Ökningen av kontextuella och semantiska sökningar har gjort e-handels- och detaljhandelsföretag att söka enkelt för sina konsumenter. Sökmotorer och rekommendationssystem som drivs av generativ AI kan förbättra produktsökningsupplevelsen exponentiellt genom att förstå naturliga språkfrågor och ge mer exakta resultat. Detta förbättrar den övergripande användarupplevelsen och hjälper kunderna att hitta precis vad de letar efter.
Amazon OpenSearch Service stöder nu cosinuslikhet mått för k-NN-index. Cosinuslikhet mäter cosinus för vinkeln mellan två vektorer, där en mindre cosinusvinkel anger en högre likhet mellan vektorerna. Med cosinuslikhet kan du mäta orienteringen mellan två vektorer, vilket gör det till ett bra val för vissa specifika semantiska sökapplikationer.
I det här inlägget visar vi hur man bygger en kontextuell text- och bildsökmotor för produktrekommendationer med hjälp av Amazon Titan Multimodal Embeddings modell, tillgänglig i Amazonas berggrund, med Amazon OpenSearch Serverlös.
En multimodal inbäddningsmodell är utformad för att lära sig gemensamma representationer av olika modaliteter som text, bilder och ljud. Genom att träna på storskaliga datamängder som innehåller bilder och deras motsvarande bildtexter, lär sig en multimodal inbäddningsmodell att bädda in bilder och texter i ett delat latent utrymme. Följande är en översikt på hög nivå av hur det fungerar konceptuellt:
- Separata kodare – Dessa modeller har separata kodare för varje modalitet – en textkodare för text (till exempel BERT eller RoBERTa), bildkodare för bilder (till exempel CNN för bilder) och ljudkodare för ljud (till exempel modeller som Wav2Vec) . Varje kodare genererar inbäddningar som fångar semantiska egenskaper hos deras respektive modaliteter
- Modalitetsfusion – Inbäddningarna från de unimodala kodarna kombineras med hjälp av ytterligare neurala nätverksskikt. Målet är att lära sig interaktioner och samband mellan modaliteterna. Vanliga fusionsmetoder inkluderar sammanlänkning, elementvisa operationer, pooling och uppmärksamhetsmekanismer.
- Delat representationsutrymme – Fusionslagren hjälper till att projicera de individuella modaliteterna till ett delat representationsutrymme. Genom att träna på multimodala datamängder lär sig modellen ett gemensamt inbäddningsutrymme där inbäddningar från varje modalitet som representerar samma underliggande semantiska innehåll ligger närmare varandra.
- Nedströms uppgifter – De gemensamma multimodala inbäddningarna som genereras kan sedan användas för olika nedströmsuppgifter som multimodal hämtning, klassificering eller översättning. Modellen använder korrelationer mellan olika modaliteter för att förbättra prestanda för dessa uppgifter jämfört med individuella modala inbäddningar. Den viktigaste fördelen är förmågan att förstå interaktioner och semantik mellan modaliteter som text, bilder och ljud genom gemensam modellering.
Lösningsöversikt
Lösningen tillhandahåller en implementering för att bygga en sökmotordriven prototyp för en stor språkmodell (LLM) för att hämta och rekommendera produkter baserat på text- eller bildfrågor. Vi beskriver stegen för att använda en Amazon Titan multimodala inbäddningar modell för att koda bilder och text till inbäddningar, mata in inbäddningar i ett OpenSearch Service-index och fråga efter indexet med OpenSearch Service k-närmaste grannar (k-NN) funktionalitet.
