Beskrivning
Retrieval Augmented-Generation (RAG) har tagit världen av Storm ända sedan starten. RAG är vad som krävs för att de stora språkmodellerna (LLM) ska kunna tillhandahålla eller generera korrekta och sakliga svar. Vi löser LLM:s fakta genom RAG, där vi försöker ge LLM ett sammanhang som är kontextuellt likt användarfrågan så att LLM kommer att arbeta med detta sammanhang och generera ett faktamässigt korrekt svar. Vi gör detta genom att representera vår data och användarfråga i form av vektorinbäddningar och utföra en cosinuslikhet. Men problemet är att alla traditionella metoder representerar data i en enda inbäddning, vilket kanske inte är idealiskt för gott hämtningssystem. I den här guiden kommer vi att titta på ColBERT som utför hämtning med bättre noggrannhet än traditionella bi-encoder-modeller.
Inlärningsmål
- Förstå hur hämtning i RAG fungerar på hög nivå.
- Förstå enstaka inbäddningsbegränsningar vid hämtning.
- Förbättra hämtningskontexten med ColBERTs tokeninbäddningar.
- Lär dig hur ColBERTs sena interaktion förbättrar hämtning.
- Lär känna hur du arbetar med ColBERT för korrekt hämtning.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Vad är RAG?
Även om LLM kan generera text som är både meningsfull och grammatiskt korrekt, lider dessa LLM av ett problem som kallas hallucination. Hallucinationer i LLM är konceptet där LLM:erna med tillförsikt genererar felaktiga svar, det vill säga de skapar fel svar på ett sätt som får oss att tro att det är sant. Detta har varit ett stort problem sedan införandet av LLM:erna. Dessa hallucinationer leder till felaktiga och faktiskt felaktiga svar. Därför introducerades Retrieval Augmented Generation.
I RAG tar vi en lista över dokument/bitar av dokument och kodar dessa textdokument till en numerisk representation som kallas vektorinbäddningar, där en enda vektorinbäddning representerar en enda bit av dokument och lagrar dem i en databas som heter vektor butik. De modeller som krävs för att koda dessa bitar till inbäddningar kallas kodningsmodeller eller bi-kodare. Dessa kodare är tränade på en stor mängd data, vilket gör dem kraftfulla nog att koda dokumentbitarna i en enda vektorinbäddningsrepresentation.
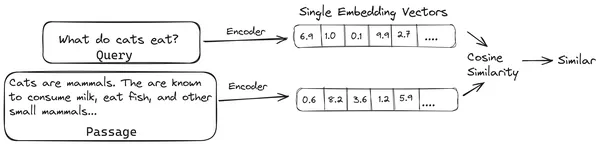
Nu när en användare ställer en fråga till LLM, då ger vi denna fråga till samma kodare för att producera en enda vektorinbäddning. Denna inbäddning används sedan för att beräkna likhetspoängen med olika andra vektorinbäddningar av dokumentbitarna för att få fram den mest relevanta delen av dokumentet. Den mest relevanta biten eller en lista över de mest relevanta bitarna tillsammans med användarfrågan ges till LLM. LLM tar sedan emot denna extra kontextuella information och genererar sedan ett svar som är anpassat till det sammanhang som tas emot från användarförfrågan. Detta säkerställer att det genererade innehållet av LLM är sakligt och något som kan spåras tillbaka vid behov.
Problemet med traditionella bi-kodare
Problemet med traditionella Encoder-modeller som all-miniLM, OpenAI inbäddningsmodell och andra kodarmodeller är att de komprimerar hela texten till en enda vektorinbäddningsrepresentation. Dessa enkla vektorinbäddningsrepresentationer är användbara eftersom de hjälper till att effektivt och snabbt hämta liknande dokument. Problemet ligger dock i sammanhanget mellan frågan och dokumentet. Den enda vektorinbäddningen kanske inte är tillräcklig för att lagra den kontextuella informationen för en dokumentbit, vilket skapar en informationsflaskhals.
Föreställ dig att 500 ord komprimeras till en enda vektor med storleken 782. Det kanske inte räcker att representera en sådan bit med en enda vektorinbäddning, vilket ger subpar resultat vid hämtning i de flesta fall. Den enda vektorrepresentationen kan också misslyckas i fall av komplexa frågor eller dokument. En sådan lösning skulle vara att representera dokumentbiten eller en fråga som en lista över inbäddningsvektorer istället för en enda inbäddningsvektor, det är här ColBERT kommer in.
Vad är ColBERT?
