Detta är ett gästinlägg skrivet tillsammans med Scott Gutterman från PGA TOUR.
Generativ artificiell intelligens (generativ AI) har möjliggjort nya möjligheter att bygga intelligenta system. Nyligen genomförda förbättringar av generativa AI-baserade stora språkmodeller (LLM) har möjliggjort deras användning i en mängd olika applikationer kring informationshämtning. Med tanke på datakällorna tillhandahöll LLM verktyg som skulle göra det möjligt för oss att bygga en Q&A chatbot på veckor, snarare än vad som kan ha tagit år tidigare, och troligen med sämre prestanda. Vi formulerade en RAG-lösning (Retrieval-Augmented-Generation) som skulle göra det möjligt för PGA TOUR att skapa en prototyp för en framtida plattform för fansengagemang som skulle kunna göra dess data tillgänglig för fansen på ett interaktivt sätt i ett konversationsformat.
Att använda strukturerad data för att svara på frågor kräver ett sätt att effektivt extrahera data som är relevant för en användares fråga. Vi formulerade en text-till-SQL-metod där en användares naturliga språkfråga konverteras till en SQL-sats med hjälp av en LLM. SQL körs av Amazonas Athena för att returnera relevanta uppgifter. Dessa data tillhandahålls återigen till en LLM, som ombeds svara på användarens förfrågan givet data.
Att använda textdata kräver ett index som kan användas för att söka och tillhandahålla relevant sammanhang till en LLM för att svara på en användarfråga. För att möjliggöra snabb informationssökning använder vi Amazon Kendra som index för dessa dokument. När användare ställer frågor söker vår virtuella assistent snabbt igenom Amazon Kendra-index för att hitta relevant information. Amazon Kendra använder naturlig språkbehandling (NLP) för att förstå användarfrågor och hitta de mest relevanta dokumenten. Den relevanta informationen tillhandahålls sedan till LLM för slutlig svarsgenerering. Vår slutliga lösning är en kombination av dessa text-till-SQL- och text-RAG-metoder.
I det här inlägget belyser vi hur AWS Generative AI Innovation Center samarbetade med AWS professionella tjänster och PGA TOUR att utveckla en prototyp av virtuell assistent med hjälp av Amazonas berggrund som skulle kunna göra det möjligt för fans att extrahera information om alla händelser, spelare, hål- eller slagnivådetaljer på ett sömlöst interaktivt sätt. Amazon Bedrock är en fullt hanterad tjänst som erbjuder ett urval av högpresterande grundmodeller (FM) från ledande AI-företag som AI21 Labs, Anthropic, Cohere, Meta, Stability AI och Amazon via ett enda API, tillsammans med en bred uppsättning av funktioner du behöver för att bygga generativa AI-applikationer med säkerhet, integritet och ansvarsfull AI.
Utveckling: Förbereda data
Som med alla datadrivna projekt kommer prestandan alltid att vara lika bra som data. Vi bearbetade data för att göra det möjligt för LLM att effektivt kunna fråga och hämta relevant data.
För tävlingsdata i tabellform fokuserade vi på en delmängd av data som är relevanta för det största antalet användarfrågor och märkte kolumnerna intuitivt, så att de skulle vara lättare att förstå för LLM:er. Vi skapade också några extra kolumner för att hjälpa LLM att förstå koncept som det annars skulle kunna kämpa med. Till exempel, om en golfare skjuter ett slag mindre än par (som gör det i hålet i 3 slag på ett par 4 eller i 4 slag på ett par 5), kallas det vanligtvis en pippi. Om en användare frågar, "Hur många birdies gjorde spelare X förra året?", räcker det inte att bara ha poängen och paret i tabellen. Som ett resultat lade vi till kolumner för att indikera vanliga golftermer, som bogey, birdie och eagle. Dessutom kopplade vi tävlingsdata till en separat videosamling genom att gå med i en kolumn för en video_id, vilket skulle göra det möjligt för vår app att hämta videon som är kopplad till en viss bild i tävlingsdata. Vi gjorde det också möjligt att koppla textdata till tabelldata, till exempel att lägga till biografier för varje spelare som en textkolumn. Följande figurer visar steg-för-steg-proceduren för hur en fråga bearbetas för text-till-SQL-pipeline. Siffrorna anger serien av steg för att besvara en fråga.
