ZOO Digital tillhandahåller end-to-end lokalisering och mediatjänster för att anpassa original-TV- och filminnehåll till olika språk, regioner och kulturer. Det gör globaliseringen enklare för världens bästa innehållsskapare. Pålitlig av de största namnen inom underhållning, ZOO Digital levererar högkvalitativa lokaliserings- och medietjänster i stor skala, inklusive dubbning, undertextning, skript och efterlevnad.
Typiska lokaliseringsarbetsflöden kräver manuell högtalardiarisering, där en ljudström segmenteras baserat på högtalarens identitet. Denna tidskrävande process måste slutföras innan innehåll kan dubbas till ett annat språk. Med manuella metoder kan en 30-minuters episod ta mellan 1–3 timmar att lokalisera. Genom automatisering siktar ZOO Digital på att uppnå lokalisering på under 30 minuter.
I det här inlägget diskuterar vi implementering av modeller för skalbar maskininlärning (ML) för att diarieisera medieinnehåll med hjälp av Amazon SageMaker, med fokus på WhisperX modell.
Bakgrund
ZOO Digitals vision är att tillhandahålla en snabbare vändning av lokaliserat innehåll. Detta mål är flaskhalsade av den manuellt intensiva karaktären av övningen som förvärras av den lilla personalstyrkan av skickliga personer som kan lokalisera innehåll manuellt. ZOO Digital arbetar med över 11,000 600 frilansare och lokaliserade över 2022 miljoner ord bara under XNUMX. Utbudet av kvalificerade personer överträffas dock av den ökande efterfrågan på innehåll, vilket kräver automatisering för att hjälpa till med lokaliseringsarbetsflöden.
I syfte att påskynda lokaliseringen av innehållsarbetsflöden genom maskininlärning, engagerade ZOO Digital AWS Prototyping, ett investeringsprogram från AWS för att sambygga arbetsbelastningar med kunder. Engagemanget fokuserade på att leverera en funktionell lösning för lokaliseringsprocessen, samtidigt som den gav praktisk utbildning till ZOO Digital-utvecklare på SageMaker, Amazon Transcribeoch Amazon Translate.
Kundutmaning
Efter att en titel (en film eller ett avsnitt av en TV-serie) har transkriberats, måste högtalare tilldelas varje segment av tal så att de korrekt kan tilldelas röstartisterna som är castade för att spela karaktärerna. Denna process kallas högtalardiarisering. ZOO Digital står inför utmaningen att diarieföra innehåll i stor skala samtidigt som det är ekonomiskt lönsamt.
Lösningsöversikt
I denna prototyp lagrade vi de ursprungliga mediefilerna i en specificerad Amazon enkel lagringstjänst (Amazon S3) hink. Denna S3-bucket konfigurerades för att avge en händelse när nya filer upptäcks i den, vilket utlöser en AWS Lambda fungera. För instruktioner om hur du konfigurerar denna utlösare, se handledningen Använda en Amazon S3-utlösare för att anropa en Lambda-funktion. Därefter anropade Lambda-funktionen SageMaker-slutpunkten för slutledning med hjälp av Boto3 SageMaker Runtime-klient.
Smakämnen WhisperX modell, baserad på OpenAIs Whisper, utför transkriptioner och diarieföring för mediatillgångar. Den är byggd på Snabbare Whisper återimplementering, erbjuder upp till fyra gånger snabbare transkription med förbättrad tidsstämpeljustering på ordnivå jämfört med Whisper. Dessutom introducerar den högtalardiarisering, som inte finns i den ursprungliga Whisper-modellen. WhisperX använder Whisper-modellen för transkriptioner, den Wav2Vec2 modell för att förbättra tidsstämpeljusteringen (säkerställa synkronisering av transkriberad text med ljudtidsstämplar), och pyannot modell för diarisering. FFmpeg används för att ladda ljud från källmedia, som stöder olika medieformat. Den transparenta och modulära modellarkitekturen tillåter flexibilitet, eftersom varje komponent i modellen kan bytas ut efter behov i framtiden. Det är dock viktigt att notera att WhisperX saknar fullständiga hanteringsfunktioner och inte är en produkt på företagsnivå. Utan underhåll och support kanske det inte är lämpligt för produktionsinstallation.
I detta samarbete har vi distribuerat och utvärderat WhisperX på SageMaker, med hjälp av en endpoint för asynkron slutledning att vara värd för modellen. SageMaker asynkrona ändpunkter stöder uppladdningsstorlekar på upp till 1 GB och innehåller funktioner för automatisk skalning som effektivt dämpar trafikspikar och sparar kostnader under lågtrafik. Asynkrona slutpunkter är särskilt väl lämpade för bearbetning av stora filer, såsom filmer och TV-serier i vårt användningsfall.
Följande diagram illustrerar kärnelementen i de experiment vi genomförde i detta samarbete.

I de följande avsnitten fördjupar vi oss i detaljerna kring implementeringen av WhisperX-modellen på SageMaker, och utvärderar diariseringsprestandan.
