No final do 2022, AWS anunciou a disponibilidade geral de ingestão de streaming em tempo real para Amazon RedShift para Fluxos de dados do Amazon Kinesis e Amazon Managed Streaming para Apache Kafka (Amazon MSK), eliminando a necessidade de preparar dados de streaming em Serviço de armazenamento simples da Amazon (Amazon S3) antes de ingeri-lo no Amazon Redshift.
Ingestão de streaming do Amazon MSK ao Amazon Redshift, representa uma abordagem de ponta para processamento e análise de dados em tempo real. O Amazon MSK atua como um serviço altamente escalável e totalmente gerenciado para Apache Kafka, permitindo a coleta e o processamento contínuos de vastos fluxos de dados. A integração de dados de streaming ao Amazon Redshift traz imenso valor ao permitir que as organizações aproveitem o potencial da análise em tempo real e da tomada de decisões orientada por dados.
Essa integração permite alcançar baixa latência, medida em segundos, enquanto ingere centenas de megabytes de dados de streaming por segundo no Amazon Redshift. Ao mesmo tempo, esta integração ajuda a garantir que as informações mais atualizadas estejam prontamente disponíveis para análise. Como a integração não exige dados de preparação no Amazon S3, o Amazon Redshift pode ingerir dados de streaming com latência mais baixa e sem custo de armazenamento intermediário.
Você pode configurar a ingestão de streaming do Amazon Redshift em um cluster Redshift usando instruções SQL para autenticar e conectar-se a um tópico MSK. Esta solução é uma excelente opção para engenheiros de dados que buscam simplificar pipelines de dados e reduzir custos operacionais.
Nesta postagem, fornecemos uma visão geral completa sobre como configurar Ingestão de streaming do Amazon Redshift da Amazon MSK.
Visão geral da solução
O diagrama de arquitetura a seguir descreve os serviços e recursos da AWS que você usará.

O fluxo de trabalho inclui as seguintes etapas:
- Você começa configurando um Amazon MSK Conectar conector de origem, para criar um tópico MSK, gerar dados simulados e gravá-los no tópico MSK. Para esta postagem, trabalhamos com dados simulados de clientes.
- A próxima etapa é conectar-se a um cluster Redshift usando o Editor de consultas v2.
- Por fim, você configura um esquema externo e cria uma visualização materializada no Amazon Redshift para consumir os dados do tópico MSK. Esta solução não depende de um conector de coletor MSK Connect para exportar os dados do Amazon MSK para o Amazon Redshift.
O diagrama de arquitetura da solução a seguir descreve com mais detalhes a configuração e a integração dos serviços da AWS que você usará.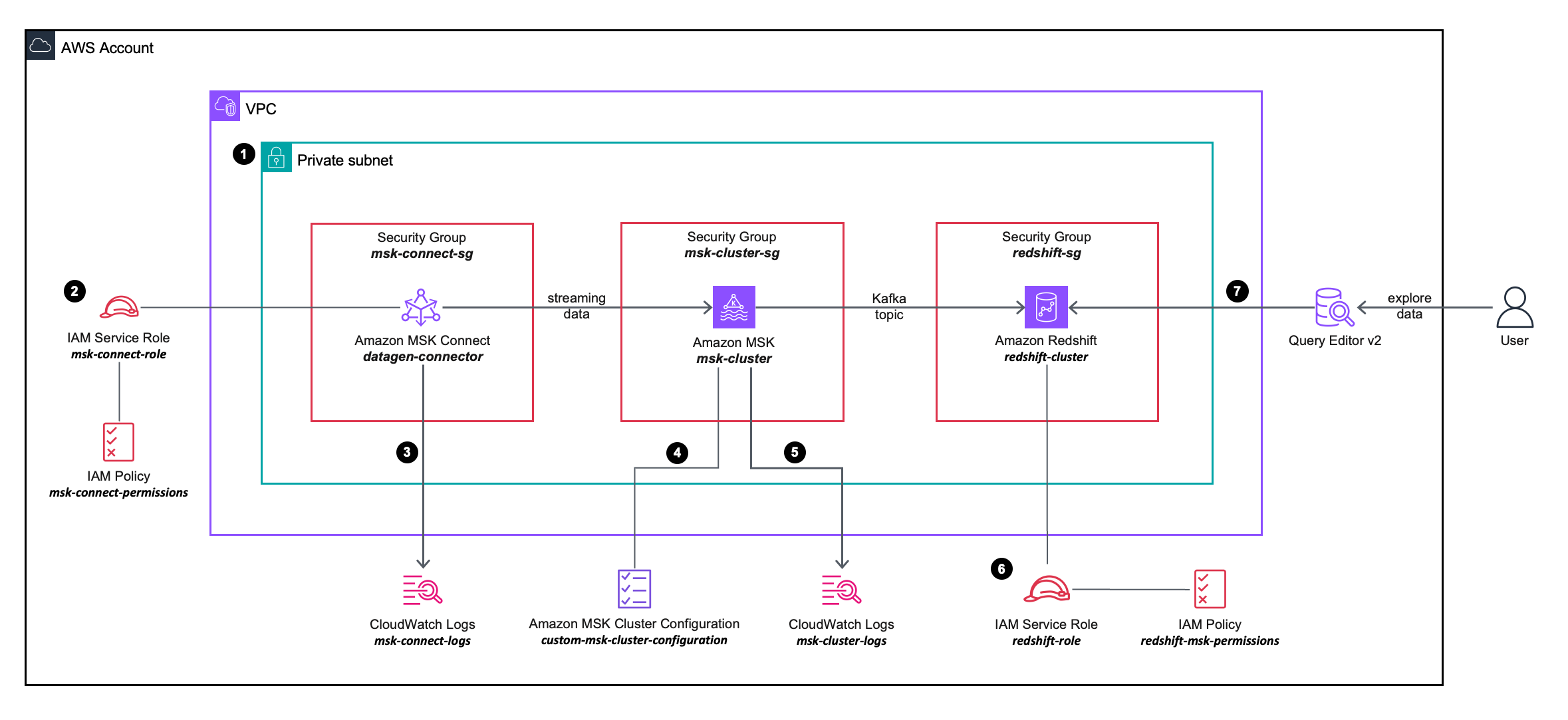
O fluxo de trabalho inclui as seguintes etapas:
- Você implanta um conector de origem MSK Connect, um cluster MSK e um cluster Redshift nas sub-redes privadas em uma VPC.
