Beskrivning
Vektordatabaser har blivit den bästa platsen för lagring och indexering av representationer av ostrukturerad och strukturerad data. Dessa representationer är de vektorinbäddningar som genereras av inbäddningsmodellerna. Vektorbutikerna har blivit en integrerad del av att utveckla appar med Deep Learning Models, speciellt de stora språkmodellerna. I det ständigt föränderliga landskapet av Vector Stores är Qdrant en sådan Vector Database som har introducerats nyligen och är full av funktioner. Låt oss dyka in och lära oss mer om det.
Inlärningsmål
- Bekanta dig med Qdrant-terminologierna för att bättre förstå den
- Dyka in i Qdrant Cloud och skapa kluster
- Lär dig att skapa inbäddningar av våra dokument och lagra dem i Qdrant Collections
- Utforska hur frågan fungerar i Qdrant
- Träna med filtreringen i Qdrant för att kontrollera hur det fungerar
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Vad är inbäddningar?
Vektorinbäddningar är ett sätt att uttrycka data i numerisk form – det vill säga som tal i ett n-dimensionellt utrymme, eller som en numerisk vektor – oavsett typ av data – text, foton, ljud, videor etc. Inbäddningar gör det möjligt för oss att gruppera relaterade data på detta sätt. Vissa indata kan omvandlas till vektorer med hjälp av vissa modeller. En välkänd inbäddningsmodell skapad av Google som översätter ord till vektorer (vektorer är punkter med n dimensioner) kallas Word2Vec. Var och en av de stora språkmodellerna har en inbäddningsmodell som genererar en inbäddning för LLM.
Vad används inbäddningar till?
En fördel med att översätta ord till vektorer är att de möjliggör jämförelse. När två ord ges som numeriska inmatningar, eller vektorinbäddningar, kan en dator jämföra dem även om den inte kan jämföra dem direkt. Det är möjligt att gruppera ord med jämförbara inbäddningar. Eftersom de är släkt med varandra kommer termerna kung, drottning, prins och prinsessa att dyka upp i ett kluster.
I denna mening hjälper inbäddningar oss att hitta ord som är relaterade till en given term. Detta kan användas i meningar, där vi skriver in en mening, och den tillhandahållna informationen returnerar relaterade meningar. Detta fungerar som grunden för många användningsfall, inklusive chatbots, meningslikhet, avvikelsedetektering och semantisk sökning. Chatbotarna som vi utvecklar för att svara på frågor baserade på en PDF eller ett dokument som vi tillhandahåller använder sig av detta inbäddningsbegrepp. Denna metod används av alla generativa stora språkmodeller för att erhålla innehåll som på liknande sätt är kopplat till de frågor som tillhandahålls dem.
Vad är vektordatabaser?
Som diskuterats är inbäddningar representationer av alla typer av data vanligtvis, de ostrukturerade i det numeriska formatet i ett n-dimensionellt utrymme. Var förvarar vi dem nu? Traditionella RDMS (Relational Database Management Systems) kan inte användas för att lagra dessa vektorinbäddningar. Det är här Vector Store / Vector Dabases kommer in i bilden. Vektordatabaser är utformade för att lagra och hämta vektorinbäddningar på ett effektivt sätt. Det finns många Vector Stores där ute, som skiljer sig åt beroende på vilka inbäddningsmodeller de stöder och vilken typ av sökalgoritm de använder för att få liknande vektorer.
Vad är Qdrant?
Qdrant är den nya Vector Similarity Search Engine och en Vector DB, som tillhandahåller en produktionsklar tjänst byggd i Rust, språket känt för sin säkerhet. Qdrant kommer med ett användarvänligt API designat för att lagra, söka och hantera högdimensionella punkter (punkter är inget annat än vektorinbäddningar) berikad med metadata som kallas nyttolaster. Dessa nyttolaster blir värdefulla delar av information, förbättrar sökprecisionen och ger användarna insiktsfulla data. Om du är bekant med andra vektordatabaser som Chroma, liknar Payload metadata, den innehåller information om vektorerna.
Att vara skrivet i Rust gör Qdrant till en snabb och pålitlig Vectore Store även under tung belastning. Det som skiljer Qdrant från de andra databaserna är antalet klient-API:er den tillhandahåller. För närvarande stöder Qdrant Python, TypeSciprt/JavaScript, Rust och Go. Det följer med. Qdrant använder HSNW (Hierarchical Navigable Small World Graph) för vektorindexering och kommer med många avståndsmått som Cosinus, Dot och Euclidian. Den levereras med ett rekommendations-API direkt ur lådan.
