Beskrivning
Den här artikeln kommer att introducera begreppet datamodellering, en avgörande process som beskriver hur data lagras, organiseras och nås i en databas eller datasystem. Det innebär att konvertera verkliga affärsbehov till ett logiskt och strukturerat format som kan realiseras i en databas eller datalager. Vi kommer att utforska hur datamodellering skapar ett konceptuellt ramverk för att förstå relationerna och sammankopplingarna mellan data inom en organisation eller en specifik domän. Dessutom kommer vi att diskutera vikten av att designa datastrukturer och relationer för att säkerställa effektiv datalagring, hämtning och manipulation.

Användningsfall för datamodellering
Datamodellering är grundläggande för att hantera och använda data effektivt över olika scenarier. Här är några typiska användningsfall för datamodellering, vart och ett förklarat i detalj:
Data Acquisition
I datamodellering innebär datainsamling att definiera hur data samlas in eller genereras från olika källor. Denna fas inkluderar att upprätta den nödvändiga datastrukturen för att hålla inkommande data, vilket säkerställer att den kan integreras och lagras effektivt. Genom att modellera data i detta skede kan organisationer säkerställa att den insamlade informationen är strukturerad för att passa deras analytiska behov och affärsprocesser. Det hjälper till att identifiera vilken typ av data som behövs, formatet den ska vara i och hur den kommer att behandlas för vidare användning.
Dataladdning
När data väl har inhämtats måste de laddas in i målsystemet, såsom en databas, datalagret, eller data lake. Datamodellering spelar en avgörande roll här genom att definiera schemat eller strukturen i vilken data kommer att infogas. Detta inkluderar att specificera hur data från olika källor ska mappas till databasens tabeller och kolumner och att sätta upp relationer mellan olika dataenheter. Korrekt datamodellering säkerställer att data laddas optimalt, vilket underlättar effektiv lagring, åtkomst och frågeprestanda.
Affärsberäkning
Datamodellering är en integrerad del av att sätta upp ramverk för affärsberäkningar. Dessa beräkningar genererar insikter, mätvärden och nyckelprestandaindikatorer (KPI:er) från lagrad data. Genom att etablera en tydlig datamodell kan organisationer definiera hur data från olika källor kan aggregeras, transformeras och analyseras för att utföra komplexa affärsberäkningar. Detta säkerställer att den underliggande informationen stöder härledning av meningsfull och korrekt business intelligence, som kan vägleda beslutsfattande och strategisk planering.
Fördelning
Distributionsfasen gör den bearbetade datan tillgänglig för slutanvändare eller andra system för analys, rapportering och beslutsfattande. Datamodellering i detta skede fokuserar på att säkerställa att data är strukturerad och formaterad på ett sätt som är tillgängligt och begripligt för den avsedda publiken. Detta kan handla om att modellera data till dimensionsscheman för användning i business intelligence-verktyg, skapa API:er för programmatisk åtkomst eller definiera exportformat för datadelning. Effektiv datamodellering säkerställer att data enkelt kan distribueras och konsumeras över olika plattformar och av olika intressenter, vilket ökar dess användbarhet och värde.
Vart och ett av dessa användningsfall illustrerar betydelsen i hela datalivscykeln, från insamling och lagring till analys och distribution. Genom att noggrant utforma datastrukturer och relationer i varje steg kan organisationer säkerställa att deras dataarkitektur stödjer deras operativa och analytiska behov effektivt och effektivt.
Dataingenjörer/modellerare
Dataingenjörer och Data Modelers spelar centrala roller i datahantering och analys, och alla bidrar med unika färdigheter och expertis för att utnyttja kraften i data inom en organisation. Att förstå varandras roller och ansvar kan hjälpa till att klargöra hur de arbetar tillsammans för att bygga och underhålla robusta datainfrastrukturer.
