olika dimensioner i segmenteringsuppgifter, vilket gör indata av varierande storlek utmanande att hantera med typiska CNN.
Begränsad lokaliseringsnoggrannhet: Traditionella CNN använder ofta helt anslutna lager i slutet för att tillhandahålla en utdatavektor med fast storlek för klassificering. Eftersom de inte behåller rumslig information kan de inte exakt lokalisera objekt eller regioner i bilden.
Fully Convolutional Networks (FCN) som en lösning för semantisk segmentering
Genom att enbart arbeta på faltningslager och upprätthålla rumslig information i hela nätverket, adresserar Fully Convolutional Networks (FCN) begränsningarna för klassiska CNN-arkitekturer i segmenteringsuppgifter. FCN är avsedda att göra pixel-för-pixel-förutsägelser, där varje pixel i inmatningsbilden tilldelas en etikett eller klass. FCN möjliggör konstruktionen av en tät segmenteringskarta med pixelnivåprognoser genom att sampla upp funktionskartorna. Transponerade faltningar (även kända som dekonvolutioner eller uppsamplingsskikt) används för att ersätta de helt länkade skikten efter CNN-designen. Den rumsliga upplösningen av funktionskartorna ökas av transponerade faltningar, vilket gör att de kan ha samma storlek som ingångsbilden.
Under uppsampling använder FCN vanligtvis överhoppningsanslutningar, kringgår specifika lager och direkt länkar funktionskartor på lägre nivå med sådana på högre nivå. Dessa överhoppningsrelationer hjälper till att bevara finkorniga detaljer och kontextuell information, vilket ökar de segmenterade regionernas lokaliseringsnoggrannhet. FCN:er är extremt effektiva i olika segmenteringstillämpningar, inklusive medicinsk bildsegmentering, scenanalys och instanssegmentering. Den kan nu hantera ingångsbilder av olika storlekar, tillhandahålla förutsägelser på pixelnivå och behålla rumslig information över nätverket genom att utnyttja FCN:er för semantisk segmentering.
Bildsegmentering
Bildsegmentering är en grundläggande process i dator vision där en bild är uppdelad i många meningsfulla och separata delar eller segment. I motsats till bildklassificering, som ger en enda etikett till en komplett bild, lägger segmentering etiketter till varje pixel eller grupp av pixlar, vilket i huvudsak delar upp bilden i semantiskt signifikanta delar. Bildsegmentering är viktigt eftersom det möjliggör en mer detaljerad förståelse av innehållet i en bild. Vi kan extrahera betydande information om objektgränser, former, storlekar och rumsliga relationer genom att segmentera en bild i flera delar. Denna finkorniga analys är avgörande för olika datorseendeuppgifter, vilket möjliggör förbättrade applikationer och stöder tolkningar av visuella data på högre nivå.

Förstå UNET-arkitekturen
Traditionella bildsegmenteringstekniker, såsom manuell annotering och pixelvis klassificering, har olika nackdelar som gör dem slösaktiga och svåra för exakta och effektiva segmenteringsjobb. På grund av dessa begränsningar, mer avancerade lösningar, såsom UNET arkitektur, har utvecklats. Låt oss titta på bristerna i tidigare sätt och varför UNET skapades för att övervinna dessa problem.
- Manuell anteckning: Manuell anteckning innebär att man skissar och markerar bildgränser eller områden av intresse. Även om denna metod ger tillförlitliga segmenteringsresultat, är den tidskrävande, arbetsintensiv och mottaglig för mänskliga misstag. Manuell anteckning är inte skalbar för stora datamängder, och det är svårt att upprätthålla konsistens och överensstämmelse mellan annotatorerna, särskilt i sofistikerade segmenteringsuppgifter.
- Pixelmässig klassificering: Ett annat vanligt tillvägagångssätt är pixelvis klassificering, där varje pixel i en bild klassificeras oberoende, vanligtvis med hjälp av algoritmer som beslutsträd, stödvektormaskiner (SVM) eller slumpmässiga skogar. Pixel-vis kategorisering, å andra sidan, kämpar för att fånga globala sammanhang och beroenden mellan omgivande pixlar, vilket resulterar i över- eller undersegmenteringsproblem. Den kan inte beakta rumsliga relationer och misslyckas ofta med att erbjuda exakta objektgränser.
