Temeljni modeli (FM) so veliki modeli strojnega učenja (ML), usposobljeni na širokem spektru neoznačenih in posplošenih naborov podatkov. FM-ji, kot že ime pove, zagotavljajo osnovo za izdelavo bolj specializiranih nadaljnjih aplikacij in so edinstveni v svoji prilagodljivosti. Opravljajo lahko široko paleto različnih nalog, kot je obdelava naravnega jezika, razvrščanje slik, napovedovanje trendov, analiza čustev in odgovarjanje na vprašanja. Zaradi tega obsega in splošne prilagodljivosti se FM razlikujejo od tradicionalnih modelov ML. FM so multimodalni; delujejo z različnimi tipi podatkov, kot so besedilo, video, zvok in slike. Veliki jezikovni modeli (LLM) so vrsta FM in so vnaprej usposobljeni za velike količine besedilnih podatkov in običajno uporabljajo aplikacije, kot so generiranje besedila, inteligentni klepetalni roboti ali povzemanje.
Pretakanje podatkov omogoča stalen pretok raznolikih in posodobljenih informacij, s čimer se izboljša sposobnost modelov za prilagajanje in ustvarjanje natančnejših, kontekstualno ustreznih rezultatov. Ta dinamična integracija pretočnih podatkov omogoča generativni AI aplikacije, da se hitro odzovejo na spreminjajoče se razmere, izboljšajo svojo prilagodljivost in splošno učinkovitost pri različnih nalogah.
Da bi to bolje razumeli, si predstavljajte chatbota, ki popotnikom pomaga rezervirati potovanje. V tem scenariju klepetalni robot potrebuje dostop v realnem času do inventarja letalskih prevoznikov, statusa leta, hotelskega inventarja, zadnjih sprememb cen in drugega. Ti podatki običajno prihajajo od tretjih oseb in razvijalci morajo najti način, kako te podatke zaužiti in obdelati spremembe podatkov, ko se zgodijo.
Paketna obdelava ni najbolj primerna za ta scenarij. Ko se podatki hitro spreminjajo, lahko obdelava v paketu povzroči uporabo zastarelih podatkov, ki jih uporablja klepetalni robot, kar stranki zagotavlja netočne informacije, kar vpliva na celotno izkušnjo stranke. Pretočna obdelava pa lahko klepetalnemu robotu omogoči dostop do podatkov v realnem času in se prilagaja spremembam razpoložljivosti in cene, kar stranki zagotavlja najboljše smernice in izboljša uporabniško izkušnjo.
Drug primer je rešitev za opazovanje in spremljanje, ki temelji na umetni inteligenci, kjer FM spremljajo interne meritve sistema v realnem času in ustvarjajo opozorila. Ko model najde anomalijo ali nenormalno metrično vrednost, mora nemudoma izdati opozorilo in obvestiti operaterja. Vendar se vrednost tako pomembnih podatkov sčasoma bistveno zmanjša. Idealno bi bilo, da bi ta obvestila prejeli v nekaj sekundah ali celo med dogajanjem. Če operaterji ta obvestila prejmejo nekaj minut ali ur po tem, ko so se zgodila, takega vpogleda ni mogoče ukrepati in je potencialno izgubil svojo vrednost. Podobne primere uporabe lahko najdete v drugih panogah, kot so trgovina na drobno, proizvodnja avtomobilov, energetika in finančna industrija.
V tej objavi razpravljamo o tem, zakaj je pretakanje podatkov ključna komponenta generativnih aplikacij AI zaradi svoje narave v realnem času. Razpravljamo o vrednosti storitev pretakanja podatkov AWS, kot je npr Amazonovo pretakanje za Apache Kafka (Amazon MSK), Amazonski kinezi podatkovni tokovi, Amazonova upravljana storitev za Apache Flinkin Amazon Kinesis Data Firehose pri gradnji generativnih aplikacij AI.
Učenje v kontekstu
LLM se usposabljajo s podatki v trenutku in nimajo lastne zmožnosti dostopa do svežih podatkov v času sklepanja. Ko se pojavijo novi podatki, boste morali model nenehno izpopolnjevati ali dodatno usposabljati. To ni samo draga operacija, ampak tudi zelo omejujoča v praksi, saj hitrost generiranja novih podatkov daleč presega hitrost natančnega prilagajanja. Poleg tega LLM nimajo razumevanja konteksta in se zanašajo izključno na svoje podatke o usposabljanju, zato so nagnjeni h halucinacijam. To pomeni, da lahko ustvarijo tekoč, koherenten in skladenjsko zveneč, a dejansko nepravilen odgovor. Prav tako so brez ustreznosti, personalizacije in konteksta.