Dataingenjörer
Dataingenjörer ansvarar för design, konstruktion och underhåll av de system och arkitekturer som möjliggör effektiv hantering och tillgänglighet av data. Deras roll innefattar ofta:
- Bygga och underhålla datapipelines: De skapar infrastrukturen för att extrahera, transformera och ladda data (ETL) från olika källor.
- Datalagring och hantering: De designar och implementerar databassystem, datasjöar och andra lagringslösningar för att hålla data organiserad och tillgänglig.
- Prestandaoptimering: Dataingenjörer arbetar för att säkerställa att dataprocesser körs effektivt, ofta genom att optimera datalagring och exekvering av frågor.
- Samarbete med intressenter: De arbetar nära affärsanalytiker, datavetare och andra användare för att förstå databehov och implementera lösningar som möjliggör datadrivet beslutsfattande.
- Säkerställa datakvalitet och integritet: De implementerar system och processer för att övervaka, validera och rensa data, vilket säkerställer att användare har tillgång till tillförlitlig och korrekt information.
Datamodellerare
Datamodellerare fokuserar på att designa ritningen för datahanteringssystem. Deras arbete innebär att förstå affärskrav och översätta dem till datastrukturer som stöder effektiv datalagring, hämtning och analys. Nyckelansvar inkluderar:
- Utveckla konceptuella, logiska och fysiska datamodeller: De skapar modeller som definierar hur data hänger ihop och hur det kommer att lagras i databaser.
- Definiera dataenheter och relationer: Datamodellerare identifierar nyckelenheterna som en organisations datasystem behöver representera och definierar hur dessa enheter är relaterade till varandra.
- Säkerställa datakonsistens och standardisering: De upprättar namnkonventioner och standarder för dataelement för att säkerställa konsistens i hela organisationen.
- Samarbete med dataingenjörer och arkitekter: Datamodellerare arbetar nära dataingenjörer för att säkerställa att dataarkitekturen effektivt stöder de designade modellerna.
- Datastyrning och strategi: De spelar ofta en roll i datastyrning, och hjälper till att definiera policyer och standarder för datahantering inom organisationen.
Även om det finns en viss överlappning i dataingenjörers och datamodellers kompetens och uppgifter, kompletterar de två rollerna varandra. Dataingenjörer fokuserar på att bygga och underhålla infrastrukturen som stöder datalagring och åtkomst, medan Data Modelers utformar strukturen och organisationen av data inom dessa system. De säkerställer att en organisations dataarkitektur är robust, skalbar och anpassad till affärsmål, vilket möjliggör effektivt datadrivet beslutsfattande.
Nyckelkomponenter i datamodellering
Datamodellering är en kritisk process för att designa och implementera databaser och datasystem som är effektiva, skalbara och kan uppfylla kraven från olika applikationer. Nyckelkomponenterna inkluderar entiteter, attribut, relationer och nycklar. Att förstå dessa komponenter är viktigt för att skapa en sammanhängande och funktionell datamodell.
enheter
En entitet representerar ett verkligt objekt eller koncept som kan identifieras tydligt. I en databas översätts en entitet ofta till en tabell. Entiteter används för att kategorisera den information vi vill lagra. Till exempel, i ett CRM-system (Customer Relationship Management) kan typiska enheter inkludera "Kund", "Order" och Product.
attribut
Attribut är en enhets egenskaper eller egenskaper. De ger detaljer om enheten, hjälper till att beskriva den mer fullständigt. I en databastabell representerar attribut kolumnerna. För entiteten "Kund" kan attribut inkludera "Kund-ID", "Namn", "Adress", "Telefonnummer", etc. Attribut definierar datatypen (som heltal, sträng, datum, etc.) som lagras för varje enhet exempel.
Förhållanden
Relationer beskriver hur enheter i ett system är kopplade till varandra och representerar deras interaktioner. Det finns flera typer av relationer:
- En-till-en (1:1): Varje instans av Entitet A är relaterad till en och endast en instans av Entitet B, och vice versa.