Övervinner utmaningar
UNET-arkitekturen utvecklades för att hantera dessa begränsningar och övervinna de utmaningar som traditionella metoder för bildsegmentering står inför. Så här hanterar UNET dessa problem:
- End-to-end-inlärning: UNET använder en end-to-end-inlärningsteknik, vilket innebär att den lär sig att segmentera bilder direkt från input-output-par utan användarkommentarer. UNET kan automatiskt extrahera nyckelfunktioner och utföra exakt segmentering genom att träna på en stor märkt datauppsättning, vilket tar bort behovet av arbetskrävande manuell anteckning.
- Helt konvolutionell arkitektur: UNET är baserat på en helt faltningsarkitektur, vilket innebär att den helt består av faltningslager och inte inkluderar några helt anslutna lager. Denna arkitektur gör det möjligt för UNET att fungera på indatabilder av alla storlekar, vilket ökar dess flexibilitet och anpassningsförmåga till olika segmenteringsuppgifter och inmatningsvariationer.
- U-formad arkitektur med Skip Connections: Nätverkets karakteristiska arkitektur inkluderar en kodningsväg (kontrakterande sökväg) och en avkodningsväg (expanderande sökväg), vilket gör att det kan samla in lokal information och globala sammanhang. Hoppa över anslutningar överbryggar gapet mellan kodnings- och avkodningsvägarna, upprätthåller kritisk information från tidigare lager och möjliggör mer exakt segmentering.
- Kontextuell information och lokalisering: Överhoppningsanslutningarna används av UNET för att aggregera flerskaliga funktionskartor från flera lager, vilket gör att nätverket kan absorbera kontextuell information och fånga detaljer på olika abstraktionsnivåer. Denna informationsintegration förbättrar lokaliseringsnoggrannheten, vilket möjliggör exakta objektgränser och exakta segmenteringsresultat.
- Dataökning och -reglering: UNET använder dataförstärknings- och regleringstekniker för att förbättra sin motståndskraft och generaliseringsförmåga under träning. För att öka mångfalden av träningsdata, innebär dataförstärkning att man lägger till många transformationer till träningsbilderna, såsom rotationer, vändningar, skalning och deformationer. Regulariseringstekniker som bortfall och batchnormalisering förhindrar överanpassning och förbättrar modellens prestanda på okända data.
Översikt över UNET-arkitekturen
UNET är en helt konvolutionell neural nätverksarkitektur (FCN) byggd för bildsegmenteringsapplikationer. Det föreslogs första gången 2015 av Olaf Ronneberger, Philipp Fischer och Thomas Brox. UNET används ofta för sin noggrannhet i bildsegmentering och har blivit ett populärt val i olika medicinska bildbehandlingstillämpningar. UNET kombinerar en kodningsväg, även kallad sammandragningsväg, med en avkodningsväg som kallas expanderande sökväg. Arkitekturen är uppkallad efter dess U-formade utseende när den avbildas i ett diagram. På grund av denna U-formade arkitektur kan nätverket spela in både lokala funktioner och globala sammanhang, vilket resulterar i exakta segmenteringsresultat.
Kritiska komponenter i UNET-arkitekturen
- Kontrakterande sökväg (kodningsväg): UNET:s kontrakteringsväg omfattar faltningslager följt av maxpoolningsoperationer. Den här metoden fångar högupplösta egenskaper på låg nivå genom att gradvis sänka indatabildens rumsliga dimensioner.
- Expanderande sökväg (avkodningsväg): Transponerade faltningar, även kända som dekonvolutioner eller uppsamplingslager, används för uppsampling av funktionskartorna från kodningsvägen i UNET-expansionsvägen. Funktionskartornas rumsliga upplösning ökas under uppsamplingsfasen, vilket gör att nätverket kan rekonstruera en tät segmenteringskarta.
