Beskrivning
I hjärtat av datavetenskap ligger statistik, som har funnits i århundraden men fortfarande är grundläggande i dagens digitala tidsålder. Varför? Eftersom grundläggande statistikbegrepp är ryggraden i dataanalys, gör det möjligt för oss att förstå de enorma mängder data som genereras dagligen. Det är som att samtala med data, där statistik hjälper oss att ställa rätt frågor och förstå historierna som data försöker berätta.
Från att förutsäga framtida trender och fatta beslut baserat på data till att testa hypoteser och mäta prestanda, statistik är verktyget som driver insikterna bakom datadrivna beslut. Det är bryggan mellan rådata och handlingsbara insikter, vilket gör det till en oumbärlig del av datavetenskap.
I den här artikeln har jag sammanställt de 15 bästa grundläggande statistikkoncepten som varje nybörjare inom datavetenskap bör känna till!

Innehållsförteckning
1. Statistisk urval och datainsamling
Vi kommer att lära oss några grundläggande statistikkoncept, men att förstå var vår data kommer ifrån och hur vi samlar in den är viktigt innan vi dyker djupt ner i datahavet. Det är här populationer, prover och olika provtagningstekniker kommer in i bilden.
Föreställ dig att vi vill veta medellängden på människor i en stad. Det är praktiskt att mäta alla, så vi tar en mindre grupp (prov) som representerar den större populationen. Tricket ligger i hur vi väljer detta prov. Tekniker som slumpmässigt, stratifierat eller klusterprov säkerställer att vårt urval är väl representerat, vilket minimerar bias och gör våra resultat mer tillförlitliga.
Genom att förstå populationer och urval kan vi med säkerhet utöka våra insikter från urvalet till hela populationen och fatta välgrundade beslut utan att behöva undersöka alla.
2. Typer av data och mätskalor
Data finns i olika varianter, och att veta vilken typ av data du har att göra med är avgörande för att välja rätt statistiska verktyg och tekniker.
Kvantitativ och kvalitativ data
- Kvantitativa data: Denna typ av data handlar om siffror. Det är mätbart och kan användas för matematiska beräkningar. Kvantitativ data talar om för oss "hur mycket" eller "hur många", som antalet användare som besöker en webbplats eller temperaturen i en stad. Det är enkelt och objektivt och ger en tydlig bild genom numeriska värden.
- Kvalitativa data: Omvänt handlar kvalitativ data om egenskaper och beskrivningar. Det handlar om "vilken typ" eller "vilken kategori". Se det som data som beskriver egenskaper eller attribut, som färgen på en bil eller genren på en bok. Dessa data är subjektiva, baserade på observationer snarare än mätningar.
Fyra måttvågar
- Nominell skala: Detta är den enklaste formen av mätning som används för att kategorisera data utan en specifik ordning. Exempel inkluderar typer av kök, blodgrupper eller nationalitet. Det handlar om märkning utan något kvantitativt värde.
- Ordinalskala: Data kan beställas eller rangordnas här, men intervallen mellan värden är inte definierade. Tänk på en nöjdhetsundersökning med alternativ som nöjd, neutral och missnöjd. Det berättar ordningen men inte avståndet mellan rankingarna.
- Intervallskala: Intervall skalar beställer data och kvantifierar skillnaden mellan poster. Det finns dock ingen faktisk nollpunkt. Ett bra exempel är temperaturen i Celsius; skillnaden mellan 10°C och 20°C är densamma som mellan 20°C och 30°C, men 0°C betyder inte frånvaro av temperatur.
- Förhållandeskala: Den mest informativa skalan har alla egenskaper hos en intervallskala plus en meningsfull nollpunkt, vilket möjliggör en exakt jämförelse av magnituder. Exempel inkluderar vikt, längd och inkomst. Här kan vi säga att något är dubbelt så mycket som ett annat.
3. Beskrivande statistik
Föreställ dig beskrivande statistik som din första dejt med dina uppgifter. Det handlar om att lära känna grunderna, de breda dragen som beskriver vad som ligger framför dig. Beskrivande statistik har två huvudtyper: centrala tendens- och variabilitetsmått.
Centralmått: Dessa är som datas tyngdpunkt. De ger oss ett enda värde som är typiskt eller representativt för vår datamängd.
