Det här är ett gästblogginlägg som skrivits tillsammans med Minghui Yu och Jianzhe Xiao från Bytedance.
ByteDance är ett teknikföretag som driver en rad innehållsplattformar för att informera, utbilda, underhålla och inspirera människor över språk, kulturer och geografier. Användare litar på och tycker om våra innehållsplattformar på grund av de rika, intuitiva och säkra upplevelser de tillhandahåller. Dessa upplevelser möjliggörs av vår backend-motor för maskininlärning (ML), med ML-modeller byggda för innehållsmoderering, sökning, rekommendationer, annonsering och nya visuella effekter.
ByteDance AML (Applied Machine Learning)-teamet tillhandahåller högpresterande, pålitliga och skalbara ML-system och end-to-end ML-tjänster för företagets verksamhet. Vi undersökte sätt att optimera våra ML-inferenssystem för att minska kostnaderna, utan att öka svarstiderna. När AWS lanserades AWS slutledning, ett högpresterande ML-inferenschip som är specialbyggt av AWS, samarbetade vi med vårt AWS-kontoteam för att testa om AWS Inferentia kan hantera våra optimeringsmål. Vi körde flera proof of concept, vilket resulterade i upp till 60 % lägre slutledningskostnad jämfört med T4 GPU-baserade EC2 G4dn-instanser och upp till 25 % lägre slutledningslatens. För att realisera dessa kostnadsbesparingar och prestandaförbättringar beslutade vi att distribuera modeller på AWS Inferentia-baserade Amazon Elastic Compute Cloud (Amazon EC2) Inf1-instanser i produktion.
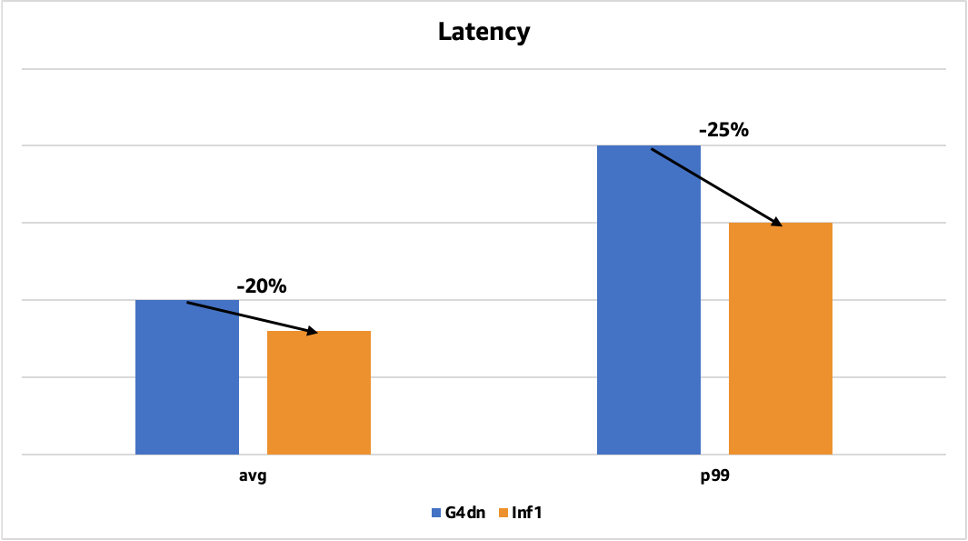
Följande diagram visar latensförbättringen för en av våra ansiktsdetektionsmodeller som tidigare distribuerades på GPU:er med Tensor RT. Den genomsnittliga latensen minskade med 20 % (från 50 millisekunder till 40 millisekunder), och p99-latensen minskade med 25 % (från 200 millisekunder till 150 millisekunder).
I det här inlägget delar vi hur vi sparade på slutledningskostnader samtidigt som vi minskade latenser och ökade genomströmningen med AWS Inferentia.
På jakt efter högpresterande, kostnadseffektiv beräkning
ByteDance AML-teamet fokuserar på forskning och implementering av banbrytande ML-system och de heterogena datorresurser de kräver. Vi skapar storskaliga utbildnings- och slutledningssystem för en mängd olika modeller för rekommendator, naturlig språkbehandling (NLP) och datorseende (CV). Dessa modeller är mycket komplexa och bearbetar en enorm mängd data från de många innehållsplattformar som ByteDance driver. Att distribuera dessa modeller kräver betydande GPU-resurser, oavsett om det är i molnet eller på plats. Därför är beräkningskostnaderna för dessa slutledningssystem ganska höga.
