
Sliko ustvaril avtor z Midjourney
MetaGPT je multi-agentski okvir za dodeljevanje vlog različnim agentom, kar vodi do oblikovanja sodelujočih subjektov, ki lahko delujejo v tandemu in izvajajo zapletena navodila. MetaGPT se predstavlja kot »programsko podjetje kot sistem z več agenti«, kar vam daje predstavo o predvideni uporabi teh sodelovalnih entitet. MetaGPT se lahko uporablja kot samostojna aplikacija iz ukazne vrstice in kot knjižnica v vaših lastnih skriptih Python, kar omogoča prilagodljivost in nadzor, ki bi si ga želeli v takšnem okviru.
Projekt se je začel aprila 2023 z uporabo ChatGPT in je imel v času pisanja tega članka skoraj 40 zvezdic na GitHubu. Njegov repo GitHub se nadalje opisuje na naslednji način:
MetaGPT sprejme zahtevo po eni vrstici kot vhod in izhode uporabniških zgodb / konkurenčnih analiz / zahtev / podatkovnih struktur / API-jev / dokumentov itd.
Interno MetaGPT vključuje vodje izdelkov / arhitekte / vodje projektov / inženirje. Zagotavlja celoten proces podjetja za programsko opremo skupaj s skrbno orkestriranimi SOP.
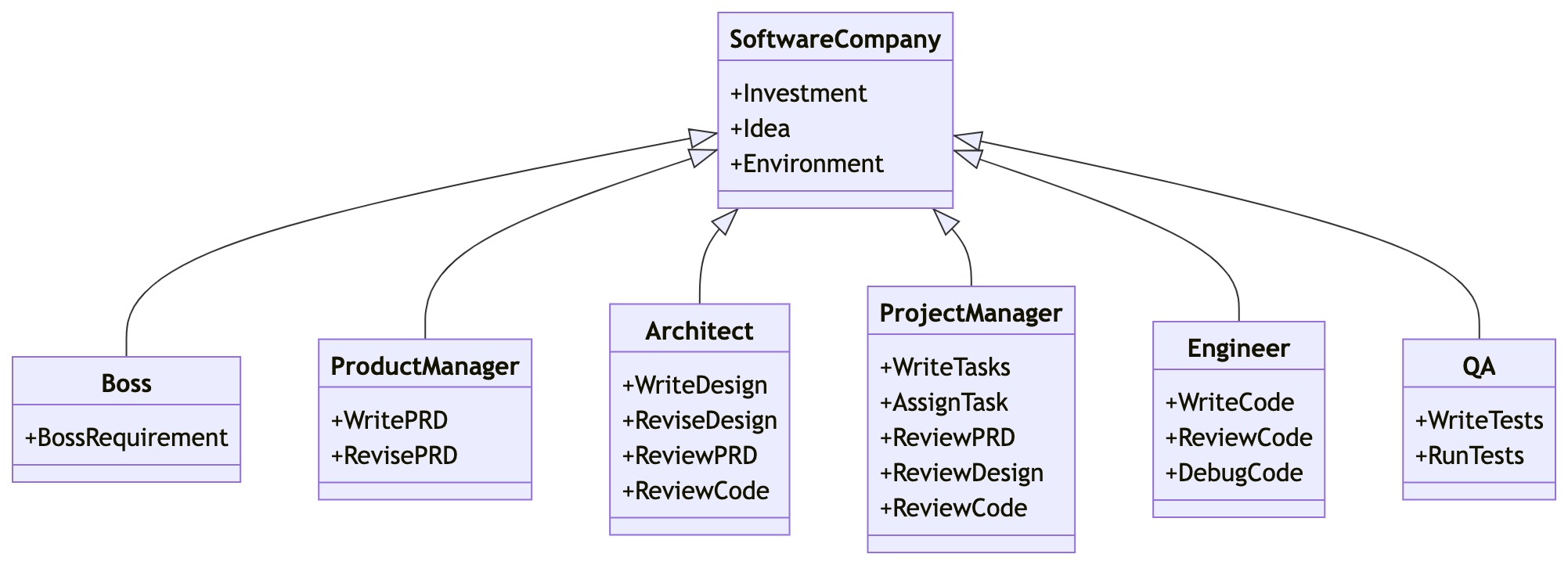
Večagentna shema podjetja MetaGPT Software Company (postopno uvajanje) (od MetaGPT's GitHub)
MetaGPT se lahko uporablja za ustvarjanje kode, izdelavo prototipov, načrtovanje projektov in več. Priznan je bil kot a izjemen odprtokodni dosežek, in je vedno v trendu GitHub repo.