Betyda: Genomsnittet beräknas genom att lägga ihop alla värden och dividera med antalet värden. Det är som det övergripande betyget för en restaurang baserat på alla recensioner. Den matematiska formeln för medelvärdet ges nedan:

Median: Det mellersta värdet när data sorteras från minsta till största. Om antalet observationer är jämnt, är det genomsnittet av de två mittersta talen. Den används för att hitta mittpunkten på en bro.
Om n är jämnt är medianen medelvärdet av de två centrala talen.
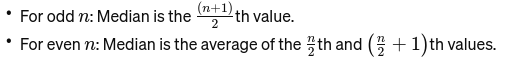
Mode: Det är den vanligast förekommande värdet i en datamängd. Se det som den mest populära rätten på en restaurang.
Variabilitetsmått: Medan mått på central tendens tar oss till centrum, berättar mått på variabilitet oss om spridningen eller spridningen.
Räckvidd: Skillnaden mellan högsta och lägsta värden. Det ger en grundläggande uppfattning om spridningen.
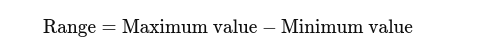
Variation: Mäter hur långt varje nummer i mängden är från medelvärdet och därmed från vartannat tal i mängden. För ett prov, är det beräknat som:
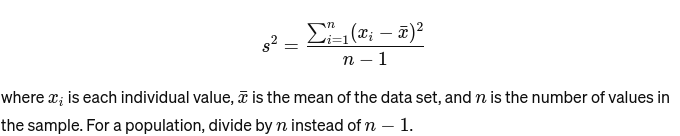
Standardavvikelse: Kvadratroten ur variansen ger ett mått på medelavståndet från medelvärdet. Det är som att bedöma konsistensen av en bagares kakstorlekar. Det representeras som:
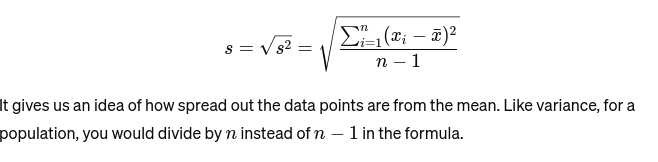
Innan vi går vidare till nästa grundläggande statistikkoncept, här är ett Nybörjarguide till statistisk analys till dig!
4. Datavisualisering
Datavisualisering är konsten och vetenskapen att berätta historier med data. Det gör komplexa resultat från vår analys till något påtagligt och begripligt. Det är avgörande för utforskande dataanalys, där målet är att avslöja mönster, korrelationer och insikter från data utan att ännu dra formella slutsatser.
- Diagram och grafer: Från och med grunderna ger stapeldiagram, linjediagram och cirkeldiagram grundläggande insikter i data. De är ABC:erna för datavisualisering, viktiga för alla databerättare.
Vi har ett exempel på ett stapeldiagram (vänster) och ett linjediagram (höger) nedan.
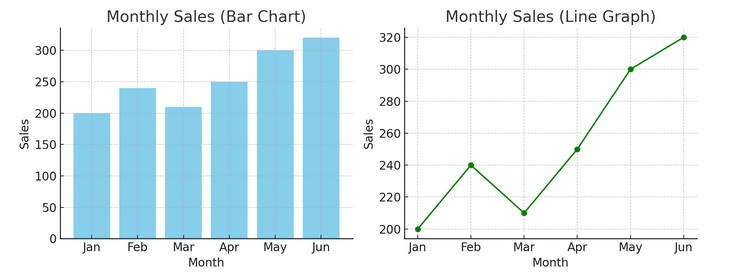
- Avancerade visualiseringar: När vi dyker djupare tillåter värmekartor, spridningsdiagram och histogram mer nyanserad analys. Dessa verktyg hjälper till att identifiera trender, distributioner och extremvärden.
Nedan är ett exempel på ett spridningsdiagram och ett histogram

Visualiseringar överbryggar rådata och mänsklig kognition, vilket gör att vi snabbt kan tolka och förstå komplexa datauppsättningar.
5. Sannolikhetsgrunderna
Sannolikhet är grammatiken i statistikens språk. Det handlar om chansen eller sannolikheten att händelser inträffar. Att förstå begrepp i sannolikhet är väsentligt för att tolka statistiska resultat och göra förutsägelser.
- Oberoende och beroende evenemang:
- Oberoende evenemang: En händelses utfall påverkar inte en annans utfall. Som att vända ett mynt förändrar inte oddsen för nästa vändning att få huvuden på en flip.
- Beroende händelser: Resultatet av en händelse påverkar resultatet av en annan. Om du till exempel drar ett kort från en kortlek och inte byter ut det, ändras dina chanser att dra ett annat specifikt kort.