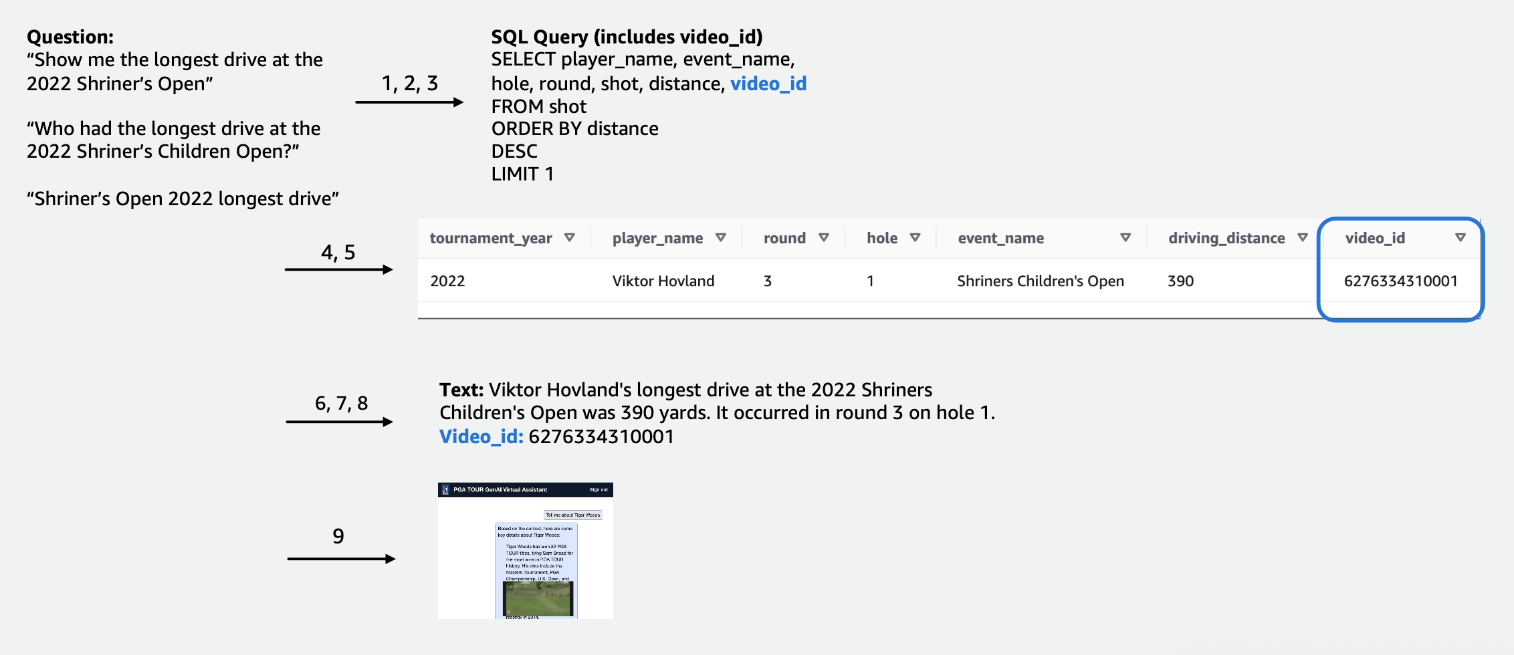
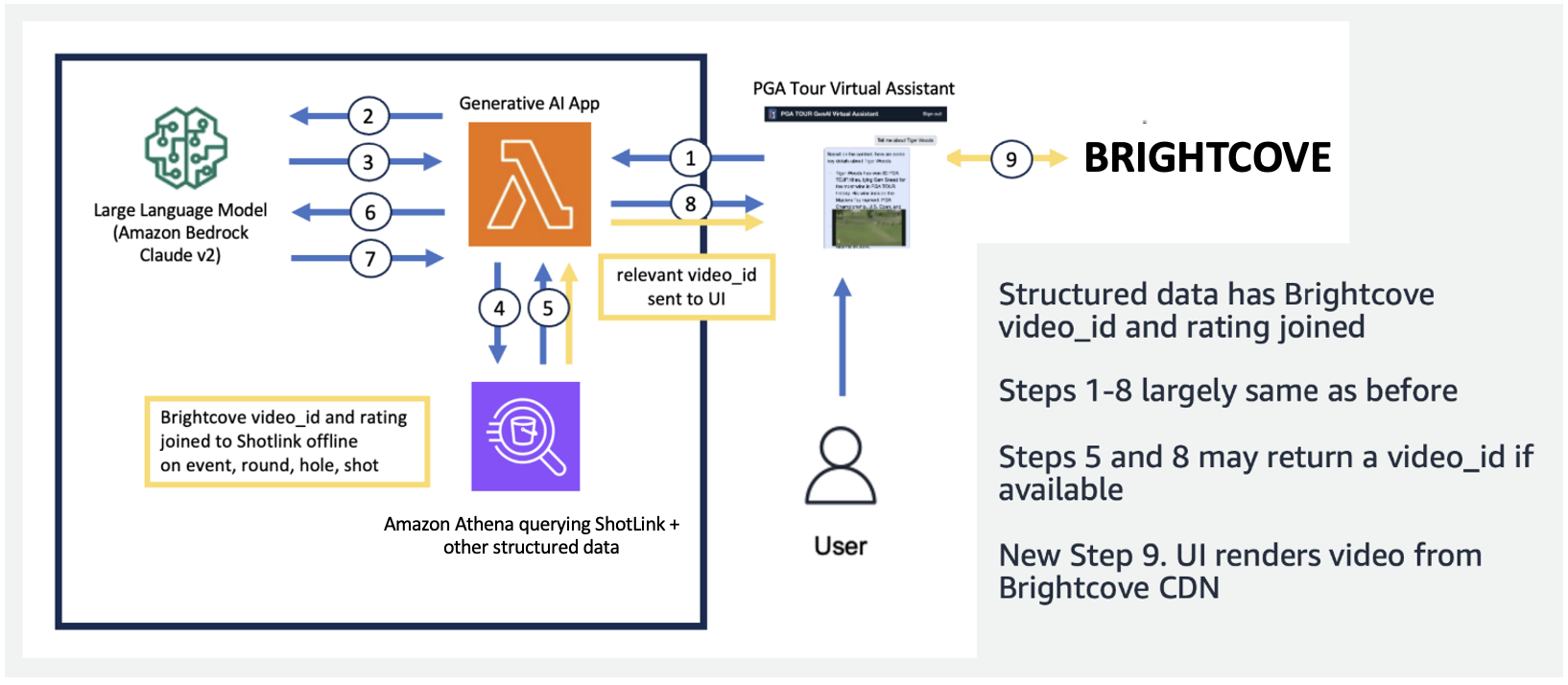
I följande figur visar vi vår end-to-end pipeline. Vi använder AWS Lambda som vår orkestreringsfunktion ansvarig för att interagera med olika datakällor, LLM och felkorrigering baserat på användarens fråga. Steg 1-8 liknar det som visas i den föregående figuren. Det finns små förändringar för de ostrukturerade data, som vi diskuterar härnäst.
