Amazon OpenSearch Service introducerade nyligen OpenSearch Optimized Instance-familjen (OR1), som ger upp till 30 % pris-prestandaförbättringar jämfört med befintliga minnesoptimerade instanser i interna benchmarks, och använder Amazon enkel lagringstjänst (Amazon S3) för att ge 11 9:or av hållbarhet. Med den här nya instansfamiljen använder OpenSearch Service OpenSearch-innovation och AWS-tekniker för att ombilda hur data indexeras och lagras i molnet.
Idag använder kunder i stor utsträckning OpenSearch Service för operationell analys på grund av dess förmåga att ta in stora mängder data samtidigt som de tillhandahåller rik och interaktiv analys. För att ge dessa fördelar är OpenSearch designat som ett distribuerat system i hög skala med flera oberoende instanser som indexerar data och bearbetar förfrågningar. När din operativa analysdatahastighet och datavolym växer kan flaskhalsar uppstå. För att på ett hållbart sätt stödja hög indexeringsvolym och ge hållbarhet byggde vi OR1-instansfamiljen.
I det här inlägget diskuterar vi hur det omarbetade dataflödet fungerar med OR1-instanser och hur det kan ge hög indexeringsgenomströmning och hållbarhet med hjälp av ett nytt fysiskt replikeringsprotokoll. Vi dyker också djupt ner i några av de utmaningar vi löste för att bibehålla korrekthet och dataintegritet.
Designad för hög genomströmning med 11 9s hållbarhet
OpenSearch Service hanterar tiotusentals OpenSearch-kluster. Vi har fått insikter om typiska klusterkonfigurationer som kunder använder för att uppfylla mål för hög genomströmning och hållbarhet. För att uppnå högre genomströmning väljer kunder ofta att släppa kopior för att spara på replikeringsfördröjningen; denna konfiguration resulterar dock i att offra tillgänglighet och hållbarhet. Andra kunder kräver hög hållbarhet och måste därför behålla flera kopior, vilket resulterar i högre driftskostnader för dem.
OpenSearch Optimized Instance-familjen ger extra hållbarhet samtidigt som de håller kostnaderna lägre genom att lagra en kopia av data på Amazon S3. Med OR1-instanser kan du konfigurera flera replikakopior för hög lästillgänglighet samtidigt som indexeringsgenomströmningen bibehålls.
Följande diagram illustrerar ett indexeringsflöde som involverar en metadatauppdatering i OR1
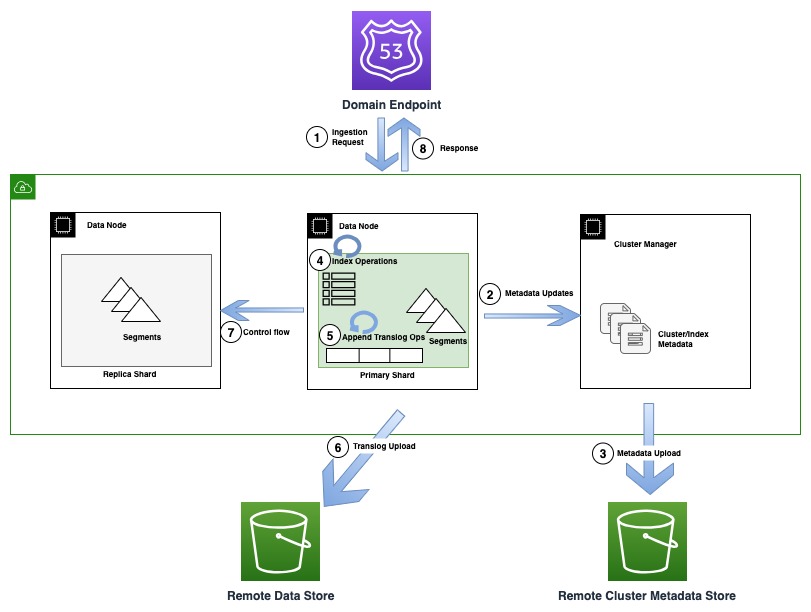
Under indexeringsoperationer indexeras enskilda dokument i Lucene och läggs även till i en framskrivningslogg, även känd som en translogg. Innan du skickar tillbaka en bekräftelse till klienten, fortsätter alla translogoperationer till fjärrdatalagret som backas upp av Amazon S3. Om några replikkopior är konfigurerade, utför den primära kopian kontroller för att upptäcka möjligheten av flera skribenter (kontrollflöde) på alla replikkopior av korrekthetsskäl.