Känn till Qdrant-terminologin
För att få en smidig start med Qdrant är det bra att bekanta sig med terminologin / huvudkomponenterna som används i Qdrant Vector Database.
Kollektioner
Samlingar är namngivna uppsättningar av poäng, där varje punkt innehåller en vektor och ett valfritt ID och nyttolast. Vektorer i samma samling måste dela samma dimensionalitet och utvärderas med en enda vald måttenhet.
Avståndsmått
Viktigt för att mäta hur nära vektorerna är varandra, avståndsmått väljs under skapandet av en samling. Qdrant tillhandahåller följande avståndsmått: Punkt, Cosinus och Euklidisk.
Poäng
Den grundläggande enheten inom Qdrant, poäng består av en vektorinbäddning, ett valfritt ID och en tillhörande nyttolast, där
id: En unik identifierare för varje vektorinbäddning
vektor: En högdimensionell representation av data, som kan vara antingen strukturerade eller ostrukturerade format som bilder, text, dokument, PDF-filer, videor, ljud etc.
nyttolast: Ett valfritt JSON-objekt som innehåller data kopplade till en vektor. Detta kan anses likna metadata och vi kan arbeta med detta för att filtrera sökprocessen
lagring
Qdrant erbjuder två lagringsalternativ:
- Lagring i minnet: Lagrar alla vektorer i RAM, optimerar hastigheten genom att minimera diskåtkomst till beständighetsuppgifter.
- Memmap lagring: Skapar ett virtuellt adressutrymme länkat till en fil på disken, balanserar hastighet och beständighetskrav.
Det här är huvudkoncepten som vi måste vara medvetna om så att vi snabbt kan komma igång med Qdrant
Qdrant Cloud – Skapar vårt första kluster
Qdrant tillhandahåller en skalbar molntjänst för lagring och hantering av vektorer. Det ger till och med ett gratis forever 1GB-kluster utan kreditkortsinformation. I det här avsnittet kommer vi att gå igenom processen att skapa ett konto med Qdrant Cloud och skapa vårt första kluster.
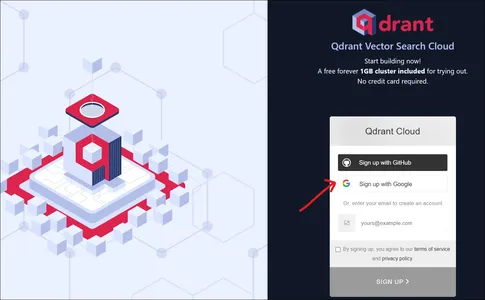
Genom att gå till Qdrants webbplats kommer vi att skapa en målsida som ovan. Vi kan registrera oss för Qdrant antingen med ett Google-konto eller med ett GitHub-konto.
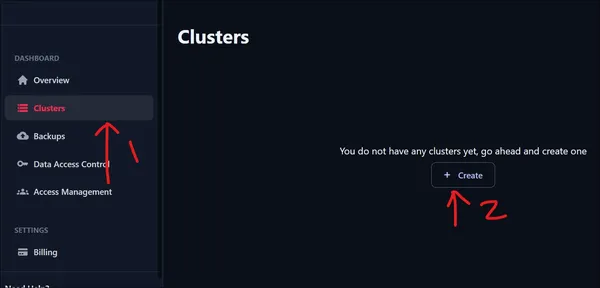
Efter att ha loggat in kommer vi att presenteras med UI som visas ovan. För att skapa ett kluster, gå till den vänstra rutan och klicka på alternativet Kluster under instrumentpanelen. Eftersom vi precis har loggat in har vi noll kluster. Klicka på Skapa kluster för att skapa ett nytt kluster.
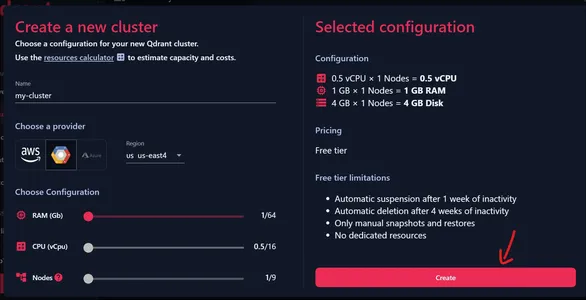
Nu kan vi ge ett namn för vårt kluster. Se till att ha alla konfigurationer inställda på startpositionen, eftersom detta ger oss ett gratis kluster. Vi kan välja en av leverantörerna som visas ovan och välja en av regionerna som är kopplade till den.