- Hoppa över anslutningar: Skip-anslutningar används i UNET för att ansluta matchande lager från kodnings- till avkodningsvägar. Dessa länkar gör det möjligt för nätverket att samla in både lokal och global data. Nätverket behåller viktig rumslig information och förbättrar segmenteringsnoggrannheten genom att integrera funktionskartor från tidigare lager med de i avkodningsrutten.
- Sammanfogning: Sammankoppling används vanligtvis för att implementera hoppa över anslutningar i UNET. Särdragskartorna från kodningsvägen är sammanlänkade med de uppsamplade särdragskartorna från avkodningsvägen under uppsamplingsproceduren. Denna sammanlänkning gör det möjligt för nätverket att införliva flerskalig information för lämplig segmentering, utnyttja högnivåkontext och lågnivåfunktioner.
- Helt konvolutionerande lager: UNET består av faltningslager utan helt anslutna lager. Denna faltningsarkitektur gör det möjligt för UNET att hantera bilder av obegränsade storlekar samtidigt som den bevarar rumslig information över nätverket, vilket gör det flexibelt och anpassningsbart till olika segmenteringsuppgifter.
Kodningsvägen, eller kontrakteringsvägen, är en viktig komponent i UNET-arkitekturen. Den är ansvarig för att extrahera information på hög nivå från ingångsbilden samtidigt som den gradvis krymper de rumsliga dimensionerna.
Konvolutionella lager
Kodningsprocessen börjar med en uppsättning faltningslager. Konvolutionella lager extraherar information i flera skalor genom att tillämpa en uppsättning inlärningsbara filter på inmatningsbilden. Dessa filter fungerar på det lokala receptiva fältet, vilket gör att nätverket kan fånga rumsliga mönster och mindre funktioner. Med varje faltningslager växer djupet på funktionskartorna, vilket gör att nätverket kan lära sig mer komplicerade representationer.
Aktiveringsfunktion
Efter varje faltningslager appliceras en aktiveringsfunktion såsom Rectified Linear Unit (ReLU) element för element för att inducera icke-linjäritet i nätverket. Aktiveringsfunktionen hjälper nätverket att lära sig icke-linjära korrelationer mellan inmatade bilder och hämtade funktioner.
Samla lager
Poolningsskikt används efter faltningsskikten för att minska särdragskartornas rumsliga dimensionalitet. Åtgärderna, som t.ex. maximal pooling, delar in kartor i områden som inte överlappar varandra och behåller endast det maximala värdet inom varje zon. Det minskar den rumsliga upplösningen genom att sampla ned funktionskartor, vilket gör att nätverket kan fånga mer abstrakt och högre nivå av data.
Kodningsvägens uppgift är att fånga funktioner i olika skalor och abstraktionsnivåer på ett hierarkiskt sätt. Kodningsprocessen fokuserar på att extrahera globalt sammanhang och information på hög nivå när de rumsliga dimensionerna minskar.
Hoppa över anslutningar
Tillgängligheten av överhoppningsanslutningar som förbinder lämpliga nivåer från kodningsvägen till avkodningsvägen är en av UNET-arkitekturens utmärkande egenskaper. Dessa överhoppningslänkar är avgörande för att behålla nyckeldata under kodningsprocessen.
Funktionskartor från tidigare lager samlar in lokala detaljer och finkornig information under kodningsvägen. Dessa särdragskartor är sammanlänkade med de uppsamplade särdragskartorna i avkodningspipelinen som använder överhoppningsanslutningar. Detta gör det möjligt för nätverket att integrera flerskalig data, lågnivåfunktioner och högnivåkontext i segmenteringsprocessen.
Genom att bevara rumslig information från tidigare lager kan UNET på ett tillförlitligt sätt lokalisera objekt och behålla finare detaljer i segmenteringsresultat. UNETs överhoppningsanslutningar hjälper till att lösa problemet med informationsförlust orsakad av nedsampling. Överhoppningslänkarna möjliggör mer utmärkt lokal och global informationsintegration, vilket förbättrar segmenteringsprestanda totalt sett.
