2023 har varit ett hektiskt år Amazon OpenSearch Service! Läs mer om de utgåvor som OpenSearch Service lanserade i första halvan av 2023.
Under andra halvåret 2023 lade OpenSearch Service till stöd för två nya Opensearch versioner: 2.9 och 2.11 Dessa två versioner introducerar nya funktioner i sökutrymmet, sökutrymme för maskininlärning (ML), migrering och den operativa sidan av tjänsten.
Med lanseringen av noll-ETL-integration med Amazon enkel lagringstjänst (Amazon S3), du kan analysera dina data i din datasjö med hjälp av OpenSearch Service för att bygga instrumentpaneler och fråga efter data utan att behöva flytta din data från Amazon S3.
OpenSearch Service tillkännagav också en ny noll-ETL-integration med Amazon DynamoDB genom insticksprogrammet DynamoDB för Amazon OpenSearch Intag. OpenSearch Ingestion tar hand om bootstrapping och strömmar kontinuerligt data från din DynamoDB-källa.
OpenSearch Serverless meddelade den allmänna tillgängligheten av Vector Engine för Amazon OpenSearch Serverless tillsammans med andra funktioner för att förbättra din upplevelse med tidsseriesamlingar, hantera dina kostnader för utvecklingsmiljöer och snabbt skala dina resurser för att matcha dina arbetsbelastningskrav.
I det här inlägget diskuterar vi de nya utgåvorna i OpenSearch Service för att ge ditt företag möjligheter med sökning, observerbarhet, säkerhetsanalys och migrering.
Bygg kostnadseffektiva lösningar med OpenSearch Service
Med noll-ETL-integrationen för Amazon S3 låter OpenSearch Service dig nu söka efter dina data på plats, vilket sparar kostnader för lagring. Dataförflyttning är en dyr operation eftersom du behöver replikera data över olika datalager. Detta ökar ditt dataavtryck och ökar kostnaderna. Att flytta data lägger också till överkostnaderna för att hantera pipelines för att migrera data från en källa till en ny destination.
OpenSearch Service lade också till nya instanstyper för datanoder – Im4gn och OR1 – för att hjälpa dig att ytterligare optimera din infrastrukturkostnad. Med maximalt 30 TB icke-flyktigt minne (NVMe) solid state-enheter (SSD) ger Im4gn-instansen tät lagring och bättre prestanda. OR1-instanser använder segmentreplikering och fjärrbackad lagring för att kraftigt öka genomströmningen för indexeringstunga arbetsbelastningar.
Noll-ETL från DynamoDB till OpenSearch Service
I november 2023 introducerade DynamoDB och OpenSearch Ingestion en noll-ETL-integrering för OpenSearch Service. OpenSearch Service-domäner och OpenSearch Serverless-samlingar ger avancerade sökfunktioner, såsom fulltext- och vektorsökning, på dina DynamoDB-data. Med några få klick på AWS Management Console, kan du nu sömlöst ladda och synkronisera dina data från DynamoDB till OpenSearch Service, vilket eliminerar behovet av att skriva anpassad kod för att extrahera, transformera och ladda data.
Direktfråga (noll-ETL för Amazon S3-data, i förhandsvisning)
OpenSearch Service tillkännagav ett nytt sätt för dig att söka efter driftsloggar i Amazon S3- och S3-baserade datasjöar utan att behöva växla mellan verktyg för att analysera driftsdata. Tidigare var du tvungen att kopiera data från Amazon S3 till OpenSearch Service för att dra fördel av OpenSearchs rika analys- och visualiseringsfunktioner för att förstå dina data, identifiera avvikelser och upptäcka potentiella hot.
Att kontinuerligt replikera data mellan tjänster kan dock vara dyrt och kräver operativt arbete. Med OpenSearch Service-funktionen för direktfråga kan du komma åt operativa loggdata lagrade i Amazon S3, utan att behöva flytta själva data. Nu kan du utföra komplexa frågor och visualiseringar på dina data utan någon datarörelse.
Support för Im4gn med OpenSearch Service
Im4gn-instanser är optimerade för arbetsbelastningar som hanterar stora datamängder och behöver hög lagringstäthet per vCPU. Im4gn-instanser finns i storlekar stora till 16xlarge, med upp till 30 TB i NVMe SSD-diskstorlek. Im4gn-instanser är byggda på AWS Nitro-system SSD:er, som erbjuder hög genomströmning, låg latens diskåtkomst för bästa prestanda. OpenSearch Service Im4gn-instanser stöder alla OpenSearch-versioner och Elasticsearch-versioner 7.9 och senare. För mer information, se Stöds instanstyper i Amazon OpenSearch Service.