- O conector de origem MSK Connect usa permissões granulares definidas em um AWS Identity and Access Management (IAM) política em linha anexado a um Papel do IAM, que permite que o conector de origem execute ações no cluster MSK.
- Os logs do conector de origem do MSK Connect são capturados e enviados para um Amazon CloudWatch grupo de registros.
- O cluster MSK usa um configuração de cluster MSK personalizada, permitindo que o conector MSK Connect crie tópicos no cluster MSK.
- Os logs do cluster MSK são capturados e enviados para um grupo de logs do Amazon CloudWatch.
- O cluster Redshift usa permissões granulares definidas em uma política em linha do IAM anexada a uma função do IAM, o que permite que o cluster Redshift execute ações no cluster MSK.
- Você pode usar o Query Editor v2 para se conectar ao cluster Redshift.
Pré-requisitos
Para simplificar o provisionamento e a configuração dos recursos de pré-requisito, você pode usar o seguinte Formação da Nuvem AWS modelo:
![]()
Conclua as etapas a seguir ao iniciar a pilha:
- Escolha Nome da pilha, insira um nome significativo para a pilha, por exemplo,
prerequisites. - Escolha Avançar.
- Escolha Avançar.
- Selecionar Eu reconheço que o AWS CloudFormation pode criar recursos IAM com nomes personalizados.
- Escolha Enviar.
A pilha do CloudFormation cria os seguintes recursos:
- Uma VPC
custom-vpc, criado em três zonas de disponibilidade, com três sub-redes públicas e três sub-redes privadas:- As sub-redes públicas estão associadas a uma tabela de rotas públicas e o tráfego de saída é direcionado para um gateway de Internet.
- As sub-redes privadas estão associadas a uma tabela de rotas privada e o tráfego de saída é enviado para um gateway NAT.
- An gateway de internet anexado ao Amazon VPC.
- A Gateway NAT que está associado a um IP elástico e é implantado em uma das sub-redes públicas.
- Três grupos de segurança:
msk-connect-sg, que será posteriormente associado ao conector MSK Connect.redshift-sg, que será posteriormente associado ao cluster Redshift.msk-cluster-sg, que será posteriormente associado ao cluster MSK. Ele permite o tráfego de entrada demsk-connect-sgeredshift-sg.
- Dois grupos de logs do CloudWatch:
msk-connect-logs, a ser usado para os logs do MSK Connect.msk-cluster-logs, a ser usado para os logs de cluster MSK.
- Duas funções IAM:
msk-connect-role, que inclui permissões granulares do IAM para MSK Connect.redshift-role, que inclui permissões granulares do IAM para o Amazon Redshift.
- A configuração de cluster MSK personalizada, permitindo que o conector MSK Connect crie tópicos no cluster MSK.
- Um cluster MSK, com três corretores implantados nas três sub-redes privadas do
custom-vpc. Amsk-cluster-sggrupo de segurança e ocustom-msk-cluster-configurationconfiguração são aplicadas ao cluster MSK. Os logs do corretor são entregues aomsk-cluster-logsGrupo de logs do CloudWatch. - A Grupo de sub-redes do cluster Redshift, que está usando as três sub-redes privadas de
custom-vpc. - Um cluster Redshift, com um único nó implantado em uma sub-rede privada dentro do grupo de sub-redes de cluster Redshift. O
redshift-sggrupo de segurança eredshift-roleA função IAM é aplicada ao cluster Redshift.
Crie um plugin personalizado do MSK Connect
Para esta postagem, usamos um Gerador de dados Amazon MSK implantado no MSK Connect, para gerar dados simulados do cliente e gravá-los em um tópico MSK.
Conclua as seguintes etapas:
- Faça o download do Gerador de dados Amazon MSK Arquivo JAR com dependências do GitHub.

- Faça upload do arquivo JAR em um bucket S3 em sua conta AWS.