Textdata kräver unika bearbetningssteg som delar upp (eller segmenterar) långa dokument i delar som kan smältas av LLM, samtidigt som ämnesöverensstämmelsen bibehålls. Vi experimenterade med flera tillvägagångssätt och bestämde oss för ett uppdelningsschema på sidnivå som passade väl med formatet för medieguiderna. Vi använde Amazon Kendra, som är en hanterad tjänst som tar hand om att indexera dokument, utan att kräva specifikation av inbäddningar, samtidigt som det tillhandahåller ett enkelt API för hämtning. Följande figur illustrerar denna arkitektur.

Den enhetliga, skalbara pipeline vi utvecklade gör att PGA TOUR kan skalas till sin fullständiga historik av data, varav en del går tillbaka till 1800-talet. Det möjliggör framtida applikationer som kan ta live på kurskontexten för att skapa rika realtidsupplevelser.
Utveckling: Utvärdera LLM och utveckla generativa AI-applikationer
Vi testade och utvärderade noggrant de första och tredje part LLM som finns tillgängliga i Amazon Bedrock för att välja den modell som är bäst lämpad för vår pipeline och användningsfall. Vi valde Anthropics Claude v2 och Claude Instant på Amazon Bedrock. För vår slutliga strukturerade och ostrukturerade datapipeline observerar vi att Anthropics Claude 2 på Amazon Bedrock genererade bättre övergripande resultat för vår slutliga datapipeline.
Uppmaning är en kritisk aspekt för att få LLM:er att mata ut text som önskat. Vi tillbringade mycket tid med att experimentera med olika uppmaningar för var och en av uppgifterna. Till exempel, för text-till-SQL-pipelinen hade vi flera reservuppmaningar, med ökande specificitet och gradvis förenklade tabellscheman. Om en SQL-fråga var ogiltig och resulterade i ett fel från Athena utvecklade vi en felkorrigeringsprompt som skulle skicka felet och felaktig SQL till LLM och be den fixa det. Den sista uppmaningen i text-till-SQL-pipelinen ber LLM att ta Athena-utdata, som kan tillhandahållas i Markdown- eller CSV-format, och ge ett svar till användaren. För den ostrukturerade texten utvecklade vi allmänna uppmaningar för att använda sammanhanget hämtat från Amazon Kendra för att svara på användarfrågan. Uppmaningen inkluderade instruktioner om att endast använda informationen hämtad från Amazon Kendra och inte förlita sig på data från LLM-förutbildningen.
Latens är ofta ett problem med generativa AI-applikationer, och det är också fallet här. Det är särskilt ett problem för text-till-SQL, som kräver en initial SQL-generering LLM-anrop, följt av en svarsgenerering LLM-anrop. Om vi använder en stor LLM, som Anthropics Claude V2, fördubblar detta effektivt latensen för bara en LLM-anrop. Vi experimenterade med flera konfigurationer av stora och mindre LLM:er för att utvärdera körtid såväl som korrekthet. Följande tabell visar ett exempel för en fråga som visas nedan som visar latensen, såväl som de genererade svaren med Anthropics Claude V2 och Claude Instant på Amazon Bedrock.

Prototype
I vår applikation använde vi en Lambda-funktion för att orkestrera de snabba valen och kommunikationen mellan Amazon Athena, Amazon Kendra och Amazon Bedrock. Den virtuella assistenten har ett konversationsgränssnitt, byggt med React och Cloudscape Design System, som använder text och videor för att interagera med användare.