To je MetaGPT. Zdaj pa se pogovorimo Tolmač podatkov, Globoka modrostNajnovejša izboljšava MetaGPT in dosežek sam po sebi.
Celoten videoposnetek za predstavitev tolmača podatkov MetaGPT
Predstavitev, kako obravnavati izzive napovedovanja obremenitve električne energije z dinamičnim načrtovanjem, uporabo orodij, izboljšanim razmišljanjem in preverjanjem na podlagi izkušenj.
Repo: https://t.co/xWGS0UF9oW
Primeri: https://t.co/GhNH54Ahhi... pic.twitter.com/Xc5aam1TXz— MetaGPT (@MetaGPT_) Marec 19, 2024
Data Interpreter je še en posrednik član ogrodja MetaGPT, agent, namenjen ocenjevanju in reševanju nalog, povezanih s podatki. Iz papirja:
V tej študiji predstavljamo Data Interpreter, rešitev, zasnovano za reševanje s kodo, ki poudarja tri ključne tehnike za izboljšanje reševanja problemov v podatkovni znanosti: 1) dinamično načrtovanje s hierarhičnimi strukturami grafov za prilagodljivost podatkov v realnem času; 2) dinamična integracija orodja za izboljšanje znanja kode med izvajanjem, obogatitev potrebnega strokovnega znanja; 3) prepoznavanje logičnih nedoslednosti v povratnih informacijah in izboljšanje učinkovitosti z beleženjem izkušenj. […] V primerjavi z odprtokodnimi izhodišči je pokazal vrhunsko zmogljivost, saj je pokazal znatne izboljšave pri nalogah strojnega učenja, in sicer z 0.86 na 0.95. Poleg tega je pokazal 26-odstotno povečanje nabora podatkov MATH in izjemno 112-odstotno izboljšanje odprtih nalog.
Te ugotovitve so vsekakor impresivne. In ni jih treba jemati po nominalni vrednosti, saj so te rezultate objavili. Deep Wisdom je dal na voljo tudi a obilica primerov da pokažejo, kako je mogoče njihov agent Data Interpreter uporabiti v povezavi z obstoječim ogrodjem MetaGPT.
Ta primer tukaj prikazuje, kako ga je mogoče uporabiti za analizo trendov delnic NVIDIA. Če želite videti, kako izgleda poziv tolmača podatkov MetaGPT, ga bom podvojil spodaj:
Pridobite podatke o cenah delnic NVIDIA Corporation (NVDA) od Yahoo Finance, s poudarkom na zgodovinskih zaključnih cenah iz zadnjih 5 let. Sumarna statistika (povprečje, mediana, standardni odklon itd.) za razumevanje osrednje težnje in razpršenosti zaključnih cen. Analizirajte podatke glede kakršnih koli opaznih trendov, vzorcev ali anomalij skozi čas, po možnosti z uporabo drsečih povprečij ali odstotnih sprememb. Ustvarite graf za vizualizacijo vse analize podatkov. Rezervirajte 20 % nabora podatkov za validacijo. Urite napovedni model na učnem nizu. Poročite o natančnosti validacije modela in vizualizirajte rezultat rezultata napovedi. blizu
Ogledate si lahko primer zvezka (z zgornjo povezavo), da sledite postopku MetaGPT in si ogledate rezultate. Opozorilo o spojlerju: Deep Wisdom jih ne deli z drugimi, ker niso impresivni 🙂
Preberi celoten papir za vse informacije, ki jih lahko zahtevate. Več o namestitvi in uporabi lahko izveste na projektu GitHub repo. Iz izkušenj lahko potrdim, da je MetaGPT vreden projekta, ki ga je vredno preveriti, in z dodatkom agenta Data Interpreter je to še bolj res, kot je bilo prej.
Matthew Mayo (@mattmayo13) ima magisterij iz računalništva in diplomo iz podatkovnega rudarjenja. Matthew si kot glavni urednik KDnuggets prizadeva narediti dostopne zapletene koncepte podatkovne znanosti. Njegovi poklicni interesi vključujejo obdelavo naravnega jezika, algoritme strojnega učenja in raziskovanje nastajajoče umetne inteligence. Vodi ga misija demokratizacije znanja v skupnosti podatkovne znanosti. Matthew kodira od svojega 6. leta.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/metagpt-data-interpreter-open-source-llm-based-data-solutions?utm_source=rss&utm_medium=rss&utm_campaign=introducing-metagpts-data-interpreter-sota-open-source-llm-based-data-solutions