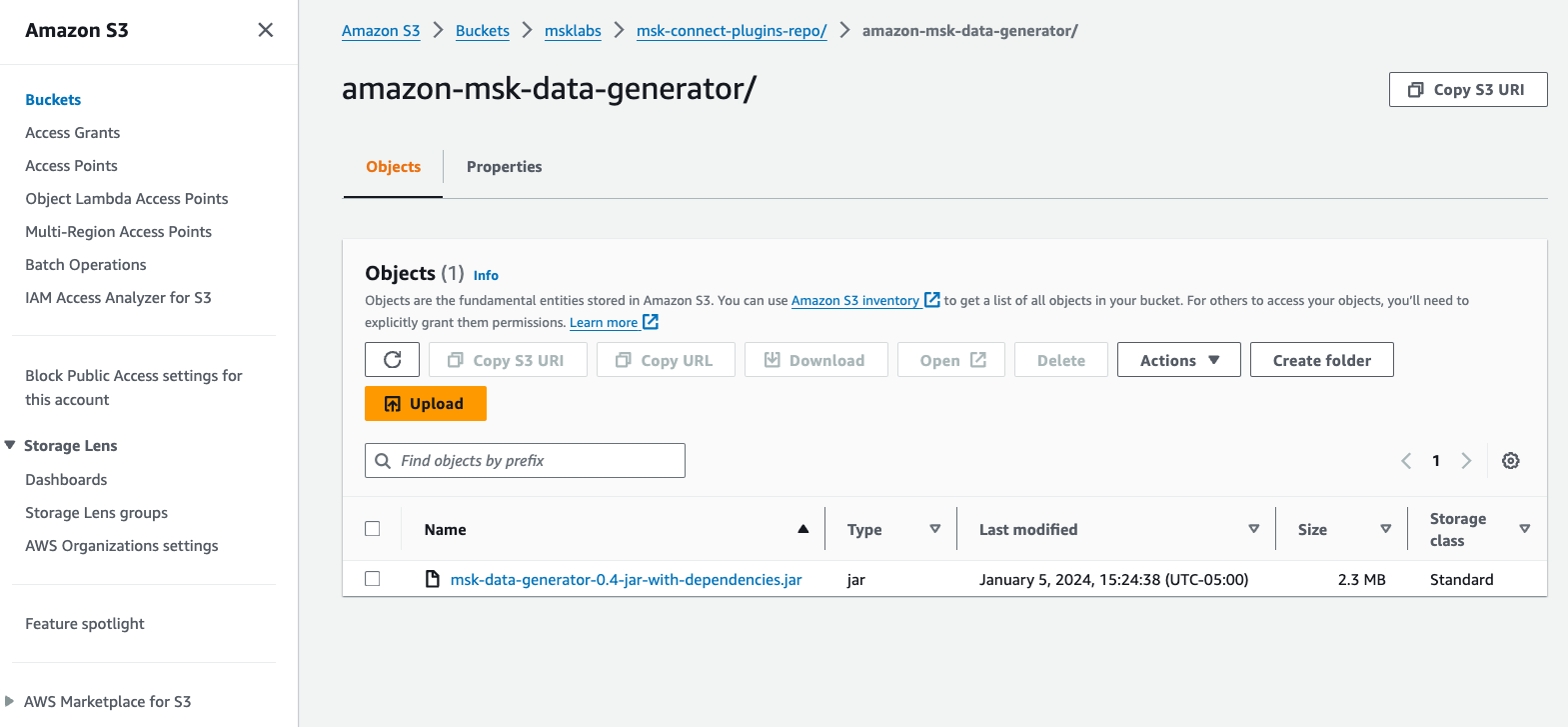
- No console do Amazon MSK, escolha Plug-ins personalizados para Conexão MSK no painel de navegação.
- Escolha Crie um plugin personalizado.
- Escolha Navegar S3, procure o arquivo JAR do gerador de dados do Amazon MSK que você carregou no Amazon S3 e escolha Escolha.
- Escolha Nome do plug-in personalizado, entrar
msk-datagen-plugin. - Escolha Crie um plugin personalizado.
Quando o plugin personalizado for criado, você verá que seu status é Ativoe você pode passar para a próxima etapa.
Crie um conector MSK Connect
Conclua as etapas a seguir para criar seu conector:
- No console do Amazon MSK, escolha conectores para Conexão MSK no painel de navegação.
- Escolha Crie um conector.
- Escolha Tipo de plugin personalizado, escolha Use o plugin existente.
- Selecionar
msk-datagen-plugin, Em seguida, escolha Avançar. - Escolha Nome do conector, entrar
msk-datagen-connector. - Escolha Tipo de cluster, escolha Cluster Apache Kafka autogerenciado.
- Escolha VPC, escolha
custom-vpc. - Escolha Sub-rede 1, escolha a sub-rede privada na sua primeira zona de disponibilidade.
Para o custom-vpc criado pelo modelo CloudFormation, estamos usando intervalos CIDR ímpares para sub-redes públicas e até intervalos CIDR para sub-redes privadas:
-
- Os CIDRs para as sub-redes públicas são 10.10.1.0/24, 10.10.3.0/24 e 10.10.5.0/24
- Os CIDRs para as sub-redes privadas são 10.10.2.0/24, 10.10.4.0/24 e 10.10.6.0/24
- Escolha Sub-rede 2, selecione a sub-rede privada na sua segunda zona de disponibilidade.
- Escolha Sub-rede 3, selecione a sub-rede privada na sua terceira zona de disponibilidade.
- Escolha Servidores de inicialização, insira a lista de servidores de inicialização para autenticação TLS do seu cluster MSK.
Para recupere os servidores de inicialização para seu cluster MSK, navegue até o console do Amazon MSK e escolha Clusters, escolha msk-cluster, Em seguida, escolha Ver informações do cliente. Copie os valores TLS para os servidores de inicialização.