Denna lösning innehåller följande komponenter:
- Amazon Titan Multimodal Embeddings modell – Den här grundmodellen (FM) genererar inbäddningar av produktbilderna som används i det här inlägget. Med Amazon Titan Multimodal Embeddings kan du generera inbäddningar för ditt innehåll och lagra dem i en vektordatabas. När en slutanvändare skickar in en kombination av text och bild som en sökfråga, genererar modellen inbäddningar för sökfrågan och matchar dem med de lagrade inbäddningarna för att ge slutanvändarna relevanta sök- och rekommendationsresultat. Du kan ytterligare anpassa modellen för att förbättra dess förståelse av ditt unika innehåll och ge mer meningsfulla resultat genom att använda bild-text-par för finjustering. Som standard genererar modellen vektorer (inbäddningar) med 1,024 XNUMX dimensioner och nås via Amazon Bedrock. Du kan också generera mindre dimensioner för att optimera för hastighet och prestanda
- Amazon OpenSearch Serverlös – Det är en on-demand-serverlös konfiguration för OpenSearch Service. Vi använder Amazon OpenSearch Serverless som en vektordatabas för att lagra inbäddningar genererade av Amazon Titan Multimodal Embeddings-modellen. Ett index skapat i Amazon OpenSearch Serverless-samlingen fungerar som vektorlager för vår Retrieval Augmented Generation (RAG)-lösning.
- Amazon SageMaker Studio – Det är en integrerad utvecklingsmiljö (IDE) för maskininlärning (ML). ML-utövare kan utföra alla ML-utvecklingssteg – från att förbereda dina data till att bygga, träna och distribuera ML-modeller.
Lösningsdesignen består av två delar: dataindexering och kontextuell sökning. Under dataindexering bearbetar du produktbilderna för att generera inbäddningar för dessa bilder och fyller sedan i vektordatalagret. Dessa steg slutförs innan användarinteraktionsstegen.
I den kontextuella sökfasen konverteras en sökfråga (text eller bild) från användaren till inbäddningar och en likhetssökning körs på vektordatabasen för att hitta liknande produktbilder baserat på likhetssökning. Du visar sedan de översta liknande resultaten. All kod för detta inlägg finns tillgänglig i GitHub repo.
Följande diagram illustrerar lösningsarkitekturen.
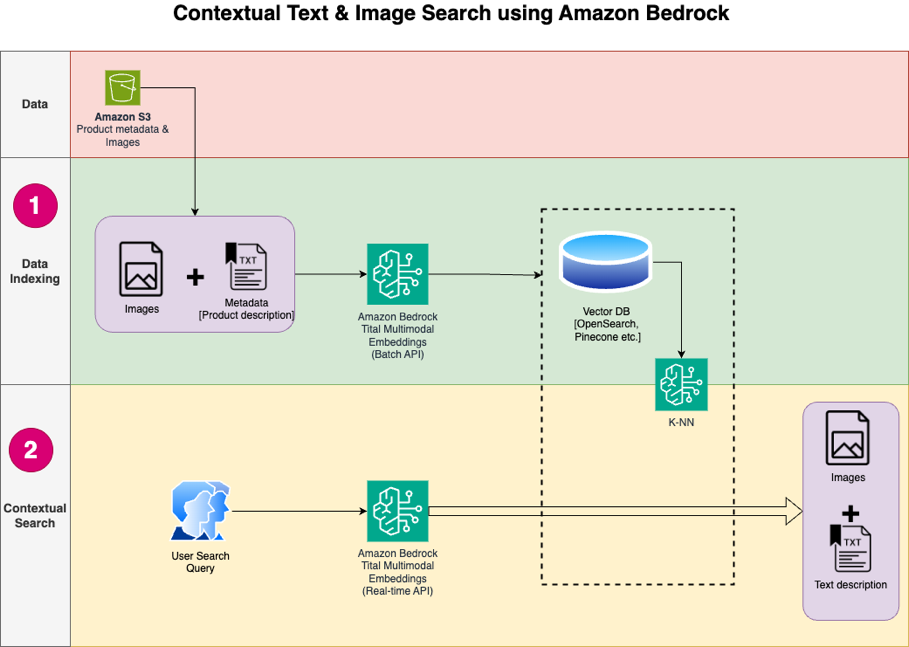
Följande är stegen för lösningens arbetsflöde:
- Ladda ner produktbeskrivningstext och bilder från allmänheten Amazon enkel lagringstjänst (Amazon S3) hink.
- Granska och förbered datasetet.
- Generera inbäddningar för produktbilderna med Amazon Titan Multimodal Embeddings-modellen (amazon.titan-embed-image-v1). Om du har ett stort antal bilder och beskrivningar kan du valfritt använda Batch slutledning för Amazon Bedrock.
