Bild från Bing Image Creator
Vem har inte varit road av tekniska framsteg, särskilt inom artificiell intelligens, från Alexa till Tesla självkörande bilar och en myriad andra innovationer? Jag förundras över framstegen varannan dag, men det som är ännu mer intressant är när du får en uppfattning om vad som ligger till grund för dessa innovationer. Välkommen till Artificiell intelligens och till de oändliga möjligheterna djupt lärande. Om du har undrat vad det är, då är du hemma.
I den här handledningen kommer jag att dekonstruera terminologin och ta dig igenom hur du utför en djupinlärningsuppgift i R. För att notera kommer den här artikeln att anta att du har en viss grundläggande förståelse för maskininlärning begrepp som regression, klassificering och klustring.
Låt oss börja med definitioner av några terminologier kring begreppet djupinlärning:
Djup lärning är en gren av maskininlärning som lär datorer att efterlikna den mänskliga hjärnans kognitiva funktioner. Detta uppnås genom användning av artificiella neurala nätverk som hjälper till att packa upp komplexa mönster i datamängder. Med djupinlärning kan en dator klassificera ljud, bilder eller till och med texter.
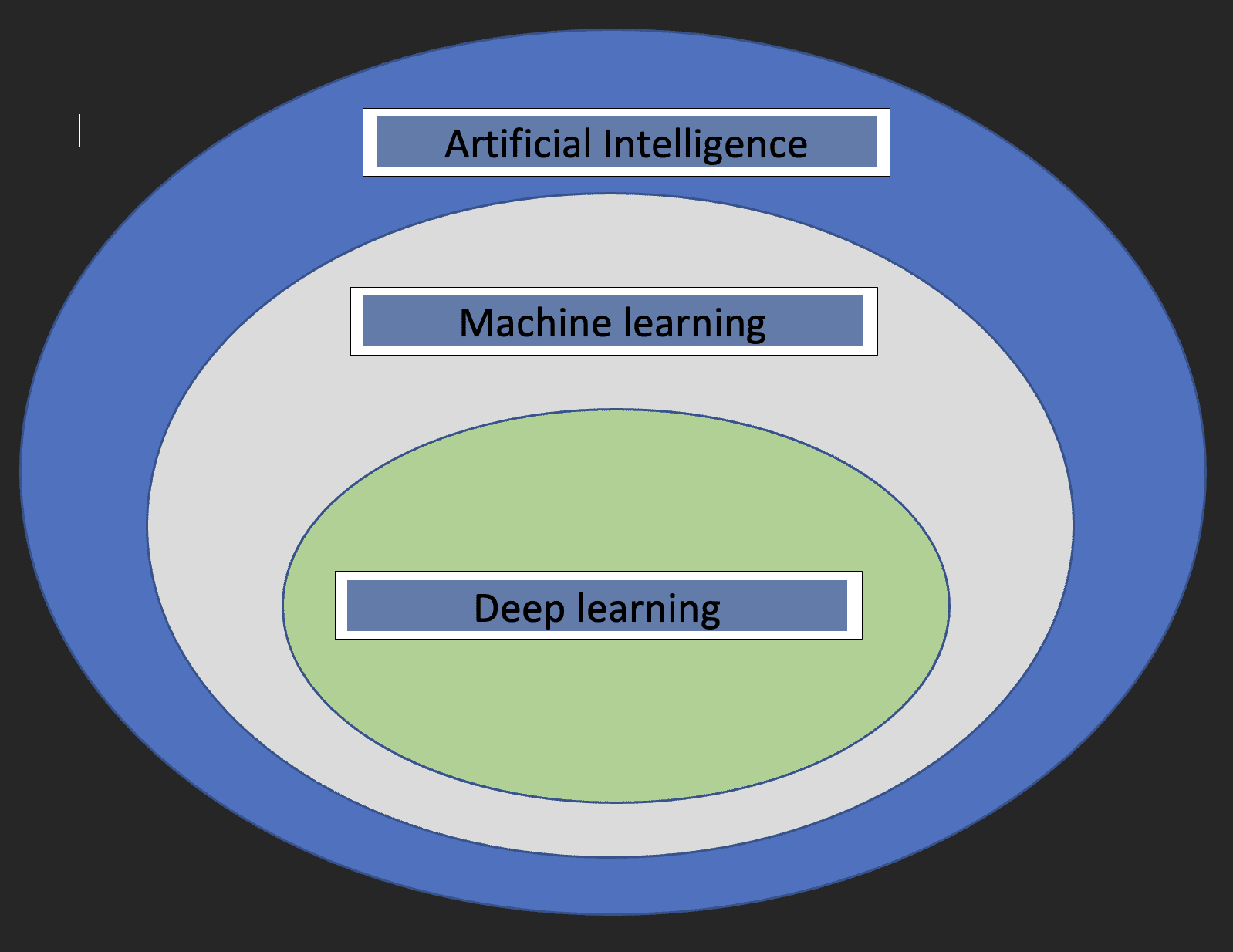
Innan vi dyker in i detaljerna kring Deep learning skulle det vara trevligt att förstå vad maskininlärning och artificiell intelligens är och hur de tre begreppen relaterar till varandra.