- Escolha Grupos de segurança, escolha Use grupos de segurança específicos com acesso a este clustere escolha
msk-connect-sg. - Escolha Configuração do conector, substitua as configurações padrão pelas seguintes:
- Para capacidade do conector, escolha Provisionado.
- Escolha Contagem de MCU por trabalhador, escolha 1.
- Escolha Número de trabalhadores, escolha 1.
- Escolha configuração do trabalhador, escolha Use a configuração padrão do MSK.
- Escolha Permissões de acesso, escolha
msk-connect-role. - Escolha Avançar.
- Para criptografia, selecione Tráfego criptografado TLS.
- Escolha Avançar.
- Escolha Log de entrega, escolha Entregue no Amazon CloudWatch Logs.
- Escolha Procurar, selecione
msk-connect-logse escolha Escolha. - Escolha Avançar.
- Revise e escolha Crie um conector.
Após a criação do conector personalizado, você verá que seu status é Corridae você pode passar para a próxima etapa.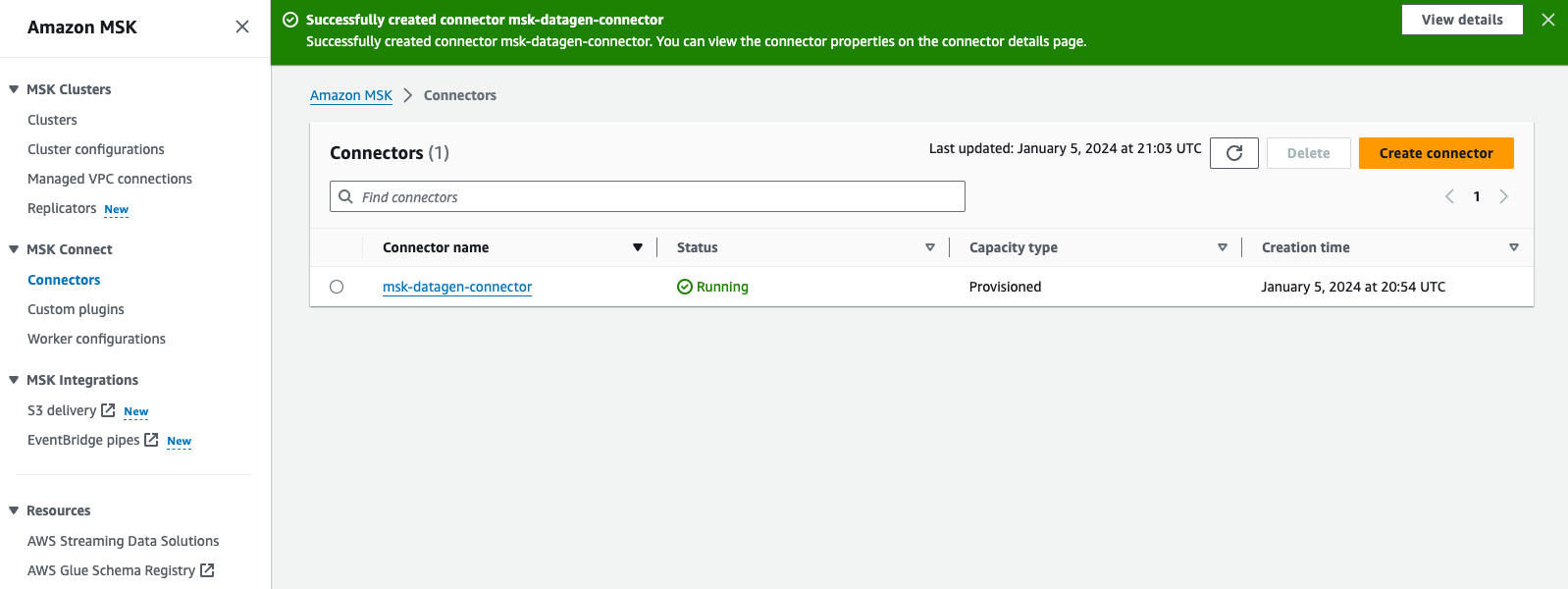
Configurar a ingestão de streaming do Amazon Redshift para Amazon MSK
Conclua as etapas a seguir para configurar a ingestão de streaming:
- Conecte-se ao seu cluster Redshift usando o Query Editor v2 e autentique-se com o nome de usuário do banco de dados
awsuser, e senhaAwsuser123. - Crie um esquema externo do Amazon MSK usando a instrução SQL a seguir.
No código a seguir, insira os valores para o redshift-role Função do IAM e o msk-cluster cluster ARN.
- Escolha Execute para executar a instrução SQL.
