Bild av Freepik
Språkmodeller har revolutionerat området för naturlig språkbehandling. Medan stora modeller som GPT-3 har gripit rubriker, är små språkmodeller också fördelaktiga och tillgängliga för olika applikationer. I den här artikeln kommer vi att utforska betydelsen och användningsfallen av små språkmodeller med alla implementeringssteg i detalj.
Små språkmodeller är kompakta versioner av sina större motsvarigheter. De erbjuder flera fördelar. Några av fördelarna är följande:
- Effektivitet: Jämfört med stora modeller kräver små modeller mindre beräkningskraft, vilket gör dem lämpliga för miljöer med begränsade resurser.
- Hastighet: De kan göra beräkningen snabbare, som att generera texterna baserade på given input snabbare, vilket gör dem idealiska för realtidsapplikationer där du kan ha hög daglig trafik.
- Anpassning: Du kan finjustera små modeller utifrån dina krav för domänspecifika uppgifter.
- Sekretess: Mindre modeller kan användas utan externa servrar, vilket säkerställer dataintegritet och integritet.
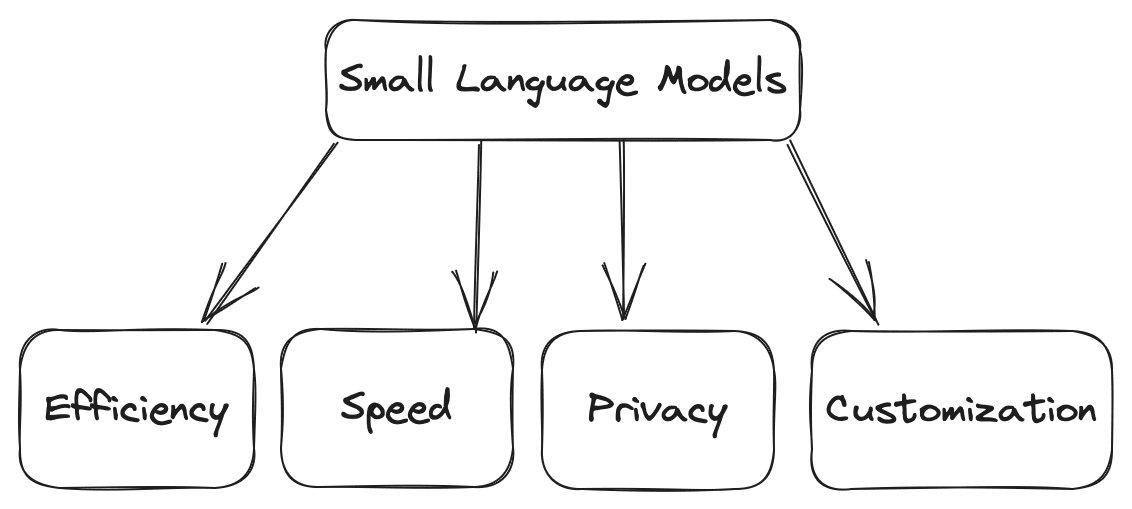
Bild av författare
Flera användningsfall för små språkmodeller inkluderar chatbots, innehållsgenerering, sentimentanalys, frågesvar och många fler.
Innan vi börjar djupdyka i hur små språkmodeller fungerar måste du ställa in din miljö, vilket innebär att du installerar nödvändiga bibliotek och beroenden. Att välja rätt ramverk och bibliotek för att bygga en språkmodell på din lokala CPU blir avgörande. Populära val inkluderar Python-baserade bibliotek som TensorFlow och PyTorch. Dessa ramverk tillhandahåller många förbyggda verktyg och resurser för maskininlärning och deep learning-baserade applikationer.
Installera obligatoriska bibliotek
I det här steget kommer vi att installera biblioteket "llama-cpp-python" och ctransformers för att introducera dig till små språkmodeller. Du måste öppna din terminal och köra följande kommandon för att installera den. När du kör följande kommandon, se till att du har Python och pip installerade på ditt system.
pip install llama-cpp-python
pip install ctransformers -q
Produktion:

Nu när vår miljö är klar kan vi få en förtränad liten språkmodell för lokalt bruk. För en liten språkmodell kan vi överväga enklare arkitekturer som LSTM eller GRU, som är beräkningsmässigt mindre intensiva än mer komplexa modeller som transformatorer. Du kan också använda förtränade ordinbäddningar för att förbättra din modells prestanda samtidigt som du minskar träningstiden. Men för att arbeta snabbt kommer vi att ladda ner en förtränad modell från webben.
