Организации внедряют Apache Kafka и Amazon Managed Streaming для Apache Kafka (Amazon MSK) для сбора и анализа данных в режиме реального времени. Amazon MSK позволяет создавать и запускать производственные приложения на Apache Kafka, не обладая знаниями в области управления инфраструктурой Kafka или самостоятельно сталкиваясь со сложными накладными расходами, связанными с запуском Apache Kafka. По мере роста зрелости клиенты стремятся создавать сложные варианты использования, сочетающие аспекты реального времени и пакетной обработки. Например, вы можете захотеть обучить модели машинного обучения (ML) на основе исторических данных, а затем использовать эти модели для вывода в реальном времени. Или вы можете захотеть иметь возможность пересчитать предыдущие результаты, когда логика приложения изменилась, например, когда в приложение потоковой аналитики был добавлен новый KPI или когда была исправлена ошибка, вызывавшая неверный вывод. Эти варианты использования часто требуют хранения данных в течение нескольких недель, месяцев или даже лет.
Apache Kafka имеет хорошие возможности для поддержки таких вариантов использования. Данные хранятся в кластере Kafka столько времени, сколько требуется путем настройки политики хранения. Таким образом, самые последние данные могут обрабатываться в режиме реального времени для вариантов использования с малой задержкой, в то время как исторические данные остаются доступными в кластере и могут обрабатываться в пакетном режиме.
Однако хранение данных в кластере Kafka может стать дорогостоящим, поскольку хранилище и вычислительные ресурсы тесно связаны в кластере. Чтобы масштабировать хранилище, вам нужно добавить больше брокеров. Но добавление большего количества брокеров с единственной целью увеличения объема хранилища приводит к растрате остальных вычислительных ресурсов, таких как ЦП и память. Кроме того, большой кластер с большим количеством узлов усложняет работу, так как требуется больше времени для восстановления и повторной балансировки в случае сбоя брокера. Чтобы избежать этой операционной сложности и более высоких затрат, вы можете переместить свои данные в Простой сервис хранения Amazon (Amazon S3) для долгосрочного доступа, а экономичные классы хранения в Amazon S3 позволяют оптимизировать общую стоимость хранения. Это решает проблемы с затратами, но теперь вам нужно создавать и поддерживать эту часть архитектуры для перемещения данных в другое хранилище данных. Вам также необходимо создать другую логику обработки данных, используя разные API для потребления данных (API Kafka для потоковой передачи, API Amazon S3 для чтения исторических данных).
Сегодня мы анонсируем многоуровневое хранилище Amazon MSK, которое предоставляет практически неограниченный и недорогой уровень хранения для Amazon MSK, упрощая и удешевляя создание приложений для потоковой передачи данных для разработчиков. С момента запуска Amazon MSK в 2019 году мы включили такие возможности, как вертикальное масштабирование и автоматическое масштабирование хранилища брокера чтобы вы могли экономично управлять рабочими нагрузками Kafka. Ранее в этом году мы запустили выделенная пропускная способность что позволяет плавно масштабировать ввод-вывод без необходимости предоставления дополнительных брокеров. Многоуровневое хранилище делает запуск рабочих нагрузок Kafka еще более экономичным. Теперь вы можете хранить данные в Apache Kafka, не беспокоясь об ограничениях. Вы можете эффективно сбалансировать производительность и затраты, используя оптимизированную для производительности первичное хранилище для данных в реальном времени и новый недорогой уровень для исторических данных. С помощью нескольких щелчков мыши вы можете переместить потоковые данные на более дешевый уровень, чтобы хранить данные и платить только за то, что вы используете.
Многоуровневое хранилище избавляет вас от необходимости искать компромисс между поддержкой требований к хранению данных для ваших групп приложений и связанной с этим сложностью эксплуатации. Это позволяет использовать один и тот же код для обработки как данных в реальном времени, так и исторических данных, чтобы свести к минимуму избыточные рабочие процессы и упростить архитектуру. Благодаря многоуровневому хранилищу Amazon MSK вы можете внедрить архитектуру Kappa — шаблон развертывания программной архитектуры, ориентированный на потоковую передачу, — чтобы использовать один и тот же конвейер обработки данных для обеспечения правильности и полноты данных в течение гораздо более длительного периода времени для бизнес-анализа.
Как работает многоуровневое хранилище Amazon MSK
Давайте посмотрим, как работает многоуровневое хранилище для Amazon MSK. Apache Kafka хранит данные в файлах с именем сегменты журнала. По мере завершения каждого сегмента, в зависимости от размера сегмента, настроенного на уровне кластера или раздела, он копируется на недорогой уровень хранения. Данные хранятся в хранилище с оптимизированной производительностью в течение определенного времени хранения или до определенного размера, а затем удаляются. Существует отдельная настройка ограничения времени и размера для недорогого хранилища, которое должно быть длиннее, чем уровень хранилища с оптимизированной производительностью. Если клиенты запрашивают данные из сегментов, хранящихся на низкозатратном уровне, брокер считывает данные из него и обслуживает данные так же, как если бы они обслуживались из хранилища с оптимизированной производительностью. API и существующие клиенты работают с минимальными изменениями. Когда ваше приложение начинает считывать данные с низкозатратного уровня, вы можете ожидать увеличения задержки чтения для первых нескольких байтов. Когда вы начнете последовательно считывать оставшиеся данные с недорогого уровня, вы можете ожидать задержек, которые аналогичны основному уровню хранения. При использовании многоуровневого хранилища вы платите за объем данных, которые вы храните, и за объем данных, которые вы извлекаете.