- Lagra inbäddningar i Amazon OpenSearch Serverlös som sökmotor.
- Slutligen, hämta användarfrågan på naturligt språk, konvertera den till inbäddningar med Amazon Titan Multimodal Embeddings-modellen och utför en k-NN-sökning för att få relevanta sökresultat.
Vi använder SageMaker Studio (visas inte i diagrammet) som IDE för att utveckla lösningen.
Dessa steg diskuteras i detalj i följande avsnitt. Vi inkluderar även skärmdumpar och detaljer om resultatet.
Förutsättningar
För att implementera lösningen som tillhandahålls i det här inlägget bör du ha följande:
- An AWS-konto och förtrogenhet med FMs, Amazon Bedrock, Amazon SageMakeroch OpenSearch Service.
- Amazon Titan Multimodal Embeddings-modellen aktiverad i Amazon Bedrock. Du kan bekräfta att det är aktiverat på Modellåtkomst sidan av Amazon Bedrock-konsolen. Om Amazon Titan Multimodal Embeddings är aktiverat kommer åtkomststatusen att visas som Tillgång beviljad, som visas i följande skärmdump.

Om modellen inte är tillgänglig, aktivera åtkomst till modellen genom att välja Hantera modellåtkomst, väljer Amazon Titan Multimodal Embeddings G1, och välja Begär modellåtkomst. Modellen är aktiverad för användning omedelbart.

Ställ in lösningen
När de nödvändiga stegen är klara är du redo att konfigurera lösningen:
- Öppna SageMaker-konsolen i ditt AWS-konto och välj Studio i navigeringsfönstret.
- Välj din domän och användarprofil och välj sedan Öppen studio.
Ditt domän- och användarprofilnamn kan skilja sig åt.

- Välja Systemterminal under Verktyg och filer.
- Kör följande kommando för att klona GitHub repo till SageMaker Studio-instansen:
- Navigera till
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2emapp. - Öppna
titan_mm_embed_search_blog.ipynbanteckningsbok.
Kör lösningen
Öppna filen titan_mm_embed_search_blog.ipynb och använd Data Science Python 3-kärnan. På Körning meny, välj Kör alla celler för att köra koden i den här anteckningsboken.
Den här anteckningsboken utför följande steg:
- Installera de paket och bibliotek som krävs för den här lösningen.
- Ladda den allmänt tillgängliga Amazon Berkeley Objects Dataset och metadata i en pandas dataram.
Datauppsättningen är en samling av 147,702 398,212 produktlistor med flerspråkig metadata och 1,600 XNUMX unika katalogbilder. För det här inlägget använder du bara objektbilderna och objektnamnen på amerikansk engelska. Du använder cirka XNUMX XNUMX produkter.

- Generera inbäddningar för objektbilderna med Amazon Titan Multimodal Embeddings-modellen med hjälp av
get_titan_multomodal_embedding()fungera. För abstraktionens skull har vi definierat alla viktiga funktioner som används i den här anteckningsboken iutils.pyfil.

Därefter skapar och ställer du in en Amazon OpenSearch Serverless vektorbutik (insamling och index).
- Innan du skapar den nya vektorsökningssamlingen och indexet måste du först skapa tre associerade OpenSearch Service-policyer: krypteringssäkerhetspolicyn, nätverkssäkerhetspolicyn och dataåtkomstpolicyn.