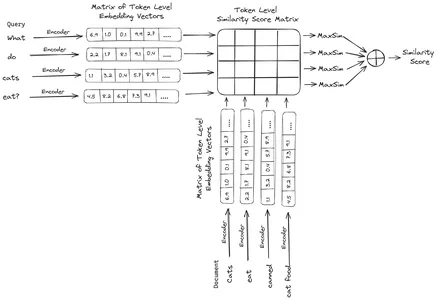
ColBERT (Contextual Late Interactions BERT) är en bi-encoder som representerar text i en multi-vektor inbäddningsrepresentation. Den tar in en fråga eller en bit av ett dokument / ett litet dokument och skapar vektorinbäddningar på tokennivå. Det vill säga att varje token får sin egen vektorinbäddning, och frågan/dokumentet kodas till en lista över vektorinbäddningar på tokennivå. Tokennivåinbäddningarna genereras från en förtränad BERTI modell därav namnet BERT.
Dessa lagras sedan i vektordatabasen. Nu, när en fråga kommer in, skapas en lista med inbäddningar på tokennivå för den och sedan utförs en matrismultiplikation mellan användarfrågan och varje dokument, vilket resulterar i en matris som innehåller likhetspoäng. Den övergripande likheten uppnås genom att ta summan av maximal likhet över dokumenttoken för varje frågetoken. Formeln för detta kan ses på bilden nedan:
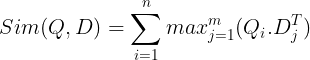
Här i ekvationen ovan ser vi att vi gör en punktprodukt mellan Query Tokens-matrisen (innehållande vektorinbäddningar på N tokennivå) och Transpose of Document Tokens-matrisen (innehållande vektorinbäddningar på M tokennivå), och sedan tar vi maximal likhet korsa dokumenttecknen för varje frågetoken. Sedan tar vi summan av alla dessa maximala likheter, vilket ger oss den slutliga likhetspoängen mellan dokumentet och frågan. Anledningen till att detta ger effektiv och korrekt hämtning är att vi här har en interaktion på tokennivå, vilket ger utrymme för mer kontextuell förståelse mellan frågan och dokumentet.
Varför namnet ColBERT?
Eftersom vi beräknar listan över inbäddningsvektorer före sig själv och endast utför denna MaxSim (maximal likhet) operation under modellinferensen, vilket alltså kallar det ett sent interaktionssteg, och eftersom vi får mer kontextuell information genom interaktioner på tokennivå, kallas det kontextuellt sena interaktioner. Alltså namnet Contextual Late Interactions BERTI eller ColBERT. Dessa beräkningar kan utföras parallellt, därför kan de beräknas effektivt. Slutligen, ett problem är utrymmet, det vill säga det kräver mycket utrymme för att lagra den här listan över vektorinbäddningar på tokennivå. Detta problem löstes i ColBERTv2, där inbäddningarna komprimeras genom tekniken som kallas restkompression, vilket optimerar det använda utrymmet.
Hands-On ColBERT med exempel
I det här avsnittet kommer vi att komma igång med ColBERT och till och med kontrollera hur den presterar mot en vanlig inbäddningsmodell.
Steg 1: Ladda ner bibliotek
Vi börjar med att ladda ner följande bibliotek:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Detta bibliotek låter oss arbeta med toppmoderna (SOTA) hämtningsmetoder som ColBERT på ett lättanvänt sätt. Det ger alternativ för att skapa index över datamängderna, fråga efter dem och till och med låta oss träna en ColBERT-modell på våra data.
- Langkedja: Det här biblioteket låter oss arbeta med inbäddningsmodellerna med öppen källkod så att vi kan testa hur bra de andra inbäddningsmodellerna fungerar jämfört med ColBERT.
- langchain_openai: Installerar Langkedja beroenden för OpenAI. Vi kommer till och med att arbeta med OpenAI Embedding-modellen för att kontrollera dess prestanda mot ColBERT.
- ChromaDB: Detta bibliotek låter oss skapa ett vektorlager i vår miljö så att vi kan spara de inbäddningar som vi har skapat på våra data och senare utföra en semantisk sökning mellan frågan och de lagrade inbäddningarna.
- oj: Detta bibliotek behövs för effektiv tensormatrismultiplikation.
- meningstransformatorer och tiktoken bibliotek behövs för att inbäddningsmodellerna med öppen källkod ska fungera korrekt.
Steg 2: Ladda ner förutbildad modell
I nästa steg kommer vi att ladda ner den förtränade ColBERT-modellen. För detta kommer koden att vara
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Vi importerar först RAGPretrainedModel-klassen från RAGatouille-biblioteket.