Kontrollera den aktuella konfigurationen
Vi kan se den aktuella konfigurationen till vänster, dvs 0.5 vCPU, 1 GB RAM och 4 GB disklagring. Klicka på Skapa för att skapa vårt kluster.
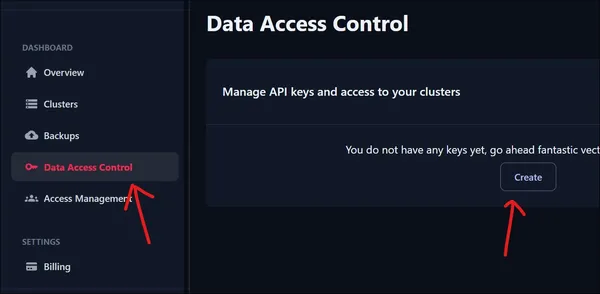
För att komma åt vårt nyskapade kluster behöver vi en API-nyckel. För att skapa en ny API-nyckel, gå till Data Access Control under instrumentpanelen. Klicka på knappen Skapa för att skapa en ny API-nyckel.

Som visas ovan kommer vi att presenteras med en rullgardinsmeny där vi väljer vilket kluster vi behöver skapa API för. Eftersom vi bara har ett kluster väljer vi det och klickar på OK-knappen.
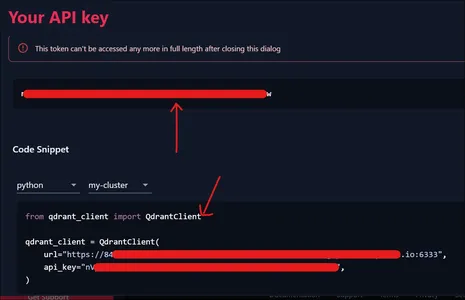
Sedan kommer du att presentera API-tokenet som visas ovan. Om vi ser nedanstående del av bilden, förses vi även med kodavsnittet för att ansluta vårt kluster, som vi kommer att använda i nästa avsnitt.
Qdrant – Hands On
I det här avsnittet kommer vi att arbeta med Qdrant Vector Database. Först börjar vi med att importera de nödvändiga biblioteken.
!pip install sentence-transformers
!pip install qdrant_clientDen första raden installerar satstransformatorns Python-bibliotek. Meningstransformatorbiblioteket används för att skapa menings-, text- och bildinbäddningar. Vi kan använda det här biblioteket för att importera olika inbäddningsmodeller för att skapa inbäddningar. Nästa programsats installerar qdrant-klienten för Python. Låt oss börja med att skapa vår kund.
from qdrant_client import QdrantClient
client = QdrantClient(
url="YOUR CLUSTER URL",
api_key="YOUR API KEY",
)
QdrantClient
I ovanstående instansierar vi klient genom att importera QdrantClient klass och ger klustrets URL och API-nyckel som vi skapade för ett tag sedan. Därefter kommer vi att ta in vår inbäddningsmodell.
# bringing in our embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')I ovanstående kod har vi använt SentenceTransformer klass och instansierade en modell. Inbäddningsmodellen vi har tagit är all-mpnet-base-v2. Detta är en allmänt populär vektorinbäddningsmodell för allmänt bruk. Denna modell tar in text och matar ut en 768-dimensionell vektor. Låt oss definiera vår data.
# data
documents = [
"""Elephants, the largest land mammals, exhibit remarkable intelligence and
social bonds, relying on their powerful trunks for communication and various
tasks like lifting objects and gathering food.""",
""" Penguins, flightless birds adapted to life in the water, showcase strong
social structures and exceptional parenting skills. Their sleek bodies
enable efficient swimming, and they endure
harsh Antarctic conditions in tightly-knit colonies. """,
"""Cars, versatile modes of transportation, come in various shapes and
sizes, from compact city cars to powerful sports vehicles, offering a
range of features for different preferences and needs.""",
"""Motorbikes, nimble two-wheeled machines, provide a thrilling and
liberating riding experience, appealing to enthusiasts who appreciate
speed, agility, and the open road.""",
"""Tigers, majestic big cats, are solitary hunters with distinctive
striped fur. Their powerful build and stealthy movements make them
formidable predators, but their populations are threatened
due to habitat loss and poaching."""