Ladda ner modellen och dess komponenter
WhisperX är ett system som inkluderar flera modeller för transkription, påtvingad anpassning och diarisering. För smidig SageMaker-drift utan att behöva hämta modellartefakter under slutledning, är det viktigt att förnedladda alla modellartefakter. Dessa artefakter laddas sedan i SageMaker serveringsbehållare under initiering. Eftersom dessa modeller inte är direkt tillgängliga erbjuder vi beskrivningar och exempelkod från WhisperX-källan, och ger instruktioner om hur du laddar ner modellen och dess komponenter.
WhisperX använder sex modeller:
De flesta av dessa modeller kan erhållas från Kramande ansikte använder huggingface_hub-biblioteket. Vi använder följande download_hf_model() funktion för att hämta dessa modellartefakter. En åtkomsttoken från Hugging Face, genererad efter att ha accepterat användaravtalen för följande pyannote-modeller, krävs:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
VAD-modellen hämtas från Amazon S3 och Wav2Vec2-modellen hämtas från modulen torchaudio.pipelines. Baserat på följande kod kan vi hämta alla modellers artefakter, inklusive de från Hugging Face, och spara dem i den angivna lokala modellkatalogen:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Välj lämplig AWS Deep Learning Container för att betjäna modellen
Efter att modellartefakterna har sparats med hjälp av föregående exempelkod kan du välja förbyggd AWS Deep Learning-behållare (DLC) från följande GitHub repo. När du väljer Docker-bilden, överväg följande inställningar: ramverk (Kramande ansikte), uppgift (inferens), Python-version och hårdvara (till exempel GPU). Vi rekommenderar att du använder följande bild: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Den här bilden har alla nödvändiga systempaket förinstallerade, såsom ffmpeg. Kom ihåg att ersätta [REGION] med den AWS-region du använder.
För andra nödvändiga Python-paket, skapa en requirements.txt fil med en lista över paket och deras versioner. Dessa paket kommer att installeras när AWS DLC byggs. Följande är de extra paket som behövs för att vara värd för WhisperX-modellen på SageMaker:
Skapa ett inferensskript för att ladda modellerna och köra inferens
Därefter skapar vi en anpassad inference.py skript för att beskriva hur WhisperX-modellen och dess komponenter laddas in i behållaren och hur slutledningsprocessen ska köras. Skriptet innehåller två funktioner: model_fn och transform_fn. De model_fn funktionen anropas för att ladda modellerna från deras respektive platser. Därefter överförs dessa modeller till transform_fn funktion under inferens, där transkriptions-, anpassnings- och diariseringsprocesser utförs. Följande är ett kodexempel för inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
Inom modellens katalog, bredvid requirements.txt fil, säkerställa närvaron av inference.py i en kodunderkatalog. De models katalogen ska likna följande:
Skapa en tarball av modellerna
När du har skapat modellerna och kodkatalogerna kan du använda följande kommandorader för att komprimera modellen till en tarball (.tar.gz-fil) och ladda upp den till Amazon S3. I skrivande stund, med den snabbare viskande Large V2-modellen, är den resulterande tarballen som representerar SageMaker-modellen 3 GB stor. För mer information, se Modellvärdsmönster i Amazon SageMaker, del 2: Komma igång med att distribuera realtidsmodeller på SageMaker.
Skapa en SageMaker-modell och distribuera en slutpunkt med en asynkron prediktor
Nu kan du skapa SageMaker-modellen, endpoint config och asynkron endpoint med AsyncPredictor använda modellen tarball som skapades i föregående steg. För instruktioner, se Skapa en asynkron slutpunkt för slutledning.
Utvärdera diariseringsprestanda
För att bedöma prestandan för WhisperX-modellen i olika scenarier valde vi ut tre avsnitt vardera från två engelska titlar: en dramatitel bestående av 30-minutersavsnitt och en dokumentärtitel bestående av 45-minutersavsnitt. Vi använde Pyannotes mätverktyg, pyannote.metrics, för att beräkna diariseringsfelfrekvens (DER). I utvärderingen fungerade manuellt transkriberade och diarieförda avskrifter från ZOO som grundsanningen.
Vi definierade DER enligt följande:
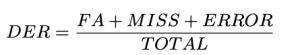
Totalt är längden på jorden sanningsvideo. FA (Falskt larm) är längden på segment som betraktas som tal i förutsägelser, men inte i sanning. Fröken är längden på segment som betraktas som tal i grundsanning, men inte i förutsägelse. Fel, Även kallad Förvirring, är längden på segment som tilldelas olika talare i förutsägelse och grundsanning. Alla enheter mäts i sekunder. De typiska värdena för DER kan variera beroende på den specifika applikationen, datasetet och kvaliteten på diariseringssystemet. Observera att DER kan vara större än 1.0. En lägre DER är bättre.