LLM pa se lahko učijo iz podatkov, ki jih prejmejo iz konteksta, da se natančneje odzovejo brez spreminjanja uteži modela. To se imenuje učenje v kontekstu, in se lahko uporablja za ustvarjanje prilagojenih odgovorov ali zagotavljanje natančnega odgovora v kontekstu politik organizacije.
Na primer, v klepetalnem robotu se lahko podatkovni dogodki nanašajo na popis letov in hotelov ali spremembe cen, ki se nenehno prenašajo v mehanizem za pretočno shranjevanje. Poleg tega se podatkovni dogodki filtrirajo, obogatijo in pretvorijo v potrošno obliko z uporabo pretočnega procesorja. Rezultat je na voljo aplikaciji s poizvedbo po najnovejšem posnetku. Posnetek se nenehno posodablja z obdelavo toka; zato so posodobljeni podatki zagotovljeni v kontekstu uporabniškega poziva k modelu. To omogoča, da se model prilagodi najnovejšim spremembam cen in razpoložljivosti. Naslednji diagram ponazarja osnovni delovni tok učenja v kontekstu.
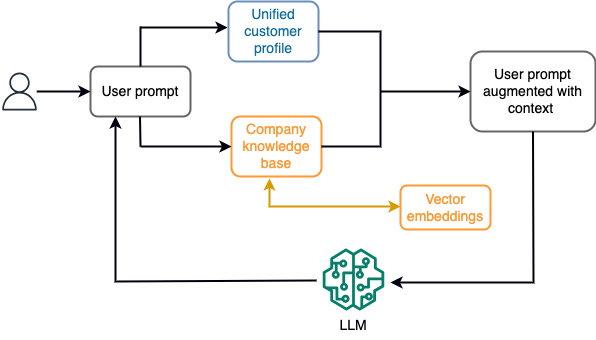
Običajno uporabljen pristop učenja v kontekstu je uporaba tehnike, imenovane Retrieval Augmented Generation (RAG). V RAG na poziv posredujete ustrezne informacije, kot so najpomembnejši pravilniki in evidence strank, skupaj z uporabniškim vprašanjem. Na ta način LLM generira odgovor na uporabniško vprašanje z uporabo dodatnih informacij, navedenih kot kontekst. Če želite izvedeti več o RAG, glejte Odgovarjanje na vprašanja z uporabo Retrieval Augmented Generation z modeli temeljev v Amazon SageMaker JumpStart.
Generativna aplikacija umetne inteligence, ki temelji na RAG, lahko proizvede samo splošne odzive na podlagi svojih podatkov o usposabljanju in ustreznih dokumentov v bazi znanja. Ta rešitev ne deluje, ko se od aplikacije pričakuje prilagojen odziv v skoraj realnem času. Na primer, od potovalnega klepetalnika se pričakuje, da bo upošteval uporabnikove trenutne rezervacije, razpoložljiv inventar hotelov in letov in drugo. Poleg tega so ustrezni osebni podatki stranke (splošno znani kot enoten profil stranke) se običajno spreminja. Če se za posodobitev podatkovne baze uporabniškega profila generativnega umetne inteligence uporabi paketni postopek, lahko stranka prejme nezadovoljive odgovore na podlagi starih podatkov.
V tem prispevku razpravljamo o uporabi obdelave toka za izboljšanje rešitve RAG, ki se uporablja za ustvarjanje agentov za odgovarjanje na vprašanja s kontekstom od dostopa v realnem času do poenotenih profilov strank in organizacijske baze znanja.
Posodobitve profila strank v skoraj realnem času
Zapisi o strankah so običajno porazdeljeni po shrambah podatkov znotraj organizacije. Da bi vaša generativna aplikacija umetne inteligence zagotovila ustrezen, natančen in posodobljen profil stranke, je bistvenega pomena, da zgradite cevovode za pretočne podatke, ki lahko izvajajo razreševanje identitete in združevanje profilov v porazdeljenih shrambah podatkov. Pretočna opravila nenehno zajemajo nove podatke za sinhronizacijo med sistemi in lahko učinkoviteje izvajajo obogatitev, transformacije, združevanja in združevanja v časovnih oknih. Dogodki zajemanja podatkov o spremembi (CDC) vsebujejo informacije o izvornem zapisu, posodobitvah in metapodatki, kot so čas, vir, klasifikacija (vstavljanje, posodobitev ali brisanje) in pobudnik spremembe.