]
I ovanstående har vi en variabel som kallas dokument och den innehåller en lista med 5 strängar (låt oss ta var och en av dem som ett enda dokument). Varje datasträng är relaterad till ett visst ämne. Vissa data är relaterade till element och vissa data är relaterade till bilar. Låt oss skapa inbäddningar för data.
# embedding the data
embeddings = model.encode(documents)
print(embeddings.shape)Vi använder koda() modellobjektets funktion för att koda våra data. För att koda skickar vi dokumentlistan direkt till koda() funktion och lagra de resulterande vektorinbäddningarna i inbäddningsvariabeln. Vi skriver till och med ut formen på inbäddningarna, som här kommer att tryckas (5, 768). Detta beror på att vi har 5 datapunkter, det vill säga 5 dokument och för varje dokument skapas en vektorinbäddning av 768 dimensioner.
Skapa din samling
Nu ska vi skapa vår samling.
from qdrant_client.http.models import VectorParams, Distance
client.create_collection(
collection_name = "my-collection",
vectors_config = VectorParams(size=768,distance=Distance.COSINE)
)
- För att skapa en samling arbetar vi med funktionen create_collection() för klientobjektet och till "Collection_name", vi skickar in vårt samlingsnamn dvs "min-samling"
- VectorParams: Denna klass från qdrant är för vektorkonfiguration, som vad är storleken på vektorinbäddningen, vad är avståndsmåttet och sådant
- Distans: Denna klass från qdrant är för att definiera vilket avståndsmått som ska användas för att fråga vektorer
- Nu till vector_config variabel vi passerar vår Configuration, det vill säga storleken på vektorinbäddningar, dvs 786, och avståndsmåttet vi vill använda, vilket är COSINUS
Lägg till vektorinbäddningar
Vi har nu framgångsrikt skapat vår samling. Nu kommer vi att lägga till våra vektorinbäddningar till denna samling.
from qdrant_client.http.models import Batch
client.upsert (
collection_name = "my-collection",
points = Batch(
ids = [1,2,3,4,5],
payloads= [
{"category":"animals"},
{"category":"animals"},
{"category":"automobiles"},
{"category":"automobiles"},
{"category":"animals"}
],
vectors = embeddings.tolist()
)
)
- För att lägga till data till qdrant kallar vi för upsert() metod och skicka in samlingens namn och poäng. Som vi har lärt oss ovan, a Punkt består av vektorer, ett valfritt index och nyttolaster. De Sats Klass från qdrant låter oss lägga till data i omgångar istället för att lägga till dem en efter en.
- ids: Vi ger våra dokument ett ID. För närvarande ger vi en rad värden från 1 till 5 eftersom vi har 5 dokument på vår lista.
- nyttolaster: Som vi har sett tidigare, den nyttolast innehåller information om vektorerna, som metadata. Vi tillhandahåller det i nyckel-värdepar. För varje dokument har vi tillhandahållit en nyttolast här tilldelar vi kategoriinformation för varje dokument.
- vektorer: Dessa är vektorinbäddningar av dokumenten. Vi konverterar den till en lista från en numpy array och matar den.
Så efter att ha kört den här koden läggs vektorinbäddningarna till i samlingen. För att kontrollera om de har lagts till kan vi besöka molnets instrumentpanel som Qdrant Cloud tillhandahåller. För det gör vi följande:
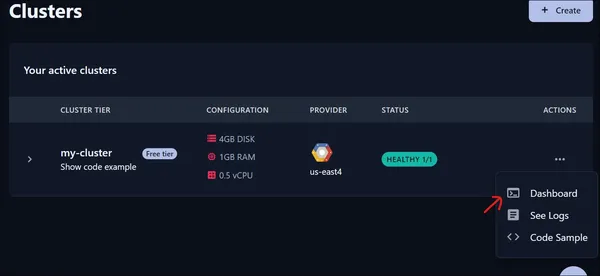
Vi klickar på instrumentpanelen och sedan öppnas en ny sida.
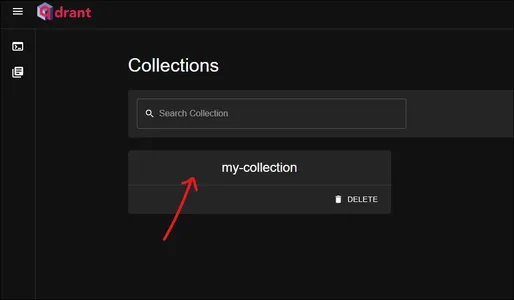
Detta är qdrant-instrumentpanelen. Kolla vår "min samling" samling här. Klicka på den för att se vad den innehåller.