Vår virtuella assistent kan ställa ett brett utbud av frågor om PGA TOUR-evenemang, spelare, statistik, historia och mer. Till exempel, när assistenten tillfrågas om Tony Finaus längsta drives vid Shriners Children's Open (en av Signature-evenemangen på PGA TOUR), kan assistenten fråga strukturerad data för att hämta hans slagnivådata. Den kan extrahera det exakta avståndet i yards, det runda numret och hålet under vilket han uppnådde detta rekord med hjälp av text-till-SQL-pipeline. Assistenten tolkar sedan dessa numeriska data för att generera ett slutligt svar. Följande tabell innehåller några exempelsvar.
| Fråga | Svar |
| Vilken var den längsta drive som Tony Finau träffade i Shriners Children's Open? | Den längsta drive som Tony Finau träffade i Shriners Childrens Open var 382 yards, som han slog under den första rundan på hål nummer 4 2018. |
| Vilken var den längsta drive som Collin Morikawa träffade i Shriners Children's Open? | Collin Morikawas längsta drive på Shriners Childrens Open var 334 yards. Detta inträffade 2019 under den första rundan på hål nummer 15. |
| Var det någon som gjorde ett ess på Shriners Children's Open 2022? | Ja, Adam Hadwin gjorde en hole-in-one på hål 14 under omgång 3 av Shriners Children's Open 2022 |
Följande förklarande video belyser några exempel på interaktion med den virtuella assistenten.
I de första testerna har vår virtuella PGA TOUR-assistent visat stort lovande när det gäller att förbättra fansupplevelser. Genom att blanda AI-teknologier som text-till-SQL, semantisk sökning och generering av naturligt språk, levererar assistenten informativa, engagerande svar. Fansen har möjlighet att enkelt komma åt data och berättelser som tidigare var svåra att hitta.
Vad har framtiden att erbjuda?
När vi fortsätter utvecklingen kommer vi att utöka utbudet av frågor som vår virtuella assistent kan hantera. Detta kommer att kräva omfattande tester, genom samarbete mellan AWS och PGA TOUR. Med tiden siktar vi på att utveckla assistenten till en personlig, omni-channel-upplevelse tillgänglig över webb-, mobil- och röstgränssnitt.
Etableringen av en molnbaserad generativ AI-assistent låter PGA TOUR presentera sin stora datakälla för flera interna och externa intressenter. När det sportgenerativa AI-landskapet utvecklas, möjliggör det skapandet av nytt innehåll. Du kan till exempel använda AI och maskininlärning (ML) för att visa innehåll som fans vill se när de tittar på ett evenemang, eller när produktionsteam letar efter bilder från tidigare turneringar som matchar en aktuell händelse. Till exempel, om Max Homa gör sig redo att ta sitt sista skott på PGA TOUR Championship från en plats 20 fot från stiftet, kan PGA TOUR använda AI och ML för att identifiera och presentera klipp, med AI-genererade kommentarer, av honom försökte ett liknande skott fem gånger tidigare. Den här typen av åtkomst och data tillåter ett produktionsteam att omedelbart lägga till ett värde till sändningen eller tillåta ett fan att anpassa den typ av data som de vill se.
"PGA TOUR är branschledande när det gäller att använda banbrytande teknologi för att förbättra fläktupplevelsen. AI ligger i framkant av vår teknikstack, där det gör det möjligt för oss att skapa en mer engagerande och interaktiv miljö för fans. Detta är början på vår generativa AI-resa i samarbete med AWS Generative AI Innovation Center för en transformerande end-to-end kundupplevelse. Vi arbetar för att utnyttja Amazon Bedrock och vår egendomsdata för att skapa en interaktiv upplevelse för PGA TOUR-fans för att hitta information av intresse om ett evenemang, spelare, statistik eller annat innehåll på ett interaktivt sätt."
– Scott Gutterman, SVP för Broadcast and Digital Properties på PGA TOUR.
Slutsats
Projektet vi diskuterade i det här inlägget exemplifierar hur strukturerade och ostrukturerade datakällor kan smältas samman med hjälp av AI för att skapa nästa generations virtuella assistenter. För sportorganisationer möjliggör denna teknik ett mer uppslukande engagemang hos fansen och låser upp intern effektivitet. Den dataintelligens vi tar fram hjälper PGA TOUR-intressenter som spelare, tränare, funktionärer, partners och media att fatta välgrundade beslut snabbare. Utöver sport kan vår metodik replikeras i alla branscher. Samma principer gäller för byggnadsassistenter som engagerar kunder, anställda, studenter, patienter och andra slutanvändare. Med genomtänkt design och testning kan praktiskt taget alla organisationer dra nytta av ett AI-system som kontextualiserar deras strukturerade databaser, dokument, bilder, videor och annat innehåll.