Sammanfattningsvis är UNET-kodningsmetoden avgörande för att fånga egenskaper på hög nivå och sänka indatabildens rumsliga dimensioner. Kodningsvägen extraherar progressivt abstrakta representationer via faltningslager, aktiveringsfunktioner och poollager. Genom att integrera lokala funktioner och globala kontexter möjliggör införandet av hoppa över länkar för att bevara kritisk rumslig information, vilket underlättar tillförlitliga segmenteringsresultat.
Avkodningsväg i UNET
En kritisk komponent i UNET-arkitekturen är avkodningsvägen, även känd som den expanderande sökvägen. Det är ansvarigt för att sampla upp kodningsvägens funktionskartor och konstruera den slutliga segmenteringsmasken.
Uppsampling av lager (transponerade faltningar)
För att öka den rumsliga upplösningen av funktionskartorna inkluderar UNET-avkodningsmetoden uppsamplingslager, ofta gjorda med hjälp av transponerade faltningar eller dekonvolutioner. Transponerade veck är i huvudsak motsatsen till vanliga veck. De förbättrar rumsliga dimensioner snarare än minskar dem, vilket möjliggör uppsampling. Genom att konstruera en gles kärna och applicera den på indatakartan, lär sig transponerade faltningar att upsampla funktionskartorna. Nätverket lär sig att fylla i luckorna mellan de aktuella rumsliga platserna under denna process, vilket ökar upplösningen på funktionskartorna.
sammanlänkning
Funktionskartorna från de föregående skikten är sammanlänkade med de uppsamplade särdragskartorna under avkodningsfasen. Denna sammanlänkning gör det möjligt för nätverket att aggregera multi-skala information för korrekt segmentering, utnyttja högnivåkontext och lågnivåfunktioner. Bortsett från uppsampling inkluderar UNET-avkodningsvägen överhoppningsanslutningar från kodningsvägens jämförbara nivåer.
Nätverket kan återställa och integrera finkorniga egenskaper som förlorats under kodning genom att sammanfoga funktionskartor från överhoppningsanslutningar. Det möjliggör mer exakt objektlokalisering och avgränsning i segmenteringsmasken.
Avkodningsprocessen i UNET rekonstruerar en tät segmenteringskarta som passar med den rumsliga upplösningen för ingångsbilden genom att progressivt upsampla funktionskartorna och inkludera hoppa över länkar.
Avkodningsvägens funktion är att återställa rumslig information som förlorats under kodningsvägen och förfina segmenteringsresultaten. Den kombinerar lågnivåkodningsdetaljer med högnivåkontext från uppsamplingsskikten för att ge en exakt och grundlig segmenteringsmask.
UNET kan öka den rumsliga upplösningen av funktionskartorna genom att använda transponerade faltningar i avkodningsprocessen, och därigenom uppsampla dem för att matcha den ursprungliga bildstorleken. Transponerade faltningar hjälper nätverket att generera en tät och finkornig segmenteringsmask genom att lära sig att fylla i luckorna och utöka de rumsliga dimensionerna.
Sammanfattningsvis rekonstruerar avkodningsprocessen i UNET segmenteringsmasken genom att förbättra den rumsliga upplösningen av funktionskartorna via uppsamplingslager och överhoppningsanslutningar. Transponerade faltningar är kritiska i denna fas eftersom de tillåter nätverket att sampla funktionskartorna och bygga en detaljerad segmenteringsmask som matchar den ursprungliga ingångsbilden.
Kontrakterande och expanderande vägar i UNET
UNET-arkitekturen följer en "encoder-decoder"-struktur, där den kontrakterande sökvägen representerar kodaren och den expanderande sökvägen representerar avkodaren. Denna design liknar kodning av information till en komprimerad form och sedan avkodning av den för att rekonstruera originaldata.
Kontraktsväg (kodare)
Kodaren i UNET är kontraktsvägen. Det extraherar sammanhanget och komprimerar inmatningsbilden genom att gradvis minska de rumsliga dimensionerna. Denna metod inkluderar faltningslager följt av poolningsprocedurer som maxpoolning för att nedsampla funktionskartorna. Kontraktsvägen är ansvarig för att erhålla egenskaper på hög nivå, lära sig globala sammanhang och minska rumslig upplösning. Den fokuserar på att komprimera och abstrahera ingångsbilden, och effektivt fånga relevant information för segmentering.