Naslednji diagram prikazuje primer delovnega toka za pretakanje in obdelavo CDC za poenotene profile strank.

V tem razdelku razpravljamo o glavnih komponentah vzorca pretakanja CDC, ki je potreben za podporo generativnih aplikacij AI, ki temeljijo na RAG.
Pretakanje CDC
Replikator CDC je postopek, ki zbira spremembe podatkov iz izvornega sistema (običajno z branjem dnevnikov transakcij ali binlogov) in zapisuje dogodke CDC v popolnoma enakem vrstnem redu, kot so se zgodili v toku pretakanja podatkov ali temi. To vključuje zajemanje na podlagi dnevnika z orodji, kot je npr Storitev za selitev baze podatkov AWS (AWS DMS) ali odprtokodni konektorji, kot je Debezium za povezavo Apache Kafka. Apache Kafka Connect je del okolja Apache Kafka, ki omogoča vnos podatkov iz različnih virov in dostavo na različne destinacije. Svoj konektor Apache Kafka lahko zaženete Amazon MSK Connect v nekaj minutah brez skrbi glede konfiguracije, nastavitve in delovanja gruče Apache Kafka. Naložiti morate samo prevedeno kodo konektorja v Preprosta storitev shranjevanja Amazon (Amazon S3) in nastavite konektor s konfiguracijo, specifično za vašo delovno obremenitev.
Obstajajo tudi druge metode za zajemanje sprememb podatkov. na primer Amazon DynamoDB ponuja funkcijo za pretakanje podatkov CDC Amazon DynamoDB Streams ali Kinesis Data Streams. Amazon S3 ponuja sprožilec za priklic an AWS Lambda funkcijo, ko je shranjen nov dokument.
Shramba za pretakanje
Pretočno shranjevanje deluje kot vmesni medpomnilnik za shranjevanje dogodkov CDC, preden se obdelajo. Shramba za pretakanje zagotavlja zanesljivo shrambo za pretakanje podatkov. Po zasnovi je zelo razpoložljiv in odporen na napake strojne opreme ali vozlišč ter ohranja vrstni red dogodkov, kot so zapisani. Pretočni pomnilnik lahko shranjuje podatkovne dogodke trajno ali za določeno časovno obdobje. To omogoča pretočnim procesorjem, da berejo del toka, če pride do okvare ali potrebe po ponovni obdelavi. Kinesis Data Streams je storitev pretakanja podatkov brez strežnika, ki omogoča preprosto zajemanje, obdelavo in shranjevanje podatkovnih tokov v velikem obsegu. Amazon MSK je popolnoma upravljana, visoko razpoložljiva in varna storitev, ki jo zagotavlja AWS za izvajanje Apache Kafka.
Pretočna obdelava
Sistemi za obdelavo tokov bi morali biti zasnovani za paralelizem za obvladovanje visoke prepustnosti podatkov. Vhodni tok morajo razdeliti med več nalog, ki se izvajajo na več računalniških vozliščih. Naloge morajo imeti možnost pošiljanja rezultatov ene operacije naslednji preko omrežja, kar omogoča vzporedno obdelavo podatkov med izvajanjem operacij, kot so združevanja, filtriranje, obogatitev in združevanje. Aplikacije za obdelavo tokov bi morale imeti možnost obdelave dogodkov glede na čas dogodka za primere uporabe, kjer bi lahko dogodki prispeli z zamudo ali pravilni izračun temelji na času nastanka dogodkov in ne na sistemskem času. Za več informacij glejte Pojmi časa: čas dogodka in čas obdelave.