Följande diagram illustrerar segmentgenereringen och replikeringsflödet i OR1-instanser
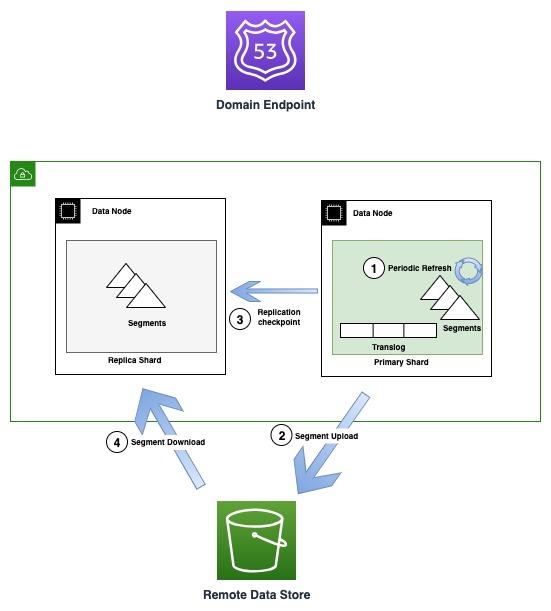
Med jämna mellanrum, när nya segmentfiler skapas, kopierar OR1 dessa segment till Amazon S3. När överföringen är klar publicerar den primära nya kontrollpunkter till alla replikkopior och meddelar dem om ett nytt segment som är tillgängligt för nedladdning. Kopiorna laddar sedan ner nyare segment och gör dem sökbara. Denna modell frikopplar dataflödet som sker med Amazon S3 och kontrollflödet (checkpointpublicering och termvalidering) som sker över transportkommunikation mellan noder.
Följande diagram illustrerar återhämtningsflödet i OR1-instanser
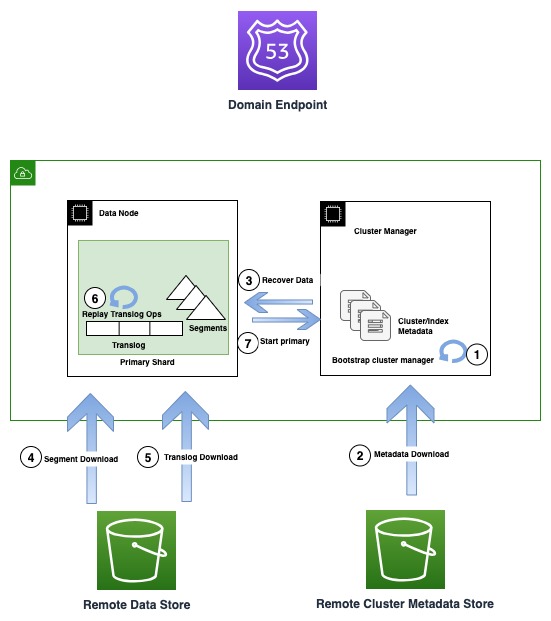
OR1-instanser kvarstår inte bara data, utan klustermetadata som indexmappningar, mallar och inställningar i Amazon S3. Detta säkerställer att i händelse av en klusterhanterares kvorumförlust, vilket är ett vanligt felläge i icke-dedikerade klusterhanterareinställningar, kan OpenSearch på ett tillförlitligt sätt återställa den senast bekräftade metadatan.
I händelse av ett infrastrukturfel kan en OpenSearch-domän sluta med att förlora en eller flera noder. I ett sådant fall garanterar den nya instansfamiljen återställning av både klustermetadata och indexdata fram till den senast bekräftade operationen. När nya ersättningsnoder ansluter sig till klustret, startar den interna klusteråterställningsmekanismen den nya uppsättningen noder och återställer sedan den senaste klustermetadatan från fjärrklustrets metadatalager. Efter att klustrets metadata har återställts, börjar återställningsmekanismen att hydratisera de saknade segmentdata och translog från Amazon S3. Sedan spelas alla oengagerade translogoperationer, fram till den senast bekräftade operationen, upp igen för att återställa den förlorade kopian.
Den nya designen ändrar inte hur sökningar fungerar. Frågor bearbetas normalt av antingen det primära eller replika fragmentet för varje shard i indexet. Du kan se längre förseningar (i intervallet 10 sekunder) innan alla kopior stämmer överens med en viss tidpunkt eftersom datareplikeringen använder Amazon S3.