Expanderande sökväg (avkodare)
Avkodaren i UNET är den expanderande sökvägen. Genom att sampla upp särdragskartorna från sammandragningsvägen, återvinner den rumslig information och genererar den slutliga segmenteringskartan. Den expanderande rutten innefattar uppsamplingslager, ofta utförda med transponerade faltningar eller dekonvolutioner för att öka den rumsliga upplösningen av särdragskartorna. Den expanderande banan rekonstruerar de ursprungliga rumsliga dimensionerna via överhoppningsförbindelser genom att integrera de uppsamplade funktionskartorna med motsvarande kartor från den sammandragande banan. Denna metod gör det möjligt för nätverket att återställa finkorniga funktioner och korrekt lokalisera objekt.
UNET-designen fångar globala sammanhang och lokala detaljer genom att blanda kontrakterande och expanderande vägar. Den sammandragande banan komprimerar ingångsbilden till en kompakt representation, beslutat att bygga en detaljerad segmenteringskarta av den expanderande banan. Den expanderande vägen avser avkodning av den komprimerade representationen till en tät och exakt segmenteringskarta. Den rekonstruerar den saknade rumsliga informationen och förfinar segmenteringsresultaten. Denna kodare-avkodarstruktur möjliggör precisionssegmentering med hjälp av högnivåkontext och finkornig rumslig information.
Sammanfattningsvis liknar UNET:s kontrakterande och expanderande rutter en "encoder-decoder"-struktur. Den expanderande vägen är avkodaren, som återvinner rumslig information och genererar den slutliga segmenteringskartan. Däremot fungerar den sammandragande banan som kodare, fångar sammanhang och komprimerar inmatningsbilden. Denna arkitektur gör det möjligt för UNET att koda och avkoda information effektivt, vilket möjliggör noggrann och grundlig bildsegmentering.
Hoppa över anslutningar i UNET
Hoppa över anslutningar är väsentliga för UNET-designen eftersom de tillåter information att färdas mellan de sammandragande (kodnings-) och expanderande (avkodnings-) vägarna. De är avgörande för att upprätthålla rumslig information och förbättra segmenteringsnoggrannheten.
Bevara rumslig information
Viss rumslig information kan gå förlorad under kodningsvägen eftersom funktionskartorna genomgår nedsamplingsprocedurer såsom maxpooling. Denna informationsförlust kan leda till lägre lokaliseringsnoggrannhet och förlust av finkorniga detaljer i segmenteringsmasken.
Genom att upprätta direkta kopplingar mellan motsvarande lager i kodnings- och avkodningsprocesserna hjälper hoppa över anslutningar till att lösa detta problem. Hoppa över anslutningar skyddar viktig rumslig information som annars skulle gå förlorad under nedsampling. Dessa anslutningar tillåter information från kodningsströmmen att undvika nedsampling och överförs direkt till avkodningsvägen.
Multi-scale Information Fusion
Hoppa över anslutningar möjliggör sammanslagning av flerskalig information från många nätverkslager. Senare nivåer av kodningsprocessen fångar kontext och semantisk information på hög nivå, medan tidigare lager fångar upp lokala detaljer och finkornig information. UNET kan framgångsrikt kombinera lokal och global information genom att koppla dessa funktionskartor från kodningsvägen till motsvarande lager i avkodningsvägen. Denna integrering av flerskalig information förbättrar segmenteringsnoggrannheten totalt sett. Nätverket kan använda lågnivådata från kodningsvägen för att förfina segmenteringsfynd i avkodningsvägen, vilket möjliggör mer exakt lokalisering och bättre objektgränsavgränsning.
Kombinera högnivåkontext och lågnivådetaljer
Hoppa över anslutningar gör att avkodningsvägen kan kombinera högnivåkontext och lågnivådetaljer. De sammanlänkade särdragskartorna från överhoppningsanslutningarna inkluderar avkodningsvägens uppsamplade särdragskartor och kodningsvägens särdragskartor.