Pretočni procesi nenehno ustvarjajo rezultate v obliki podatkovnih dogodkov, ki jih je treba poslati v ciljni sistem. Ciljni sistem je lahko kateri koli sistem, ki se lahko integrira neposredno s procesom ali prek pretočnega pomnilnika kot pri posredniku. Odvisno od ogrodja, ki ga izberete za obdelavo toka, boste imeli različne možnosti za ciljne sisteme glede na razpoložljive priključke ponora. Če se odločite za zapisovanje rezultatov v vmesno pretočno shrambo, lahko zgradite ločen proces, ki bere dogodke in uveljavlja spremembe v ciljnem sistemu, kot je zagon ponornega priključka Apache Kafka. Ne glede na to, katero možnost izberete, podatki CDC zaradi svoje narave potrebujejo dodatno obravnavo. Ker dogodki CDC prenašajo informacije o posodobitvah ali izbrisih, je pomembno, da se združijo v ciljnem sistemu v pravilnem vrstnem redu. Če so spremembe uporabljene v napačnem vrstnem redu, ciljni sistem ne bo sinhroniziran z izvorom.
Apache Flash je zmogljivo ogrodje za obdelavo toka, znano po nizki zakasnitvi in visoki prepustnosti. Podpira časovno obdelavo dogodkov, semantiko obdelave točno enkrat in visoko odpornost na napake. Poleg tega zagotavlja izvorno podporo za podatke CDC prek posebne strukture, imenovane dinamične mize. Dinamične tabele posnemajo tabele izvorne baze podatkov in zagotavljajo stolpčno predstavitev pretočnih podatkov. Podatki v dinamičnih tabelah se spreminjajo z vsakim obdelanim dogodkom. Nove zapise je mogoče kadar koli dodati, posodobiti ali izbrisati. Dinamične tabele abstrahirajo dodatno logiko, ki jo morate implementirati za vsako operacijo zapisa (vstavljanje, posodobitev, brisanje) posebej. Za več informacij glejte Dinamične tabele.
z Amazonova upravljana storitev za Apache Flink, lahko izvajate opravila Apache Flink in se integrirate z drugimi storitvami AWS. Ni strežnikov in gruč, ki bi jih bilo treba upravljati, in ni računalniške in pomnilniške infrastrukture, ki bi jo bilo treba nastaviti.
AWS lepilo je popolnoma upravljana storitev ekstrahiranja, preoblikovanja in nalaganja (ETL), kar pomeni, da AWS namesto vas skrbi za zagotavljanje infrastrukture, skaliranje in vzdrževanje. Čeprav je znan predvsem po svojih zmožnostih ETL, je AWS Glue mogoče uporabiti tudi za pretočne aplikacije Spark. AWS Glue lahko komunicira s pretočnimi podatkovnimi storitvami, kot sta Kinesis Data Streams in Amazon MSK za obdelavo in pretvorbo podatkov CDC. AWS Glue se lahko brezhibno integrira tudi z drugimi storitvami AWS, kot so Lambda, Korak funkcije AWS, in DynamoDB, ki vam zagotavlja celovit ekosistem za gradnjo in upravljanje cevovodov za obdelavo podatkov.
Enoten profil stranke
Premagovanje poenotenja profila stranke v različnih izvornih sistemih zahteva razvoj robustnih podatkovnih cevovodov. Potrebujete podatkovne cevovode, ki lahko prenesejo in sinhronizirajo vse zapise v eno shrambo podatkov. Ta shramba podatkov zagotavlja vaši organizaciji celovit pogled na evidence strank, ki je potreben za operativno učinkovitost generativnih aplikacij AI, ki temeljijo na RAG. Za izgradnjo takega podatkovnega shrambe bi bila najboljša nestrukturirana podatkovna shramba.
Identitetni graf je uporabna struktura za ustvarjanje poenotenega profila stranke, ker konsolidira in integrira podatke o strankah iz različnih virov, zagotavlja točnost podatkov in deduplikacijo, ponuja posodobitve v realnem času, povezuje medsistemske vpoglede, omogoča personalizacijo, izboljšuje uporabniško izkušnjo in podpira skladnost s predpisi. Ta poenoten profil stranke omogoča generativni aplikaciji umetne inteligence, da razume in učinkovito sodeluje s strankami ter spoštuje predpise o zasebnosti podatkov, kar na koncu izboljša uporabniško izkušnjo in spodbudi rast poslovanja. Svojo rešitev grafa identitete lahko zgradite z uporabo Amazonski Neptun, hitra, zanesljiva, popolnoma upravljana storitev zbirke podatkov grafov.