Ladda ner en förtränad modell
Du kan hitta förtränade små språkmodeller på plattformar som Hugging Face (https://huggingface.co/models). Här är en snabb rundtur på webbplatsen, där du enkelt kan observera sekvenserna av modeller som tillhandahålls, som du enkelt kan ladda ner genom att logga in i applikationen eftersom dessa är öppen källkod.
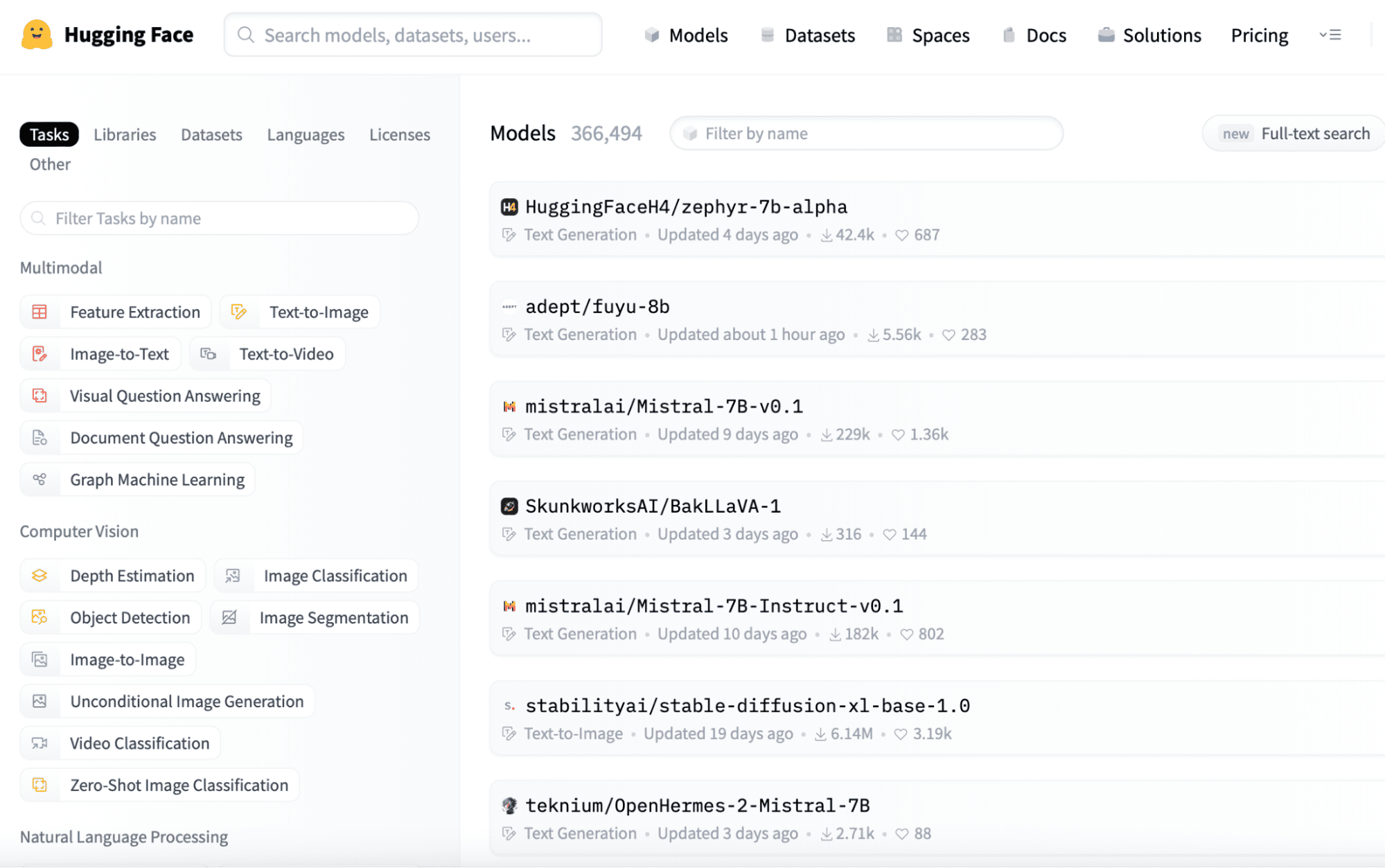
Du kan enkelt ladda ner modellen du behöver från denna länk och spara den i din lokala katalog för vidare användning.
from ctransformers import AutoModelForCausalLMI steget ovan har vi färdigställt den förtränade modellen från Hugging Face. Nu kan vi använda den modellen genom att ladda den i vår miljö. Vi importerar AutoModelForCausalLM-klassen från ctransformers-biblioteket i koden nedan. Denna klass kan användas för att ladda och arbeta med modeller för kausal språkmodellering.
