Beskrivning
I den här artikeln utforskar vi tillämpningen av GAN i TensorFlow för att generera unika återgivningar av handskrivna siffror. GAN-ramverket består av två nyckelkomponenter: generatorn och diskriminatorn. Generatorn genererar nya bilder på ett randomiserat sätt, medan diskriminatorn är utformad för att skilja mellan autentiska och förfalskade bilder. Genom GAN-utbildning får vi en samling bilder som liknar handskrivna siffror. Det primära syftet med denna artikel är att beskriva proceduren för att konstruera och utvärdera GAN:er med hjälp av MNIST-datauppsättning.
Inlärningsmål
- Den här artikeln ger en omfattande introduktion till Generativa Adversarial Networks (GAN) och utforskar deras tillämpningar för bildgenerering.
- Huvudsyftet med denna handledning är att vägleda läsare genom steg-för-steg-processen för att konstruera ett GAN med hjälp av TensorFlow-biblioteket. Det omfattar träning av GAN på MNIST-datauppsättningen för att generera nya bilder av handskrivna siffror.
- Artikeln diskuterar arkitekturen och komponenterna i GAN, inklusive generatorer och diskriminatorer, för att förbättra läsarnas förståelse för deras grundläggande funktion.
- För att underlätta inlärningen innehåller artikeln kodexempel som visar olika uppgifter, som att läsa och förbearbeta MNIST-datauppsättningen, bygga GAN-arkitekturen, beräkna förlustfunktioner, träna nätverket och utvärdera resultaten.
- Dessutom utforskar artikeln det förväntade resultatet av GAN, som är en samling bilder som har en slående likhet med handskrivna siffror.
Denna artikel publicerades som en del av Data Science Blogathon.
Innehållsförteckning
Vad bygger vi?
Att generera nya bilder med hjälp av redan existerande bilddatabaser är ett framträdande inslag i specialiserade modeller som kallas Generative Adversarial Networks (GAN). GAN:er utmärker sig i att producera oövervakade eller semi-övervakade bilder med hjälp av olika bilddatauppsättningar.
Den här artikeln utnyttjar bildgenereringspotentialen hos GAN:er för att skapa handskrivna siffror. Metodiken innebär att utbilda nätverket på en handskriven sifferdatabas. I det här instruktionsstycket kommer vi att konstruera en rudimentär GAN med hjälp av Tensorflow-biblioteket, genomföra utbildning på MNIST-datauppsättningen och generera färska bilder av handskrivna siffror.
Hur ställer vi upp detta?
Den primära tonvikten i den här artikeln kretsar kring att utnyttja bildgenereringspotentialen hos GAN. Proceduren börjar med laddning och förbearbetning av bilddatabasen för att underlätta GAN-utbildningsprocessen. När data väl har laddats, fortsätter vi att konstruera GAN-modellen och utveckla den nödvändiga koden för utbildning och testning. I det efterföljande avsnittet ges detaljerade instruktioner om hur du implementerar denna funktion och genererar en ny bild med hjälp av MNIST-databasen.
Modellbyggnad
Den GAN-modell vi vill bygga består av två viktiga komponenter:
- Generator: Den här komponenten är ansvarig för att generera nya bilder.
- Diskriminator: Den här komponenten utvärderar kvaliteten på den genererade bilden.
Den allmänna arkitekturen som vi kommer att utveckla för att generera bilder med GAN visas i diagrammet nedan. Följande avsnitt ger en kort beskrivning av hur man läser databasen, skapar den nödvändiga arkitekturen, beräknar förlustfunktionen och tränar nätverket. Dessutom tillhandahålls kod för att inspektera nätverket och generera nya bilder.
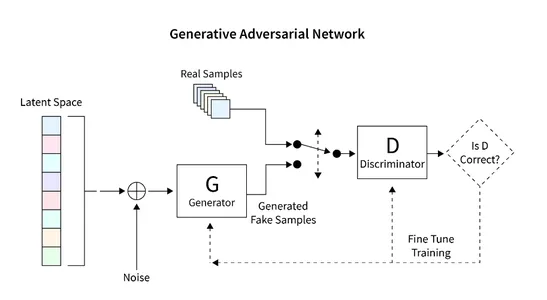
Läser datauppsättningen
MNIST-datauppsättningen har stor framträdande plats inom datorseende och omfattar en stor samling handskrivna siffror med dimensioner på 28×28 pixlar. Denna datauppsättning visar sig vara idealisk för vår GAN-implementering på grund av dess gråskala, enkanaliga bildformat.