Om du är intresserad av att implementera liknande funktioner, överväg att använda Agenter för Amazon Bedrock och Kunskapsbaser för Amazon Bedrock som en alternativ, helt AWS-hanterad lösning. Detta tillvägagångssätt kan ytterligare undersöka tillhandahållande av intelligent automation och datasökningsförmåga genom anpassningsbara agenter. Dessa agenter skulle potentiellt kunna omvandla interaktioner med användarapplikationer till att bli mer naturliga, effektiva och effektiva.
Om författarna
 Scott Gutterman är SVP för Digital Operations för PGA TOUR. Han är ansvarig för TOUR:s övergripande digitala verksamhet, produktutveckling och driver deras GenAI-strategi.
Scott Gutterman är SVP för Digital Operations för PGA TOUR. Han är ansvarig för TOUR:s övergripande digitala verksamhet, produktutveckling och driver deras GenAI-strategi.
 Ahsan Ali är en tillämpad forskare vid Amazon Generative AI Innovation Center, där han arbetar med kunder från olika domäner för att lösa deras akuta och dyra problem med hjälp av Generative AI.
Ahsan Ali är en tillämpad forskare vid Amazon Generative AI Innovation Center, där han arbetar med kunder från olika domäner för att lösa deras akuta och dyra problem med hjälp av Generative AI.
 Tahin Syed är en tillämpad forskare med Amazon Generative AI Innovation Center, där han arbetar med kunder för att hjälpa till att förverkliga affärsresultat med generativa AI-lösningar. Utanför jobbet tycker han om att testa ny mat, resa och lära ut taekwondo.
Tahin Syed är en tillämpad forskare med Amazon Generative AI Innovation Center, där han arbetar med kunder för att hjälpa till att förverkliga affärsresultat med generativa AI-lösningar. Utanför jobbet tycker han om att testa ny mat, resa och lära ut taekwondo.
 Grace Lang är en Associate Data & ML-ingenjör med AWS Professional Services. Driven av en passion för att övervinna tuffa utmaningar hjälper Grace kunder att nå sina mål genom att utveckla maskininlärningsdrivna lösningar.
Grace Lang är en Associate Data & ML-ingenjör med AWS Professional Services. Driven av en passion för att övervinna tuffa utmaningar hjälper Grace kunder att nå sina mål genom att utveckla maskininlärningsdrivna lösningar.
 Jae Lee är Senior Engagement Manager i ProServes M&E-vertikal. Hon leder och levererar komplexa engagemang, uppvisar starka problemlösningsförmåga, hanterar intressenternas förväntningar och kurerar presentationer på chefsnivå. Hon tycker om att arbeta med projekt fokuserade på sport, generativ AI och kundupplevelse.
Jae Lee är Senior Engagement Manager i ProServes M&E-vertikal. Hon leder och levererar komplexa engagemang, uppvisar starka problemlösningsförmåga, hanterar intressenternas förväntningar och kurerar presentationer på chefsnivå. Hon tycker om att arbeta med projekt fokuserade på sport, generativ AI och kundupplevelse.
 Karn Chahar är en säkerhetskonsult med det delade leveransteamet på AWS. Han är en teknikentusiast som tycker om att arbeta med kunder för att lösa deras säkerhetsutmaningar och förbättra deras säkerhetsställning i molnet.
Karn Chahar är en säkerhetskonsult med det delade leveransteamet på AWS. Han är en teknikentusiast som tycker om att arbeta med kunder för att lösa deras säkerhetsutmaningar och förbättra deras säkerhetsställning i molnet.
