Beskrivning
Machine Learning (ML) är ett studieområde som fokuserar på att utveckla algoritmer för att lära sig automatiskt från data, göra förutsägelser och härleda mönster utan att uttryckligen få veta hur man gör det. Det syftar till att skapa system som automatiskt förbättras med erfarenhet och data.
Detta kan uppnås genom övervakat lärande, där modellen tränas med hjälp av märkta data för att göra förutsägelser, eller genom oövervakad inlärning, där modellen försöker avslöja mönster eller korrelationer inom data utan specifika målutdata att förutse.
ML har framstått som ett oumbärligt och brett använt verktyg inom olika discipliner, inklusive datavetenskap, biologi, ekonomi och marknadsföring. Den har bevisat sin användbarhet i olika applikationer som bildklassificering, naturlig språkbehandling och bedrägeriupptäckt.
Maskininlärningsuppgifter
Maskininlärning kan grovt klassificeras i tre huvuduppgifter:
- Övervakad inlärning
- Oövervakat lärande
- Förstärkningslärande
Här kommer vi att fokusera på de två första fallen.
Övervakat lärande
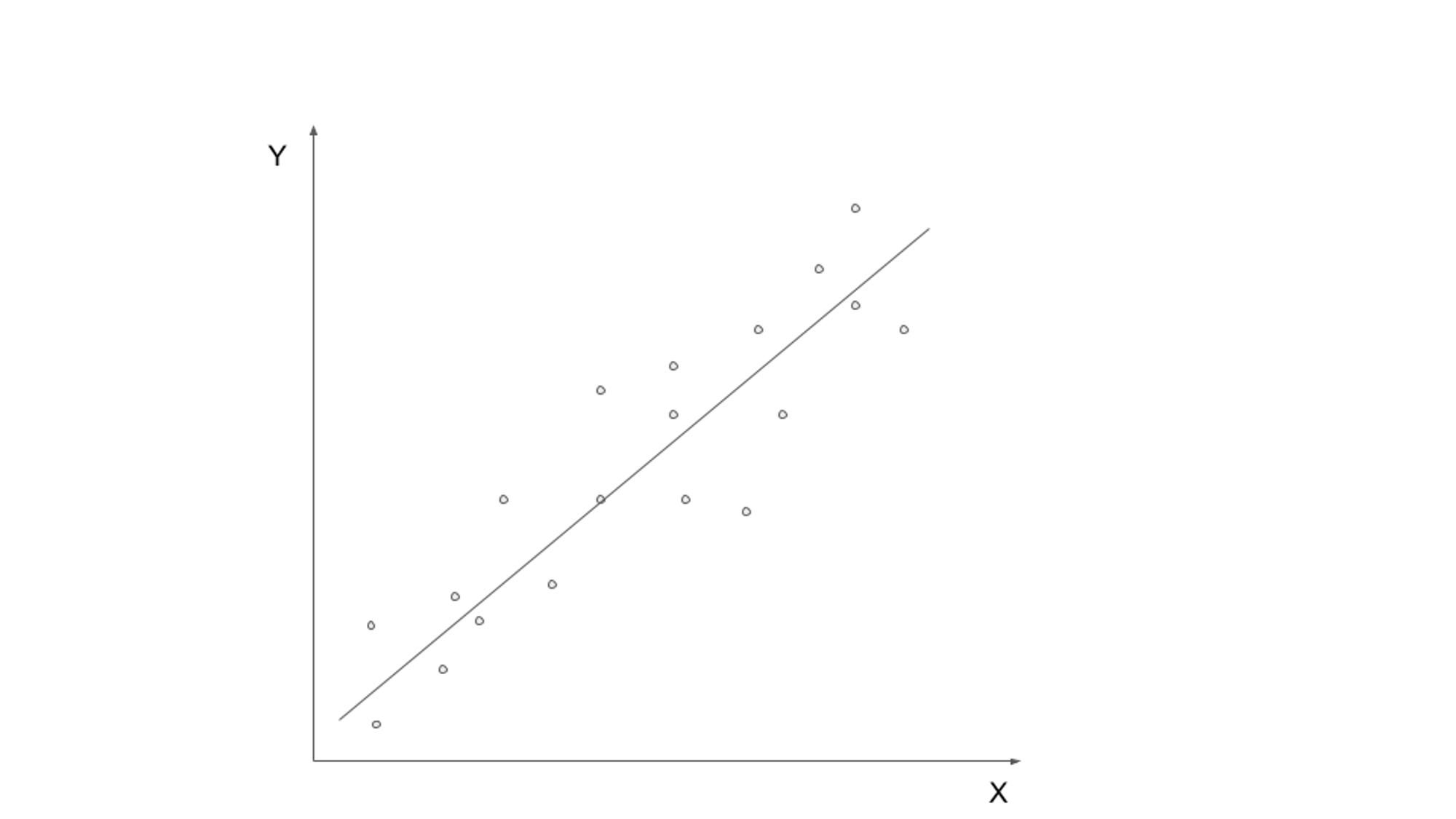
Övervakat lärande innebär att man tränar en modell på märkt data, där indata paras med motsvarande utdata- eller målvariabel. Målet är att lära sig en funktion som kan mappa indata till rätt utgång. Vanliga övervakade inlärningsalgoritmer inkluderar linjär regression, logistisk regression, beslutsträd och stödvektormaskiner.