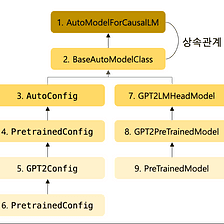
Bild från Medium
# Load the pretrained model
llm = AutoModelForCausalLM.from_pretrained('TheBloke/Llama-2-7B-Chat-GGML', model_file = 'llama-2-7b-chat.ggmlv3.q4_K_S.bin' )
Produktion:

Små språkmodeller kan finjusteras utifrån dina specifika behov. Om du måste använda dessa modeller i verkliga applikationer är det viktigaste att komma ihåg effektivitet och skalbarhet. Så för att göra de små språkmodellerna effektiva jämfört med stora språkmodeller kan du justera kontextstorleken och batchningen (partitionera data i mindre batcher för snabbare beräkning), vilket också resulterar i att övervinna skalbarhetsproblemet.
Ändra kontextstorlek
Kontextstorleken avgör hur mycket text modellen tar hänsyn till. Baserat på ditt behov kan du välja värdet på kontextstorlek. I det här exemplet kommer vi att ställa in värdet på denna hyperparameter som 128 tokens.
model.set_context_size(128)Batchning för effektivitet
Genom att introducera batchtekniken är det möjligt att behandla flera datasegment samtidigt, vilket kan hantera frågorna parallellt och hjälpa till att skala applikationen för en stor uppsättning användare. Men när du bestämmer batchstorleken måste du noggrant kontrollera ditt systems kapacitet. Annars kan ditt system orsaka problem på grund av hög belastning.
model.set_batch_size(16)Fram till detta steg är vi klara med att göra modellen, ställa in den modellen och spara den. Nu kan vi snabbt testa det baserat på vår användning och kontrollera om det ger samma utdata som vi förväntar oss. Så låt oss ge några inmatningsfrågor och generera texten baserat på vår laddade och konfigurerade modell.
for word in llm('Explain something about Kdnuggets', stream = True): print(word, end='')
Produktion:

För att få lämpliga resultat för de flesta inmatningsfrågor från din lilla språkmodell kan följande saker övervägas.
- Finjustering: Om din applikation kräver hög prestanda, det vill säga att resultatet av frågorna ska lösas på betydligt kortare tid, måste du finjustera din modell på din specifika datauppsättning, den korpus som du tränar din modell på.
- Cachning: Genom att använda cachningstekniken kan du lagra vanliga data baserade på användaren i RAM så att när användaren kräver den datan igen kan den enkelt tillhandahållas istället för att hämta igen från disken, vilket kräver relativt sett mer tid, pga. det kan generera resultat för att påskynda framtida förfrågningar.
- Vanliga problem: Om du stöter på problem när du skapar, laddar och konfigurerar modellen kan du hänvisa till dokumentationen och användargemenskapen för felsökningstips.
I den här artikeln diskuterade vi hur du kan skapa och distribuera en liten språkmodell på din lokala CPU genom att följa de sju enkla stegen som beskrivs i den här artikeln. Detta kostnadseffektiva tillvägagångssätt öppnar dörren till olika applikationer för språkbehandling eller datorseende och fungerar som ett språngbräde för mer avancerade projekt. Men när du arbetar med projekt måste du komma ihåg följande saker för att lösa eventuella problem:
- Spara regelbundet kontrollpunkter under träningen för att säkerställa att du kan fortsätta träna eller återställa din modell i händelse av avbrott.
- Optimera din kod- och datapipelines för effektiv minnesanvändning, särskilt när du arbetar på en lokal CPU.
- Överväg att använda GPU-acceleration eller molnbaserade resurser om du behöver skala upp din modell i framtiden.
Sammanfattningsvis erbjuder små språkmodeller en mångsidig och effektiv lösning för olika språkbehandlingsuppgifter. Med rätt inställning och optimering kan du utnyttja deras kraft effektivt.
Ariska Garg är en B.Tech. Elektroteknikstudent, går för närvarande sista året av sin grundexamen. Hans intresse ligger inom området webbutveckling och maskininlärning. Han har följt detta intresse och är angelägen om att arbeta mer i dessa riktningar.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/7-steps-to-running-a-small-language-model-on-a-local-cpu?utm_source=rss&utm_medium=rss&utm_campaign=7-steps-to-running-a-small-language-model-on-a-local-cpu