Vi ville sänka dessa kostnader utan att påverka genomströmning eller latens. Vi ville ha molnets flexibilitet och snabbare leveranscykel, som är mycket kortare än den som behövs för en lokal installation. Och även om vi var öppna för att utforska nya alternativ för accelererad ML, ville vi också ha en sömlös utvecklarupplevelse.
Vi lärde oss av vårt AWS-team att AWS Inferentia-baserade EC2 Inf1-instanser levererar högpresterande ML-inferens till lägsta kostnad per slutledning i molnet. Vi var nyfikna på att utforska dem och fann att de var väl lämpade för vårt användningsfall, eftersom vi kör omfattande maskininlärning på stora mängder bild-, objekt-, tal- och textdata. De passade definitivt bra för våra mål, eftersom vi kunde realisera enorma kostnadsbesparingar med tanke på komplexiteten hos våra modeller och volymen av dagliga förutsägelser. Dessutom har AWS Inferentia en stor mängd on-chip-minne, som du kan använda för att cachelagra stora modeller istället för att lagra dem utanför chip. Vi insåg att detta kan ha en betydande inverkan på att minska slutledningslatens eftersom bearbetningskärnorna i AWS Inferentia, kallade NeuronCores, har höghastighetsåtkomst till modeller som är lagrade i on-chip-minne och inte begränsas av off-chip-minnet bandbredd.
I slutändan, efter att ha utvärderat flera alternativ, valde vi EC2 Inf1-instanser för deras bättre prestanda/prisförhållande jämfört med G4dn-instanser och NVIDIA T4 på plats. Vi engagerade oss i en cykel av kontinuerlig iteration med AWS-teamet för att låsa upp pris- och prestandafördelarna med Inf1.
Distribuera inferensarbetsbelastningar på AWS Inferentia
Att komma igång med AWS Inferentia med AWS Neuron SDK involverade två faser: kompilering av modellkod och distribution på Inf1-instanser. Som är vanligt när man flyttar ML-modeller till ny infrastruktur, fanns det några utmaningar som vi stod inför. Vi kunde övervinna dessa utmaningar med flit och stöd från vårt AWS-team. I följande avsnitt delar vi med oss av flera användbara tips och observationer baserat på vår erfarenhet av att implementera inferensarbetsbelastningar på AWS Inferentia.
Conformer modell för OCR
Vår optiska teckenigenkänning (OCR) konformermodell upptäcker och läser text i bilder. Vi arbetade med flera optimeringar för att få hög prestanda (QPS) för en mängd olika batchstorlekar, samtidigt som latensen hölls låg. Några viktiga optimeringar noteras nedan:
- Kompilatoroptimeringar – Som standard presterar Inferentia bäst på ingångar med en fast sekvenslängd, vilket var en utmaning eftersom längden på textdata inte är fast. För att övervinna detta delar vi upp vår modell i två delar: en kodare och en avkodare. Vi kompilerade dessa två undermodeller separat och slog sedan samman dem till en enda modell via TorchScript. Genom att köra for loop-kontrollflödet på CPU: er, möjliggjorde detta tillvägagångssätt stöd för variabla sekvenslängder på Inferentia.
- Djupvis faltningsprestanda – Vi stötte på en DMA-flaskhals i den djupgående faltningsoperationen, som används mycket av vår konformermodell. Vi arbetade nära AWS Neuron-teamet för att identifiera och lösa flaskhalsen för DMA-åtkomstprestanda, vilket förbättrade prestandan för denna operation och förbättrade den övergripande prestandan för vår OCR-modell.
Vi skapade två nya modellvarianter för att optimera vår distribution på Inferentia:
- Kombinerad och utrullad kodare/dekoder – Istället för att använda en oberoende kompilerad kodare och avkodare kombinerade vi kodaren och en helt utrullad avkodare till en enda modell och kompilerade denna modell som en enda NEFF. Att rulla ut avkodaren gör det möjligt att köra hela avkodarens kontrollflöde på Inferentia utan att använda några CPU-operationer. Med detta tillvägagångssätt använder varje iteration av avkodaren exakt den mängd beräkning som krävs för denna token. Detta tillvägagångssätt förbättrar prestandan eftersom vi avsevärt minskar den överflödiga beräkningen som tidigare introducerades av utfyllnadsingångar. Dessutom behövs ingen dataöverföring från Inferentia till CPU mellan dekoder iterationer, vilket drastiskt minskar I/O-tiden. Denna version av modellen stöder inte tidig stopp.
