Det här blogginlägget är skrivet tillsammans med Caroline Chung från Veoneer.
Veoneer är ett globalt fordonselektronikföretag och världsledande inom elektroniska säkerhetssystem för fordon. De erbjuder klassens bästa säkerhetskontrollsystem och har levererat över 1 miljard elektroniska styrenheter och krocksensorer till biltillverkare globalt. Företaget fortsätter att bygga på en 70-årig historia av bilsäkerhetsutveckling, specialiserat på banbrytande hårdvara och system som förhindrar trafikincidenter och mildrar olyckor.
Automotive in-cabin sensing (ICS) är ett framväxande utrymme som använder en kombination av flera typer av sensorer som kameror och radar, och artificiell intelligens (AI) och maskininlärning (ML) baserade algoritmer för att förbättra säkerheten och förbättra körupplevelsen. Att bygga ett sådant system kan vara en komplicerad uppgift. Utvecklare måste manuellt kommentera stora volymer bilder för utbildnings- och testsyften. Detta är mycket tidskrävande och resurskrävande. Handläggningstiden för en sådan uppgift är flera veckor. Dessutom måste företag hantera frågor som inkonsekventa märkningar på grund av mänskliga fel.
AWS är fokuserat på att hjälpa dig att öka din utvecklingshastighet och sänka dina kostnader för att bygga sådana system genom avancerad analys som ML. Vår vision är att använda ML för automatiserad annotering, möjliggöra omskolning av säkerhetsmodeller och säkerställa konsekventa och tillförlitliga prestandamått. I det här inlägget delar vi hur, genom att samarbeta med Amazons Worldwide Specialist Organization och Generativt AI Innovation Center, utvecklade vi en aktiv inlärningspipeline för begränsningsrutor för bildhuvuden i kabinen och anteckningar för nyckelpunkter. Lösningen minskar kostnaderna med över 90 %, accelererar annoteringsprocessen från veckor till timmar när det gäller handläggningstiden och möjliggör återanvändning för liknande ML-datamärkningsuppgifter.
Lösningsöversikt
Aktivt lärande är en ML-metod som involverar en iterativ process för att välja och kommentera de mest informativa data för att träna en modell. Givet en liten uppsättning märkta data och en stor uppsättning omärkta data, förbättrar aktivt lärande modellens prestanda, minskar märkningsarbetet och integrerar mänsklig expertis för robusta resultat. I det här inlägget bygger vi en aktiv inlärningspipeline för bildkommentarer med AWS-tjänster.
Följande diagram visar det övergripande ramverket för vår pipeline för aktivt lärande. Märkningspipelinen tar bilder från en Amazon enkel lagringstjänst (Amazon S3) hinkar och matar ut kommenterade bilder i samarbete med ML-modeller och mänsklig expertis. Utbildningspipelinen förbehandlar data och använder dem för att träna ML-modeller. Den initiala modellen är inställd och tränad på en liten uppsättning manuellt märkta data, och kommer att användas i märkningspipelinen. Märkningspipeline och utbildningspipeline kan itereras gradvis med mer märkta data för att förbättra modellens prestanda.