- En-till-många (1:N): Varje instans av Entitet A kan associeras med noll, en eller flera instanser av Entitet B, men varje instans av Entitet B är relaterad till endast en instans av Entitet A.
- Många-till-många (M:N): Varje instans av Entitet A kan associeras med noll, en eller flera instanser av Entitet B, och varje instans av Entitet B kan associeras med noll, en eller flera instanser av Entitet A.
Relationer är avgörande för att länka data som lagras i olika enheter, vilket underlättar datahämtning och rapportering över flera tabeller.
Nycklar
Nycklar är specifika attribut som används för att unikt identifiera poster i en tabell och upprätta relationer mellan tabeller. Det finns flera typer av nycklar:
- Primärnyckel: En kolumn, eller en uppsättning kolumner, identifierar varje tabellpost unikt. Inga två poster kan ha samma primärnyckelvärde i en tabell.
- Främmande nyckel: En kolumn, eller en uppsättning kolumner, i en tabell som refererar till primärnyckeln för en annan tabell. Främmande nycklar används för att upprätta och upprätthålla relationer mellan tabeller.
- Sammansatt nyckel: En kombination av två eller flera kolumner i en tabell som kan användas för att identifiera varje post i tabellen unikt.
- Kandidatnyckel: Valfri kolumn eller uppsättning kolumner som kan kvalificeras som en primärnyckel i tabellen.
Att förstå och korrekt implementera dessa nyckelkomponenter är grundläggande för att skapa effektiva datalagrings-, hämtnings- och hanteringssystem. Korrekt datamodellering leder till välorganiserade och optimerade databaser för prestanda och skalbarhet, vilket stödjer behoven hos både utvecklare och slutanvändare.
Faser av datamodeller
Datamodellering utspelar sig vanligtvis i tre huvudfaser: den konceptuella datamodellen, den logiska datamodellen och den fysiska datamodellen. Varje fas tjänar ett specifikt syfte och bygger på den föregående för att progressivt omvandla abstrakta idéer till en konkret databasdesign. Att förstå dessa faser är avgörande för alla som skapar eller hanterar datasystem.
Konceptuell datamodell
Den konceptuella datamodellen är den mest abstrakta nivån av datamodellering. Denna fas fokuserar på att definiera enheterna på hög nivå och relationerna mellan dem utan att gå in på detaljer om hur data kommer att lagras. Det primära målet är att beskriva de viktigaste dataobjekten som är relevanta för affärsdomänen och deras interaktioner på ett sätt som icke-tekniska intressenter förstår. Denna modell används ofta för inledande planering och kommunikation, för att överbrygga affärskraven och den tekniska implementeringen.
Viktiga egenskaper inkluderar
- Identifiering av viktiga enheter och deras relationer.
- Hög nivå, ofta med affärsterminologi.
- Oberoende av databashanteringssystem (DBMS) eller teknologi.
Logisk datamodell
Den logiska datamodellen lägger till mer detaljer till den konceptuella modellen, specificerar strukturen för dataelementen och anger relationerna mellan dem. Den inkluderar definitionen av entiteter, attribut för varje entitet, primärnycklar och främmande nycklar. Det är dock fortfarande oberoende av den teknik som kommer att användas för implementering. Den logiska modellen är mer detaljerad och strukturerad än den konceptuella modellen och börjar introducera regler och begränsningar som styr data.
Viktiga egenskaper inkluderar
- Detaljerad definition av enheter, relationer och attribut.
- Inkluderandet av primärnycklar och främmande nycklar är nödvändigt för att upprätta relationer.
- Normaliseringsprocesser tillämpas för att säkerställa dataintegritet och minska redundans.
- Fortfarande oberoende av den specifika DBMS-tekniken.