En viktig fördel med denna arkitektur är att den fungerar som en grundläggande byggsten för framtida innovationer, som separation av läsare och skribenter, och hjälper till att separera beräknings- och lagringsskikt.
Hur omdefiniering av replikeringsstrategin ökar indexeringsgenomströmningen
OpenSearch stöder två replikeringsstrategier: logisk (dokument) och fysisk (segment) replikering. I fallet med logisk replikering indexeras data på alla kopior oberoende, vilket leder till redundant beräkning i klustret. OR1-instanserna använder den nya fysisk replikering modell, där data endast indexeras på den primära kopian och ytterligare kopior skapas genom att kopiera data från den primära. Med ett stort antal replikakopior kräver noden som är värd för den primära kopian betydande nätverksbandbredd, vilket replikerar segmentet till alla kopior. De nya OR1-instanserna löser detta problem genom att varaktigt bevara segmentet till Amazon S3, som är konfigurerat som en fjärrlagring alternativ. De hjälper också till med skalning av repliker utan flaskhalsar på primära.
Efter att segmenten har laddats upp till Amazon S3, skickar den primära ut en kontrollpunktsbegäran, som meddelar alla repliker att ladda ner de nya segmenten. Replikakopiorna behöver sedan ladda ner de inkrementella segmenten. Eftersom den här processen frigör beräkningsresurser på repliker, som annars krävs för att redundant indexera data och nätverkskostnader som uppstår på primära data för att replikera data, kan klustret churna mer genomströmning. I händelse av att replikerna inte kan bearbeta de nyskapade segmenten, på grund av överbelastning eller långsamma nätverksvägar, markeras replikerna bortom en punkt som misslyckade för att förhindra att de returnerar inaktuella resultat.
Varför hög hållbarhet är en bra idé, men svårt att göra bra
Även om alla engagerade segment är varaktigt bevarade till Amazon S3 närhelst de skapas, är en av de viktigaste utmaningarna för att uppnå hög hållbarhet att synkront skriva alla oengagerade operationer till en skriv-ahead-logg på Amazon S3, innan man bekräftar begäran till kunden, utan att offra genomströmning. Den nya semantiken introducerar ytterligare nätverkslatens för individuella förfrågningar, men sättet vi har sett till att det inte finns någon påverkan på genomströmningen är genom att batcha och tömma förfrågningar på en enskild tråd i upp till ett specificerat intervall, samtidigt som vi ser till att andra trådar fortsätter att indexera förfrågningar. Som ett resultat kan du driva högre genomströmning med fler samtidiga klientanslutningar genom att optimalt batcha dina bulknyttolaster.
Andra utmaningar med att designa ett mycket hållbart system inkluderar att alltid upprätthålla dataintegritet och korrekthet. Även om vissa händelser som nätverkspartitioner är sällsynta kan de bryta systemets korrekthet och därför måste systemet vara förberett för att hantera dessa fellägen. Därför, medan vi bytte till det nya segmentreplikeringsprotokollet, introducerade vi också några andra protokolländringar, som att upptäcka flera skrivare på varje replik. Protokollet ser till att en isolerad skribent inte kan godkänna en skrivbegäran, medan en annan nyligen befordrad primär, baserad på klusterhanterarens kvorum, samtidigt accepterar nyare skrivningar.
Den nya instansfamiljen upptäcker automatiskt förlusten av en primär shard samtidigt som data återställs, och utför omfattande kontroller av nätverkets tillgänglighet innan data kan återhydreras från Amazon S3 och klustret återförs till ett hälsosamt tillstånd.
För dataintegritet kontrolleras alla filer omfattande för att säkerställa att vi kan upptäcka och förhindra nätverks- eller filsystemkorruption som kan leda till att data blir oläsliga. Dessutom är alla filer inklusive metadata designade för att vara oföränderliga, vilket ger ytterligare säkerhet mot korruption och versionsversion för att förhindra oavsiktliga muterande ändringar.
Ombilda hur data flödar
OR1-instanserna hydratiserar kopior direkt från Amazon S3 för att utföra återställning av förlorade skärvor under ett infrastrukturfel. Genom att använda Amazon S3 kan vi frigöra den primära nodens nätverksbandbredd, diskgenomströmning och beräkning, och ger därför en mer sömlös skalning på plats och blå/grön implementeringsupplevelse genom att orkestrera hela processen med minimal primär nodkoordination.