Vi introducerar OR1, en OpenSearch Optimized Instance-familj för indexering av tunga arbetsbelastningar
I november 2023 lanserades OpenSearch Service OR1, familjen OpenSearch Optimized Instance, som ger upp till 30 % förbättring av pris och prestanda jämfört med befintliga instanser i interna benchmarks och använder Amazon S3 för att ge 11 9:or av hållbarhet. En domän med OR1-instanser använder Amazon Elastic Block Store (Amazon EBS) volymer för primär lagring, med data kopierad synkront till Amazon S3 när den anländer. OR1-instanser använder OpenSearchs segmentreplikeringsfunktion för att göra det möjligt för replikskärvor att läsa data direkt från Amazon S3, vilket undviker resurskostnaden för indexering i både primära och replika skärvor. OR1-instansfamiljen stöder också automatisk dataåterställning i händelse av fel. För mer information om alternativ för OR1-instanstyp, se Aktuell generation instanstyper i OpenSearch Service.
Aktivera ditt företag med säkerhetsanalysfunktioner
Plugin-programmet Security Analytics i OpenSearch Service stöder direkt färdigförpackade stocktyper och tillhandahåller säkerhetsdetekteringsregler (SIGMA-regler) för att upptäcka potentiella säkerhetsincidenter.
I OpenSearch 2.9 lade Security Analytics-pluginen till stöd för kundloggtyper och inbyggt stöd för Open Cybersecurity Schema Framework (OCSF) dataformat. Med detta nya stöd kan du bygga detektorer med OCSF-data lagrade i Amazon Security Lake för att analysera säkerhetsfynd och mildra eventuella incidenter. Security Analytics-pluginet har också lagt till möjligheten att skapa dina egna anpassade loggtyper och skapa anpassade detektionsregler.
Bygg ML-drivna söklösningar
År 2023 investerade OpenSearch Service i att eliminera de tunga lyft som krävs för att bygga nästa generations sökapplikationer. Med funktioner som sökpipelines, sökprocessorer och AI/ML-anslutningar möjliggjorde OpenSearch Service snabb utveckling av sökapplikationer som drivs av neural sökning, hybridsökning och personliga resultat. Dessutom förbättrade förbättringar av kNN-pluginen lagring och hämtning av vektordata. Nylanserade valfria plugins för OpenSearch Service möjliggör sömlös integration med ytterligare språkanalysatorer och Amazon Anpassa.
Sök pipelines
Sök pipelines tillhandahålla nya sätt att förbättra sökfrågor och förbättra sökresultaten. Du definierar en sökpipeline och skickar sedan dina frågor till den. När du definierar sökpipeline anger du processorer som omvandlar och utökar dina frågor och omrangerar dina resultat. De förbyggda frågeprocessorerna inkluderar datumkonvertering, aggregering, strängmanipulation och datatypkonvertering. Resultatprocessorn i sökpipelinen fångar upp och anpassar resultat i farten innan den renderas till nästa fas. Både begäran och svarsbehandling för pipelinen utförs på koordinatornoden, så det finns ingen bearbetning på skärvnivå.
Valfria plugins
OpenSearch Service låter dig associera förinstallerade valfria OpenSearch-plugins att använda med din domän. Ett valfritt plugin-paket är kompatibelt med en specifik OpenSearch-version och kan endast kopplas till domäner med den versionen. Tillgängliga plugins listas på Paket sidan på OpenSearch Service-konsolen. Det valfria pluginet inkluderar Amazon Personalize-plugin, som integrerar OpenSearch Service med Amazon Personalize, och nya språkanalysatorer som Nori, Sudachi, STConvert och Pinyin.
Stöd för nya språkanalysatorer
OpenSearch Service lade till stöd för fyra nya plugins för språkanalysator: Nori (koreanska), Sudachi (japanska), Pinyin (kinesiska) och STConvert Analysis (kinesiska). Dessa är tillgängliga i alla AWS-regioner som valfria plugins som du kan associera med domäner som kör valfri OpenSearch-version. Du kan använda Paket sida på OpenSearch Service-konsolen för att koppla dessa plugins till din domän, eller använd Associate Package API.
Neural sökfunktion
Neural sökning är allmänt tillgänglig med OpenSearch Service version 2.9 och senare. Neural sökning låter dig integrera med ML-modeller som är värd på distans med hjälp av modellbetjäningsramverket. När du använder en neural fråga under sökning, konverterar neural sökning frågetexten till vektorinbäddningar, använder vektorsökning för att jämföra frågan och dokumentinbäddning och returnerar de närmaste resultaten. Under inmatning omvandlar neural sökning dokumenttext till vektorinbäddning och indexerar både texten och dess vektorinbäddningar i ett vektorindex.
Integration med Amazon Personalize
OpenSearch Service introducerade ett valfritt plugin för att integreras med Amazon Personalize i OpenSearch version 2.9 eller senare. OpenSearch Service-plugin för Amazon Personalize Search Ranking låter dig förbättra slutanvändarnas engagemang och konvertering från din webbplats och applikationssökning genom att dra nytta av de djupa inlärningsmöjligheterna som erbjuds av Amazon Personalize. Som ett valfritt plugin, paketet är kompatibelt med OpenSearch version 2.9 eller senare, och kan endast associeras till domäner med den versionen.