Exempel på övervakad inlärningskod med Python:
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train, y_train) predictions = model.predict(X_test)
I detta enkla kodexempel tränar vi LinearRegression algoritm från scikit-learn på vår träningsdata och använd den sedan för att få förutsägelser för våra testdata.
Ett praktiskt användningsfall av övervakat lärande är klassificering av e-postspam. Med den exponentiella tillväxten av e-postkommunikation har identifiering och filtrering av skräppost blivit avgörande. Genom att använda övervakade inlärningsalgoritmer är det möjligt att träna en modell för att skilja mellan legitima e-postmeddelanden och spam baserat på märkt data.
Den övervakade inlärningsmodellen kan tränas på en datauppsättning som innehåller e-postmeddelanden märkta som antingen "spam" eller "inte spam." Modellen lär sig mönster och funktioner från märkta data, såsom förekomsten av vissa nyckelord, e-poststruktur eller e-postavsändarinformation. När modellen väl har tränats kan den användas för att automatiskt klassificera inkommande e-postmeddelanden som spam eller icke-spam, och effektivt filtrera oönskade meddelanden.
Oövervakat lärande
Vid oövervakat lärande är ingångsdata omärkta, och målet är att upptäcka mönster eller strukturer i datan. Oövervakade inlärningsalgoritmer syftar till att hitta meningsfulla representationer eller kluster i datan.
Exempel på oövervakade inlärningsalgoritmer inkluderar k- betyder klustring, hierarkisk klustringoch huvudkomponentanalys (PCA).
Exempel på oövervakad inlärningskod:
from sklearn.cluster import KMeans model = KMeans(n_clusters=3) model.fit(X) predictions = model.predict(X_new)
I detta enkla kodexempel tränar vi KMeans algoritm från scikit-learn för att identifiera tre kluster i vår data och sedan passa in ny data i dessa kluster.
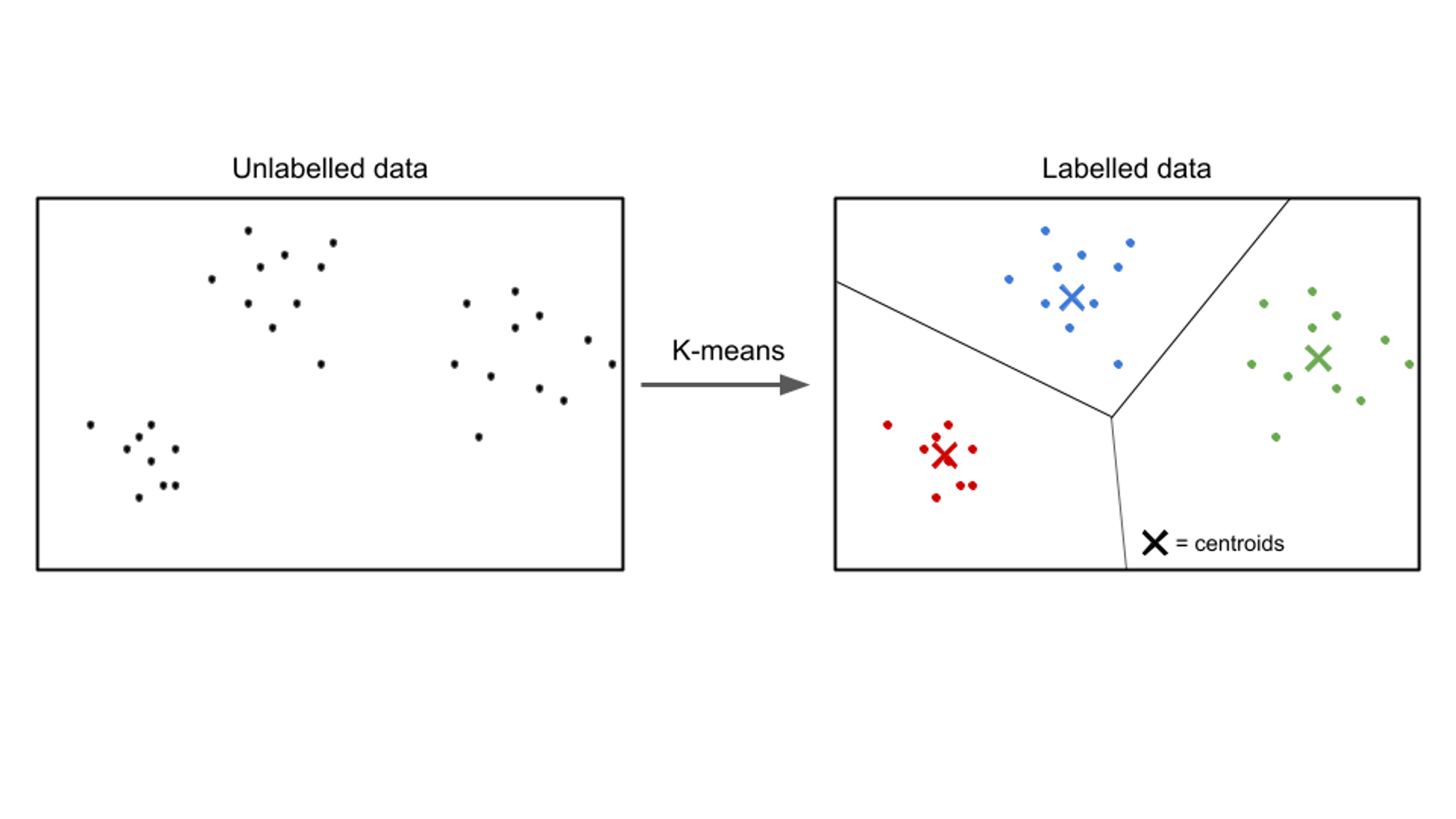
Ett exempel på ett användningsfall för oövervakat lärande är kundsegmentering. I olika branscher strävar företag efter att förstå sin kundbas bättre för att skräddarsy sina marknadsföringsstrategier, anpassa sina erbjudanden och optimera kundupplevelser. Oövervakade inlärningsalgoritmer kan användas för att segmentera kunder i distinkta grupper baserat på deras gemensamma egenskaper och beteenden.