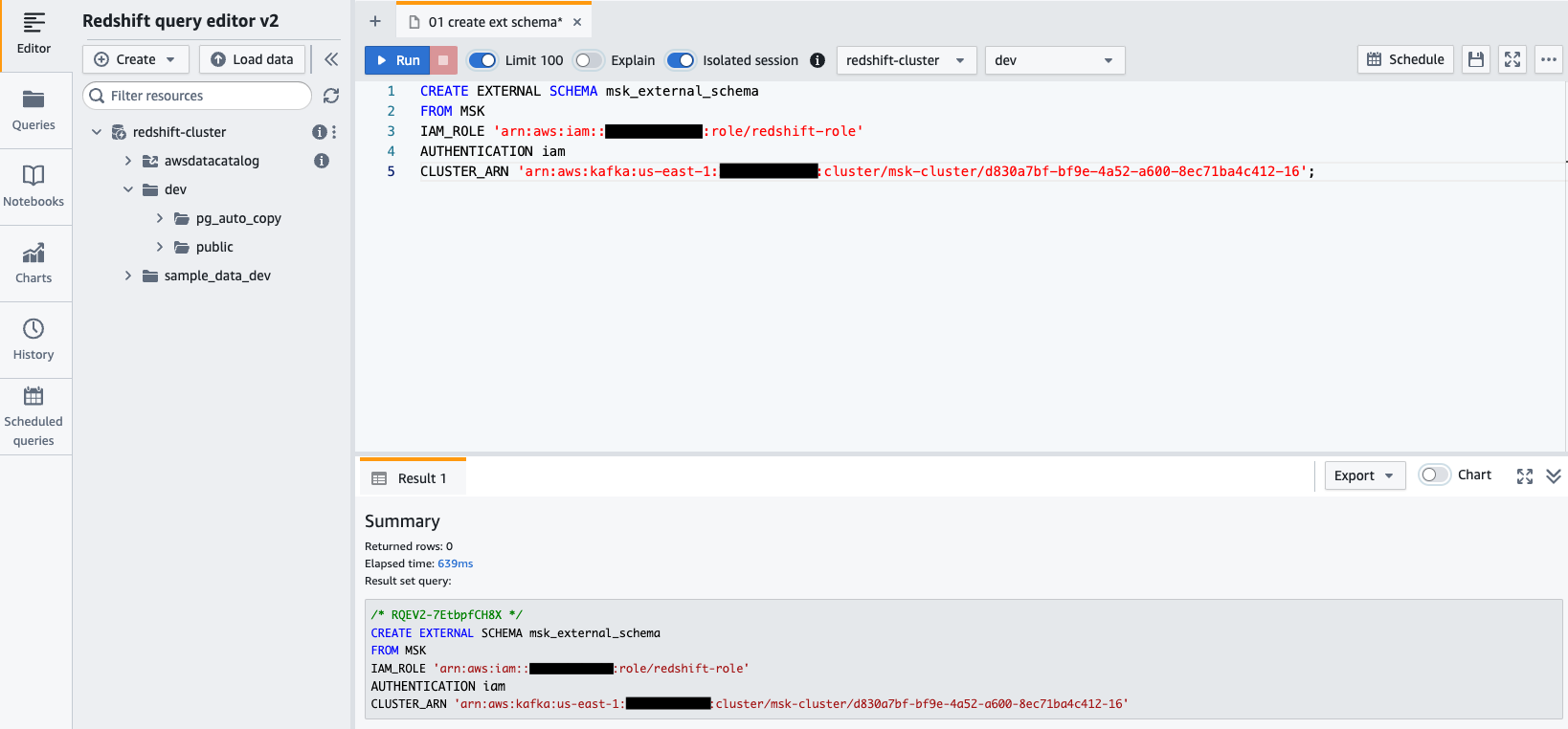
- Crie uma visão materializada usando a seguinte instrução SQL:
- Escolha Execute para executar a instrução SQL.
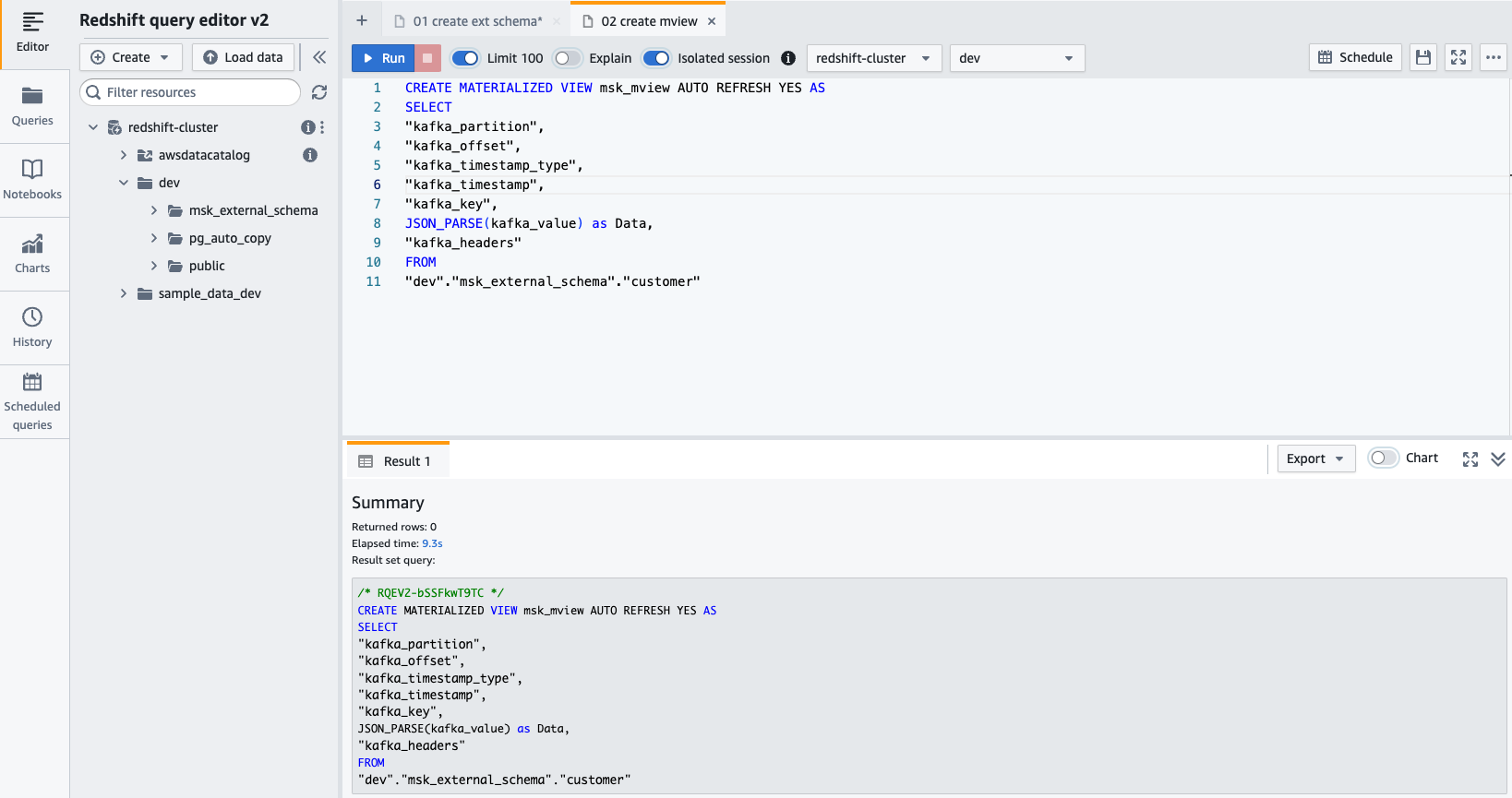