Fysisk datamodell
Den fysiska datamodellen är den mest detaljerade fasen och involverar implementering av datamodellen inom ett specifikt databashanteringssystem. Denna modell översätter den logiska datamodellen till ett detaljerat schema som kan implementeras i en databas. Den innehåller alla nödvändiga detaljer för implementering, såsom tabeller, kolumner, datatyper, begränsningar, index, utlösare och andra databasspecifika funktioner.
Nyckelegenskaper inkluderar
- Specifik för ett visst DBMS och inkluderar databasspecifik optimering.
- Detaljerade specifikationer av tabeller, kolumner, datatyper och begränsningar.
- Övervägande av fysiska lagringsalternativ, indexeringsstrategier och prestandaoptimering.
Övergång genom dessa faser möjliggör noggrann planering och design av ett datasystem anpassat till affärskrav och optimerat för prestanda inom en specifik teknisk miljö. Den konceptuella modellen säkerställer att den övergripande strukturen överensstämmer med affärsmålen, den logiska modellen överbryggar gapet mellan konceptuell planering och fysisk implementering, och den fysiska modellen säkerställer att databasen är optimerad för faktisk användning.
Exempel skoldataset
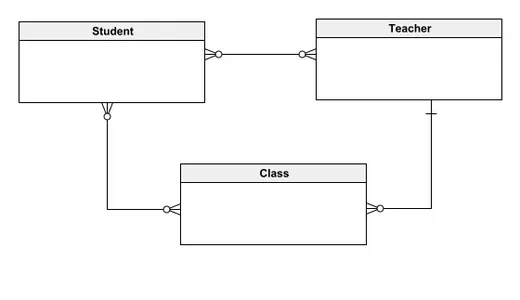
Entiteter: Studenter, lärare och klasser.
Konceptuell datamodell
Denna konceptuella datamodell beskriver ett databassystem för hantering av skolregister, med tre primära enheter: elev, lärare och klass. I den här modellen kan elever associeras med flera lärare och klasser, medan lärare kan instruera flera elever och leda olika klasser. Varje klass rymmer många elever men undervisas av en enda lärare. Designen syftar till att förenkla förståelsen av relationerna mellan enheter för både tekniska och icke-tekniska intressenter, vilket ger en tydlig och intuitiv överblick över systemets struktur. Att börja med en konceptuell modell möjliggör gradvis integrering av mer detaljerade element, vilket lägger en solid grund för att utveckla sofistikerade databasmodeller.
Logisk datamodell
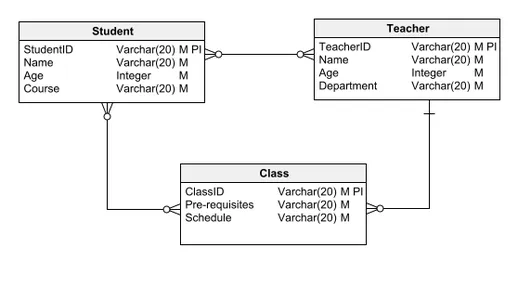
Den logiska datamodellen, mycket gynnad för sin balans mellan klarhet och detaljer, innehåller enheter, relationer, attribut, PRIMÄRNYCKLAR och UTLÄNDSKA NYCKLAR. Den beskriver noggrant datas logiska utveckling i en databas, och förtydligar detaljerade detaljer som dess sammansättning eller de datatyper som används. Den logiska datamodellen ger tillräcklig grund för mjukvaruutveckling för att påbörja själva databaskonstruktionen.
För att gå vidare från den tidigare diskuterade konceptuella datamodellen, låt oss undersöka en typisk logisk datamodell. Till skillnad från sin konceptuella föregångare är denna modell berikad med attribut och primärnycklar. Student-entiteten kännetecknas till exempel av ett StudentID som dess primära nyckel och unika identifierare, tillsammans med andra viktiga attribut som namn och ålder.
Detta tillvägagångssätt tillämpas konsekvent över andra enheter, såsom lärare och klass, och bevarar de relationer som etablerats i den konceptuella modellen men förbättrar modellen med ett detaljerat schema som inkluderar attribut och nyckelidentifierare.