Denna kombination gör det möjligt för nätverket att dra fördel av högnivåkontexten som registrerats i avkodningsvägen och de finkorniga funktionerna som fångas i kodningsvägen. Nätverket kan innehålla information av flera storlekar, vilket möjliggör en mer exakt och detaljerad segmentering.
UNET kan dra nytta av flerskalig information, bevara rumsliga detaljer och slå samman högnivåkontext med lågnivådetaljer genom att lägga till överhoppningsanslutningar. Som ett resultat förbättras segmenteringsnoggrannheten, objektlokaliseringen förbättras och finkornig information i segmenteringsmasken behålls.
Sammanfattningsvis, hoppa över anslutningar i UNET är avgörande för att upprätthålla rumslig information, integrera flerskalig information och öka segmenteringsnoggrannheten. De ger ett direkt informationsflöde över kodnings- och avkodningsvägarna, vilket gör att nätverket kan samla in lokala och globala detaljer, vilket resulterar i mer exakt och detaljerad bildsegmentering.
Förlustfunktion i UNET
Det är viktigt att välja en lämplig förlustfunktion när du tränar UNET och optimerar dess parametrar för bildsegmenteringsuppgifter. UNET använder ofta segmenteringsvänliga förlustfunktioner som tärningskoefficienten eller korsentropiförlust.
Tärningskoefficientförlust
Tärningskoefficienten är en likhetsstatistik som beräknar överlappningen mellan de förväntade och sanna segmenteringsmaskerna. Tärningskoefficientförlusten, eller mjuktärningsförlust, beräknas genom att subtrahera en från tärningskoefficienten. När de förväntade och markerade sanningsmaskerna överensstämmer väl, minimeras förlusten, vilket resulterar i en högre tärningskoefficient.
Tärningskoefficientförlusten är särskilt effektiv för obalanserade datauppsättningar där bakgrundsklassen har många pixlar. Genom att bestraffa falska positiva och falska negativa, främjar det nätverket att dela upp både förgrunds- och bakgrundsregioner korrekt.
Cross-Entropy Förlust
Använd kors-entropiförlustfunktion i bildsegmenteringsuppgifter. Den mäter olikheten mellan de förutspådda klasssannolikheterna och marksanningsetiketterna. Behandla varje pixel som ett oberoende klassificeringsproblem i bildsegmentering, och korsentropiförlusten beräknas pixelvis.
Korsentropiförlusten uppmuntrar nätverket att tilldela hög sannolikhet till rätt klassetiketter för varje pixel. Det straffar avvikelser från grundsanningen och främjar korrekta segmenteringsresultat. Denna förlustfunktion är effektiv när förgrunds- och bakgrundsklasserna är balanserade eller när flera klasser är involverade i segmenteringsuppgiften.
Valet mellan tärningskoefficientförlust och korsentropiförlust beror på segmenteringsuppgiftens specifika krav och datasetets egenskaper. Båda förlustfunktionerna har fördelar och kan kombineras eller skräddarsys utifrån specifika behov.