Det efterföljande kodavsnittet visar användningen av en inbyggd funktion i Tensorflow för att ladda MNIST-datauppsättningen. Efter lyckad laddning fortsätter vi att normalisera och omforma bilderna till ett tredimensionellt format. Denna transformation möjliggör effektiv bearbetning av 2D-bilddata inom GAN-arkitekturen. Dessutom tilldelas minne för både tränings- och valideringsdata.
Formen på varje bild definieras som en 28x28x1 matris, där den sista dimensionen representerar antalet kanaler i bilden. Eftersom MNIST-datauppsättningen består av gråskalebilder har vi bara en enda kanal.
I det här specifika fallet ställer vi in storleken på det latenta utrymmet, betecknat som "zsize", till 100. Detta värde kan justeras enligt specifika krav eller preferenser.
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100 (train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3) valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
Definiera generatorn
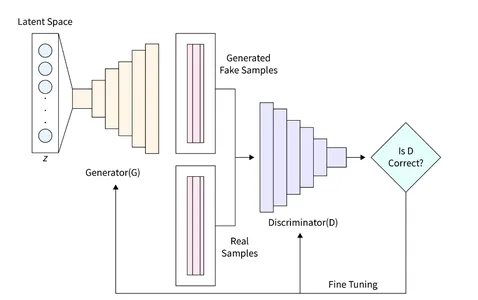
Generatorn (D) tar en avgörande roll i GAN eftersom den är ansvarig för att generera realistiska bilder som kan lura diskriminatorn. Den fungerar som den primära komponenten för bildbildning i GAN. I den här studien använder vi en specifik arkitektur för Generatorn, som innehåller ett helt anslutet (FC) lager och använder Leaky ReLU-aktivering. Det är dock värt att notera att det sista lagret av Generatorn använder TanH-aktivering istället för LeakyReLU. Denna justering gjordes för att säkerställa att den genererade bilden ligger inom samma intervall (-1, 1) som den ursprungliga MNIST-databasen.
def build_generator(): gen_model = Sequential() gen_model.add(Dense(256, input_dim=z_size)) gen_model.add(LeakyReLU(alpha=0.2)) gen_model.add(BatchNormalization(momentum=0.8)) gen_model.add(Dense(512)) gen_model.add(LeakyReLU(alpha=0.2)) gen_model.add(BatchNormalization(momentum=0.8)) gen_model.add(Dense(1024)) gen_model.add(LeakyReLU(alpha=0.2)) gen_model.add(BatchNormalization(momentum=0.8)) gen_model.add(Dense(np.prod(input_shape), activation='tanh')) gen_model.add(Reshape(input_shape)) gen_noise = Input(shape=(z_size,)) gen_img = gen_model(gen_noise) return Model(gen_noise, gen_img)
Definiera Diskriminatorn
I ett Generative Adversarial Network (GAN) utför Diskriminatorn (D) den kritiska uppgiften att skilja mellan verkliga bilder och genererade bilder genom att bedöma deras autenticitet och sannolikhet. Denna komponent kan ses som ett binärt klassificeringsproblem. För att ta itu med denna uppgift kan vi använda en förenklad nätverksarkitektur som omfattar Fully Connected Layers (FC), Leaky ReLU-aktivering och Dropout Layers. Det är viktigt att nämna att det sista lagret av Diskriminatorn inkluderar ett FC-lager följt av Sigmoid-aktivering. Sigmoid-aktiveringsfunktionen ger den önskade klassificeringssannolikheten.
def build_discriminator(): disc_model = Sequential() disc_model.add(Flatten(input_shape=input_shape)) disc_model.add(Dense(512)) disc_model.add(LeakyReLU(alpha=0.2)) disc_model.add(Dense(256)) disc_model.add(LeakyReLU(alpha=0.2)) disc_model.add(Dense(1, activation='sigmoid')) disc_img = Input(shape=input_shape) validity = disc_model(disc_img) return Model(disc_img, validity)
Beräknar förlustfunktionen
För att säkerställa en bra bildgenereringsprocess i GAN:er är det viktigt att fastställa lämpliga mätvärden för att utvärdera dess prestanda. Definiera denna parameter med förlustfunktionen.
Diskriminatorn ansvarar för att dela upp den genererade bilden i verklig eller falsk och ge sannolikheten att den är verklig. För att uppnå denna skillnad strävar Diskriminatorn efter att maximera funktionen D(x) när den presenteras med en verklig bild och minimera D(G(z)) när den presenteras med en falsk bild.
Å andra sidan är syftet med Generatorn att lura Diskriminatorn genom att skapa en realistisk bild som kan misstolkas. Matematiskt innebär detta att skala D(G(z)). Men att bara lita på denna komponent som en förlustfunktion kan göra att nätverket blir översäkert med felaktiga resultat. För att lösa detta problem använder vi loggen för förlustfunktionen (D(G(z)).