Fysisk datamodell
Den fysiska datamodellen är den mest detaljerade bland abstraktionsnivåerna, och innehåller detaljer som är skräddarsydda för det valda databashanteringssystemet, såsom PostgreSQL, Oracle eller MySQL. I den här modellen översätts entiteter till tabeller och attribut blir kolumner, vilket speglar strukturen i en faktisk databas. Varje kolumn tilldelas en specifik datatyp, till exempel INT för heltal, VARCHAR för variabla teckensträngar eller DATE för datum.
Med tanke på dess detaljerade karaktär fördjupar den fysiska datamodellen de tekniska detaljerna som är unika för den databasplattform som används. Dessa omfattande aspekter sträcker sig utanför räckvidden för en översikt på hög nivå. Detta inkluderar överväganden som lagringsallokering, indexeringsstrategier och implementeringsbegränsningar, som är avgörande för databasens prestanda och integritet men som vanligtvis är för detaljerade för en preliminär diskussion.

Faser av datamodellering
- Förstå affärskrav: Delta i detaljerade diskussioner med intressenter för att förstå databasens affärssyfte. Viktiga överväganden inkluderar att identifiera affärsdomänen, datalagringsbehov och problem som databasen syftar till att lösa. Fokusera på att anpassa databasdesign med affärsmål avseende prestanda, kostnad och säkerhet.
- Lagsamarbete: Arbeta nära med andra team (t.ex. UX/UI-designers och utvecklare) för att säkerställa att databasen stöder den bredare lösningen. Anpassa dataformat och typer för att möta applikationskrav, med betoning på samarbetsdesign och kommunikationsförmåga.
- Utnyttja industristandarder: Undersök befintliga modeller och standarder för att undvika att börja om från början. Använd branschens bästa praxis för att spara tid och resurser, fokusera unika ansträngningar på aspekter av din databas som skiljer den från befintliga modeller.
- Börja databasmodellering: Med en gedigen förståelse för affärsbehov, teaminput och branschstandarder, börja med konceptuell modellering, övergå till logisk och avsluta med den fysiska modellen. Detta strukturerade tillvägagångssätt säkerställer en heltäckande förståelse av de nödvändiga enheterna, attributen och relationerna, vilket underlättar en smidig databasimplementering i linje med affärsmålen.
Datamodelleringsverktyg är viktiga för att designa, underhålla och utveckla organisatoriska datastrukturer. Dessa verktyg erbjuder en rad funktioner för att stödja hela databasens design och hanteringslivscykel. Nyckelfunktioner att leta efter i datamodelleringsverktyg inkluderar:
- Bygg datamodeller: Underlätta skapandet av konceptuella, logiska och fysiska datamodeller, vilket möjliggör en tydlig definition av enheter, attribut och relationer. Denna kärnfunktionalitet stöder den initiala och pågående designen av databasarkitektur.
- Samarbete och centrallager: Gör det möjligt för teammedlemmar att samarbeta kring design och modifieringar av datamodeller. Ett centralt arkiv säkerställer att de senaste versionerna är tillgängliga för alla intressenter, vilket främjar konsekvens och effektivitet i utvecklingen.
- Reverse engineering: Ge möjligheten att importera SQL-skript eller ansluta till befintliga databaser för att generera datamodeller. Detta är särskilt användbart för att förstå och dokumentera äldre system eller för att integrera befintliga databaser.
- Forward Engineering: Tillåter generering av SQL-skript eller kod från datamodellen. Denna funktion effektiviserar implementeringen av ändringar i databasstrukturen, vilket säkerställer att den fysiska databasen återspeglar den senaste modellen.
- Stöd för olika databastyper: Erbjud kompatibilitet med flera databashanteringssystem (DBMS), som MySQL, PostgreSQL, Oracle, SQL Server och mer. Denna flexibilitet säkerställer att verktyget kan användas i olika projekt och tekniska miljöer.