Artificiell intelligens: Detta är en gren av datavetenskap som sysslar med utvecklingen av maskiner vars funktion efterliknar den mänskliga hjärnan.
Maskininlärning: Detta är en delmängd av artificiell intelligens som gör det möjligt för datorer att lära sig av data.
Med ovanstående definitioner har vi nu en uppfattning om hur djupinlärning relaterar till artificiell intelligens och maskininlärning.
Diagrammet nedan hjälper till att visa förhållandet.
Två viktiga saker att notera om djupinlärning är:
- Kräver enorma mängder data
- Kräver högpresterande datorkraft
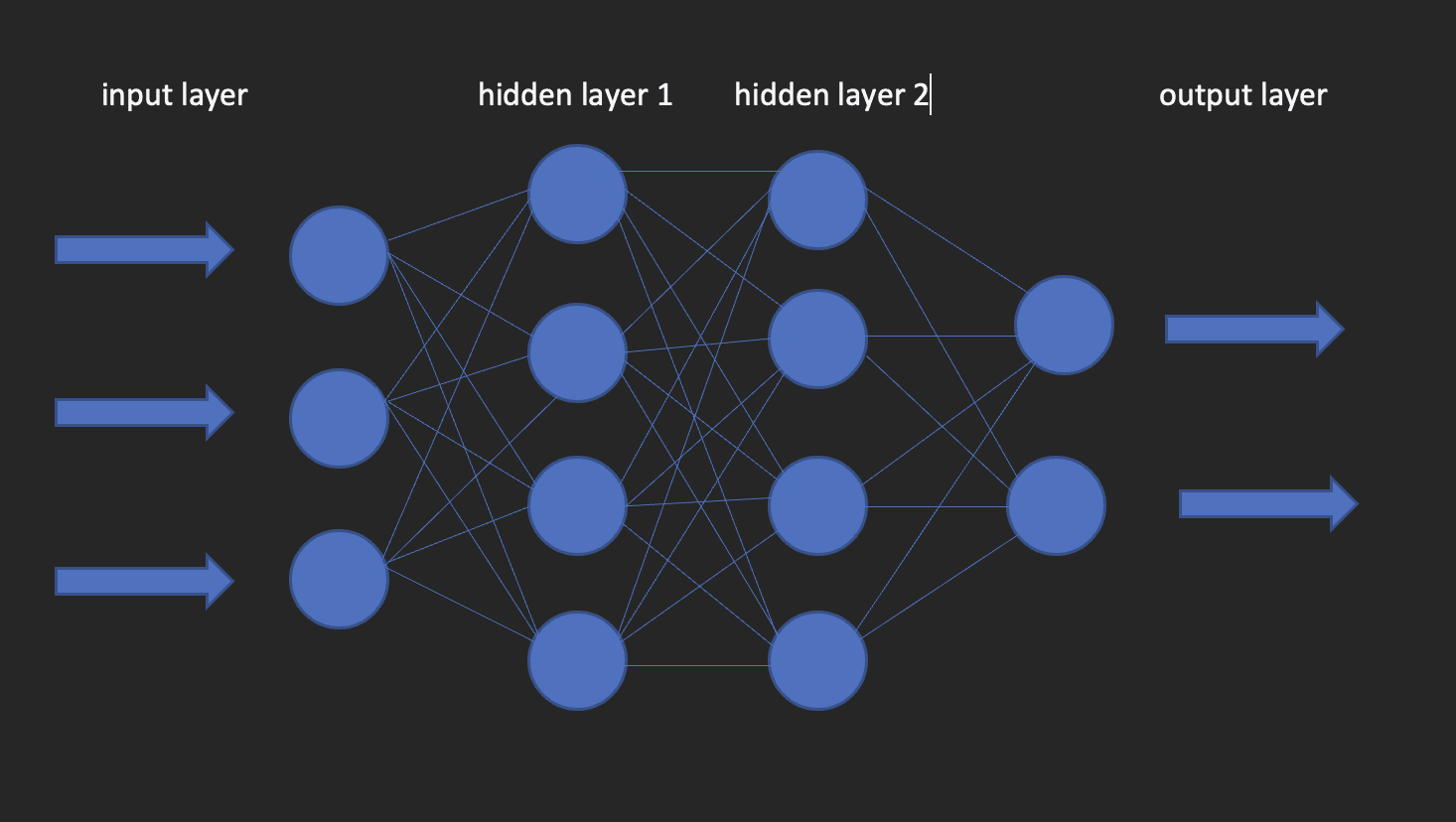
Dessa är byggstenarna i modeller för djupinlärning. Som namnet antyder kommer ordet neural från neuroner, precis som nervcellerna i den mänskliga hjärnan. Egentligen hämtar arkitekturen av djupa neurala nätverk sin inspiration från strukturen i den mänskliga hjärnan.