 Mike Amjadi är en Data & ML Engineer med AWS ProServe fokuserad på att göra det möjligt för kunder att maximera värdet av data. Han är specialiserad på att designa, bygga och optimera datapipelines enligt väl utformade principer. Mike brinner för att använda teknik för att lösa problem och är engagerad i att leverera de bästa resultaten för våra kunder.
Mike Amjadi är en Data & ML Engineer med AWS ProServe fokuserad på att göra det möjligt för kunder att maximera värdet av data. Han är specialiserad på att designa, bygga och optimera datapipelines enligt väl utformade principer. Mike brinner för att använda teknik för att lösa problem och är engagerad i att leverera de bästa resultaten för våra kunder.
 Vrushali Sawant är en Front End Engineer med Proserve. Hon är mycket skicklig på att skapa responsiva webbsidor. Hon älskar att arbeta med kunder, förstå deras krav och förse dem med skalbara, lättanvända UI/UX-lösningar.
Vrushali Sawant är en Front End Engineer med Proserve. Hon är mycket skicklig på att skapa responsiva webbsidor. Hon älskar att arbeta med kunder, förstå deras krav och förse dem med skalbara, lättanvända UI/UX-lösningar.
 Neelam Patel är en Customer Solutions Manager på AWS och leder nyckelinitiativ för generativ AI och molnmodernisering. Neelam arbetar med nyckelchefer och teknikägare för att ta itu med deras molntransformationsutmaningar och hjälper kunder att maximera fördelarna med molnadoption. Hon har en MBA från Warwick Business School, Storbritannien och en kandidatexamen i datateknik, Indien.
Neelam Patel är en Customer Solutions Manager på AWS och leder nyckelinitiativ för generativ AI och molnmodernisering. Neelam arbetar med nyckelchefer och teknikägare för att ta itu med deras molntransformationsutmaningar och hjälper kunder att maximera fördelarna med molnadoption. Hon har en MBA från Warwick Business School, Storbritannien och en kandidatexamen i datateknik, Indien.
 Dr Murali Baktha är Global Golf Solution Architect på AWS, spjutspetsar för centrala initiativ som involverar generativ AI, dataanalys och banbrytande molnteknik. Murali arbetar med nyckelchefer och teknikägare för att förstå kundernas affärsutmaningar och designar lösningar för att möta dessa utmaningar. Han har en MBA i finans från UConn och en doktorsexamen från Iowa State University.
Dr Murali Baktha är Global Golf Solution Architect på AWS, spjutspetsar för centrala initiativ som involverar generativ AI, dataanalys och banbrytande molnteknik. Murali arbetar med nyckelchefer och teknikägare för att förstå kundernas affärsutmaningar och designar lösningar för att möta dessa utmaningar. Han har en MBA i finans från UConn och en doktorsexamen från Iowa State University.
 Mehdi Noor är en tillämpad vetenskapschef på Generative Ai Innovation Center. Med en passion för att överbrygga teknik och innovation hjälper han AWS-kunder att låsa upp potentialen hos Generativ AI, omvandla potentiella utmaningar till möjligheter för snabba experiment och innovation genom att fokusera på skalbar, mätbar och effektfull användning av avancerad AI-teknik, och effektivisera vägen. till produktion.
Mehdi Noor är en tillämpad vetenskapschef på Generative Ai Innovation Center. Med en passion för att överbrygga teknik och innovation hjälper han AWS-kunder att låsa upp potentialen hos Generativ AI, omvandla potentiella utmaningar till möjligheter för snabba experiment och innovation genom att fokusera på skalbar, mätbar och effektfull användning av avancerad AI-teknik, och effektivisera vägen. till produktion.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/the-journey-of-pga-tours-generative-ai-virtual-assistant-from-concept-to-development-to-prototype/