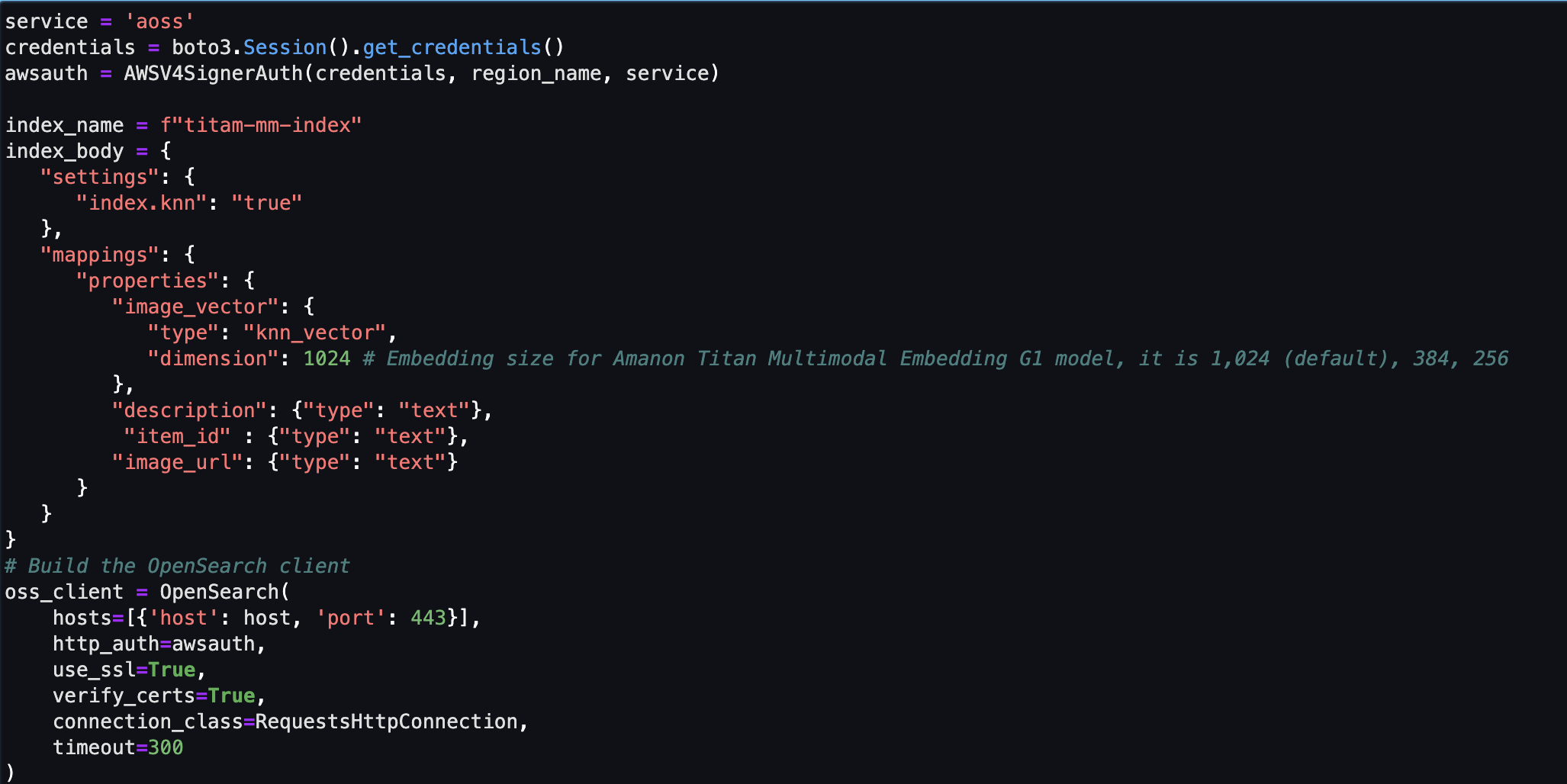
- Slutligen, mata in bilden som bäddas in i vektorindexet.