1: Importera bibliotek
import tensorflow as tf
import os
import numpy as np
from tqdm import tqdm
from skimage.io import imread, imshow
from skimage.transform import resize
import matplotlib.pyplot as plt
import random2: Bildmått – Inställningar
IMG_WIDTH = 128
IMG_HEIGHT = 128
IMG_CHANNELS = 33: Ställa in slumpmässigheten
seed = 42
np.random.seed = seed4: Importera datamängden
# Data downloaded from - https://www.kaggle.com/competitions/data-science-bowl-2018/data #importing datasets
TRAIN_PATH = 'stage1_train/'
TEST_PATH = 'stage1_test/'5: Läser alla bilder som finns i undermappen
train_ids = next(os.walk(TRAIN_PATH))[1]
test_ids = next(os.walk(TEST_PATH))[1]6: Träning
X_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)7: Ändra storlek på bilderna
print('Resizing training images and masks')
for n, id_ in tqdm(enumerate(train_ids), total=len(train_ids)): path = TRAIN_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_train[n] = img #Fill empty X_train with values from img mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool) for mask_file in next(os.walk(path + '/masks/'))[2]: mask_ = imread(path + '/masks/' + mask_file) mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True), axis=-1) mask = np.maximum(mask, mask_) Y_train[n] = mask 8: Testa bilderna
# test images
X_test = np.zeros((len(test_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
sizes_test = []
print('Resizing test images') for n, id_ in tqdm(enumerate(test_ids), total=len(test_ids)): path = TEST_PATH + id_ img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS] sizes_test.append([img.shape[0], img.shape[1]]) img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True) X_test[n] = img print('Done!')9: Slumpmässig kontroll av bilderna
image_x = random.randint(0, len(train_ids))
imshow(X_train[image_x])
plt.show()
imshow(np.squeeze(Y_train[image_x]))
plt.show()10: Bygga modellen
inputs = tf.keras.layers.Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = tf.keras.layers.Lambda(lambda x: x / 255)(inputs)11: stigar
#Contraction path
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(s)
c1 = tf.keras.layers.Dropout(0.1)(c1)
c1 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c1)
p1 = tf.keras.layers.MaxPooling2D((2, 2))(c1) c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p1)
c2 = tf.keras.layers.Dropout(0.1)(c2)
c2 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c2)
p2 = tf.keras.layers.MaxPooling2D((2, 2))(c2) c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p2)
c3 = tf.keras.layers.Dropout(0.2)(c3)
c3 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c3)
p3 = tf.keras.layers.MaxPooling2D((2, 2))(c3) c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p3)
c4 = tf.keras.layers.Dropout(0.2)(c4)
c4 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c4)
p4 = tf.keras.layers.MaxPooling2D(pool_size=(2, 2))(c4) c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(p4)
c5 = tf.keras.layers.Dropout(0.3)(c5)
c5 = tf.keras.layers.Conv2D(256, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c5)12: Expansionsvägar
u6 = tf.keras.layers.Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(c5)
u6 = tf.keras.layers.concatenate([u6, c4])
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u6)
c6 = tf.keras.layers.Dropout(0.2)(c6)
c6 = tf.keras.layers.Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c6) u7 = tf.keras.layers.Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(c6)
u7 = tf.keras.layers.concatenate([u7, c3])
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u7)
c7 = tf.keras.layers.Dropout(0.2)(c7)
c7 = tf.keras.layers.Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c7) u8 = tf.keras.layers.Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same')(c7)
u8 = tf.keras.layers.concatenate([u8, c2])
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u8)
c8 = tf.keras.layers.Dropout(0.1)(c8)
c8 = tf.keras.layers.Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c8) u9 = tf.keras.layers.Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same')(c8)
u9 = tf.keras.layers.concatenate([u9, c1], axis=3)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(u9)
c9 = tf.keras.layers.Dropout(0.1)(c9)
c9 = tf.keras.layers.Conv2D(16, (3, 3), activation='relu', kernel_initializer='he_normal', padding='same')(c9)13: Utgångar
outputs = tf.keras.layers.Conv2D(1, (1, 1), activation='sigmoid')(c9)14: Sammanfattning
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()15: Modellkontrollpunkt