Sannolikhet utgör grunden för att dra slutsatser om data och är avgörande för att förstå statistisk signifikans och hypotestestning.
6. Vanliga sannolikhetsfördelningar
Sannolikhetsfördelningar är som olika arter i statistikekosystemet, var och en anpassad till sin nisch av tillämpningar.
- Normal distribution: Ofta kallad klockkurvan på grund av dess form, denna fördelning kännetecknas av dess medelvärde och standardavvikelse. Det är ett vanligt antagande i många statistiska tester eftersom många variabler är naturligt fördelade på detta sätt i den verkliga världen.
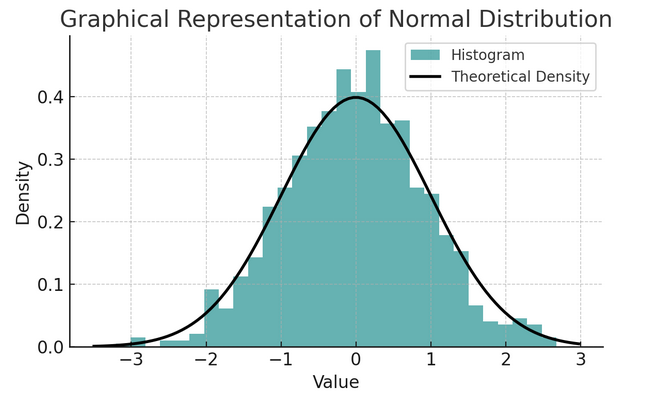
En uppsättning regler som kallas den empiriska regeln eller 68-95-99.7-regeln sammanfattar egenskaperna hos en normalfördelning, som beskriver hur data sprids runt medelvärdet.
68-95-99.7 Regel (empirisk regel)
Denna regel gäller för en perfekt normalfördelning och beskriver följande:
- 68% av datan faller inom en standardavvikelse (σ) av medelvärdet (μ).
- 95% av datan faller inom två standardavvikelser från medelvärdet.
- Ungefär 99.7% av datan faller inom tre standardavvikelser från medelvärdet.
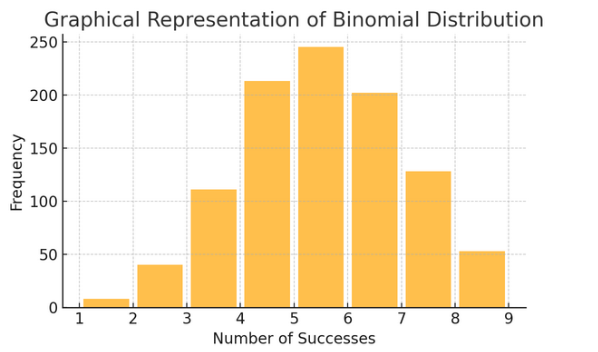
Binomial distribution: Denna fördelning gäller situationer med två utfall (som framgång eller misslyckande) som upprepas flera gånger. Det hjälper till att modellera händelser som att vända ett mynt eller ta ett sant/falskt test.
Poisson-distribution räknar antalet gånger något händer under ett specifikt intervall eller mellanrum. Den är idealisk för situationer där händelser sker oberoende och konstant, som de dagliga e-postmeddelanden du får.
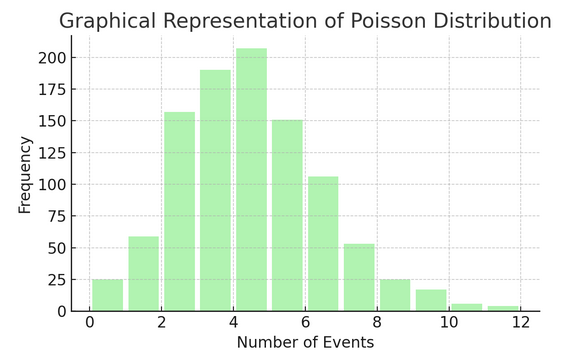
Varje distribution har sin egen uppsättning formler och egenskaper, och att välja rätt beror på typen av dina data och vad du försöker ta reda på. Genom att förstå dessa fördelningar kan statistiker och datavetare modellera verkliga fenomen och förutsäga framtida händelser korrekt.
7 . Hypotestestning
Tänk på hypotesprövning som detektivarbete inom statistik. Det är en metod för att testa om en viss teori om vår data kan vara sann. Denna process börjar med två motsatta hypoteser:
- Nollhypotes (H0): Detta är standardantagandet, vilket tyder på att det finns en effekt eller skillnad. Det står att "inte" är ny här."