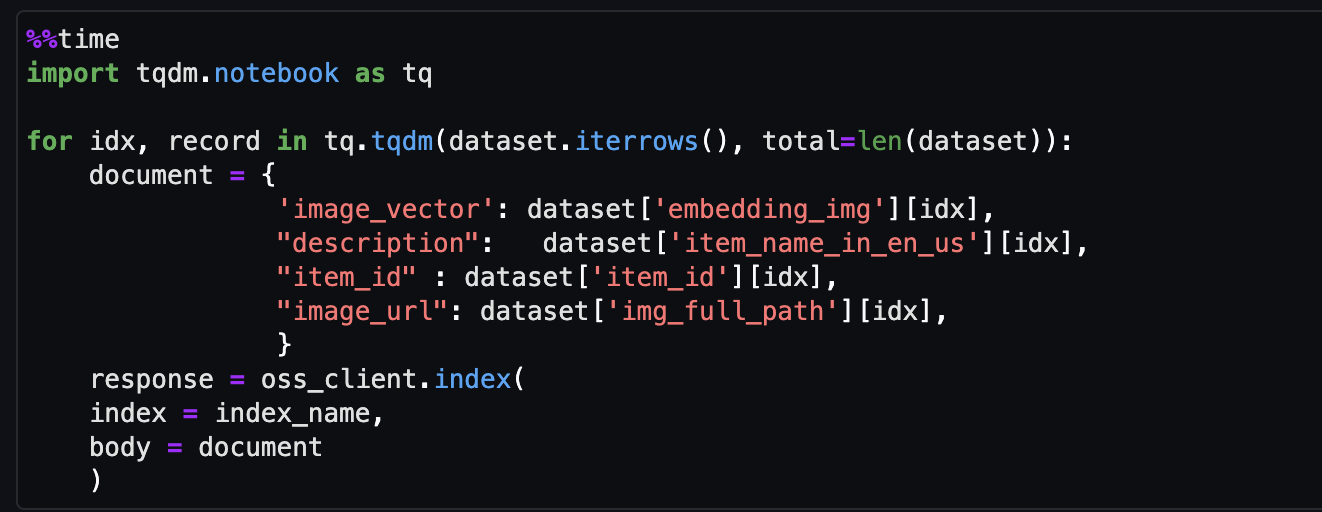
Nu kan du utföra en multimodal sökning i realtid.
Kör en kontextuell sökning
I det här avsnittet visar vi resultaten av kontextuell sökning baserat på en text- eller bildfråga.
Låt oss först göra en bildsökning baserat på textinmatning. I följande exempel använder vi textinmatningen "drinkware glass" och skickar den till sökmotorn för att hitta liknande föremål.
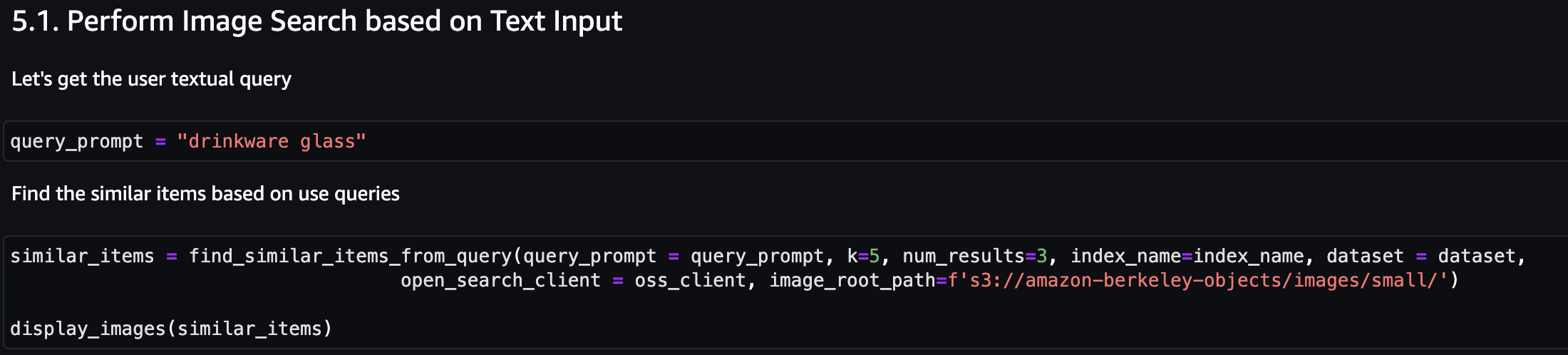
Följande skärmdump visar resultaten.

Låt oss nu titta på resultaten baserat på en enkel bild. Inmatningsbilden konverteras till vektorinbäddningar och, baserat på likhetssökningen, returnerar modellen resultatet.
Du kan använda vilken bild som helst, men för följande exempel använder vi en slumpmässig bild från datamängden baserad på artikel-ID (till exempel, item_id = "B07JCDQWM6") och skicka sedan den här bilden till sökmotorn för att hitta liknande objekt.

Följande skärmdump visar resultaten.

Städa upp
Ta bort resurserna som används i den här lösningen för att undvika framtida avgifter. Du kan göra detta genom att köra rensningsavsnittet i anteckningsboken.