AWS ponuja nekaj drugih upravljanih in brezstrežniških ponudb storitev shranjevanja NoSQL za nestrukturirane objekte ključ-vrednost. Amazonski dokumentDB (z združljivostjo z MongoDB) je hitro, razširljivo, zelo razpoložljivo in popolnoma upravljano podjetje baza dokumentov storitev, ki podpira izvorne delovne obremenitve JSON. DynamoDB je popolnoma upravljana storitev baze podatkov NoSQL, ki zagotavlja hitro in predvidljivo delovanje z brezhibno razširljivostjo.
Posodobitve organizacijske baze znanja v skoraj realnem času
Podobno kot pri zapisih o strankah so interni repozitoriji znanja, kot so politike podjetja in organizacijski dokumenti, ločeni v sistemih za shranjevanje. To so običajno nestrukturirani podatki, ki se posodabljajo neinkrementalno. Uporaba nestrukturiranih podatkov za aplikacije umetne inteligence je učinkovita z uporabo vektorskih vdelav, ki so tehnika predstavljanja visokodimenzionalnih podatkov, kot so besedilne datoteke, slike in zvočne datoteke, kot večdimenzionalne numerične.
AWS ponuja več storitve vektorskih motorjev, Kot je Amazon OpenSearch brez strežnika, Amazonska Kendrain Izdaja Amazon Aurora, združljiva s PostgreSQL z razširitvijo pgvector za shranjevanje vdelanih vektorjev. Generativne aplikacije umetne inteligence lahko izboljšajo uporabniško izkušnjo tako, da preoblikujejo uporabniški poziv v vektor in ga uporabijo za poizvedovanje vektorskega mehanizma za pridobivanje kontekstualno pomembnih informacij. Tako poziv kot pridobljeni vektorski podatki se nato posredujejo LLM, da prejme natančnejši in prilagojen odgovor.
Naslednji diagram ponazarja primer poteka dela za obdelavo toka za vdelave vektorjev.
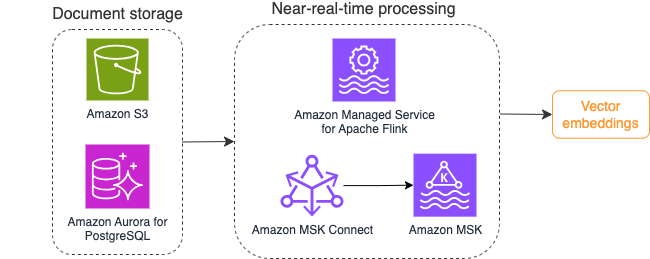
Vsebino baze znanja je treba pretvoriti v vektorske vdelave, preden se zapiše v shrambo vektorskih podatkov. Amazon Bedrock or Amazon SageMaker vam lahko pomaga dostopati do modela po vaši izbiri in izpostaviti zasebno končno točko za to pretvorbo. Poleg tega lahko za integracijo s temi končnimi točkami uporabite knjižnice, kot je LangChain. Izdelava paketnega procesa vam lahko pomaga pretvoriti vsebino vaše baze znanja v vektorske podatke in jo na začetku shraniti v vektorsko bazo podatkov. Vendar se morate zanašati na interval za ponovno obdelavo dokumentov, da sinhronizirate svojo vektorsko bazo podatkov s spremembami vsebine vaše baze znanja. Pri velikem številu dokumentov je ta postopek lahko neučinkovit. Med temi intervali bodo vaši generativni uporabniki aplikacije AI prejeli odgovore glede na staro vsebino ali pa prejeli netočen odgovor, ker nova vsebina še ni vektorizirana.
Pretočna obdelava je idealna rešitev za te izzive. Na začetku ustvari dogodke glede na obstoječe dokumente in nadalje spremlja izvorni sistem ter ustvari dogodek spremembe dokumenta takoj, ko se zgodijo. Te dogodke je mogoče shraniti v shrambo za pretakanje in počakati, da jih obdela pretočno opravilo. Pretočno opravilo prebere te dogodke, naloži vsebino dokumenta in pretvori vsebino v niz povezanih besednih žetonov. Vsak žeton se nadalje pretvori v vektorske podatke prek klica API-ja v FM za vdelavo. Rezultati se pošljejo v shranjevanje v vektorsko shrambo prek operaterja ponora.
Če uporabljate Amazon S3 za shranjevanje svojih dokumentov, lahko zgradite arhitekturo vira dogodkov, ki temelji na sprožilcih za spremembo objekta S3 za Lambda. Funkcija Lambda lahko ustvari dogodek v želeni obliki in ga zapiše v vašo shrambo za pretakanje.