- Al "alternativ hypotes (H1 eller Ha): Detta utmanar status quo, föreslår en effekt eller en skillnad. Den hävdar: "Något är intressant på gång."
Exempel: Testa om ett nytt dietprogram leder till viktminskning jämfört med att inte följa någon diet.
- Nollhypotes (H0): Det nya kostprogrammet leder inte till viktminskning (ingen skillnad i viktminskning mellan de som följer det nya kostprogrammet och de som inte gör det).
- Alternativ hypotes (H1): Det nya kostprogrammet leder till viktminskning (en skillnad i viktminskning mellan de som följer det och de som inte gör det).
Hypotestestning innebär att välja mellan dessa två baserat på bevisen (våra data).
Typ I och II fel- och signifikansnivåer:
- Typ I-fel: Detta händer när vi felaktigt förkastar nollhypotesen. Den dömer en oskyldig person.
- Typ II fel: Detta inträffar när vi misslyckas med att förkasta en falsk nollhypotes. Det låter en skyldig person gå fri.
- Signifikansnivå (α): Detta är tröskeln för att bestämma hur mycket bevis som räcker för att förkasta nollhypotesen. Den är ofta inställd på 5 % (0.05), vilket indikerar en 5 % risk för ett typ I-fel.
8. Konfidensintervall
Förtroendeintervaller ge oss ett värdeintervall inom vilka vi förväntar oss att den giltiga populationsparametern (som ett medelvärde eller en andel) ska falla med en viss konfidensnivå (vanligtvis 95 %). Det är som att förutsäga ett idrottslags slutresultat med en felmarginal; vi säger, "Vi är 95 % säkra på att det verkliga resultatet kommer att ligga inom detta intervall."
Att konstruera och tolka konfidensintervall hjälper oss att förstå precisionen i våra uppskattningar. Ju bredare intervall, vår uppskattning är mindre exakt, och vice versa.
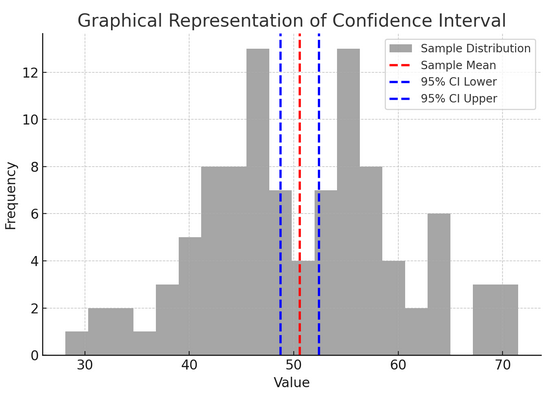
Ovanstående figur illustrerar konceptet med ett konfidensintervall (KI) i statistik, med hjälp av en stickprovsfördelning och dess 95 % konfidensintervall runt urvalets medelvärde.
Här är en uppdelning av de kritiska komponenterna i figuren:
- Provfördelning (grå histogram): Detta representerar fördelningen av 100 datapunkter slumpmässigt genererade från en normalfördelning med ett medelvärde på 50 och en standardavvikelse på 10. Histogrammet visar visuellt hur datapunkterna är spridda runt medelvärdet.
- Exempelmedelvärde (röd streckad linje): Denna rad indikerar provdatas medelvärde (genomsnitt). Det fungerar som den punktuppskattning kring vilken vi konstruerar konfidensintervallet. I det här fallet representerar det genomsnittet av alla provvärden.
- 95 % konfidensintervall (blå streckade linjer): Dessa två linjer markerar de nedre och övre gränserna för 95 % konfidensintervall runt urvalets medelvärde. Intervallet beräknas med hjälp av standardfelet för medelvärdet (SEM) och ett Z-värde som motsvarar den önskade konfidensnivån (1.96 för 95 % konfidens). Konfidensintervallet tyder på att vi är 95 % säkra på att populationsmedelvärdet ligger inom detta intervall.
9. Korrelation och orsakssamband
Korrelation och orsakssamband blandas ofta ihop, men de är olika:
- Korrelation: Indikerar ett samband eller samband mellan två variabler. När den ena förändras, tenderar den andra att förändras också. Korrelation mäts med en korrelationskoefficient som sträcker sig från -1 till 1. Ett värde närmare 1 eller -1 indikerar ett starkt samband, medan 0 antyder inga kopplingar.
