Ett av de nyare databuzzorden är "dataskuld". Egentligen är den ungefär 10 år gammal, och den blev populär ända sedan agila människor insåg att skjuta upp saker skapar inte bara tekniska skulder, utan säkerligen också dataskulder. Kommer vi 2023 att bli bättre på att inte skapa så mycket dataskulder, och kommer det att vara för att vi kan komma till vet saker lättare (kunskapsdiagram) eller kommer det att vara på grund av att kunna antar saker lättare och mer tillförlitligt (ML)? Eller båda?
Låt oss först sätta en ram för att titta på frågorna. I januari 2021 postade jag detta: Tre spelförändrande datamodelleringsperspektiv.
Sedan dess har intresset för att tillämpa ML och AI till "Dataops” i analysutrymmet har stigit till nya höjder. Hur jämför det med de spelförändrande perspektiven som jag föreslog för två år sedan?
De tre mantran i mitt inlägg i januari 2021 var:
- kontextualisering
- Federerad semantik
- Ansvarighet
Mönstren är sammanflätade, egentligen:
- Du måste fastställa relevanta sammanhang/semantik/ansvarskrav,
- Då måste du upptäcka beroenden mellan de relevanta komponenterna,
- Och då ska man jämföra vad man har av specialiteter med vad man ska leverera av en robust lösning till verksamheten.
För sammanhang kan vi nämna specialiteter såsom egenskaper hos beroenden inom och mellan sammanhang:
- Kardinaliteter
- Tillval
- Arv
- Föreningar m.m.
För semantik kan specialiteter vara egenskaper inom och mellan semantik:
- Representationsformer
- Kvalitet
- Auktoritativa och lagstiftningsmässiga aspekter (efterlevnad, etc.)
- Standard semantik inom industridomäner etc.
- Metadata ändras
Slutligen, för ansvarsskyldighet är frågorna, inom och mellan projektmedlemmar:
- Auktoritativa och lagstiftande aspekter ("gäller det i domstol" etc.)
- Multi-temporalitet (och förändringar av sådana system över tid)
- Kvalitet (på registrering och ansvarsskyldighet)
- Retentionstid
- Metadata ändras
- Kombination av data med olika nivåer av precision, temporalitet och till och med olika datatyper
I (mycket) allmänna termer kan problemen listas som dessa:

Tyvärr är oron beroende av varandra i ett komplext nät:
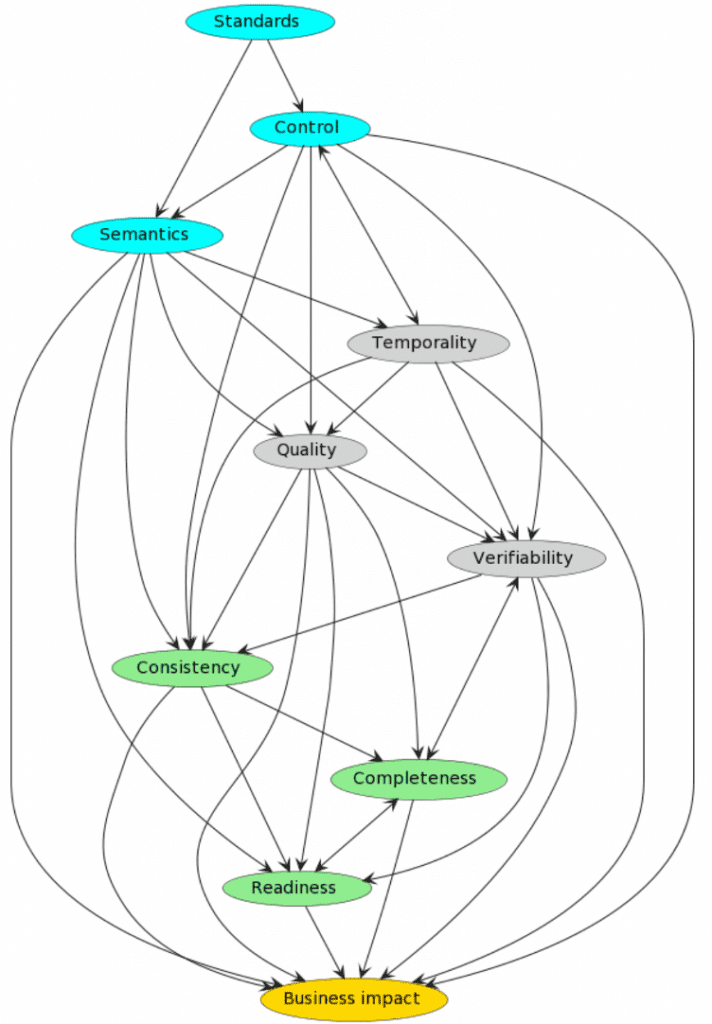
Ta några ögonblick för att härleda karaktären av beroenden (förutsättningar och samvarians) mellan problemen.
Låt oss gräva ner en nivå i vart och ett av de tre perspektiven.
Federerad semantik
Ja, det här låter som datamodeller, men här 2023 gör vi inte UML så mycket längre. Enklare och halvintelligenta lösningar finns till hands. Så, dra inte undan, ännu.

Ansvarighet
Efter att ha fastställt vilken (semantik) du pratar om är det dags att undersöka de olika aspekterna av datas tillförlitlighet.

kontextualisering
Dessa är slutgiltiga valideringar för att bestämma affärseffekten som kan levereras.