Apache Flink lahko uporabite tudi za izvajanje kot pretočno opravilo. Apache Flink zagotavlja izvorni konektor FileSystem, ki lahko odkrije obstoječe datoteke in na začetku prebere njihovo vsebino. Po tem lahko nenehno spremlja vaš datotečni sistem glede novih datotek in zajema njihovo vsebino. Konektor podpira branje nabora datotek iz porazdeljenih datotečnih sistemov, kot sta Amazon S3 ali HDFS s formatom navadnega besedila, Avro, CSV, Parquet itd., in ustvari pretočni zapis. Kot popolnoma upravljana storitev Managed Service for Apache Flink odpravlja operativne stroške uvajanja in vzdrževanja opravil Flink, kar vam omogoča, da se osredotočite na gradnjo in prilagajanje svojih pretočnih aplikacij. Z brezhibno integracijo v pretočne storitve AWS, kot sta Amazon MSK ali Kinesis Data Streams, zagotavlja funkcije, kot so samodejno skaliranje, varnost in odpornost, ter zagotavlja zanesljive in učinkovite aplikacije Flink za obdelavo pretočnih podatkov v realnem času.
Glede na vaše nastavitve DevOps lahko izbirate med Kinesis Data Streams ali Amazon MSK za shranjevanje zapisov pretakanja. Kinesis Data Streams poenostavlja zapletenost gradnje in upravljanja aplikacij za pretakanje podatkov po meri, kar vam omogoča, da se osredotočite na pridobivanje vpogledov iz svojih podatkov in ne na vzdrževanje infrastrukture. Stranke, ki uporabljajo Apache Kafka, se pogosto odločijo za Amazon MSK zaradi njegove preprostosti, razširljivosti in zanesljivosti pri nadzoru gruč Apache Kafka v okolju AWS. Kot popolnoma upravljana storitev Amazon MSK prevzema operativne zapletenosti, povezane z uvajanjem in vzdrževanjem gruč Apache Kafka, kar vam omogoča, da se osredotočite na gradnjo in razširitev svojih pretočnih aplikacij.
Ker integracija API-ja RESTful ustreza naravi tega procesa, potrebujete ogrodje, ki podpira vzorec obogatitve s stanjem prek klicev API-ja RESTful za sledenje napakam in ponovni poskus za neuspešno zahtevo. Apache Flink je spet ogrodje, ki lahko izvaja operacije s stanjem s hitrostjo v pomnilniku. Če želite razumeti najboljše načine za klice API prek Apache Flink, glejte Pogosti vzorci obogatitve pretočnih podatkov v Amazon Kinesis Data Analytics za Apache Flink.
Apache Flink ponuja izvorne priključke ponora za pisanje podatkov v vektorske podatkovne shrambe, kot je Amazon Aurora za PostgreSQL s pgvector ali Storitev Amazon OpenSearch z VectorDB. Druga možnost je, da izhod opravila Flink (vektorizirani podatki) uprizorite v temi MSK ali podatkovnem toku Kinesis. Storitev OpenSearch nudi podporo za izvorno vnos iz podatkovnih tokov Kinesis ali tem MSK. Za več informacij glejte Predstavljamo Amazon MSK kot vir za Amazon OpenSearch Ingestion in Nalaganje pretočnih podatkov iz Amazon Kinesis Data Streams.
Analitika povratnih informacij in fina nastavitev
Za upravljavce podatkovnih operacij in razvijalce AI/ML je pomembno, da dobijo vpogled v delovanje generativne aplikacije AI in FM, ki se uporabljajo. Da bi to dosegli, morate zgraditi podatkovne kanale, ki izračunajo pomembne podatke o ključnem kazalniku uspešnosti (KPI) na podlagi povratnih informacij uporabnikov ter različnih dnevnikov in meritev aplikacij. Te informacije so koristne za zainteresirane strani, da pridobijo vpogled v realnem času o delovanju FM, aplikacije in splošnega zadovoljstva uporabnikov glede kakovosti podpore, ki jo prejmejo od vaše aplikacije. Prav tako morate zbrati in shraniti zgodovino pogovorov za nadaljnjo natančno nastavitev vaših FM-jev, da bi izboljšali njihovo sposobnost izvajanja nalog, specifičnih za domeno.