Effektiv frågefiltrering med OpenSearchs k-NN FAISS
OpenSearch Service introducerade effektiv frågefiltrering med OpenSearchs k-NN FAISS i version 2.9 och senare. OpenSearchs effektiva vektorfrågefilter kapaciteten utvärderar intelligent optimala filtreringsstrategier – förfiltrering med ungefärlig närmaste granne (ANN) eller filtrering med exakt k-närmaste granne (k-NN) – för att bestämma den bästa strategin för att leverera exakta vektorsökningar med låg latens. I tidigare OpenSearch-versioner använde vektorfrågor på FAISS-motorn efterfiltreringstekniker, som möjliggjorde filtrerade frågor i skala, men som potentiellt returnerade mindre än det begärda antalet "k" resultat. Effektiva vektorfrågefilter leverera låg latens och exakta resultat, vilket gör att du kan använda hybridsökning över vektor- och lexikaltekniker.
Byte-kvantiserade vektorer i OpenSearch Service
Med den nya byte-kvantiserad vektor introducerat med 2.9 kan du minska minneskraven med en faktor 4 och avsevärt minska sökfördröjningen, med minimal kvalitetsförlust (återkallelse). Med denna funktion kvantiseras eller omvandlas de vanliga 32-bitars flöten som används för vektorer till 8-bitars heltal. För många applikationer kan befintliga flytvektordata kvantiseras med liten kvalitetsförlust. Om du jämför riktmärken kommer du att upptäcka att användning av byte-vektorer snarare än 32-bitars flytningar resulterar i en betydande minskning av lagrings- och minnesanvändning samtidigt som det förbättrar indexeringsgenomströmningen och minskar frågefördröjningen. En intern riktmärke visade att lagringsanvändningen minskade med upp till 78 % och RAM-användningen minskade med upp till 59 % (för handsken-200-vinkeldatauppsättningen). Recall-värden för vinkeldatauppsättningar var lägre än de för euklidiska datauppsättningar.
AI/ML-kontakter
OpenSearch 2.9 och senare stöder integrationer med ML-modeller värd på AWS-tjänster eller tredjepartsplattformar. Detta gör att systemadministratörer och datavetare kan köra ML-arbetsbelastningar utanför sin OpenSearch Service-domän. ML-anslutningarna kommer med en uppsättning ML-ritningar som stöds – mallar som definierar uppsättningen parametrar du måste tillhandahålla när du skickar API-förfrågningar till en specifik anslutning. OpenSearch Service tillhandahåller kopplingar för flera plattformar, som t.ex Amazon SageMaker, Amazonas berggrund, OpenAI Chat GPToch Sammanhålla.
OpenSearch Service-konsolintegrationer
OpenSearch 2.9 och senare lade till en ny integrationsfunktion på konsolen. Integrationer ger dig en AWS molnformation mall för att bygga din semantisk sökning användningsfall genom att ansluta till dina ML-modeller på SageMaker eller Amazon Bedrock. CloudFormation-mallen genererar modellens slutpunkt och registrerar modell-ID:t med OpenSearch Service-domänen du anger som indata till mallen.
Hybridsökning och intervallnormalisering
Smakämnen normaliseringsprocessor och hybridfråga bygger på de två funktioner som släpptes tidigare 2023—neural sökning och sök pipelines. Eftersom lexikaliska och semantiska frågor ger relevanspoäng på olika skalor, var det svårt att finjustera hybridsökfrågor.
OpenSearch Service 2.11 stöder nu en kombinations- och normaliseringsprocessor för hybridsökning. Du kan nu utföra hybridsökningar genom att kombinera en lexikal och en naturlig språkbaserad k-NN-vektorsökning. OpenSearch Service låter dig också ställa in dina hybridsökresultat för maximal relevans med hjälp av multipla poängkombinationer och normaliseringstekniker.
Multimodal sökning med Amazon Bedrock
OpenSearch Service 2.11 lanserar stöd för multimodal sökning som låter dig söka text- och bilddata med hjälp av multimodala inbäddningsmodeller. För att generera vektorinbäddningar måste du skapa en inmatningspipeline som innehåller en text_image_inbäddningsprocessor, som konverterar text- eller bildbinärfilerna i ett dokumentfält till vektorinbäddningar. Du kan använda den neurala frågesatsen, antingen i k-NN plugin API or Fråga DSL för att göra en kombination av text- och bildsökningar. Du kan använda de nya OpenSearch Service-integreringsfunktionerna för att snabbt börja med multimodal sökning.