Ett neuralt nätverk har ett indatalager, ett dolt lager och ett utdatalager. Detta nätverk kallas ett grunt neuralt nätverk. När vi har mer än ett dolt lager blir det ett djupt neuralt nätverk, där lagren kan vara så många som 100-tal.
Bilden nedan visar hur ett neuralt nätverk ser ut.
Detta för oss till frågan om hur man bygger modeller för djupinlärning i R? Gå in i kera!
Keras är ett djupinlärningsbibliotek med öppen källkod som gör det enkelt att använda neurala nätverk i maskininlärning. Detta bibliotek är ett omslag som använder TensorFlow som en backend-motor. Det finns dock andra alternativ för backend som Theano eller CNTK.
Låt oss nu installera båda TensorFlow och Keras.
Börja med att skapa en virtuell miljö med hjälp av reticulate
library(reticulate)
virtualenv_create("virtualenv", python = "/path/to/your/python3") install.packages(“tensorflow”) #This is only done once! library(tensorflow) install_tensorflow(envname = "/path/to/your/virtualenv", version = "cpu") install.packages(“keras”) #do this once! library(keras) install_keras(envname = "/path/to/your/virtualenv") # confirm the installation was successful
tf$constant("Hello TensorFlow!")
Nu när våra konfigurationer är inställda kan vi gå vidare till hur vi kan använda djupinlärning för att lösa ett klassificeringsproblem.
Uppgifterna jag kommer att använda för den här handledningen är från en pågående löneundersökning gjord av https://www.askamanager.org.
Huvudfrågan som ställs i formuläret är hur mycket pengar du tjänar, plus ytterligare ett par detaljer som bransch, ålder, års erfarenhet etc. Uppgifterna samlas in i ett Google-ark som jag hämtade uppgifterna från.
Problemet vi vill lösa med data är att kunna ta fram en modell för djupinlärning som förutsäger hur mycket någon potentiellt skulle kunna tjäna givet information som ålder, kön, års erfarenhet och högsta utbildningsnivå.
Ladda de bibliotek som vi behöver.
library(dplyr)
library(keras)
library(caTools)
Importera data
url - “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv” salary_data - read.csv(url)
Välj de kolumner som vi behöver
salary_data - salary_data %>% select(age,professional_experience_years,gender,highest_edu_level,annual_salary)
Kommer du ihåg det datavetenskapliga GIGO-konceptet? (Skräp in skräp ut). Tja, detta koncept är perfekt tillämpligt här som det är i andra domäner. Resultaten av vår utbildning kommer till stor del att bero på kvaliteten på den data vi använder. Detta är vad som ger datarensning och transformation, ett kritiskt steg i alla Data Science projektet.
Några av de viktigaste frågorna som datarensning försöker lösa är; konsistens, saknade värden, stavningsproblem, extremvärden och datatyper. Jag kommer inte att gå in på detaljerna om hur dessa frågor hanteras och detta är av den enkla anledningen att jag inte vill avvika från ämnet i denna artikel. Därför kommer jag att använda den rensade versionen av data, men om du är intresserad av att veta hur rengöringsbiten hanterades, kolla in den här artikeln.
Artificiella neurala nätverk accepterar endast numeriska variabler och eftersom vissa av våra variabler är av kategorisk natur, kommer vi att behöva koda sådana till tal. Detta är vad som ingår i förbehandling av data steg, vilket är nödvändigt eftersom du oftare än inte får data som är redo för modellering.