I Qdrant-molnet observerar vi att våra poäng (vektorer + nyttolast + ID) verkligen lägger till vår samling inom vårt kluster. I uppföljningsavsnittet kommer vi att lära oss hur man frågar dessa vektorer.
Frågar Qdrant Vector Database
I det här avsnittet kommer vi att gå igenom frågan om vektordatabasen och till och med försöka lägga till några filter för att få ett filtrerat resultat. För att fråga vår qdrant-vektordatabas måste vi först skapa en frågevektor, vilket vi kan göra genom att:
query = model.encode(['Animals live in the forest'])Fråga inbäddning
Följande kommer att skapa vår fråga inbäddning. Med hjälp av detta kommer vi att fråga vår vektorbutik för att få de mest relevanta vektorinbäddningarna.
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 4
)
Sök fråga
För att fråga använder vi Sök() metod för klientobjektet och skicka det följande:
- Collection_name: Namnet på vår samling
- fråga_vektor: Frågevektorn som vi vill söka i vektorlagret på
- begränsa: Hur många sökutgångar vill vi ha Sök() funktion för att begränsa också
Att köra koden kommer att producera följande utdata:
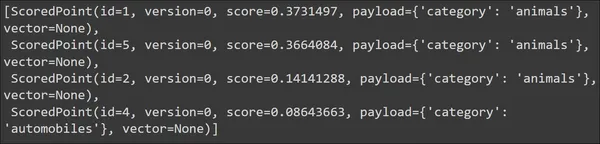
Vi ser att för vår fråga är de mest hämtade dokumenten av kategorin djur. Därför kan vi säga att sökningen är effektiv. Låt oss nu prova det med någon annan fråga så att den ger oss andra resultat. Vektorerna visas/hämtas inte som standard, därför är den inställd på Ingen.
query = model.encode(['Vehicles are polluting the world'])
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 3
)

Fråga relaterad till fordon
Den här gången har vi gett en fråga relaterade till fordon vektordatabasen kunde framgångsrikt hämta dokumenten i den relevanta kategorin (bil) överst. Vad händer nu om vi vill göra lite filtrering? Vi kan göra detta genom att:
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
query = model.encode(['Animals live in the forest'])
custom_filter = Filter(
must = [
FieldCondition(
key = "category",
match = MatchValue(
value="animals"
),
)
]
)
- För det första skapar vi vår sökinbäddning/vektor
- Här importerar vi Filter, Fältskickoch MatchVärde klasser från qdrant-biblioteket.
- Filter: Använd den här klassen för att skapa ett filterobjekt
- Arkiverat skick: Den här klassen är till för att skapa filtrering, som på vad vi vill filtrera vår sökning
- MatchVärde: Den här klassen är till för att tala om vilket värde för en given nyckel vi vill att qdrantvektorn db ska filtrera
Så i ovanstående kod säger vi i princip att vi skapar en Filter som kontrollerar Fältskick att nyckeln "kategori"I nyttolast tändstickor(MatchVärde) värdet "djur”. Det här ser lite stort ut för ett enkelt filter, men detta tillvägagångssätt kommer att göra vår kod mer strukturerad när vi har att göra med en nyttolast innehåller mycket information och vi vill filtrera på flera nycklar. Låt oss nu använda filtret i vår sökning.
client.search(
collection_name = "my-collection",
query_vector = query[0],
query_filter = custom_filter,
limit = 4
)
Fråga_filter
Här, den här gången, ger vi till och med efter en fråga_filter variabel som tar in Anpassat filter som vi har definierat. Observera att vi har hållit en gräns på 4 för att hämta de 4 översta matchande dokumenten. Frågan är relaterad till djur. Att köra koden kommer att resultera i följande utdata:

I utgången har vi bara fått de 3 närmaste dokumenten även om vi har 5 dokument. Detta beror på att vi har ställt in vårt filter för att endast välja djurkategorierna och det finns bara 3 dokument med den kategorin. På så sätt kan vi lagra vektorinbäddningarna i qdrantmolnet, utföra vektorsökning på dessa inbäddningsvektorer, hämta de närmaste och till och med använda filter för att filtrera utdata:
Applikationer
Följande applikationer kan Qdrant Vector Database:
- Rekommendationssystem: Qdrant kan driva rekommendationsmotorer genom att effektivt matcha högdimensionella vektorer, vilket gör den lämplig för personliga innehållsrekommendationer på plattformar som streamingtjänster, e-handel eller sociala medier.