- Partitionerad utrullad dekoder – I likhet med den kombinerade helt utrullade modellen rullar denna variant av modellen upp flera iterationer av avkodaren och kompilerar dem som en enda exekvering (men inkluderar inte kodaren). Till exempel, för en maximal sekvenslängd på 75, kan vi rulla upp avkodaren i 3 partitioner som beräknar tokens 1-25, 26-50 och 51-75. När det gäller I/O är detta också betydligt snabbare eftersom vi inte behöver överföra kodarutgången en gång per iteration. Istället överförs utgångarna endast en gång per varje dekoderpartition. Denna version av modellen stöder tidig stopp, men bara vid partitionsgränserna. Partitionsgränserna kan ställas in för varje specifik applikation för att säkerställa att majoriteten av förfrågningarna endast exekverar en partition.
För att ytterligare förbättra prestandan har vi gjort följande optimeringar för att minska minnesanvändningen eller förbättra åtkomsteffektiviteten:
- Tensordeduplicering och reducerade kopior – Detta är en kompilatoroptimering som avsevärt minskar storleken på utrullade modeller och antalet instruktioner/minnesåtkomst genom att återanvända tensorer för att förbättra utrymmeseffektiviteten.
- Reducerade instruktioner – Detta är en kompilatoroptimering som används med den icke vadderade versionen av avkodaren för att avsevärt minska det totala antalet instruktioner.
- Flerkärnig deduplicering – Det här är en körtidsoptimering som är ett alternativ till tensordeduplicering. Med det här alternativet blir alla flerkärniga modeller betydligt mer utrymmeseffektiva.
ResNet50-modell för bildklassificering
ResNet-50 är en förutbildad modell för djupinlärning för bildklassificering. Det är ett Convolutional Neural Network (CNN eller ConvNet) som oftast används för att analysera visuella bilder. Vi använde följande tekniker för att förbättra den här modellens prestanda på Inferentia:
- Modellförvandling – Många av ByteDances modeller exporteras i ONNX-format, vilket Inferentia för närvarande inte har stöd för. För att hantera dessa ONNX-modeller tillhandahöll AWS Neuron-teamet skript för att omvandla våra modeller från ONNX-format till PyTorch-modeller, som direkt kan kompileras för Inferentia med torch-neuron.
- Prestandaoptimering – Vi arbetade nära med AWS Neuron team för att justera schemaläggningsheuristiken i kompilatorn för att optimera prestandan för våra ResNet-50-modeller.
Multimodal modell för innehållsmoderering
Vår multimodala djupinlärningsmodell är en kombination av flera separata modeller. Storleken på denna modell är relativt stor, vilket orsakade modellladdningsfel på Inferentia. AWS Neuron-teamet löste detta problem framgångsrikt genom att använda viktdelning för att minska enhetens minnesanvändning. Neuron-teamet släppte denna viktdedupliceringsfunktion i Neuron libnrt-biblioteket och förbättrade även Neuron Tools för mer exakta mätvärden. Funktionen för deduplicering av körtidsvikt kan aktiveras genom att ställa in följande miljövariabel innan slutledning körs:
NEURON_RT_MULTI_INSTANCE_SHARED_WEIGHTS=1
Den uppdaterade Neuron SDK minskade den totala minnesförbrukningen för våra duplicerade modeller, vilket gjorde det möjligt för oss att distribuera vår multimodala modell för flerkärnig slutledning.
Migrera fler modeller till AWS Inferentia
På ByteDance fortsätter vi att distribuera innovativa modeller för djupinlärning för att leverera härliga användarupplevelser till nästan 2 miljarder aktiva användare varje månad. Med tanke på den enorma skala som vi verkar i, letar vi ständigt efter sätt att spara kostnader och optimera prestanda. Vi kommer att fortsätta att migrera modeller till AWS Inferentia för att dra nytta av dess höga prestanda och kostnadseffektivitet. Vi vill också att AWS ska lansera fler AWS Inferentia-baserade instanstyper, till exempel sådana med fler vCPU:er för förbearbetningsuppgifter. Framöver hoppas ByteDance att se mer kiselinnovation från AWS för att leverera bästa prisprestanda för ML-applikationer.