- Orsakssamband: Det innebär att förändringar i en variabel direkt orsakar förändringar i en annan. Det är ett mer robust påstående än korrelation och kräver rigorösa tester.
Bara för att två variabler är korrelerade betyder det inte att den ena orsakar den andra. Detta är ett klassiskt fall av att inte blanda ihop "korrelation" med "orsakssamband".
10. Enkel linjär regression
Enkelt linjär regression är ett sätt att modellera förhållandet mellan två variabler genom att anpassa en linjär ekvation till observerade data. En variabel anses vara en förklarande variabel (oberoende), och den andra är en beroende variabel.
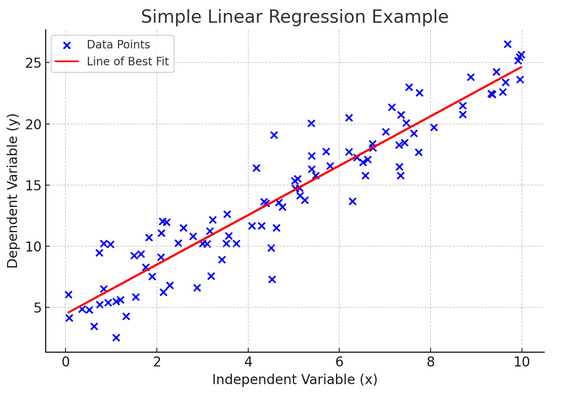
Enkel linjär regression hjälper oss att förstå hur förändringar i den oberoende variabeln påverkar den beroende variabeln. Det är ett kraftfullt verktyg för förutsägelse och är grunden för många andra komplexa statistiska modeller. Genom att analysera sambandet mellan två variabler kan vi göra välgrundade förutsägelser om hur de kommer att interagera.
Enkel linjär regression förutsätter ett linjärt samband mellan den oberoende variabeln (förklaringsvariabeln) och den beroende variabeln. Om förhållandet mellan dessa två variabler inte är linjärt, kan antagandena om enkel linjär regression kränkas, vilket kan leda till felaktiga förutsägelser eller tolkningar. Därför är det viktigt att verifiera ett linjärt samband i data innan enkel linjär regression tillämpas.
11. Multipel linjär regression
Tänk på multipel linjär regression som en förlängning av enkel linjär regression. Ändå, istället för att försöka förutsäga ett resultat med en riddare i lysande rustning (prediktor), har du ett helt lag. Det är som att uppgradera från en en-mot-en basketmatch till en hel laginsats, där varje spelare (prediktor) tar med sig unika färdigheter. Tanken är att se hur flera variabler tillsammans påverkar ett enda utfall.
Men med ett större team kommer utmaningen att hantera relationer, känd som multikollinearitet. Det uppstår när prediktorer är för nära varandra och delar liknande information. Föreställ dig två basketspelare som ständigt försöker ta samma skott; de kan komma i vägen för varandra. Regression kan göra det svårt att se varje prediktors unika bidrag, vilket potentiellt snedvrider vår förståelse av vilka variabler som är signifikanta.
12. Logistisk regression
Medan linjär regression förutsäger kontinuerliga resultat (som temperatur eller priser), logistisk återgång används när resultatet är definitivt (som ja/nej, vinna/förlora). Föreställ dig att försöka förutsäga om ett lag kommer att vinna eller förlora baserat på olika faktorer; logistisk regression är din bästa strategi.
Den transformerar den linjära ekvationen så att dess utdata faller mellan 0 och 1, vilket representerar sannolikheten att tillhöra en viss kategori. Det är som att ha en magisk lins som omvandlar kontinuerliga poäng till en tydlig "det här eller det" vy, vilket gör att vi kan förutsäga kategoriska resultat.