Den totala kostnadsfunktionen för GAN för att generera en bild kan uttryckas som ett minimalt spel:
min_G max_D V(D,G) = E(xp_data(x))(log(D(x))] + E(zp(z))(log(1 – D(G(z)))])
Sådan GAN-träning kräver en fin balans och kan ta som en match mellan två motståndare. Varje sida försöker påverka och överträffa den andra genom att spela MinMax-spelet.
Vi kan använda Binary Cross Entropy Loss för att implementera Generator och Discriminator.
För implementeringen av Generatorn och Diskriminatorn kan vi använda entropiförlusten för binärt kors.
# discriminator
disc= build_discriminator()
disc.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy']) z = Input(shape=(z_size,)) # generator
img = generator(z) disc.trainable = False validity = disc(img) # combined model
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
Optimera förlusten
För att underlätta utbildningen av nätverket är vårt mål att involvera GAN i ett MinMax-spel. Denna inlärningsprocess kretsar kring att optimera nätverkets vikter genom att använda Gradient Descent. För att påskynda inlärningsprocessen och förhindra konvergens till suboptimala förlustlandskap, används Stokastisk Gradient Descent (SGD).
Med tanke på att Diskriminatorn och Generatorn har distinkta förluster kan en enda förlustfunktion inte optimera båda systemen samtidigt. Använd därför de separata förlustfunktionerna för varje system.
def intialize_model(): disc= build_discriminator() disc.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy']) generator = build_generator() z = Input(shape=(z_size,)) img = generator(z) disc.trainable = False validity = disc(img) combined = Model(z, validity) combined.compile(loss='binary_crossentropy', optimizer='sgd') return disc, Generator, and combined
Efter att ha specificerat alla nödvändiga funktioner kan vi träna systemet och optimera förlusten. Stegen för att träna en GAN för att generera en bild är följande:
- Ladda bilden och generera ett slumpmässigt ljud av samma storlek som den laddade bilden.
- Gör skillnad på den uppladdade bilden och ljudet som produceras och överväg möjligheten av äkta eller falsk.
- Producera ytterligare ett slumpmässigt brus av samma storlek och tillhandahåll som input till generatorn.
- Träna generatorn under en viss period.
- Upprepa dessa steg tills bilden är tillfredsställande.
def train(epochs, batch_size=128, sample_interval=50): # load images (train_ims, _), (_, _) = mnist.load_data() # preprocess train_ims = train_ims / 127.5 - 1. train_ims = np.expand_dims(train_ims, axis=3) valid = np.ones((batch_size, 1)) fake = np.zeros((batch_size, 1)) # training loop for epoch in range(epochs): batch_index = np.random.randint(0, train_ims.shape[0], batch_size) imgs = train_ims[batch_index] # create noise noise = np.random.normal(0, 1, (batch_size, z_size)) # predict using a Generator gen_imgs = gen.predict(noise) # calculate loss functions real_disc_loss = disc.train_on_batch(imgs, valid) fake_disc_loss = disc.train_on_batch(gen_imgs, fake) disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss) noise = np.random.normal(0, 1, (batch_size, z_size)) g_loss = full_model.train_on_batch(noise, valid) # save outputs every few epochs if epoch % sample_interval == 0: one_batch(epoch)
Generera handskrivna siffror
Med hjälp av MNIST-datauppsättningen kan vi skapa en verktygsfunktion för att generera förutsägelser för en uppsättning bilder med hjälp av Generatorn. Denna funktion genererar ett slumpmässigt ljud, levererar det till generatorn, kör det för att visa den genererade bilden och sparar det i en speciell mapp. Rekommendera att köra den här verktygsfunktionen regelbundet, till exempel var 200:e cykel, för att övervaka nätverkets framsteg. Implementeringen är nedan:
def one_batch(epoch): r, c = 5, 5 noise_model = np.random.normal(0, 1, (r * c, z_size)) gen_images = gen.predict(noise_model) # Rescale images 0 - 1 gen_images = gen_images*(0.5) + 0.5 fig, axs = plt.subplots(r, c) cnt = 0 for i in range(r): for j in range(c): axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray') axs[i,j].axis('off') cnt += 1 fig.savefig("images/%d.png" % epoch) plt.close()
I vårt experiment tränade vi GAN för cirka 10,000 32 epoker med en batchstorlek på 200. För att spåra utbildningens framsteg sparade vi de genererade bilderna var XNUMX:e epoker och lagrade dem i en avsedd mapp som heter "bilder".