Om du är intresserad av att lära dig mer om hur AWS Inferentia kan hjälpa dig att spara kostnader samtidigt som du optimerar prestanda för dina slutledningsapplikationer, besök Amazon EC2 Inf1-instanser produktsida.
Om författarna
 Minghui Yu är en Senior Machine Learning Team Lead for Inference på ByteDance. Hans fokusområde är AI Computing Acceleration och Machine Learning System. Han är mycket intresserad av heterogen dator- och datorarkitektur i post Moore-eran. På fritiden gillar han basket och bågskytte.
Minghui Yu är en Senior Machine Learning Team Lead for Inference på ByteDance. Hans fokusområde är AI Computing Acceleration och Machine Learning System. Han är mycket intresserad av heterogen dator- och datorarkitektur i post Moore-eran. På fritiden gillar han basket och bågskytte.
 Jianzhe Xiao är en Senior Software Engineer Team Lead i AML Team på ByteDance. Hans nuvarande arbete fokuserar på att hjälpa affärsteamet att påskynda modellimplementeringsprocessen och förbättra modellens slutledningsprestanda. Utanför jobbet tycker han om att spela piano.
Jianzhe Xiao är en Senior Software Engineer Team Lead i AML Team på ByteDance. Hans nuvarande arbete fokuserar på att hjälpa affärsteamet att påskynda modellimplementeringsprocessen och förbättra modellens slutledningsprestanda. Utanför jobbet tycker han om att spela piano.
 Tian Shi är Senior Solutions Architect på AWS. Hans fokusområde är dataanalys, maskininlärning och serverlös. Han brinner för att hjälpa kunder att designa och bygga pålitliga och skalbara lösningar på molnet. På fritiden tycker han om att bada och läsa.
Tian Shi är Senior Solutions Architect på AWS. Hans fokusområde är dataanalys, maskininlärning och serverlös. Han brinner för att hjälpa kunder att designa och bygga pålitliga och skalbara lösningar på molnet. På fritiden tycker han om att bada och läsa.
 Jia Dong är Customer Solutions Manager på AWS. Hon tycker om att lära sig om AWS AI/ML-tjänster och hjälpa kunder att möta sina affärsresultat genom att bygga lösningar för dem. Utanför jobbet tycker Jia om att resa, yoga och filmer.
Jia Dong är Customer Solutions Manager på AWS. Hon tycker om att lära sig om AWS AI/ML-tjänster och hjälpa kunder att möta sina affärsresultat genom att bygga lösningar för dem. Utanför jobbet tycker Jia om att resa, yoga och filmer.
 Jonathan Lunt är en mjukvaruingenjör på Amazon med fokus på ML-ramverksutveckling. Under sin karriär har han arbetat genom hela bredden av datavetenskapliga roller inklusive modellutveckling, infrastrukturinstallation och hårdvaruspecifik optimering.
Jonathan Lunt är en mjukvaruingenjör på Amazon med fokus på ML-ramverksutveckling. Under sin karriär har han arbetat genom hela bredden av datavetenskapliga roller inklusive modellutveckling, infrastrukturinstallation och hårdvaruspecifik optimering.
 Joshua Hannan är maskininlärningsingenjör på Amazon. Han arbetar med att optimera modeller för djupinlärning för storskaliga datorseende och naturliga språkbehandlingsapplikationer.
Joshua Hannan är maskininlärningsingenjör på Amazon. Han arbetar med att optimera modeller för djupinlärning för storskaliga datorseende och naturliga språkbehandlingsapplikationer.
 Shruti Koparkar är Senior Product Marketing Manager på AWS. Hon hjälper kunder att utforska, utvärdera och använda EC2 accelererad datorinfrastruktur för deras maskininlärningsbehov.
Shruti Koparkar är Senior Product Marketing Manager på AWS. Hon hjälper kunder att utforska, utvärdera och använda EC2 accelererad datorinfrastruktur för deras maskininlärningsbehov.
- Myntsmart. Europas bästa bitcoin- och kryptobörs.Klicka här
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/bytedance-saves-up-to-60-on-inference-costs-while-reducing-latency-and-increasing-throughput-using-aws-inferentia/