В качестве примера ценообразования давайте рассмотрим рабочую нагрузку, при которой ваша скорость приема составляет 15 МБ/с с коэффициентом репликации 3, и вы хотите хранить данные в своем кластере Kafka в течение 7 дней. Для такой рабочей нагрузки требуется 6 брокеров m5.large с хранилищем EBS на 32.4 ТБ, которое стоит 4,755 долларов. Но если вы используете многоуровневое хранилище для той же рабочей нагрузки с локальным хранением в течение 4 часов и общим хранением данных в течение 7 дней, вам потребуются 3 брокера m5.large с хранилищем EBS на 0.8 ТБ и многоуровневым хранилищем на 9 ТБ, что стоит 1,584 долларов США. Если вы хотите прочитать все исторические данные сразу, это стоит 13 долларов США (0.0015 долларов США за стоимость извлечения из ГБ). В этом примере с многоуровневым хранилищем вы экономите около 66 % от общей стоимости.
Начните использовать многоуровневое хранилище Amazon MSK
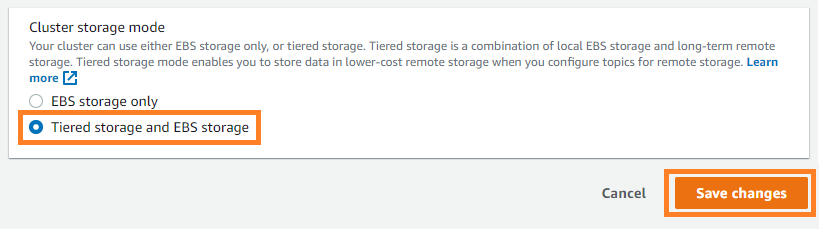
Чтобы включить многоуровневое хранилище в существующем кластере, обновите кластер MSK до версии Kafka 2.8.2.tiered, а затем выберите Многоуровневое хранилище и хранилище EBS в качестве режима хранения вашего кластера на консоли Amazon MSK.

После включения многоуровневого хранилища на уровне кластера выполните следующую команду, чтобы включить многоуровневое хранилище для существующей темы. В этом примере вы включаете многоуровневое хранилище для темы под названием msk-ts-topic со сроком хранения 7 дней (local.retention.ms=604800000) для локального уровня высокопроизводительного хранилища, установив срок хранения 180 дней (retention.ms=15550000000) для сохранения данных на низкозатратном уровне хранения и обновлении размера сегмента журнала до 48 МБ:
Наличие и цены
Многоуровневое хранилище Amazon MSK доступно во всех регионах AWS, где доступно Amazon MSK, за исключением регионов AWS China и AWS GovCloud. Этот недорогой уровень хранения масштабируется практически до неограниченного объема и не требует предварительной подготовки. Вы платите только за тот объем данных, который сохраняется и извлекается на низкозатратном уровне.
Для получения дополнительной информации об этой функции и ее стоимости см. Руководство разработчика Amazon MSK и Страница с ценами на Amazon MSK. Чтобы найти правильный размер кластера, см. страница лучших практик.
Итого
Благодаря многоуровневому хранилищу Amazon MSK вам не нужно выделять хранилище для недорогого уровня или управлять инфраструктурой. Многоуровневое хранилище позволяет масштабироваться до практически неограниченного хранилища. Вы можете получить доступ к данным на низкозатратном уровне, используя те же клиенты, которые вы в настоящее время используете для чтения данных с высокопроизводительного основного уровня хранения. Потребительский API Apache Kafka, API потоков и коннекторы потребляют данные с обоих уровней без изменений. Вы можете изменить лимиты хранения на низкозатратном уровне хранения аналогично тому, как вы можете изменить лимиты хранения на высокопроизводительном хранилище.
Включите многоуровневое хранилище в своих кластерах MSK уже сегодня, чтобы дольше хранить данные при меньших затратах.
Об авторе
 Масудур Рахаман Сайем работает потоковым архитектором в AWS. Он работает с клиентами AWS по всему миру над проектированием и созданием архитектуры потоковой передачи данных для решения реальных бизнес-задач. Он увлечен распределенными системами. Он также любит читать, особенно классические комиксы.
Масудур Рахаман Сайем работает потоковым архитектором в AWS. Он работает с клиентами AWS по всему миру над проектированием и созданием архитектуры потоковой передачи данных для решения реальных бизнес-задач. Он увлечен распределенными системами. Он также любит читать, особенно классические комиксы.