Neural sparsam apportering
Neural sparse search, en ny effektiv metod för semantisk hämtning, är tillgänglig i OpenSearch Service 2.11. Neural sparse search fungerar i två lägen: bi-encoder och endast dokument. Med bi-encoder-läget skickas både dokument och sökfrågor genom djupkodare. I endast dokumentläge skickas endast dokument genom djupkodare, medan sökfrågor tokeniseras. En gles kodare för endast dokument genererar ett index som är 10.4 % av storleken på ett tätt kodningsindex. För en bi-kodare är indexstorleken 7.2 % av storleken på ett tätt kodningsindex. Neural sparse search aktiveras av glesa kodningsmodeller som skapar glesa vektorinbäddningar: en uppsättning av <token: weight> par som representerar textinmatningen och dess motsvarande vikt i den glesa vektorn. För att lära dig mer om de förtränade modellerna för gles neural sökning, se Sparsamma kodningsmodeller.
Neural sparsam sökning minskar kostnaderna, förbättrar sökrelevansen och har lägre latens. Du kan använda de nya OpenSearch Service-integreringsfunktionerna för att snabbt börja med neural gles sökning.
OpenSearch Ingestion-uppdateringar
OpenSearch Intag är en fullt hanterad och automatiskt skalad inmatningspipeline som levererar dina data till OpenSearch Service-domäner och OpenSearch Serverless-samlingar. Sedan lanseringen 2023 fortsätter OpenSearch Ingestion att lägga till nya funktioner för att göra det enkelt att omvandla och flytta din data från källor som stöds till nedströmsdestinationer som OpenSearch Service, OpenSearch Serverless och Amazon S3.
Nya migreringsfunktioner i OpenSearch Ingestion
I november 2023 tillkännagav OpenSearch Ingestion lanseringen av nya funktioner för att stödja datamigrering från självhanterade Elasticsearch version 7.x-domäner till de senaste versionerna av OpenSearch Service.
OpenSearch Ingestion stöder även migrering av data från OpenSearch Service-hanterade domäner som kör OpenSearch version 2.x till OpenSearch Serverless-samlingar.
Lär dig hur du kan använda OpenSearch Ingestion för att migrera din data till OpenSearch Service.

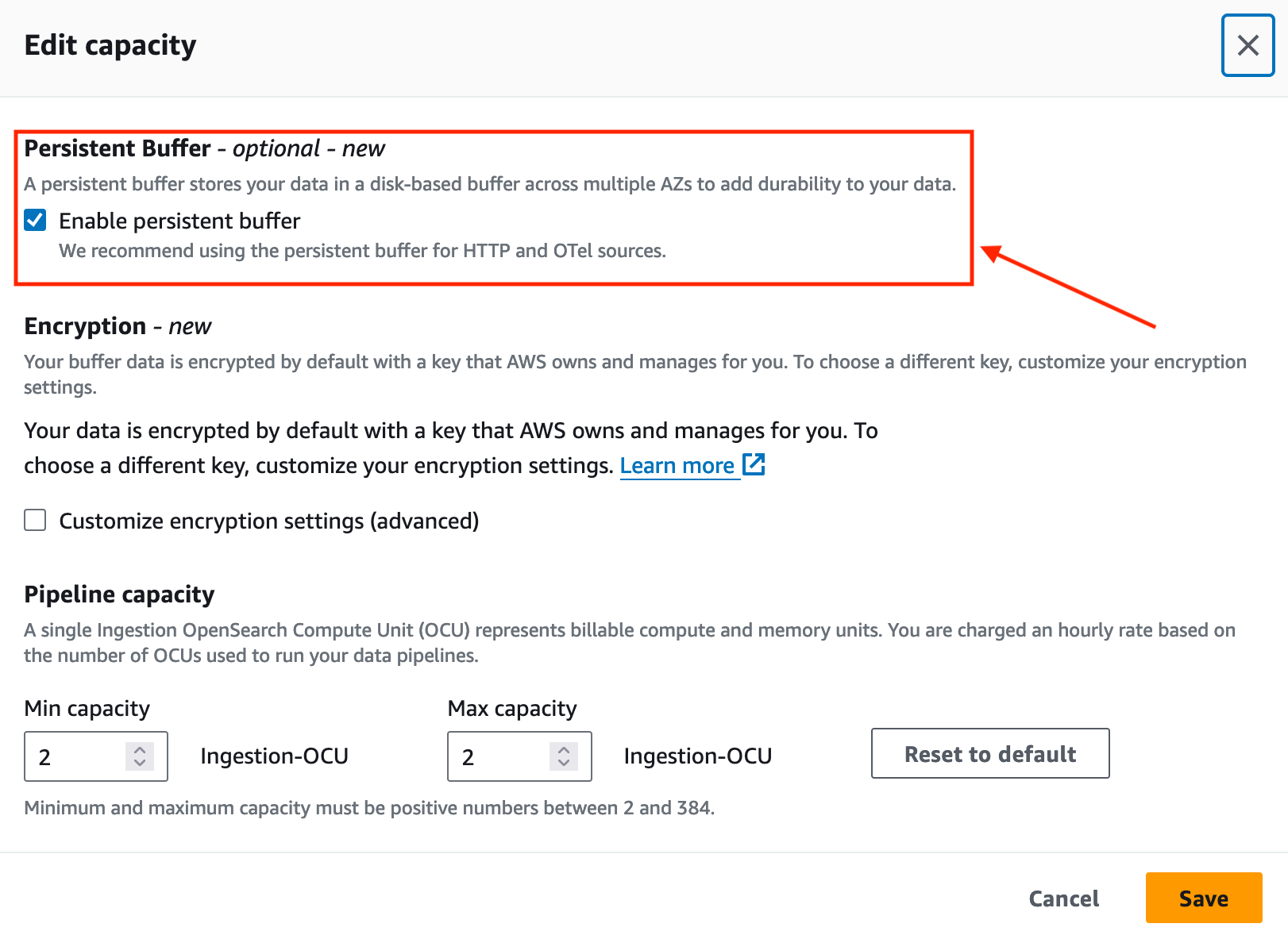
Förbättra datahållbarheten med OpenSearch Ingestion
I november 2023 introducerade OpenSearch Ingestion beständig buffring för push-baserade källor som HTTP-källor (HTTP, Fluentd, FluentBit) och OpenTelemetry-samlare.