Slutsats
Det här inlägget presenterade en genomgång av att använda Amazon Titan Multimodal Embeddings-modellen i Amazon Bedrock för att bygga kraftfulla kontextuella sökapplikationer. I synnerhet visade vi ett exempel på en produktsökningsapplikation. Vi såg hur inbäddningsmodellen möjliggör effektiv och korrekt upptäckt av information från bilder och textdata, och därigenom förbättrar användarupplevelsen när man söker efter relevanta föremål.
Amazon Titan Multimodal Embeddings hjälper dig att driva mer exakta och kontextuellt relevanta multimodala sökningar, rekommendationer och personaliseringsupplevelser för slutanvändare. Till exempel kan ett bildbanksföretag med hundratals miljoner bilder använda modellen för att driva sin sökfunktion, så att användare kan söka efter bilder med en fras, bild eller en kombination av bild och text.
Amazon Titan Multimodal Embeddings-modellen i Amazon Bedrock är nu tillgänglig i AWS-regionerna i USA:s öst (N. Virginia) och västra USA (Oregon). För att lära dig mer, se Amazon Titan Image Generator, Multimodal Embeddings och Text-modeller är nu tillgängliga i Amazon Bedrock, den Amazon Titan produktsida, Och den Amazon Bedrock användarguide. För att komma igång med Amazon Titan Multimodal Embeddings i Amazon Bedrock, besök Amazon Bedrock-konsol.
Börja bygga med Amazon Titan Multimodal Embeddings-modellen i Amazonas berggrund i dag.
Om författarna
 Sandeep Singh är Senior Generative AI Data Scientist på Amazon Web Services, som hjälper företag att förnya sig med generativ AI. Han är specialiserad på generativ AI, artificiell intelligens, maskininlärning och systemdesign. Han brinner för att utveckla toppmoderna AI/ML-drivna lösningar för att lösa komplexa affärsproblem för olika branscher, optimera effektivitet och skalbarhet.
Sandeep Singh är Senior Generative AI Data Scientist på Amazon Web Services, som hjälper företag att förnya sig med generativ AI. Han är specialiserad på generativ AI, artificiell intelligens, maskininlärning och systemdesign. Han brinner för att utveckla toppmoderna AI/ML-drivna lösningar för att lösa komplexa affärsproblem för olika branscher, optimera effektivitet och skalbarhet.
 Mani Khanuja är en Tech Lead – Generative AI Specialists, författare till boken Applied Machine Learning and High Performance Computing på AWS, och medlem i styrelsen för Women in Manufacturing Education Foundation Board. Hon leder maskininlärningsprojekt inom olika domäner som datorseende, naturlig språkbehandling och generativ AI. Hon talar på interna och externa konferenser som AWS re:Invent, Women in Manufacturing West, YouTube-webinarier och GHC 23. På fritiden gillar hon att gå långa löpturer längs stranden.
Mani Khanuja är en Tech Lead – Generative AI Specialists, författare till boken Applied Machine Learning and High Performance Computing på AWS, och medlem i styrelsen för Women in Manufacturing Education Foundation Board. Hon leder maskininlärningsprojekt inom olika domäner som datorseende, naturlig språkbehandling och generativ AI. Hon talar på interna och externa konferenser som AWS re:Invent, Women in Manufacturing West, YouTube-webinarier och GHC 23. På fritiden gillar hon att gå långa löpturer längs stranden.
 Rupinder Grewal är Senior AI/ML Specialist Solutions Architect med AWS. Han fokuserar för närvarande på servering av modeller och MLOps på Amazon SageMaker. Innan denna roll arbetade han som maskininlärningsingenjör med att bygga och vara värdmodeller. Utanför jobbet tycker han om att spela tennis och cykla på bergsstigar.
Rupinder Grewal är Senior AI/ML Specialist Solutions Architect med AWS. Han fokuserar för närvarande på servering av modeller och MLOps på Amazon SageMaker. Innan denna roll arbetade han som maskininlärningsingenjör med att bygga och vara värdmodeller. Utanför jobbet tycker han om att spela tennis och cykla på bergsstigar.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