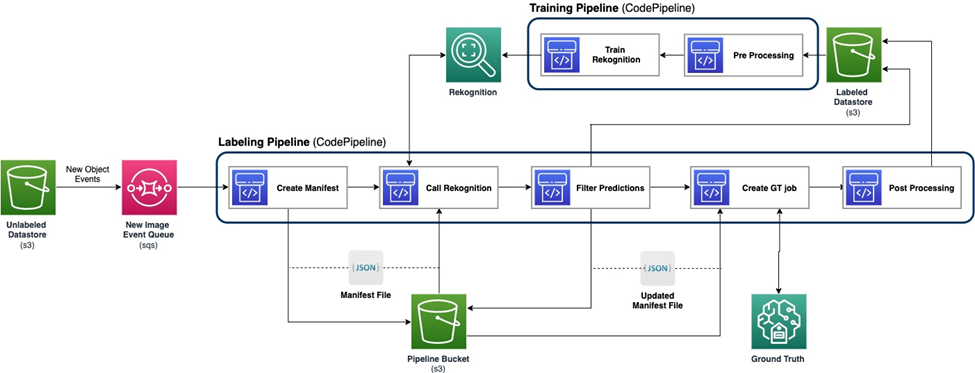
I märkning pipeline, en Amazon S3 händelsemeddelande anropas när ett nytt parti bilder kommer in i Unlabeled Datastore S3-hinken, vilket aktiverar märkningspipelinen. Modellen producerar slutledningsresultaten på de nya bilderna. En anpassad bedömningsfunktion väljer delar av data baserat på slutledningsförtroendepoängen eller andra användardefinierade funktioner. Dessa data, med dess slutledningsresultat, skickas för ett mänskligt märkningsjobb Amazon SageMaker Ground Sannhet skapad av pipelinen. Den mänskliga märkningsprocessen hjälper till att kommentera data, och de modifierade resultaten kombineras med återstående automatiskt kommenterade data, som kan användas senare av utbildningspipeline.
Modellomskolning sker i utbildningspipelinen, där vi använder datamängden som innehåller människomärkta data för att träna om modellen. En manifestfil tas fram för att beskriva var filerna lagras, och samma initiala modell tränas om på den nya datan. Efter omskolning ersätter den nya modellen den ursprungliga modellen, och nästa iteration av den aktiva inlärningspipelinen startar.
Modelldistribution
Både märkningspipeline och utbildningspipeline är utplacerade på AWS CodePipeline. AWS CodeBuild instanser används för implementering, vilket är flexibelt och snabbt för en liten mängd data. När fart behövs använder vi Amazon SageMaker slutpunkter baserade på GPU-instansen för att allokera mer resurser för att stödja och påskynda processen.
Modellens omskolningspipeline kan anropas när det finns en ny datauppsättning eller när modellens prestanda behöver förbättras. En kritisk uppgift i omskolningspipelinen är att ha versionskontrollsystemet för både träningsdata och modell. Även om AWS-tjänster som t.ex Amazon-erkännande har den integrerade versionskontrollfunktionen, vilket gör pipelinen enkel att implementera, anpassade modeller kräver metadataloggning eller ytterligare versionskontrollverktyg.
Hela arbetsflödet implementeras med hjälp av AWS Cloud Development Kit (AWS CDK) för att skapa nödvändiga AWS-komponenter, inklusive följande:
- Två roller för CodePipeline och SageMaker jobb
- Två CodePipeline-jobb, som orkestrerar arbetsflödet
- Två S3-hinkar för kodartefakterna för rörledningarna
- En S3-hink för märkning av jobbmanifest, datauppsättningar och modeller
- För- och efterbearbetning AWS Lambda funktioner för SageMaker Ground Truth-märkningsjobb
AWS CDK-stackarna är mycket modulariserade och återanvändbara för olika uppgifter. Utbildningen, slutledningskoden och SageMaker Ground Truth-mallen kan ersättas för alla liknande aktiva lärandescenarier.
Modellutbildning
Modellträning inkluderar två uppgifter: anteckning av huvudgränsruta och anteckning av mänskliga nyckelpunkter. Vi presenterar dem båda i det här avsnittet.
Anteckning för huvudbegränsningsram
Anteckning för huvudbegränsningsruta är en uppgift för att förutsäga platsen för en avgränsningsram av det mänskliga huvudet i en bild. Vi använder en Amazon Rekognition anpassade etiketter modell för anteckningar för huvudbegränsande rutor. Det följande prov anteckningsbok ger en steg-för-steg handledning om hur man tränar en Rekognition Custom Labels-modell via SageMaker.