checkpointer = tf.keras.callbacks.ModelCheckpoint('model_for_nuclei.h5', verbose=1, save_best_only=True) callbacks = [ tf.keras.callbacks.EarlyStopping(patience=2, monitor='val_loss'), tf.keras.callbacks.TensorBoard(log_dir='logs')] results = model.fit(X_train, Y_train, validation_split=0.1, batch_size=16, epochs=25, callbacks=callbacks)16: Sista etappen – Förutsägelse
idx = random.randint(0, len(X_train)) preds_train = model.predict(X_train[:int(X_train.shape[0]*0.9)], verbose=1)
preds_val = model.predict(X_train[int(X_train.shape[0]*0.9):], verbose=1)
preds_test = model.predict(X_test, verbose=1) preds_train_t = (preds_train > 0.5).astype(np.uint8)
preds_val_t = (preds_val > 0.5).astype(np.uint8)
preds_test_t = (preds_test > 0.5).astype(np.uint8) # Perform a sanity check on some random training samples
ix = random.randint(0, len(preds_train_t))
imshow(X_train[ix])
plt.show()
imshow(np.squeeze(Y_train[ix]))
plt.show()
imshow(np.squeeze(preds_train_t[ix]))
plt.show() # Perform a sanity check on some random validation samples
ix = random.randint(0, len(preds_val_t))
imshow(X_train[int(X_train.shape[0]*0.9):][ix])
plt.show()
imshow(np.squeeze(Y_train[int(Y_train.shape[0]*0.9):][ix]))
plt.show()
imshow(np.squeeze(preds_val_t[ix]))
plt.show()Slutsats
I det här omfattande blogginlägget har vi tagit upp UNET-arkitekturen för bildsegmentering. Genom att ta itu med begränsningarna i tidigare metoder har UNET-arkitekturen revolutionerat bildsegmenteringen. Dess kodnings- och avkodningsrutter, hoppa över anslutningar och andra modifieringar, såsom U-Net++, Attention U-Net och Dense U-Net, har visat sig vara mycket effektiva för att fånga sammanhang, bibehålla rumslig information och öka segmenteringsnoggrannheten. Potentialen för exakt och automatisk segmentering med UNET erbjuder nya vägar för att förbättra datorseendet och mer. Vi uppmuntrar läsarna att lära sig mer om UNET och experimentera med dess implementering för att maximera dess användbarhet i sina bildsegmenteringsprojekt.
Key Takeaways
1. Bildsegmentering är väsentligt i datorseende uppgifter, vilket möjliggör uppdelning av bilder i meningsfulla regioner eller objekt.
2. Traditionella tillvägagångssätt för bildsegmentering, såsom manuell anteckning och pixelvis klassificering, har begränsningar vad gäller effektivitet och noggrannhet.
3. Utveckla UNET-arkitekturen för att hantera dessa begränsningar och uppnå korrekta segmenteringsresultat.
4. Det är ett helt konvolutionellt neuralt nätverk (FCN) som kombinerar en kodningsväg för att fånga funktioner på hög nivå och en avkodningsmetod för att generera segmenteringsmasken.
5. Hoppa över anslutningar i UNET bevara rumslig information, förbättra funktionsutbredning och förbättra segmenteringsnoggrannheten.
6. Hittade framgångsrika tillämpningar inom medicinsk bildbehandling, satellitbildsanalys och industriell kvalitetskontroll, vilket uppnådde anmärkningsvärda riktmärken och erkännande i tävlingar.
Vanliga frågor
S. U-Net-arkitekturen är en populär CNN-arkitektur (convolutional neural network) som är vanlig för bildsegmenteringsuppgifter. Ursprungligen utvecklad för biomedicinsk bildsegmentering, har den sedan dess hittat tillämpningar inom olika domäner. U-Net-arkitekturen hanterar lokal och global information och har en U-formad encoder-decoder-struktur.
A. U-Net-arkitekturen består av en kodarväg och en avkodarväg. Kodarvägen minskar gradvis de rumsliga dimensionerna för ingångsbilden samtidigt som antalet funktionskanaler ökar. Detta hjälper till att extrahera abstrakta funktioner på hög nivå. Avkodarvägen utför uppsamplings- och sammanlänkningsoperationer. Och återställ de rumsliga dimensionerna samtidigt som du minskar antalet funktionskanaler. Nätverket lär sig att kombinera lågnivåfunktionerna från kodarvägen med högnivåfunktionerna från avkodarvägen för att generera segmenteringsmasker.
S. U-Net-arkitekturen erbjuder flera fördelar för bildsegmenteringsuppgifter. För det första tillåter dess U-formade design att kombinera lågnivå- och högnivåfunktioner, vilket möjliggör bättre lokalisering av objekt. För det andra hjälper hoppkopplingarna mellan kodaren och avkodarvägarna till att bevara rumslig information, vilket möjliggör mer exakt segmentering. Slutligen har U-Net-arkitekturen ett relativt litet antal parametrar, vilket gör den mer beräkningseffektiv än andra arkitekturer.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/08/unet-architecture-mastering-image-segmentation/