- Versionskontroll: Inkludera eller integrera med versionskontrollsystem för att spåra ändringar av datamodeller över tid. Denna funktion är avgörande för att hantera iterationer av databasstrukturen och underlätta återställning till tidigare versioner vid behov.
- Exportera diagram i olika format: Tillåt användare att exportera datamodeller och diagram i olika format (t.ex. PDF, PNG, XML), vilket underlättar delning och dokumentation. Detta säkerställer att icke-tekniska intressenter också kan granska och förstå dataarkitekturen.
Att välja ett datamodelleringsverktyg med dessa funktioner kan avsevärt förbättra effektiviteten, noggrannheten och samarbetet för datahanteringsinsatser inom en organisation, vilket säkerställer att databaser är väldesignade, uppdaterade och anpassade till affärsbehov.
ER/Studio

Erbjuder omfattande modelleringsmöjligheter och samarbetsfunktioner och stöder olika databasplattformar.
IBM InfoSphere Data Architect

Ger en robust miljö för att designa och hantera datamodeller med stöd för integration och synkronisering med andra IBM-produkter.
IBM InfoSphere Data Architect Link
Oracle SQL Developer Data Modeler

Ett gratis verktyg som stöder framåt- och bakåtutveckling, versionskontroll och stöd för flera databaser.
Oracle SQL Developer Data Modeler Link
PowerDesigner (SAP)

Erbjuder omfattande modelleringsfunktioner, inklusive data, information och stöd för företagsarkitektur.
Navicat Data Modeler
Känd för sitt användarvänliga gränssnitt och stöd för ett brett utbud av databaser, möjliggör den framåt- och bakåtutveckling.
Dessa verktyg effektiviserar datamodelleringsprocessen, förbättrar teamsamarbete och säkerställer kompatibilitet mellan olika databassystem.
Läs också: Datamodellering intervjufrågor
Slutsats
Den här artikeln grävde ner sig i den grundläggande praxisen för datamodellering, och lyfte fram dess avgörande roll för att organisera, lagra och komma åt data i databaser och datasystem. Genom att dela upp processen i konceptuella, logiska och fysiska modeller har vi illustrerat hur datamodellering översätter affärsbehov till strukturerade dataramverk, vilket underlättar effektiv datahantering och insiktsfull analys.
Viktiga takeaways inkluderar vikten av att förstå affärskrav, den samarbetande karaktären hos databasdesign som involverar olika intressenter och den strategiska användningen av datamodelleringsverktyg för att effektivisera utvecklingsprocessen. Datamodellering säkerställer att datastrukturer är optimerade för nuvarande behov och ger skalbarhet för framtida tillväxt.
Datamodellering står i centrum för effektiv datahantering, vilket gör det möjligt för organisationer att utnyttja sin data för strategiskt beslutsfattande och operativ effektivitet.
Vanliga frågor
Ans. Datamodellering representerar visuellt ett systems data och beskriver hur det lagras, organiseras och nås. Det är avgörande för att översätta affärskrav till ett strukturerat databasformat, vilket möjliggör effektiv dataanvändning.
Ans. Viktiga användningsfall inkluderar datainsamling, laddning, affärsberäkningar och distribution, vilket säkerställer att data effektivt samlas in, lagras och används för affärsinsikter.
Ans. Dataingenjörer bygger och underhåller datainfrastrukturen, medan datamodellerare utformar datans struktur och organisation för att stödja affärsmål och dataintegritet.
Ans. Processen går från att förstå affärskrav till att samarbeta med team, utnyttja industristandarder och modellera databasen genom konceptuella, logiska och fysiska faser.
Ans. Dessa verktyg underlättar design, samarbete och utveckling av datamodeller, stöder olika databastyper och möjliggör bakåt- och framåtutveckling för effektiv databashantering.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/03/data-modeling-demystified-crafting-efficient-databases-for-business-insights/