- Sedan anropar vi .from_pretrained() och ger modellnamnet, dvs. "colbert-ir/colbertv2.0".
Att köra koden ovan kommer att instansiera en ColBERT RAG-modell. Låt oss nu ladda ner en Wikipedia-sida och utföra hämtning från den. För detta kommer koden att vara:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille kommer med en praktisk funktion som heter get_wikipedia_page som tar in en sträng och får motsvarande Wikipedia-sida. Här laddar vi ner Wikipedia-innehållet på Elon Musk och lagrar det i variabeldokumentet. Låt oss skriva ut antalet ord som finns i dokumentet och de första raderna i dokumentet.
Här kan vi se resultatet på bilden. Vi kan se att det finns totalt 64,668 XNUMX ord på Wikipedia-sidan av Elon Musk.
Steg 3: Indexering
Nu ska vi skapa ett index på detta dokument.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Här anropar vi .index() för RAG för att indexera vårt dokument. Till detta skickar vi följande:
- samling: Detta är en lista över dokument som vi vill indexera. Här har vi bara ett dokument, därav en lista över ett enda dokument.
- document_id: Varje dokument förväntar sig ett unikt dokument-ID. Här ger vi det namnet elon_musk eftersom dokumentet handlar om Elon Musk.
- document_metadatas: Varje dokument har sin metadata. Detta är återigen en lista över ordböcker, där varje ordbok innehåller ett nyckel-värdepar metadata för ett visst dokument.
- index_name: Namnet på indexet som vi skapar. Låt oss döpa den till Elon2.
- max_document_size: Detta liknar chunkstorleken. Vi anger hur mycket varje dokumentbit ska vara. Här ger vi det ett värde på 256. Om vi inte anger något värde kommer 256 att tas som standard chunkstorlek.
- split_documents: Det är ett booleskt värde, där True indikerar att vi vill dela upp vårt dokument enligt den givna bitstorleken, och False indikerar att vi vill lagra hela dokumentet som en enda bit.
Genom att köra koden ovan kommer vårt dokument att delas upp i storlekar på 256 per bit, och sedan bädda in dem genom ColBERT-modellen, som kommer att producera en lista med vektorinbäddningar på tokennivå för varje bit och slutligen lagra dem i ett index. Detta steg kommer att ta lite tid att köra och kan påskyndas om du har en GPU. Slutligen skapar den en katalog där vårt index lagras. Här kommer katalogen att vara ".ragatouille/colbert/indexes/Elon2"
Steg 4: Allmän fråga
Nu börjar vi sökandet. För detta kommer koden att vara
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Här anropar vi först metoden .search() för RAG-objektet
- Till detta ger vi variablerna som inkluderar frågenamnet, k (antal dokument att hämta) och indexnamnet att söka
- Här ger vi frågan "Vilka företag hittade Elon Musk?". Det erhållna resultatet kommer att vara i en lista med ordboksformat, som innehåller nycklar som innehåll, poäng, rang, document_id, passage_id och document_metadata
- Därför arbetar vi med koden nedan för att skriva ut de hämtade dokumenten på ett snyggt sätt
- Här går vi igenom listan över ordböcker och skriver ut innehållet i dokumenten
Att köra koden ger följande resultat:
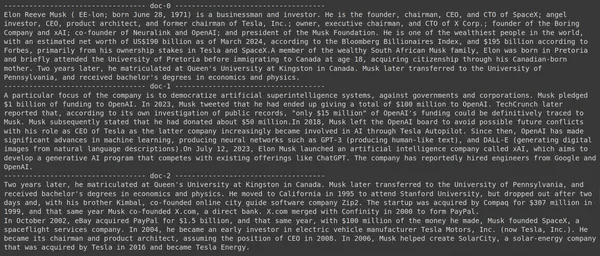
På bilden kan vi se att det första och sista dokumentet helt täcker de olika företagen som grundades av Elon Musk. ColBERT kunde korrekt hämta de relevanta bitar som behövdes för att svara på frågan.