Orsaker och kostnader för dataskuld
Jag har försökt peka dig på frågorna att se upp med i den lilla analysmodellen ovan. Andra personer har skrivit väldigt bra och djupa inlägg om dataskuld. Till exempel:
Det finns gott om skäl (ursäkter) för att lämna något ogjort – tills förhoppningsvis senare.
John Ladley, som är en mycket kunnig person med en djup förståelse för inverkan av data på affärsresultat, ger sina bästa råd i inlägget som refereras till ovan. Njut av hans "dataskuldkvadrant" i inlägget!
Men dataskuld har en kostnad. John Ladley riskerar sin nacke vid en möjlig påverkan på 10 % på de årliga IT-kostnaderna som spenderas på att hantera dataskuldposter.
Det är bara de påtagliga utvecklingskostnaderna. Jag hävdar att det också kan finnas värre bieffekter som missnöje hos kunder, förlorade intäkter, för låga vinster etc.
En av mina favoritskräckhistorier handlar om ett multinationellt B2C-företag som ville implementera ett nytt försäljningsrapporteringssystem. De byggde den för att samla in data från ett antal affärssystem som körs i olika länder – bara för att upptäcka att den konsoliderade databasen saknade produktkategorihierarkiinformation i mer än 50 % av försäljningsrapportraderna! Det försenade projektet med flera månader, där unga, tuffa controllers turades om att besöka de olika dotterbolagen... Hade de vetat det i förväg hade projektet förmodligen sett annorlunda ut.
Automation till räddning?
I grund och botten finns det två typer av automatisk hjälp möjliga:
- Kunskap baserad på förberedd semantik och/eller förvärvad metadata från API:er från tekniska eller öppen källinformationsleverantörer, eller
- Statistiska (gissnings)tekniker (ML) kompletterade med enhetsigenkänning, allt baserat på tillgängliga data
Möjligheterna för leverantörer och öppen källkod utvecklas snabbt, så följande är bara mina insatser i skrivande stund. Jag har försökt att bedöma attraktionskraften (0 till 10) hos de två metoderna för alla problem:

Naturligtvis kan dessa betyg diskuteras. Jag tycker dock att rekommendationen är tydlig: Var du än kan bör du leta efter semantikbaserad input. Affärseffekten kommer att förbättras och tillförlitligheten blir högre.
Möjligheterna finns så klart. Verktygen varierar mycket mellan olika plattformskategorier – dataväv, datakataloger, datanät, ETL, semantiska media, semantiska lager och allt annat. Var försiktig där ute, men dra nytta av det semantiska teknologier!
2023 Möjligheter
Fresh out here in 2023 är en ny bok av Andrew Iliadis från Temple University: "Semantiska medier – kartläggning av betydelse på internet." Han kommer från den informationsvetenskapliga sidan av huset och har ett trevligt, pragmatiskt och nyttoorienterat förhållningssätt till vad vi kan lära oss av semantiska medier.
Det finns gott om sådana idag: Google, Wikidata, Amazon, Facebook, IBM, eBay, Apple, Microsoft och fler (nämns i bokens ordning). Nästan alla är grafer (semantiska grafer och några egenskapsgrafer). Vissa av dem är i "pre-GA", vissa är öppen källkod, men de flesta är proprietära. Observera att trots de stora kunskapsgraferna som används av Google och de andra är byggda från mycket stora datamängder, finns det en viss kurering (automatiserad och manuell) som tillämpas, och det finns flera historier om felaktiga sökmotorresultat. Faktum är att sökmotorer är något igår. Idag handlar det om att tillhandahålla information – på ett one-stop shopping sätt.
I detta utrymme hittar du kunskapsbaser och dito grafer, kunskapspaneler och inte minst API:er. Alla är potentiella informationskällor med strukturerade format (semantisk metadata). Och ja, det är starkt påverkat av RDF/OWL och relaterade semantiska teknologier. Detta är en rik damm för dig att fiska i 2023! Håll mig uppdaterad när du får en stor fångst!
Andrews bok är inte en lärobok. Men jag är säker på att du kommer att hitta några användbara anvisningar. De tre första nedan är inspirerade av hans bok, och de åtföljs av ett exempel på en industrisektors semantisk standard och de två sista är exempel på hur man får in semantik i egenskapsgrafer:
Så vad det hela handlar om är att det verkligen är möjligt att göra något för att få ner dataskulden när man utvecklar analyspipelines, etc. Du kan ta in lite av detta nytänkande för att hjälpa dig att gå snabbare och även säkrare:
- Kombinationen av kontextualisering, federerad semantik och ansvarighet dikterar att du bör (och skulle kunna) bygga en kunskapsgraf 2023
- Du kan göra det genom att
- Utnyttja API:er till semantiska medier som Google, Apple, Microsoft etc. och/eller dra fördel av öppna semantiska källor som t.ex.
- Wikidata BranschstandardontologierInternationella och nationella standardontologierAndra mer eller mindre öppna källor som Opencorporates och många fler
- Bygger den i egenskapsgrafteknik, som har en lättare inlärningskurva än RDF
- Utnyttja API:er till semantiska medier som Google, Apple, Microsoft etc. och/eller dra fördel av öppna semantiska källor som t.ex.
- Du kan använda din egen kunskapsgraf som en viktig del av datakontraktet med verksamheten (gör krav maskinläsbara, eller så kan du behålla enkla textfiler i t.ex. PlantUML konceptsyntax)
- Du kan använda din kunskapsgraf för att göra fullständighetstest samt leta efter ansvarsegenskaper, saknad information, (brist på) tidsinformation och så vidare
- Du kan använda en grafprototyp som en test- och verifieringsplattform för affärsmän
Inlärningsgrafdatabas är avgörande. Det här är det – kör på det – jag är verkligen exalterad över den här paletten med möjligheter för 2023! Störning? Ja, och en bra sådan – att lösa verkliga problem.
Håll mig uppdaterad!
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.dataversity.net/2023-mitigating-data-debt-by-knowing-or-by-guessing/