OpenSearch Service tillhandahåller automatisk säkerhetskopiering av data som kallas snapshots med timintervall, vilket innebär att vid oavsiktliga ändringar av data, har du möjlighet att gå tillbaka till en tidigare tidpunkt. Men med den nya OpenSearch-instansfamiljen har vi diskuterat att data redan finns kvar på Amazon S3. Så hur fungerar ögonblicksbilder när vi redan har data på Amazon S3?
Med den nya instansfamiljen fungerar ögonblicksbilder som kontrollpunkter, som refererar till den redan befintliga segmentdatan som den existerar vid en tidpunkt. Detta gör ögonblicksbilder lättare och snabbare eftersom de inte behöver ladda upp ytterligare data igen. Istället laddar de upp metadatafiler som fångar synen på segmenten vid den tidpunkten, vilket vi kallar grunda ögonblicksbilder. Fördelen med grunda ögonblicksbilder omfattar alla operationer, nämligen skapande, radering och kloning av ögonblicksbilder. Du har fortfarande möjlighet att ta en ögonblicksbild av en oberoende kopia med manuella ögonblicksbilder för annan administrativ verksamhet.
Sammanfattning
OpenSearch är en öppen källkod, community-driven programvara. De flesta av de grundläggande förändringarna inklusive replikeringsmodellen, fjärrbackad lagring och fjärrklustermetadata har bidragit till öppen källkod; i själva verket följer vi en första utvecklingsmodell med öppen källkod.
Ansträngningar att förbättra genomströmning och tillförlitlighet är en oändlig cykel när vi fortsätter att lära och förbättra. De nya OpenSearch-optimerade instanserna fungerar som en grundläggande byggsten och banar väg för framtida innovationer. Vi är glada över att fortsätta våra ansträngningar för att förbättra tillförlitlighet och prestanda och att se vilka nya och befintliga lösningar som byggare kan skapa med OpenSearch Service. Vi hoppas att detta leder till en djupare förståelse för den nya OpenSearch-instansfamiljen, hur detta erbjudande uppnår hög hållbarhet och bättre genomströmning, och hur det kan hjälpa dig att konfigurera kluster baserat på ditt företags behov.
Om du är sugen på att bidra till OpenSearch, öppna upp en GitHub-problem och låt oss veta dina tankar. Vi skulle också älska att höra om dina framgångshistorier som uppnår hög genomströmning och hållbarhet på OpenSearch Service. Om du har andra frågor, vänligen lämna en kommentar.
Om författarna
 Bukhtawar Khan är en huvudingenjör som arbetar på Amazon OpenSearch Service. Han är intresserad av att bygga distribuerade och autonoma system. Han är en underhållare och en aktiv bidragsgivare till OpenSearch.
Bukhtawar Khan är en huvudingenjör som arbetar på Amazon OpenSearch Service. Han är intresserad av att bygga distribuerade och autonoma system. Han är en underhållare och en aktiv bidragsgivare till OpenSearch.
 Gaurav Bafna är en senior mjukvaruingenjör som arbetar med OpenSearch på Amazon Web Services. Han är fascinerad av att lösa problem i distribuerade system. Han är en underhållare och en aktiv bidragsgivare till OpenSearch.
Gaurav Bafna är en senior mjukvaruingenjör som arbetar med OpenSearch på Amazon Web Services. Han är fascinerad av att lösa problem i distribuerade system. Han är en underhållare och en aktiv bidragsgivare till OpenSearch.
 Sachin Kale är en senior mjukvaruutvecklingsingenjör på AWS och arbetar med OpenSearch.
Sachin Kale är en senior mjukvaruutvecklingsingenjör på AWS och arbetar med OpenSearch.
 Rohin Bhargava är Sr. Product Manager med Amazon OpenSearch Service-teamet. Hans passion på AWS är att hjälpa kunder att hitta den rätta mixen av AWS-tjänster för att nå framgång för sina affärsmål.
Rohin Bhargava är Sr. Product Manager med Amazon OpenSearch Service-teamet. Hans passion på AWS är att hjälpa kunder att hitta den rätta mixen av AWS-tjänster för att nå framgång för sina affärsmål.
 Ranjith Ramachandra är en Senior Engineering Manager som arbetar på Amazon OpenSearch Service. Han brinner för mycket skalbara distribuerade system, högpresterande och motståndskraftiga system.
Ranjith Ramachandra är en Senior Engineering Manager som arbetar på Amazon OpenSearch Service. Han brinner för mycket skalbara distribuerade system, högpresterande och motståndskraftiga system.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/amazon-opensearch-service-under-the-hood-opensearch-optimized-instancesor1/