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)Låt oss nu undersöka GAN-simuleringsresultaten i olika stadier: initialisering, 400 epoker, 5000 epoker och slutresultatet vid 10000 epoker.
Till en början börjar vi med slumpmässigt brus som insignal till generatorn.

Efter 400 epoker av träning kan vi observera vissa framsteg, även om de genererade bilderna fortfarande skiljer sig väsentligt från verkliga siffror.

Efter träning i 5000 epoker kan vi observera att de genererade siffrorna börjar likna MNIST-datauppsättningen.

Genomför de hela 10,000 XNUMX epoker av träning, vi får följande resultat.

Dessa genererade bilder liknar de handskrivna nummerdata för att träna nätverket. Det är viktigt att notera att dessa bilder inte är en del av träningsuppsättningen och helt genererade av nätverket.
Nästa steg
Nu när vi har uppnått goda resultat i GAN:s bildgenerering finns det många sätt vi kan förbättra den ytterligare. Inom ramen för denna diskussion kan vi överväga att experimentera med olika parametrar. Här är några förslag:
- Utforska olika värden för den latenta rymdvariabeln z_size för att se om den ökar effektiviteten.
- Öka antalet träningsepoker till över 10,000 XNUMX. Fördubbling eller tredubbling av träningstiden kan avslöja förbättrade eller försämrade resultat.
- Prova att använda olika datauppsättningar som fashion MNIST eller moving MNIST. Eftersom dessa datauppsättningar har samma struktur som MNIST, anpassa vår befintliga kod.
- Överväg att experimentera med alternativa arkitekturer som CycleGun, DCGAN och andra. Att modifiera generator- och diskriminatorfunktionerna kan vara tillräckligt för att utforska dessa modeller.
Genom att implementera dessa förändringar kan vi ytterligare förbättra kapaciteten hos GAN och utforska nya möjligheter inom bildgenerering.
Dessa genererade bilder liknar de handskrivna nummerdata som används för att träna nätverket. Dessa bilder är inte en del av träningsuppsättningen och genereras helt av nätverket.
Slutsats
Sammanfattningsvis är GAN en kraftfull maskininlärningsmodell som kan generera nya bilder baserade på befintliga databaser. I den här handledningen har vi visat hur man designar och tränar ett enkelt GAN med hjälp av Tensorflow-biblioteket som exempel och MNIST-databasen.
Key Takeaways
- GAN består av två viktiga komponenter: en generator, som ansvarar för att generera nya bilder från slumpmässig inmatning, och Discriminator, som syftar till att skilja mellan riktiga och falska bilder.
- Genom inlärningsprocessen har vi lyckats skapa en uppsättning bilder som liknar handskrivna siffror, som visas i exempelbilden.
- För att optimera GAN-prestanda tillhandahåller vi matchande mätvärden och förlustfunktioner som hjälper till att skilja riktiga och falska bilder. Genom att utvärdera GAN på osedda data och använda Generatorer kan vi generera nya, tidigare osedda bilder.
- Sammantaget erbjuder GAN intressanta möjligheter inom bildgenerering och har stor potential för flera applikationer som maskininlärning och datorseende.
Vanliga frågor
A. Generative Adversarial Networks (GAN) är en typ av maskininlärningsramverk som kan generera ny data med statistik som liknar en given träningsuppsättning. Använd GAN för många typer av data, inklusive bilder, videor eller text.
S. En generativ modell är en maskininlärningsalgoritm som genererar ny data baserat på en uppsättning indata. Använd dessa modeller för uppgifter som bildgenerering, textgenerering och andra former av datasyntes.
A. En förlustfunktion är en matematisk funktion för att mäta skillnaden mellan två uppsättningar data. I samband med GAN, träna modellgeneratorn genom att optimera förlustfunktionen som definierar skillnaden mellan genererad data och träningsdata, vanligtvis med hjälp av klassposter och kommenterade bilder.
A. CNN (Convolutional Neural Networks) och GAN (Generative Adversarial Networks) är båda djupinlärningsarkitekturer men har olika mål. GAN är generativa modeller som syftar till att generera ny data som liknar en given träningsuppsättning, medan CNN är för klassificerings- och igenkänningsuppgifter. Även om det är möjligt att använda CNN som en generativ modell genom att konfigurera den som en variabel autoencoder (VAE), är CNN bra i diskrimineringsträning och mer effektiv i bildklassificeringsuppgifter i datorseende.
Medierna som visas i den här artikeln ägs inte av Analytics Vidhya och används efter författarens gottfinnande.
Relaterad
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2023/06/using-gans-in-tensorflow-generate-images/