Vi måste först förbereda data för att starta utbildningen. Vi genererar en manifestfil för utbildningen och en manifestfil för testdatauppsättningen. En manifestfil innehåller flera objekt, som var och en är för en bild. Följande är ett exempel på manifestfilen, som inkluderar bildsökväg, storlek och anteckningsinformation:
Med hjälp av manifestfilerna kan vi ladda datauppsättningar till en Rekognition Custom Labels-modell för utbildning och testning. Vi itererade modellen med olika mängder träningsdata och testade den på samma 239 osynliga bilder. I detta test, mAP_50 poängen ökade från 0.33 med 114 träningsbilder till 0.95 med 957 träningsbilder. Följande skärmdump visar prestandamåtten för den slutliga Rekognition Custom Labels-modellen, som ger bra prestanda när det gäller F1-poäng, precision och återkallelse.

Vi testade vidare modellen på en undanhållen datauppsättning som har 1,128 XNUMX bilder. Modellen förutsäger konsekvent exakta begränsningsrutaförutsägelser på osynliga data, vilket ger en hög mAP_50 på 94.9 %. Följande exempel visar en automatiskt kommenterad bild med en huvudavgränsningsruta.

Viktiga punkter anteckning
Nyckelpunkters anteckning producerar placeringar av nyckelpunkter, inklusive ögon, öron, näsa, mun, nacke, axlar, armbågar, handleder, höfter och vrister. Utöver platsförutsägelsen behövs synlighet för varje punkt för att förutsäga i denna specifika uppgift, för vilken vi designar en ny metod.
För nyckelpunktsanteckningar använder vi en Yolo 8 Pose modell på SageMaker som den ursprungliga modellen. Vi förbereder först data för utbildning, inklusive generering av etikettfiler och en konfigurations-.yaml-fil enligt Yolos krav. Efter att ha förberett datat tränar vi modellen och sparar artefakter, inklusive modellviktsfilen. Med den tränade modellviktsfilen kan vi kommentera de nya bilderna.
I träningsstadiet används alla märkta punkter med platser, inklusive synliga punkter och tilltäppta punkter, för träning. Därför tillhandahåller denna modell som standard platsen och förtroendet för förutsägelsen. I följande figur kan ett stort konfidensgränsvärde (huvudtröskel) nära 0.6 dela de punkter som är synliga eller tilltäppta jämfört med utanför kamerans synpunkter. Dock separeras inte tilltäppta punkter och synliga punkter av konfidensen, vilket innebär att den förutspådda konfidensen inte är användbar för att förutsäga synligheten.

För att få en förutsägelse av synlighet introducerar vi ytterligare en modell som tränas på datamängden som endast innehåller synliga punkter, exklusive både ockluderade punkter och utanför kamerans synpunkter. Följande figur visar fördelningen av punkter med olika sikt. Synliga punkter och andra punkter kan separeras i tilläggsmodellen. Vi kan använda en tröskel (extra tröskel) nära 0.6 för att få de synliga punkterna. Genom att kombinera dessa två modeller designar vi en metod för att förutsäga läge och synlighet.

En nyckelpunkt förutsägs först av huvudmodellen med plats och huvudkonfidens, sedan får vi den extra konfidensförutsägelsen från tilläggsmodellen. Dess synlighet klassificeras sedan enligt följande:
- Synlig, om dess huvudsakliga konfidens är större än dess huvudtröskel, och dess ytterligare konfidens är större än den extra tröskeln
- Ockluderad, om dess huvudsakliga konfidens är större än dess huvudtröskel, och dess ytterligare konfidens är mindre än eller lika med den extra tröskeln
- Utanför kamerans granskning, om annat
Ett exempel på nyckelpunkterskommentarer visas i följande bild, där heldragna märken är synliga punkter och ihåliga märken är tilltäppta punkter. Utanför kamerans granskningspunkter visas inte.

Baserat på standarden OKS definition på MS-COCO-datauppsättningen kan vår metod uppnå mAP_50 på 98.4 % på den osynliga testdatauppsättningen. När det gäller synlighet ger metoden en klassificeringsnoggrannhet på 79.2 % på samma datauppsättning.