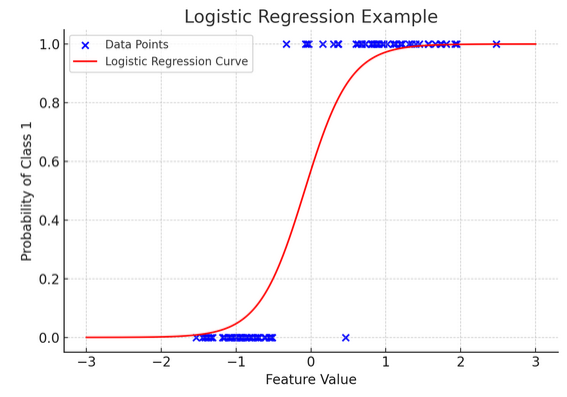
Den grafiska representationen illustrerar ett exempel på logistisk regression som tillämpas på en syntetisk binär klassificeringsdatauppsättning. De blå prickarna representerar datapunkterna, där deras position längs x-axeln anger funktionsvärdet och y-axeln anger kategorin (0 eller 1). Den röda kurvan representerar den logistiska regressionsmodellens förutsägelse av sannolikheten att tillhöra klass 1 (t.ex. "vinn") för olika funktionsvärden. Som du kan se övergår kurvan smidigt från sannolikheten för klass 0 till klass 1, vilket visar modellens förmåga att förutsäga kategoriska utfall baserat på en underliggande kontinuerlig funktion. .
Formeln för logistisk regression ges av:

Denna formel använder den logistiska funktionen för att omvandla den linjära ekvationens utdata till en sannolikhet mellan 0 och 1. Denna transformation tillåter oss att tolka utdata som sannolikheter för att tillhöra en viss kategori baserat på värdet av den oberoende variabeln xx.
13. ANOVA och Chi-Square Tester
ANOVA (Analysis of Variance) och Chi-Square tester är som detektiver i statistikvärlden och hjälper oss att lösa olika mysterier. jagt gör det möjligt för oss att jämföra medel mellan flera grupper för att se om åtminstone en är statistiskt annorlunda. Se det som att provsmaka prover från flera partier av kakor för att avgöra om någon batch smakar väsentligt annorlunda.
Å andra sidan används Chi-Square-testet för kategoriska data. Det hjälper oss att förstå om det finns ett signifikant samband mellan två kategoriska variabler. Finns det till exempel ett samband mellan en persons favoritgenre av musik och deras åldersgrupp? Chi-Square-testet hjälper till att svara på sådana frågor.
14. Central Limit Theorem och dess betydelse i datavetenskap
Smakämnen Central Limit Theorem (CLT) är en grundläggande statistisk princip som känns nästan magisk. Det säger oss att om du tar tillräckligt många prover från en population och beräknar deras medel, kommer dessa medel att bilda en normalfördelning (klockkurvan), oavsett populationens ursprungliga fördelning. Detta är otroligt kraftfullt eftersom det tillåter oss att dra slutsatser om populationer även när vi inte vet deras exakta fördelning.
Inom datavetenskap stödjer CLT många tekniker, vilket gör det möjligt för oss att använda verktyg utformade för normalfördelad data även när vår data initialt inte uppfyller dessa kriterier. Det är som att hitta en universell adapter för statistiska metoder, vilket gör många kraftfulla verktyg användbara i fler situationer.
15. Bias-Variance Tradeoff
In prediktiv modellering och maskininlärning, den avvägning mellan partiskhet och varians är ett avgörande koncept som belyser spänningen mellan två huvudtyper av fel som kan få våra modeller att gå snett. Bias hänvisar till fel från alltför förenklade modeller som inte fångar de underliggande trenderna väl. Föreställ dig att försöka passa en rak linje genom en krökt väg; du kommer att missa målet. Omvänt, avvikelser från alltför komplexa modeller fångar upp brus i data som om det vore ett verkligt mönster – som att spåra varje vridning och svänga på en gropig stig, och tro att det är vägen framåt.
Konsten ligger i att balansera dessa två för att minimera det totala felet, hitta den söta punkten där din modell är precis rätt – komplex nog för att fånga de exakta mönstren men enkel nog att ignorera det slumpmässiga bruset. Det är som att stämma en gitarr; det låter inte bra om det är för hårt eller löst. Avvägningen mellan partiskhet och varians handlar om att hitta den perfekta balansen mellan dessa två. Avvägningen mellan bias-varians är kärnan i att justera våra statistiska modeller för att prestera sitt bästa när det gäller att förutsäga utfall korrekt.
Slutsats
Från statistiskt urval till avvägningen mellan bias-varians, dessa principer är inte bara akademiska föreställningar utan viktiga verktyg för insiktsfull dataanalys. De utrustar blivande dataforskare med färdigheter att omvandla omfattande data till praktiska insikter, och betonar statistik som ryggraden i datadrivet beslutsfattande och innovation i den digitala tidsåldern.
Har vi missat något grundläggande statistikbegrepp? Låt oss veta i kommentarsfältet nedan.
utforska vår guide för statistik från början till slut för datavetenskap att veta om ämnet!
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