Som standard använder OpenSearch Ingestion buffring i minnet. Med beständig buffring lagrar OpenSearch Ingestion dina data i ett diskbaserat lager som är mer motståndskraftigt. Om du har befintliga inmatningspipelines kan du aktivera beständig buffring för dessa pipelines, som visas i följande skärmdump.
Stöd för nya plugins
I början av 2023 lade OpenSearch Ingestion till stöd för Amazon Managed Streaming för Apache Kafka (Amazon MSK). OpenSearch Ingestion använder Kafka plugin för att strömma data från Amazon MSK till OpenSearch Service-hanterade domäner eller OpenSearch Serverless-samlingar. För att lära dig mer om hur du ställer in Amazon MSK som en datakälla, se Använda en OpenSearch Ingestion pipeline med Amazon Managed Streaming för Apache Kafka.
OpenSearch Serverlösa uppdateringar
OpenSearch Serverless fortsatte att förbättra din serverlösa upplevelse med OpenSearch genom att introducera stödet för en ny samling typvektorsökningar för att lagra inbäddningar och köra likhetssökning. OpenSearch Serverless stöder nu shard replika-skalning för att hantera toppar i frågegenomströmningen. Och om du använder en tidsseriesamling kan du nu ställa in din anpassade policy för datalagring så att den matchar dina datalagringskrav.
Vector Engine för OpenSearch Serverless
I november 2023 lanserade vi vektormotor för Amazon OpenSearch Serverless. Vektormotorn gör det enkelt att bygga moderna ML-förstärkta sökupplevelser och generativa applikationer för artificiell intelligens (generativ AI) utan att behöva hantera den underliggande vektordatabasinfrastrukturen. Det låter dig också köra hybridsökning, kombinera vektorsökning och fulltextsökning i samma fråga, vilket tar bort behovet av att hantera och underhålla separata datalager eller en komplex applikationsstack.
OpenSearch Serverless billiga utvecklings- och testmiljöer
OpenSearch Serverless stöder nu utvecklings- och testarbetsbelastningar genom att låta dig undvika att köra en replik. Att ta bort repliker eliminerar behovet av att ha redundanta OCU:er i en annan tillgänglighetszon enbart för tillgänglighetssyften. Om du använder OpenSearch Serverless för utveckling och testning, där tillgänglighet inte är ett problem, kan du sänka dina lägsta OCU:er från 4 till 2.
OpenSearch Serverless stöder automatisk tidsbaserad dataradering med hjälp av datalivscykelpolicyer
I december 2023 tillkännagav OpenSearch Serverless stöd för hantering av datalagring av tidsseriesamlingar och index. Med den nya automatiska tidsbaserade dataraderingsfunktionen kan du ange hur länge du vill behålla data. OpenSearch Serverless hanterar automatiskt livscykeln för data baserat på denna konfiguration. För att lära dig mer, se Amazon OpenSearch Serverless stöder nu automatisk tidsbaserad dataradering.
OpenSearch Serverless tillkännagav stöd för att skala upp repliker på skärvnivå
Vid lanseringen stödde OpenSearch Serverless att öka kapaciteten automatiskt som svar på växande datastorlekar. Med ny skärv replika skalning funktionen, OpenSearch Serverless upptäcker automatiskt skärvor under tvång på grund av plötsliga toppar i frågefrekvensen och lägger dynamiskt till nya skärvor för att hantera den ökade sökgenomströmningen samtidigt som snabba svarstider bibehålls. Detta tillvägagångssätt visar sig vara mer kostnadseffektivt än att bara lägga till nya indexrepliker.