- Bild- och multimediahämtning: Genom att utnyttja Qdrants förmåga att hantera vektorer som representerar bilder och multimediainnehåll kan applikationer implementera effektiva sök- och hämtningsfunktioner för bilddatabaser eller multimediaarkiv.
- Natural Language Processing (NLP)-applikationer: Qdrants stöd för vektorinbäddningar gör det värdefullt för NLP-uppgifter, som semantisk sökning, matchning av dokumentlikheter och innehållsrekommendationer i applikationer som hanterar stora mängder textdatauppsättningar.
- Anomalidetektering: Qdrants högdimensionella vektorsökning kan arbetas i anomalidetekteringssystem. Genom att jämföra vektorer som representerar normalt beteende mot inkommande data, kan anomalier identifieras inom områden som nätverkssäkerhet eller industriell övervakning.
- Produktsökning och matchning: I e-handelsplattformar kan Qdrant förbättra produktsökningskapaciteten genom att matcha vektorer som representerar produktegenskaper, vilket underlättar korrekta och effektiva produktrekommendationer baserat på användarpreferenser.
- Innehållsbaserad filtrering i sociala nätverk: Qdrants vektorsökning kan användas i sociala nätverk för innehållsbaserad filtrering. Användare kan få relevant innehåll baserat på likheten mellan vektorrepresentationer, vilket förbättrar användarens engagemang.
Slutsats
När efterfrågan på effektiv representation av data växer framstår Qdrant som en Open Source-funktionsspäckad sökmotor för vektorlikhet, skriven i det robusta och säkerhetscentrerade språket Rust. Qdrant innehåller alla populära avståndsmått och ger ett robust sätt att filtrera vår vektorsökning. Med sina rika funktioner, molnbaserad arkitektur och robusta terminologi öppnar Qdrant dörrar till en ny era inom vektorlikhetssökningsteknologi. Även om det är nytt på området tillhandahåller det klientbibliotek för många programmeringsspråk och tillhandahåller ett moln som skalas effektivt med storlek.
Key Takeaways
Några av de viktigaste takeaways inkluderar:
- Tillverkad i rost säkerställer Qdrant både hastighet och tillförlitlighet, även under tung belastning, vilket gör det till det bästa valet för högpresterande vektorbutiker.
- Det som skiljer Qdrant åt är dess stöd för klient-API:er, som vänder sig till utvecklare i Python, TypeScript/JavaScript, Rust och Go.
- Qdrant utnyttjar HSNW-algoritmen och ger olika avståndsmått, inklusive Dot, Cosinus och Euclidian, vilket ger utvecklare möjlighet att välja måtten som passar deras specifika användningsfall.
- Qdrant övergår sömlöst till molnet med en skalbar molntjänst, vilket ger ett gratisalternativ för utforskning. Dess molnbaserade arkitektur säkerställer optimal prestanda, oavsett datavolym.
Vanliga frågor
S: Qdrant är en sökmotor för vektorlikhet och vektorbutik skriven i Rust. Den utmärker sig för sin hastighet, tillförlitlighet och rika klientstöd, och tillhandahåller API:er för Python, TypeScript/JavaScript, Rust och Go.
S: Qdrant använder HSNW-algoritmen och ger olika avståndsmått som Dot, Cosinus och Euclidian. Utvecklare kan välja det mått som passar deras specifika användningsfall när de skapar samlingar.
S: Viktiga komponenter inkluderar samlingar, avståndsmått, poäng (vektorer, valfria ID:n och nyttolaster) och lagringsalternativ (in-memory och memmap).
S: Ja, Qdrant integreras sömlöst med molntjänster, vilket ger en skalbar molnlösning. Den molnbaserade arkitekturen säkerställer optimal prestanda, vilket gör att den ändras till varierande datavolymer och beräkningsbehov.
S: Qdrant tillåter filtrering genom nyttolastinformation. Användare kan definiera filter med Qdrant-biblioteket genom att ge villkor baserade på nyttolastnycklar och värden för att förfina sökresultaten.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/11/a-deep-dive-into-qdrant-the-rust-based-vector-database/