Steg 5: Specifik fråga
Låt oss nu gå ett steg längre och ställa en specifik fråga till den.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])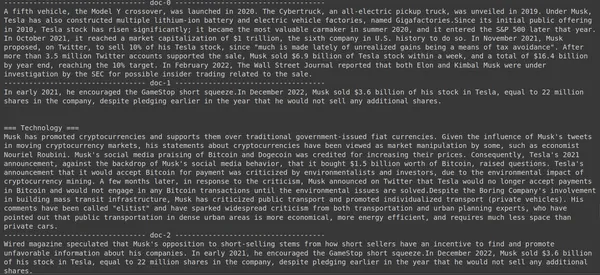
Här i ovanstående kod ställer vi en mycket specifik fråga om hur många aktier värda Tesla Elon som såldes under december månad 2022. Vi kan se resultatet här. Dok-1 innehåller svaret på frågan. Elon har sålt sina aktier i Tesla för 3.6 miljarder dollar. Återigen kunde ColBERT framgångsrikt hämta den relevanta biten för den givna frågan.
Steg 6: Testa andra modeller
Låt oss nu prova samma fråga med de andra inbäddningsmodellerna både med öppen källkod och stängd här:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Vi börjar med att ladda ner modellen först genom AutoModel-klassen från Transformers-biblioteket.
- Sedan lagrar vi model_name och model_kwargs i sina respektive variabler.
- För att nu arbeta med denna modell i LangChain importerar vi HuggingFaceEmbeddings från Langkedja och ge den modellnamnet och model_kwargs.
Genom att köra den här koden kommer Jina-inbäddningsmodellen att laddas ner och laddas så att vi kan arbeta med den
Steg 7: Skapa inbäddningar
Nu måste vi börja dela upp vårt dokument och sedan skapa inbäddningar av det och lagra dem i Chroma-vektorarkivet. För detta arbetar vi med följande kod:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Vi börjar med att importera Chroma och RecursiveCharacterTextSplitter från LangChain-biblioteket
- Sedan instansierar vi en text_splitter genom att anropa .from_tiktoken_encoder för RecursiveCharacterTextSplitter och skicka den chunk_size och chunk_overlap
- Här kommer vi att använda samma chunk_size som vi har tillhandahållit till ColBERT
- Sedan kallar vi metoden .split_text() för denna text_splitter och ger den dokumentet som innehåller Wikipedia-information om Elon Musk. Den delar sedan upp dokumentet baserat på den givna bitstorleken och slutligen lagras listan över dokumentbitar i variabeldelarna
- Slutligen anropar vi funktionen .from_texts() för Chroma-klassen för att skapa ett vektorlager. Till den här funktionen ger vi delarna, inbäddningsmodellen och samlingsnamnet
- Nu skapar vi en retriever av den genom att anropa funktionen .as_retriever() för vektorlagringsobjektet. Vi ger 3 för k-värdet
Att köra den här koden kommer att ta vårt dokument, dela upp det i mindre dokument med storleken 256 per bit och sedan bädda in dessa mindre bitar med Jina-inbäddningsmodellen och lagra dessa inbäddningsvektorer i chroma-vektorlagret.
Steg 8: Skapa en retriever
Slutligen skapar vi en retriever från den. Nu kommer vi att utföra en vektorsökning och kontrollera resultaten.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)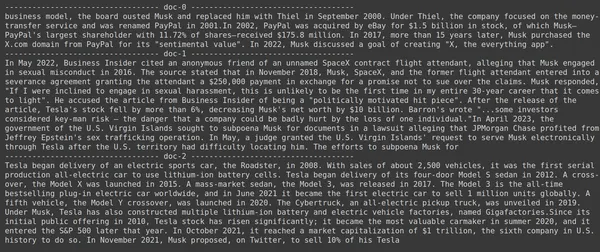
- Vi anropar funktionen .get_relevent_documents() för retrieverobjektet och ger det samma fråga.
- Sedan skriver vi snyggt ut de 3 bästa hämtade dokumenten.
- På bilden kan vi se att Jina Embedder trots att den är en populär inbäddningsmodell är hämtningen för vår fråga dålig. Det lyckades inte få rätt dokumentbitar.
Vi kan tydligt se skillnaden mellan Jina, inbäddningsmodellen som representerar varje del som en enskild vektorinbäddning, och ColBERT-modellen som representerar varje del som en lista över inbäddningsvektorer på tokennivå. ColBERT överträffar klart i detta fall.
Steg 9: Testa OpenAI:s inbäddningsmodell
Låt oss nu försöka använda en inbäddningsmodell med sluten källkod som OpenAI Embedding-modellen.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Här är koden väldigt lik den som vi just har skrivit
- Den enda skillnaden är att vi skickar in OpenAI API-nyckeln för att ställa in miljövariabeln.
- Vi skapar sedan en instans av OpenAI Embedding-modellen genom att importera den från LangChain.