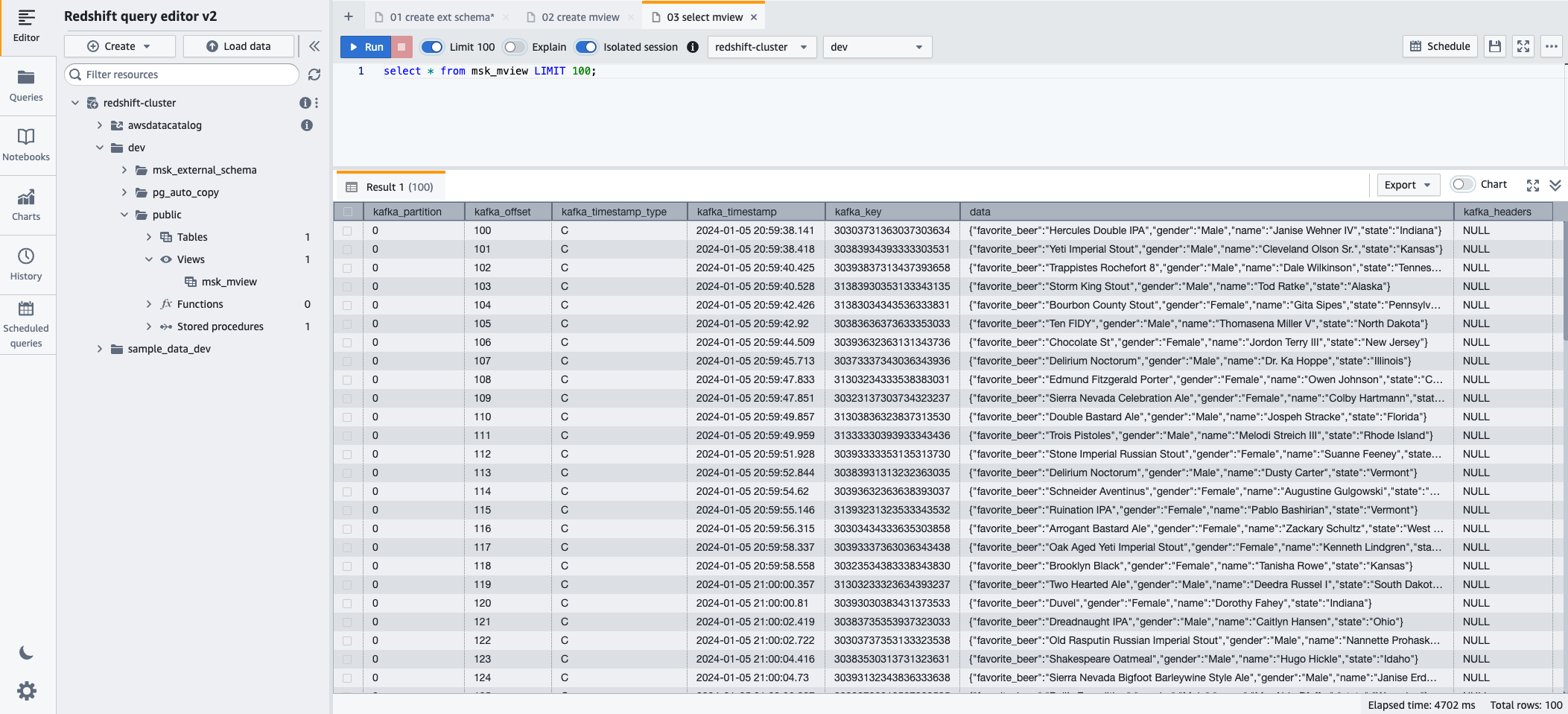
- Agora você pode consultar a visualização materializada usando a seguinte instrução SQL:
- Escolha Execute para executar a instrução SQL.