Kolla in vår praktiska, praktiska guide för att lära dig Git, med bästa praxis, branschaccepterade standarder och medföljande fuskblad. Sluta googla Git-kommandon och faktiskt lära Det!
Genom att tillämpa oövervakade inlärningstekniker, såsom klustring, kan företag upptäcka meningsfulla mönster och grupper i sina kunddata. Till exempel kan klustringsalgoritmer identifiera grupper av kunder med liknande köpvanor, demografi eller preferenser. Denna information kan utnyttjas för att skapa riktade marknadsföringskampanjer, optimera produktrekommendationer och förbättra kundnöjdheten.
Huvudalgoritmklasser
Övervakade inlärningsalgoritmer
-
Linjära modeller: Används för att förutsäga kontinuerliga variabler baserat på linjära samband mellan egenskaper och målvariabeln.
-
Trädbaserade modeller: Konstruerade med hjälp av en serie binära beslut för att göra förutsägelser eller klassificeringar.
-
Ensemblemodeller: Metod som kombinerar flera modeller (trädbaserade eller linjära) för att göra mer exakta förutsägelser.
-
Neurala nätverksmodeller: Metoder löst baserade på den mänskliga hjärnan, där flera funktioner fungerar som noder i ett nätverk.
Oövervakade inlärningsalgoritmer
-
Hierarkisk kluster: Bygger en hierarki av kluster genom att iterativt slå samman eller dela upp dem.
-
Icke-hierarkisk kluster: Delar in data i distinkta kluster baserat på likhet.
-
Dimensionalitetsreduktion: Minskar dimensionaliteten hos data samtidigt som den viktigaste informationen bevaras.
Modellutvärdering
Övervakat lärande
För att utvärdera prestandan för övervakade inlärningsmodeller används olika mätetal, inklusive noggrannhet, precision, återkallelse, F1-poäng och ROC-AUC. Korsvalideringstekniker, såsom k-faldig korsvalidering, kan hjälpa till att uppskatta modellens generaliseringsprestanda.
Oövervakat lärande
Att utvärdera oövervakade inlärningsalgoritmer är ofta mer utmanande eftersom det inte finns någon grundsanning. Mätvärden som siluettpoäng eller tröghet kan användas för att bedöma kvaliteten på klustringsresultat. Visualiseringstekniker kan också ge insikter i strukturen av kluster.
Tips och tricks
Övervakat lärande
- Förbearbeta och normalisera indata för att förbättra modellens prestanda.
- Hantera saknade värden på lämpligt sätt, antingen genom imputering eller borttagning.
- Funktionsteknik kan förbättra modellens förmåga att fånga relevanta mönster.
Oövervakat lärande
- Välj lämpligt antal kluster baserat på domänkunskap eller med hjälp av tekniker som armbågsmetoden.
- Överväg olika avståndsmått för att mäta likheten mellan datapunkter.
- Regulera klustringsprocessen för att undvika övermontering.
Sammanfattningsvis involverar maskininlärning många uppgifter, tekniker, algoritmer, metoder för modellutvärdering och användbara tips. Genom att förstå dessa aspekter kan praktiker effektivt tillämpa maskininlärning på verkliga problem och få betydande insikter från data. De givna kodexemplen visar användningen av övervakade och oövervakade inlärningsalgoritmer, och belyser deras praktiska implementering.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- EVM Finans. Unified Interface for Decentralized Finance. Tillgång här.
- Quantum Media Group. IR/PR förstärkt. Tillgång här.
- PlatoAiStream. Web3 Data Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://stackabuse.com/supervised-learning-vs-unsupervised-learning-algorithms/