AWS-användaraviseringar för att övervaka din OCU-användning
Med den här lanseringen kan du konfigurera systemet att skicka meddelanden när OCU-användning närmar sig eller har nått maximalt konfigurerade gränser för sökning eller intag. Med den nya AWS User Notification-integrationen kan du konfigurera systemet så att det skickar meddelanden när kapacitetströskeln överskrids. Användaraviseringsfunktionen eliminerar behovet av att övervaka tjänsten konstant. För mer information, se Övervaka Amazon OpenSearch Serverless med hjälp av AWS User Notifications.
Förbättra din upplevelse med OpenSearch Dashboards
OpenSearch 2.9 i OpenSearch Service introducerade nya funktioner för att göra det enkelt att snabbt analysera din data i OpenSearch Dashboards. Dessa nya funktioner inkluderar den nya färdiga lådan, förkonfigurerade instrumentpaneler med OpenSearch-integrationer och möjligheten att skapa varningar och anomalidetektering från en befintlig visualisering i dina instrumentpaneler.
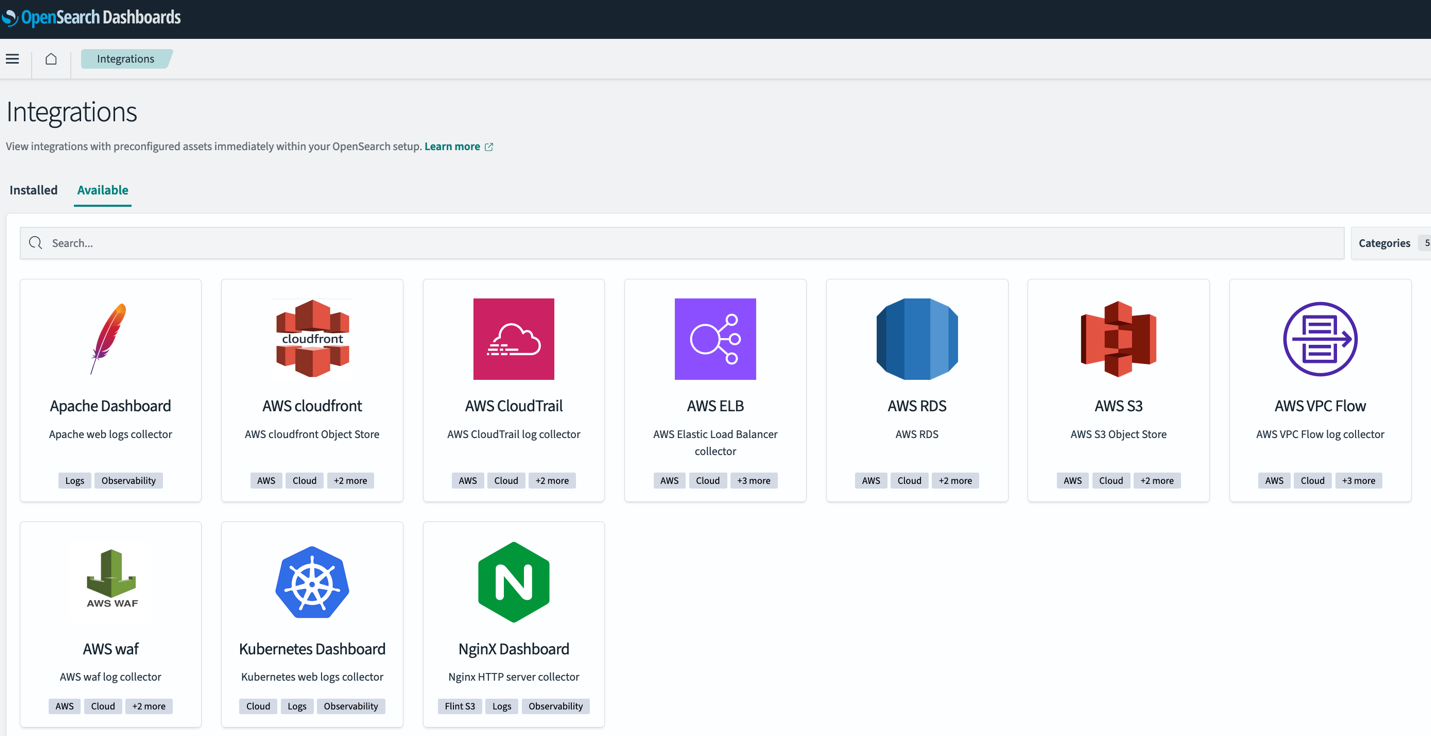
OpenSearch Dashboard-integrationer
OpenSearch 2.9 lade till stöd för OpenSearch-integrationer i OpenSearch Dashboards. OpenSearch-integrationer inkluderar förkonfigurerade instrumentpaneler så att du snabbt kan börja analysera din data som kommer från populära källor som t.ex. AWS CloudFront, AWS WAF, AWS CloudTrailoch Amazon Virtual Private Cloud (Amazon VPC) flödesloggar.