# create an encoder function
encode_ordinal - function(x, order = unique(x)) { x - as.numeric(factor(x, levels = order, exclude = NULL))
} salary_data - salary_data %>% mutate( highest_edu_level = encode_ordinal(highest_edu_level, order = c("High School","College degree","Master's degree","Professional degree (MD, JD, etc.)","PhD")), professional_experience_years = encode_ordinal(professional_experience_years, order = c("1 year or less", "2 - 4 years","5-7 years", "8 - 10 years", "11 - 20 years", "21 - 30 years", "31 - 40 years", "41 years or more")), age = encode_ordinal(age, order = c( "under 18", "18-24","25-34", "35-44", "45-54", "55-64","65 or over")), gender = case_when(gender== "Woman" ~ 0, gender == "Man" ~ 1))
Eftersom vi vill lösa en klassificering behöver vi kategorisera årslönen i två klasser så att vi använder den som svarsvariabel.
salary_data - salary_data %>% mutate(categories = case_when( annual_salary = 100000 ~ 0, annual_salary > 100000 ~ 1)) salary_data - salary_data %>% select(-annual_salary)Som i de grundläggande maskininlärningsmetoderna; regression, klassificering och klustring kommer vi att behöva dela upp vår data i utbildnings- och testuppsättningar. Vi gör detta med hjälp av 80-20-reglerna, vilket är 80 % av datamängden för träning och 20 % för testning. Detta är inte gjutet på stenar, eftersom du kan bestämma dig för att använda valfri splitkvot som du vill, men tänk på att träningssetet ska ha en bra andel av procenten.
set.seed(123) sample_split - sample.split(Y = salary_data$categories, SplitRatio = 0.7)
train_set - subset(x=salary_data, sample_split == TRUE)
test_set - subset(x = salary_data, sample_split == FALSE) y_train - train_set$categories
y_test - test_set$categories
x_train - train_set %>% select(-categories)
x_test - test_set %>% select(-categories)
Keras tar in indata i form av matriser eller arrayer. Vi använder funktionen as.matrix för konverteringen. Dessutom måste vi skala prediktorvariablerna och sedan konvertera svarsvariabeln till kategorisk datatyp.
x - as.matrix(apply(x_train, 2, function(x) (x-min(x))/(max(x) - min(x)))) y - to_categorical(y_train, num_classes = 2)Instantiera modellen
Skapa en sekventiell modell som vi lägger till lager på med hjälp av röroperatören.
model = keras_model_sequential()Konfigurera lagren
Smakämnen input_shape anger formen på indata. I vårt fall har vi fått det genom att använda ncol funktion. aktivering: Här anger vi aktiveringsfunktionen; en matematisk funktion som omvandlar utdata till ett önskat icke-linjärt format innan det överförs till nästa lager.
enheter: antalet neuroner i varje lager i det neurala nätverket.
model %>% layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>% layer_dense(units = 10, activation = "relu") %>% layer_dense(units = 2, activation = "sigmoid")Vi använder kompileringsmetoden för att göra detta. Funktionen tar tre argument;
Optimizer : Detta objekt specificerar träningsproceduren. förlust : Detta är funktionen att minimera under optimering. Tillgängliga alternativ är mse (mean square error), binary_crossentropy och categorical_crossentropy.
metrik : Vad vi använder för att övervaka träningen. Noggrannhet för klassificeringsproblem.
model %>% compile( loss = "binary_crossentropy", optimizer = "adagrad", metrics = "accuracy"
)Vi kan nu anpassa modellen med passformsmetoden från Keras. Några av de argument som passar in är:
epoker : En epok är en iteration över träningsdatauppsättningen.
satsstorlek : Modellen delar upp matrisen/matrisen som skickas till den i mindre satser över vilka den itererar under träning.
validation_split : Keras kommer att behöva skära upp en del av träningsdatan för att få en valideringsuppsättning som kommer att användas för att utvärdera modellens prestanda för varje epok.
blanda : Här anger du om du vill blanda dina träningsdata före varje epok.
fit = model %>% fit( x = x, y = y, shuffle = T, validation_split = 0.2, epochs = 100, batch_size = 5
)Utvärdera modellen
För att erhålla noggrannhetsvärdet för modellen använd utvärderingsfunktionen enligt nedan.
y_test - to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)Förutsägelse
För att förutsäga nya data använd predict_classes-funktionen från keras-biblioteket enligt nedan.
model %>% predict(as.matrix(x_test))Den här artikeln har tagit dig igenom grunderna för djupinlärning med Keras i R. Du är välkommen att dyka djupare för bättre förståelse, leka med parametrarna, smutsa ner händerna med dataförberedelser och kanske skala beräkningarna genom att utnyttja kraften av cloud computing.
Clinton Oyogo författare på Saturnus moln anser att analys av data för handlingsbara insikter är en avgörande del av hans dagliga arbete. Med sina färdigheter inom datavisualisering, datatvistelse och maskininlärning är han stolt över sitt arbete som datavetare.
Ursprungliga. Skickas om med tillstånd.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Köp och sälj aktier i PRE-IPO-företag med PREIPO®. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/05/deep-learning-r.html?utm_source=rss&utm_medium=rss&utm_campaign=deep-learning-with-r