Mänsklig märkning och omskolning
Även om modellerna uppnår bra prestanda på testdata finns det fortfarande möjligheter att göra misstag på nya verkliga data. Mänsklig märkning är processen för att korrigera dessa misstag för att förbättra modellens prestanda med hjälp av omskolning. Vi designade en bedömningsfunktion som kombinerade konfidensvärdet som matas ut från ML-modellerna för utmatningen av alla head bounding box eller nyckelpunkter. Vi använder slutresultatet för att identifiera dessa misstag och de resulterande dåliga märkta bilderna, som måste skickas till den mänskliga märkningsprocessen.
Förutom dåliga märkta bilder väljs en liten del av bilderna slumpmässigt ut för mänsklig märkning. Dessa människomärkta bilder läggs till i den aktuella versionen av träningsuppsättningen för omträning, förbättring av modellens prestanda och övergripande anteckningsnoggrannhet.
I implementeringen använder vi SageMaker Ground Truth för mänsklig märkning bearbeta. SageMaker Ground Truth tillhandahåller ett användarvänligt och intuitivt användargränssnitt för datamärkning. Följande skärmdump visar ett SageMaker Ground Truth-märkningsjobb för annotering av head bounding box.

Följande skärmdump visar ett SageMaker Ground Truth-märkningsjobb för nyckelpunkterskommentarer.

Kostnad, hastighet och återanvändbarhet
Kostnad och hastighet är de viktigaste fördelarna med att använda vår lösning jämfört med mänsklig märkning, som visas i följande tabeller. Vi använder dessa tabeller för att representera kostnadsbesparingarna och hastighetsaccelerationerna. Genom att använda den accelererade GPU SageMaker-instansen ml.g4dn.xlarge är hela livets tränings- och slutledningskostnad på 100,000 99 bilder 10 % lägre än kostnaden för mänsklig märkning, medan hastigheten är 10,000–XNUMX XNUMX gånger snabbare än mänsklig märkning, beroende på uppgift.
Den första tabellen sammanfattar kostnadsprestandamåtten.
| Modell | mAP_50 baserat på 1,128 XNUMX testbilder | Utbildningskostnad baserad på 100,000 XNUMX bilder | Slutsatskostnad baserad på 100,000 XNUMX bilder | Kostnadsminskning jämfört med mänsklig anteckning | Slutledningstid baserad på 100,000 XNUMX bilder | Tidsacceleration jämfört med mänsklig kommentar |
| Erkännande huvud avgränsning box | 0.949 | $4 | $22 | 99% mindre | 5.5 h | Dagar |
| Yolo Nyckelpunkter | 0.984 | $27.20 | * $ 10 | 99.9% mindre | minuter | veckor |
Följande tabell sammanfattar resultatstatistik.
| Anteckningsuppgift | mAP_50 (%) | Utbildningskostnad ($) | Slutledningskostnad ($) | Slutledningstid |
| Head bounding Box | 94.9 | 4 | 22 | 5.5 timmar |
| Viktiga punkter | 98.4 | 27 | 10 | 5 minuter |
Dessutom ger vår lösning återanvändbarhet för liknande uppgifter. Utveckling av kamerauppfattning för andra system som avancerade förarassistanssystem (ADAS) och system i kabinen kan också använda vår lösning.
Sammanfattning
I det här inlägget visade vi hur man bygger en aktiv inlärningspipeline för automatisk annotering av bilder i kabinen med hjälp av AWS-tjänster. Vi visar kraften i ML, som gör att du kan automatisera och påskynda anteckningsprocessen, och flexibiliteten i ramverket som använder modeller som antingen stöds av AWS-tjänster eller anpassade på SageMaker. Med Amazon S3, SageMaker, Lambda och SageMaker Ground Truth kan du effektivisera datalagring, anteckningar, utbildning och driftsättning och uppnå återanvändbarhet samtidigt som du sänker kostnaderna avsevärt. Genom att implementera den här lösningen kan fordonsföretag bli mer smidiga och kostnadseffektiva genom att använda ML-baserad avancerad analys som automatisk bildkommentar.