Varningar och avvikelser i OpenSearch Dashboards
I OpenSearch Service 2.9 kan du skapa en ny varningsmonitor direkt från din linjediagram visualisering i OpenSearch Dashboards. Du kan också koppla de befintliga monitorerna eller detektorerna som tidigare skapats i OpenSearch till instrumentpanelens visualisering.
Den här nya funktionen hjälper till att minska kontextväxling mellan instrumentpaneler och både varnings- eller anomalidetektionsplugin. Se följande instrumentpanel för att lägga till en varningsmonitor för att upptäcka minskningar i genomsnittlig datavolym i dina tjänster.

OpenSearch utökar stödet för geospatial aggregering
Med OpenSearch version 2.9 lade OpenSearch Service till stöd för tre typer av geoform dataaggregering via API: geo_gränser, geo_hashoch geo_tile.
Fälttypen geoform ger möjlighet att indexera platsdata i olika geografiska format som en punkt, en polygon eller en linjesträng. Med de nya aggregeringstyperna har du mer flexibilitet att aggregera dokument från ett index med hjälp av metriska och multi-bucket geospatiala aggregationer.
Operativa uppdateringar för OpenSearch Service
OpenSearch Service tog bort behovet av att köra blå/grön distribution när de domänhanterade noderna ändrades. Dessutom förbättrade tjänsten Auto-Tune-händelserna med stöd av nya Auto-Tune-statistik för att spåra ändringarna inom din OpenSearch Service-domän.
OpenSearch Service låter dig nu uppdatera domänhanterarens noder utan blå/grön implementering
Från och med början av H2 av 2023 tillät OpenSearch Service dig att ändra instanstypen eller instansantalet för dedikerade klusterhanterarenoder utan behov av blå/grön implementering. Denna förbättring möjliggör snabbare uppdateringar med minimala avbrott i din domändrift, samtidigt som man undviker datarörelser.
Tidigare innebar att uppdatera dina dedikerade klusterhanterarnoder på OpenSearch Service att använda en blå/grön implementering för att göra ändringen. Även om blå/gröna distributioner är avsedda att undvika störningar på dina domäner, eftersom distributionen använder ytterligare resurser på domänen, rekommenderas det att du utför dem under perioder med låg trafik. Nu kan du uppdatera klusterhanterarens instanstyper eller instansräkningar utan att kräva en blå/grön distribution, så dessa uppdateringar kan slutföras snabbare samtidigt som du undviker eventuella avbrott i din domändrift. I fall där du ändrar både domänhanterarens instanstyp och antal, kommer OpenSearch Service fortfarande att använda en blå/grön implementering för att göra ändringen. Du kan använda torrkörningsalternativet för att kontrollera om din ändring kräver en blå/grön implementering.
Förbättrad Auto-Tune-upplevelse
I september 2023 lade OpenSearch Service till nya Auto-Tune-mätvärden och förbättrade Auto-Tune-händelser som ger dig bättre insyn i domänprestandaoptimeringarna som Auto-Tune gör.
Auto-Tune är ett adaptivt resurshanteringssystem som automatiskt uppdaterar OpenSearch Service-domänresurser för att förbättra effektivitet och prestanda. Till exempel optimerar Auto-Tune minnesrelaterad konfiguration som köstorlekar, cachestorlekar och Java Virtual Machine (JVM)-inställningar på dina noder.
Med denna lansering kan du nu granska historiken för ändringarna, samt spåra dem i realtid från amazoncloudwatch konsol.
Dessutom publicerar OpenSearch Service nu detaljer om ändringarna till Amazon EventBridge när Auto-Tune-inställningar rekommenderas eller tillämpas på en OpenSearch Service-domän. Dessa Auto-Tune-händelser kommer också att vara synliga på Meddelanden sida på OpenSearch Service-konsolen.
Accelerera din migrering till OpenSearch Service med den nya Migration Assistant-lösningen
I november 2023 lanserade OpenSearch-teamet en ny öppen källkodslösning—Migreringsassistent för Amazon OpenSearch Service. Lösningen stöder datamigrering från självhanterade Elasticsearch- och OpenSearch-domäner till OpenSearch Service, med stöd för Elasticsearch 7.x (<=7.10), OpenSearch 1.x och OpenSearch 2.x som migreringskällor. Lösningen underlättar migreringen av befintlig och livedata mellan källa och destination.
Slutsats
I det här inlägget behandlade vi de nya versionerna i OpenSearch Service för att hjälpa dig att förnya ditt företag med sökning, observerbarhet, säkerhetsanalyser och migrering. Vi gav dig information om när du ska använda varje ny funktion i OpenSearch Service, OpenSearch Ingestion och OpenSearch Serverless.
Lär dig mer om OpenSearch Dashboards och OpenSearch-plugins och den nya spännande OpenSearch-assistenten som använder OpenSearch lekplats.
Kolla in funktionerna som beskrivs i det här inlägget och vi uppskattar att du ger oss din värdefulla feedback.