Ta primer uporabe se zelo dobro ujema z domeno analitike pretakanja. Vaša aplikacija mora shraniti vsak pogovor v shrambo za pretakanje. Vaša aplikacija lahko uporabnike pozove glede njihove ocene točnosti vsakega odgovora in njihovega splošnega zadovoljstva. Ti podatki so lahko v obliki binarne izbire ali besedila v prosti obliki. Te podatke je mogoče shraniti v tok podatkov Kinesis ali temo MSK in jih obdelati za ustvarjanje KPI-jev v realnem času. FM lahko vključite v analizo razpoloženja uporabnikov. FM lahko analizira vsak odgovor in dodeli kategorijo zadovoljstva uporabnikov.
Arhitektura Apache Flink omogoča kompleksno združevanje podatkov v časovnih oknih. Zagotavlja tudi podporo za poizvedovanje SQL prek toka podatkovnih dogodkov. Zato lahko z uporabo Apache Flink hitro analizirate neobdelane uporabniške vnose in ustvarite KPI v realnem času s pisanjem znanih poizvedb SQL. Za več informacij glejte Tabela API in SQL.
z Amazonova upravljana storitev za Apache Flink Studio, lahko zgradite in zaženete aplikacije za obdelavo toka Apache Flink z uporabo standardnih SQL, Python in Scala v interaktivnem zvezku. Prenosne računalnike Studio poganja Apache Zeppelin in uporabljajo Apache Flink kot mehanizem za obdelavo toka. Prenosni računalniki Studio brezhibno združujejo te tehnologije, da omogočijo napredno analitiko podatkovnih tokov dostopno razvijalcem vseh veščin. S podporo za uporabniško določene funkcije (UDF) Apache Flink omogoča izdelavo operaterjev po meri za integracijo z zunanjimi viri, kot so FM, za izvajanje zapletenih nalog, kot je analiza razpoloženja. UDF-je lahko uporabite za izračun različnih meritev ali neobdelane povratne informacije uporabnikov z dodatnimi vpogledi, kot je mnenje uporabnikov. Če želite izvedeti več o tem vzorcu, glejte Proaktivno obravnavanje skrbi strank v realnem času z GenAI, Flink, Apache Kafka in Kinesis.
Z upravljano storitvijo za Apache Flink Studio lahko z enim klikom uvedete prenosni računalnik Studio kot pretočno opravilo. Uporabite lahko izvorne priključke ponora, ki jih ponuja Apache Flink, da pošljete izhod v vašo izbrano shrambo ali ga postavite v podatkovni tok Kinesis ali temo MSK. Amazon RedShift in OpenSearch Service sta idealna za shranjevanje analitičnih podatkov. Oba mehanizma zagotavljata izvorno podporo za vnos iz Kinesis Data Streams in Amazon MSK prek ločenega cevovoda za pretakanje v podatkovno jezero ali skladišče podatkov za analizo.
Amazon Redshift uporablja SQL za analizo strukturiranih in polstrukturiranih podatkov v podatkovnih skladiščih in podatkovnih jezerih, pri čemer uporablja strojno opremo, ki jo je zasnoval AWS, in strojno učenje za zagotavljanje najboljše cene in zmogljivosti v velikem obsegu. Storitev OpenSearch ponuja zmožnosti vizualizacije, ki jih poganjajo nadzorne plošče OpenSearch in Kibana (različice od 1.5 do 7.10).
Rezultat takšne analize lahko uporabite v kombinaciji s podatki o pozivu uporabnika za natančno nastavitev FM, ko je to potrebno. SageMaker je najpreprostejši način za natančno nastavitev FM-jev. Uporaba Amazon S3 s SageMaker zagotavlja zmogljivo in brezhibno integracijo za natančno nastavitev vaših modelov. Amazon S3 služi kot razširljiva in trajna rešitev za shranjevanje predmetov, ki omogoča preprosto shranjevanje in pridobivanje velikih naborov podatkov, podatkov o usposabljanju in artefaktov modela. SageMaker je popolnoma upravljana storitev ML, ki poenostavi celoten življenjski cikel ML. Če uporabljate Amazon S3 kot zaledje za shranjevanje za SageMaker, lahko izkoristite razširljivost, zanesljivost in stroškovno učinkovitost Amazon S3, hkrati pa ga brezhibno integrirate z zmogljivostmi usposabljanja in uvajanja SageMaker. Ta kombinacija omogoča učinkovito upravljanje podatkov, olajša razvoj skupnega modela in zagotavlja, da so delovni tokovi ML poenostavljeni in razširljivi, kar na koncu izboljša splošno agilnost in učinkovitost procesa ML. Za več informacij glejte Natančno nastavite Falcon 7B in druge LLM na Amazon SageMaker z @remote dekoratorjem.