För att kunna beräkna DER för ett stycke media krävs en grundsanningsdiarisering samt WhisperX transkriberade och diariserade utdata. Dessa måste analyseras och resultera i listor med tupler som innehåller en högtalaretikett, starttid för talsegment och sluttid för talsegment för varje talsegment i media. Högtalaretiketterna behöver inte matcha mellan WhisperX- och grundsannningsdiariserna. Resultaten baseras till största delen på tidpunkten för segmenten. pyannote.metrics tar dessa tuplar av grundsanningsdiariseringar och utdatadiarier (refereras till i dokumentationen för pyannote.metrics som referens och hypotes) för att beräkna DER. Följande tabell sammanfattar våra resultat.
| Videotyp | DER | Correct | Fröken | Fel | Falskt alarm |
| Drama | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Dokumentär | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Genomsnitt | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Dessa resultat avslöjar en betydande prestandaskillnad mellan dramatitlarna och dokumentärtitlarna, där modellen uppnår avsevärt bättre resultat (med DER som ett aggregerat mått) för dramaavsnitten jämfört med dokumentärtiteln. En närmare analys av titlarna ger insikter i potentiella faktorer som bidrar till denna prestandagap. En nyckelfaktor kan vara den frekventa närvaron av bakgrundsmusik som överlappar tal i dokumentärens titel. Även om förbearbetning av media för att förbättra diaariseringsnoggrannheten, såsom att ta bort bakgrundsljud för att isolera tal, låg utanför ramen för denna prototyp, öppnar det vägar för framtida arbete som potentiellt skulle kunna förbättra prestandan hos WhisperX.
Slutsats
I det här inlägget utforskade vi samarbetspartnerskapet mellan AWS och ZOO Digital, med hjälp av maskininlärningstekniker med SageMaker och WhisperX-modellen för att förbättra arbetsflödet för diarisering. AWS-teamet spelade en avgörande roll för att hjälpa ZOO med prototyper, utvärdering och förståelse av den effektiva implementeringen av anpassade ML-modeller, speciellt utformade för diaarisering. Detta inkluderade automatisk skalning för skalbarhet med SageMaker.
Att utnyttja AI för diarisering kommer att leda till avsevärda besparingar i både kostnad och tid vid generering av lokaliserat innehåll för ZOO. Genom att hjälpa transkriberare att snabbt och exakt skapa och identifiera högtalare, tar denna teknik upp den traditionellt tidskrävande och felbenägna karaktären av uppgiften. Den konventionella processen involverar ofta flera genomgångar av videon och ytterligare kvalitetskontrollsteg för att minimera fel. Antagandet av AI för diarisering möjliggör ett mer riktat och effektivt tillvägagångssätt, vilket ökar produktiviteten inom en kortare tidsram.
Vi har beskrivit viktiga steg för att distribuera WhisperX-modellen på SageMaker asynkrona slutpunkt, och uppmuntrar dig att prova det själv med den medföljande koden. För ytterligare insikter om ZOO Digitals tjänster och teknik, besök ZOO Digitals officiella webbplats. Mer information om hur OpenAI Whisper-modellen används på SageMaker och olika slutledningsalternativ finns i Värd för Whisper Model på Amazon SageMaker: utforska inferensalternativ. Dela gärna dina tankar i kommentarerna.
Om författarna
 Ying Hou, PhD, är Machine Learning Prototyping Architect på AWS. Hennes primära intresseområden omfattar Deep Learning, med fokus på GenAI, Computer Vision, NLP och förutsägelse av tidsseriedata. På fritiden njuter hon av att tillbringa kvalitetsstunder med sin familj, fördjupa sig i romaner och vandra i Storbritanniens nationalparker.
Ying Hou, PhD, är Machine Learning Prototyping Architect på AWS. Hennes primära intresseområden omfattar Deep Learning, med fokus på GenAI, Computer Vision, NLP och förutsägelse av tidsseriedata. På fritiden njuter hon av att tillbringa kvalitetsstunder med sin familj, fördjupa sig i romaner och vandra i Storbritanniens nationalparker.
 Ethan Cumberland är AI-forskningsingenjör på ZOO Digital, där han arbetar med att använda AI och Machine Learning som hjälpmedel för att förbättra arbetsflöden i tal, språk och lokalisering. Han har en bakgrund inom mjukvaruteknik och forskning inom säkerhets- och polisdomänen, med fokus på att extrahera strukturerad information från webben och utnyttja ML-modeller med öppen källkod för att analysera och berika insamlad data.
Ethan Cumberland är AI-forskningsingenjör på ZOO Digital, där han arbetar med att använda AI och Machine Learning som hjälpmedel för att förbättra arbetsflöden i tal, språk och lokalisering. Han har en bakgrund inom mjukvaruteknik och forskning inom säkerhets- och polisdomänen, med fokus på att extrahera strukturerad information från webben och utnyttja ML-modeller med öppen källkod för att analysera och berika insamlad data.
 Gaurav Kaila leder AWS Prototyping-teamet för Storbritannien och Irland. Hans team arbetar med kunder i olika branscher för att skapa idéer och samutveckla affärskritiska arbetsbelastningar med mandat att påskynda införandet av AWS-tjänster.
Gaurav Kaila leder AWS Prototyping-teamet för Storbritannien och Irland. Hans team arbetar med kunder i olika branscher för att skapa idéer och samutveckla affärskritiska arbetsbelastningar med mandat att påskynda införandet av AWS-tjänster.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