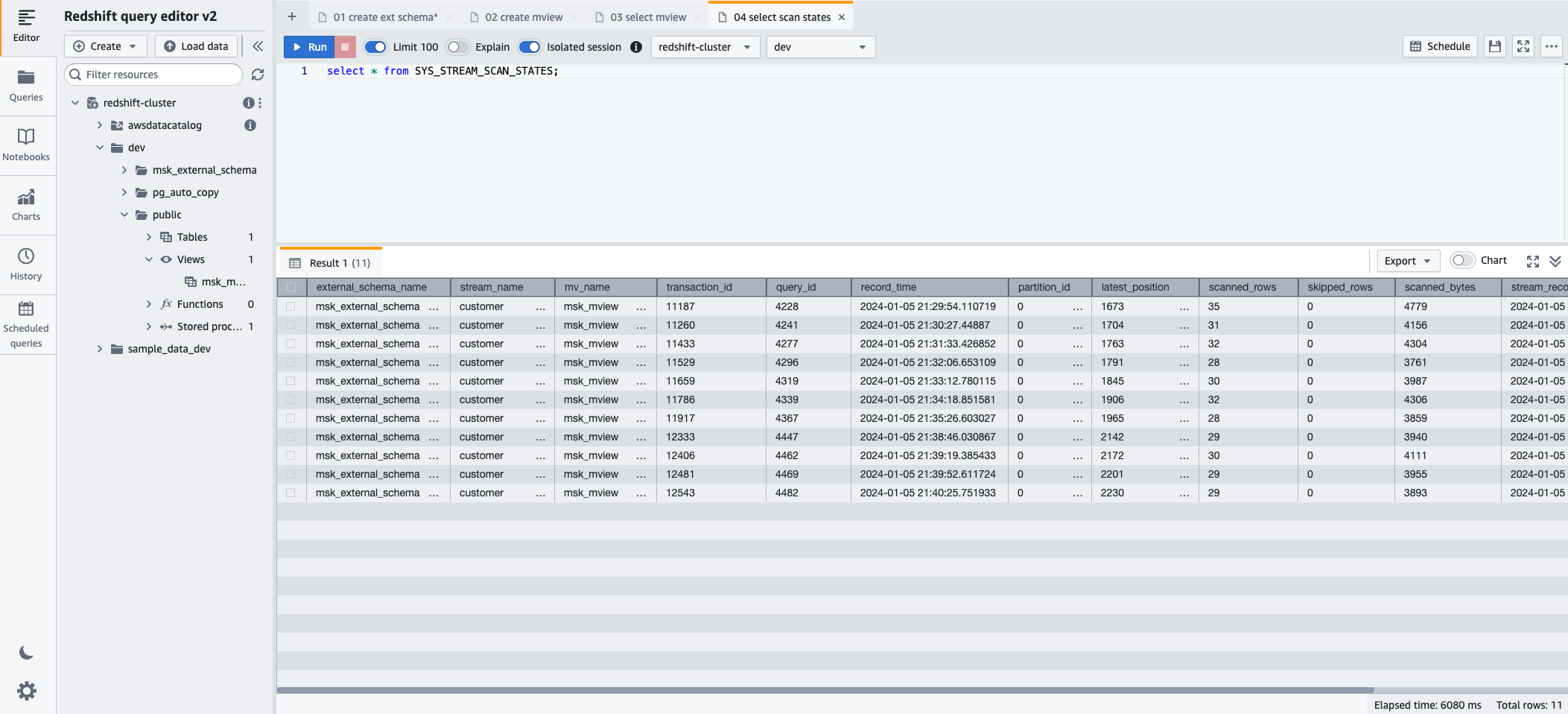
- Para monitorar o progresso dos registros carregados por meio da ingestão de streaming, você pode aproveitar o recurso SYS_STREAM_SCAN_STATES visualização de monitoramento usando a seguinte instrução SQL:
- Escolha Execute para executar a instrução SQL.