S priključkom ponora datotečnega sistema lahko opravila Apache Flink dostavijo podatke v Amazon S3 v datotekah odprtega formata (kot so JSON, Avro, Parquet in druge) kot podatkovne objekte. Če raje upravljate svoje podatkovno jezero z uporabo ogrodja transakcijskega podatkovnega jezera (kot je Apache Hudi, Apache Iceberg ali Delta Lake), vsa ta ogrodja zagotavljajo priključek po meri za Apache Flink. Za več podrobnosti glejte Z Amazon MSK Connect, Apache Flink in Apache Hudi ustvarite cevovod od vira do podatkov z nizko zakasnitvijo..
Povzetek
Za generativno aplikacijo AI, ki temelji na modelu RAG, morate razmisliti o izgradnji dveh sistemov za shranjevanje podatkov in zgraditi morate podatkovne operacije, ki jih posodabljajo z vsemi izvornimi sistemi. Tradicionalna paketna opravila ne zadostujejo za obdelavo velikosti in raznolikosti podatkov, ki jih potrebujete za integracijo z vašo generativno aplikacijo AI. Zamude pri obdelavi sprememb v izvornih sistemih povzročijo netočen odziv in zmanjšajo učinkovitost vaše generativne aplikacije AI. Pretakanje podatkov vam omogoča vnos podatkov iz različnih baz podatkov v različnih sistemih. Omogoča tudi učinkovito preoblikovanje, obogatitev, združevanje in združevanje podatkov iz številnih virov v skoraj realnem času. Pretakanje podatkov zagotavlja poenostavljeno podatkovno arhitekturo za zbiranje in preoblikovanje odzivov ali komentarjev uporabnikov v realnem času na odzive aplikacije, kar vam pomaga dostaviti in shraniti rezultate v podatkovno jezero za natančno nastavitev modela. Pretakanje podatkov vam prav tako pomaga optimizirati podatkovne cevovode z obdelavo samo dogodkov sprememb, kar vam omogoča hitrejši in učinkovitejši odziv na spremembe podatkov.
Več o tem Storitve pretakanja podatkov AWS in začnite graditi lastno rešitev za pretakanje podatkov.
O avtorjih
 Ali Alemi je strokovnjak za pretočne rešitve pri AWS. Ali strankam AWS svetuje glede najboljših arhitekturnih praks in jim pomaga oblikovati analitične podatkovne sisteme v realnem času, ki so zanesljivi, varni, učinkoviti in stroškovno učinkoviti. Deluje nazaj od strankinih primerov uporabe in oblikuje podatkovne rešitve za reševanje njihovih poslovnih težav. Preden se je pridružil AWS, je Ali podpiral številne stranke iz javnega sektorja in svetovalne partnerje AWS pri njihovi posodobitvi aplikacij in migraciji v oblak.
Ali Alemi je strokovnjak za pretočne rešitve pri AWS. Ali strankam AWS svetuje glede najboljših arhitekturnih praks in jim pomaga oblikovati analitične podatkovne sisteme v realnem času, ki so zanesljivi, varni, učinkoviti in stroškovno učinkoviti. Deluje nazaj od strankinih primerov uporabe in oblikuje podatkovne rešitve za reševanje njihovih poslovnih težav. Preden se je pridružil AWS, je Ali podpiral številne stranke iz javnega sektorja in svetovalne partnerje AWS pri njihovi posodobitvi aplikacij in migraciji v oblak.
 Imtiaz (Taz) Sayed je svetovni tehnični vodja za analitiko pri AWS. Uživa v sodelovanju s skupnostjo glede podatkov in analitike. Dosežen je prek LinkedIn.
Imtiaz (Taz) Sayed je svetovni tehnični vodja za analitiko pri AWS. Uživa v sodelovanju s skupnostjo glede podatkov in analitike. Dosežen je prek LinkedIn.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