Om författarna
 Jon Handler är Senior Principal Solutions Architect på Amazon Web Services baserad i Palo Alto, CA. Jon arbetar nära OpenSearch och Amazon OpenSearch Service, och tillhandahåller hjälp och vägledning till ett brett spektrum av kunder som har sök- och logganalysarbetsbelastningar som de vill flytta till AWS-molnet. Innan han började på AWS inkluderade Jons karriär som mjukvaruutvecklare 4 år av kodning av en storskalig e-handelssökmotor. Jon har en Bachelor of the Arts från University of Pennsylvania, och en Master of Science och en PhD i datavetenskap och artificiell intelligens från Northwestern University.
Jon Handler är Senior Principal Solutions Architect på Amazon Web Services baserad i Palo Alto, CA. Jon arbetar nära OpenSearch och Amazon OpenSearch Service, och tillhandahåller hjälp och vägledning till ett brett spektrum av kunder som har sök- och logganalysarbetsbelastningar som de vill flytta till AWS-molnet. Innan han började på AWS inkluderade Jons karriär som mjukvaruutvecklare 4 år av kodning av en storskalig e-handelssökmotor. Jon har en Bachelor of the Arts från University of Pennsylvania, och en Master of Science och en PhD i datavetenskap och artificiell intelligens från Northwestern University.
 Hajer Bouafif är en Analytics Specialist Solutions Architect på Amazon Web Services. Hon fokuserar på Amazon OpenSearch Service och hjälper kunder att designa och bygga välstrukturerade analysarbeten i olika branscher. Hajer tycker om att vara utomhus och upptäcka nya kulturer.
Hajer Bouafif är en Analytics Specialist Solutions Architect på Amazon Web Services. Hon fokuserar på Amazon OpenSearch Service och hjälper kunder att designa och bygga välstrukturerade analysarbeten i olika branscher. Hajer tycker om att vara utomhus och upptäcka nya kulturer.
 Aruna Govindaraju är en Amazon OpenSearch Specialist Solutions Architect och har arbetat med många kommersiella sökmotorer och sökmotorer med öppen källkod. Hon brinner för sökning, relevans och användarupplevelse. Hennes expertis med att relatera slutanvändarsignaler med sökmotorbeteende har hjälpt många kunder att förbättra sin sökupplevelse.
Aruna Govindaraju är en Amazon OpenSearch Specialist Solutions Architect och har arbetat med många kommersiella sökmotorer och sökmotorer med öppen källkod. Hon brinner för sökning, relevans och användarupplevelse. Hennes expertis med att relatera slutanvändarsignaler med sökmotorbeteende har hjälpt många kunder att förbättra sin sökupplevelse.
 Prashant Agrawal är en Sr. Search Specialist Solutions Architect med Amazon OpenSearch Service. Han arbetar nära kunderna för att hjälpa dem att migrera sina arbetsbelastningar till molnet och hjälper befintliga kunder att finjustera sina kluster för att uppnå bättre prestanda och spara kostnader. Innan han började med AWS hjälpte han olika kunder att använda OpenSearch och Elasticsearch för deras användningsfall för sökning och logganalys. När du inte arbetar kan du hitta honom på resande fot och utforska nya platser. Kort sagt, han gillar att göra Äta → Resa → Upprepa.
Prashant Agrawal är en Sr. Search Specialist Solutions Architect med Amazon OpenSearch Service. Han arbetar nära kunderna för att hjälpa dem att migrera sina arbetsbelastningar till molnet och hjälper befintliga kunder att finjustera sina kluster för att uppnå bättre prestanda och spara kostnader. Innan han började med AWS hjälpte han olika kunder att använda OpenSearch och Elasticsearch för deras användningsfall för sökning och logganalys. När du inte arbetar kan du hitta honom på resande fot och utforska nya platser. Kort sagt, han gillar att göra Äta → Resa → Upprepa.
 Muslim Abu Taha är en Sr. OpenSearch Specialist Solutions Architect dedikerad till att vägleda kunder genom sömlösa arbetsbelastningsmigreringar, finjustera kluster för toppprestanda och säkerställa kostnadseffektivitet. Med en bakgrund som Technical Account Manager (TAM) tillför Muslim en mängd erfarenhet av att hjälpa företagskunder med molnet och optimera deras olika arbetsbelastningar. Muslim tycker om att tillbringa tid med sin familj, resa och utforska nya platser.
Muslim Abu Taha är en Sr. OpenSearch Specialist Solutions Architect dedikerad till att vägleda kunder genom sömlösa arbetsbelastningsmigreringar, finjustera kluster för toppprestanda och säkerställa kostnadseffektivitet. Med en bakgrund som Technical Account Manager (TAM) tillför Muslim en mängd erfarenhet av att hjälpa företagskunder med molnet och optimera deras olika arbetsbelastningar. Muslim tycker om att tillbringa tid med sin familj, resa och utforska nya platser.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/amazon-opensearch-h2-2023-in-review/