- Och när vi skapar samlingsnamnet ger vi ett annat samlingsnamn, så att inbäddningarna från OpenAI Embedding-modellen lagras i en annan samling.
Att köra den här koden kommer igen att ta våra dokument, dela upp dem i mindre dokument av storlek 256 och sedan bädda in dem i en vektorinbäddningsrepresentation med OpenAI-inbäddningsmodellen och slutligen lagra dessa inbäddningar i Chroma Vector Store. Låt oss nu försöka hämta de relevanta dokumenten till den andra frågan.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)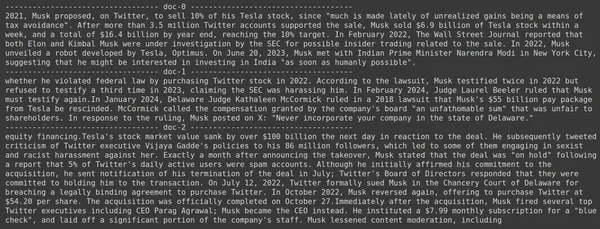
- Vi ser att svaret vi förväntar oss inte finns inom de hämtade bitarna.
- Den biten innehåller information om Tesla-aktier 2022 men talar inte om att Elon skulle sälja dem.
- Detsamma kan ses med de återstående två dokumentbitarna, där informationen de innehåller handlar om Tesla och dess lager men det är inte den information vi förväntar oss.
- De ovan hämtade bitarna tillhandahåller inte sammanhanget för LLM att svara på frågan som vi har tillhandahållit.
Även här kan vi se en tydlig skillnad mellan inbäddningsrepresentationen med en vektor och inbäddningsrepresentationen med flera vektorer. Multi-inbäddningsrepresentationerna fångar tydligt de komplexa frågorna vilket resulterar i mer exakta hämtningar.
Slutsats
Sammanfattningsvis visar ColBERT ett betydande framsteg i hämtningsprestanda jämfört med traditionella bi-encoder-modeller genom att representera text som multivektorinbäddningar på tokennivå. Detta tillvägagångssätt möjliggör en mer nyanserad kontextuell förståelse mellan frågor och dokument, vilket leder till mer exakta hämtningsresultat och mildrar problemet med hallucinationer som vanligtvis observeras i LLM.
Key Takeaways
- RAG tar itu med problemet med hallucinationer i LLM:er genom att tillhandahålla kontextuell information för generering av faktasvar.
- Traditionella bi-encoders lider av en informationsflaskhals på grund av att hela texter komprimeras till enstaka vektorinbäddningar, vilket resulterar i subpar hämtningsnoggrannhet.
- ColBERT, med sin inbäddningsrepresentation på tokennivå, underlättar bättre kontextuell förståelse mellan frågor och dokument, vilket leder till förbättrad hämtningsprestanda.
- Det sena interaktionssteget i ColBERT, kombinerat med interaktioner på tokennivå, förbättrar hämtningsnoggrannheten genom att beakta kontextuella nyanser.
- ColBERTv2 optimerar lagringsutrymme genom kvarvarande komprimering samtidigt som hämtningseffektiviteten bibehålls.
- Praktiska experiment visar ColBERTs överlägsenhet i hämtningsprestanda jämfört med traditionella inbäddningsmodeller med öppen källkod som Jina och OpenAI Embedding.
Vanliga frågor
S. Traditionella bi-kodare komprimerar hela texter till enstaka vektorinbäddningar, vilket kan förlora kontextuell information. Detta begränsar deras effektivitet i hämtningsuppgifter, särskilt med komplexa frågor eller dokument.
A. ColBERT (Contextual Late Interactions BERT) är en dubbelkodarmodell som representerar text med vektorinbäddningar på tokennivå. Det möjliggör en mer nyanserad kontextuell förståelse mellan frågor och dokument, vilket förbättrar hämtningsnoggrannheten.
S. ColBERT genererar inbäddningar på tokennivå för frågor och dokument, utför matrismultiplikation för att beräkna likhetspoäng och väljer sedan den mest relevanta informationen baserat på maximal likhet mellan tokens. Detta möjliggör effektiv hämtning med kontextuell förståelse.
A. ColBERTv2 optimerar utrymmet genom metoden med restkompression, vilket minskar lagringskraven för inbäddningar på tokennivå samtidigt som hämtningsnoggrannheten bibehålls.
S. Du kan använda bibliotek som RAGatouille för att enkelt arbeta med ColBERT. Genom att indexera dokument och frågor kan du utföra effektiva hämtningsuppgifter och generera korrekta svar anpassade till sammanhanget.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