Kom igång idag och lås upp kraften i AWS-tjänster och maskininlärning för dina användningsfall för avkänning av fordon i kabinen!
Om författarna
 Yanxiang Yu är en tillämpad forskare vid Amazon Generative AI Innovation Center. Med över 9 års erfarenhet av att bygga AI- och maskininlärningslösningar för industriella applikationer, är han specialiserad på generativ AI, datorseende och tidsseriemodellering.
Yanxiang Yu är en tillämpad forskare vid Amazon Generative AI Innovation Center. Med över 9 års erfarenhet av att bygga AI- och maskininlärningslösningar för industriella applikationer, är han specialiserad på generativ AI, datorseende och tidsseriemodellering.
 Tianyi Mao är en tillämpad forskare vid AWS baserad från Chicago-området. Han har 5+ års erfarenhet av att bygga lösningar för maskininlärning och djupinlärning och fokuserar på datorseende och förstärkningsinlärning med mänsklig feedback. Han tycker om att arbeta med kunder för att förstå deras utmaningar och lösa dem genom att skapa innovativa lösningar med hjälp av AWS-tjänster.
Tianyi Mao är en tillämpad forskare vid AWS baserad från Chicago-området. Han har 5+ års erfarenhet av att bygga lösningar för maskininlärning och djupinlärning och fokuserar på datorseende och förstärkningsinlärning med mänsklig feedback. Han tycker om att arbeta med kunder för att förstå deras utmaningar och lösa dem genom att skapa innovativa lösningar med hjälp av AWS-tjänster.
 Yanru Xiao är en tillämpad forskare vid Amazon Generative AI Innovation Center, där han bygger AI/ML-lösningar för kunders verkliga affärsproblem. Han har arbetat inom flera områden, inklusive tillverkning, energi och jordbruk. Yanru fick sin Ph.D. i datavetenskap från Old Dominion University.
Yanru Xiao är en tillämpad forskare vid Amazon Generative AI Innovation Center, där han bygger AI/ML-lösningar för kunders verkliga affärsproblem. Han har arbetat inom flera områden, inklusive tillverkning, energi och jordbruk. Yanru fick sin Ph.D. i datavetenskap från Old Dominion University.
 Paul George är en erfaren produktledare med över 15 års erfarenhet av fordonsteknik. Han är skicklig på att leda produktledning, strategi, Go-to-Market och systemteknikteam. Han har inkuberat och lanserat flera nya avkännings- och perceptionsprodukter globalt. På AWS leder han strategi och go-to-market för autonoma fordonsarbetsbelastningar.
Paul George är en erfaren produktledare med över 15 års erfarenhet av fordonsteknik. Han är skicklig på att leda produktledning, strategi, Go-to-Market och systemteknikteam. Han har inkuberat och lanserat flera nya avkännings- och perceptionsprodukter globalt. På AWS leder han strategi och go-to-market för autonoma fordonsarbetsbelastningar.
 Caroline Chung är ingenjörschef på Veoneer (uppköpt av Magna International), hon har över 14 års erfarenhet av att utveckla avkännings- och perceptionssystem. Hon leder för närvarande förutvecklingsprogram för inredningsavkänning på Magna International och leder ett team av datorseende ingenjörer och datavetare.
Caroline Chung är ingenjörschef på Veoneer (uppköpt av Magna International), hon har över 14 års erfarenhet av att utveckla avkännings- och perceptionssystem. Hon leder för närvarande förutvecklingsprogram för inredningsavkänning på Magna International och leder ett team av datorseende ingenjörer och datavetare.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/build-an-active-learning-pipeline-for-automatic-annotation-of-images-with-aws-services/