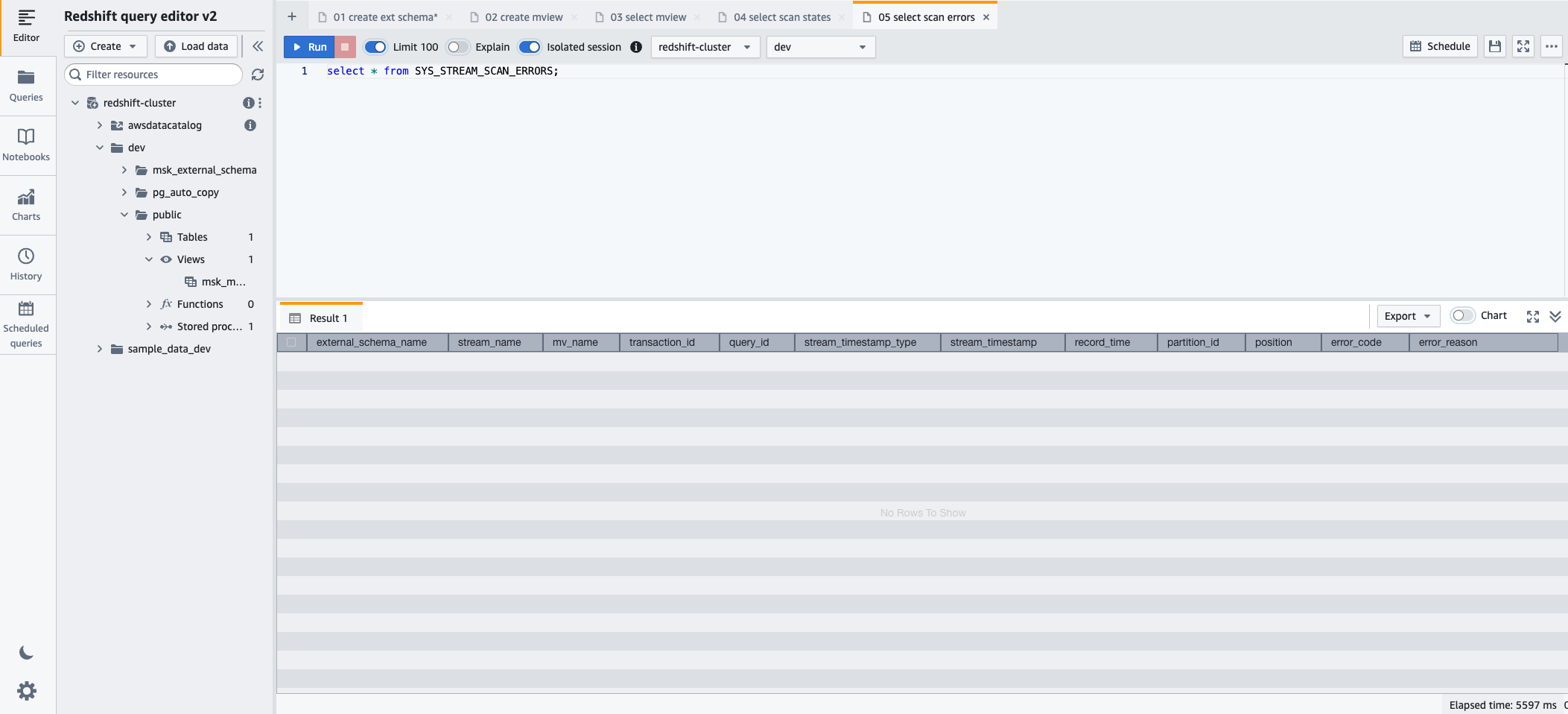
- Para monitorar erros encontrados em registros carregados por meio de ingestão de streaming, você pode aproveitar a opção SYS_STREAM_SCAN_ERRORS visualização de monitoramento usando a seguinte instrução SQL:
- Escolha Execute para executar a instrução SQL.
limpar
Depois de acompanhar, se você não precisar mais dos recursos criados, exclua-os na seguinte ordem para evitar cobranças adicionais:
- Exclua o conector MSK Connect
msk-datagen-connector. - Exclua o plug-in MSK Connect
msk-datagen-plugin. - Exclua o arquivo JAR do gerador de dados do Amazon MSK que você baixou e exclua o bucket do S3 que você criou.
- Depois de excluir o conector MSK Connect, você poderá excluir o modelo CloudFormation. Todos os recursos criados pelo modelo CloudFormation serão automaticamente excluídos da sua conta AWS.
Conclusão
Nesta postagem, demonstramos como configurar a ingestão de streaming do Amazon Redshift no Amazon MSK, com foco em privacidade e segurança.
A combinação da capacidade do Amazon MSK de lidar com fluxos de dados de alta produtividade com os recursos analíticos robustos do Amazon Redshift permite que as empresas obtenham insights acionáveis prontamente. Essa integração de dados em tempo real aumenta a agilidade e a capacidade de resposta das organizações na compreensão das mudanças nas tendências de dados, nos comportamentos dos clientes e nos padrões operacionais. Permite a tomada de decisões oportuna e informada, ganhando assim uma vantagem competitiva no cenário empresarial dinâmico de hoje.
Esta solução também é aplicável para clientes que desejam utilizar Amazon MSK sem servidor e Sem servidor Amazon Redshift.
Esperamos que esta postagem tenha sido uma boa oportunidade para aprender mais sobre integração e configuração de serviços AWS. Deixe-nos saber seu feedback na seção de comentários.
Sobre os autores
 Sebastião Vlad é arquiteto de soluções parceiro sênior da Amazon Web Services, apaixonado por soluções de dados e análise e sucesso do cliente. Sebastian trabalha com clientes empresariais para ajudá-los a projetar e construir soluções modernas, seguras e escaláveis para alcançar seus resultados de negócios.
Sebastião Vlad é arquiteto de soluções parceiro sênior da Amazon Web Services, apaixonado por soluções de dados e análise e sucesso do cliente. Sebastian trabalha com clientes empresariais para ajudá-los a projetar e construir soluções modernas, seguras e escaláveis para alcançar seus resultados de negócios.
 Sharad Pai é consultor técnico líder na AWS. Ele é especialista em análise de streaming e ajuda os clientes a criar soluções escaláveis usando Amazon MSK e Amazon Kinesis. Ele tem mais de 16 anos de experiência no setor e atualmente trabalha com clientes de mídia que hospedam plataformas de streaming ao vivo na AWS, gerenciando picos de simultaneidade de mais de 50 milhões. Antes de ingressar na AWS, a carreira de Sharad como desenvolvedor líder de software incluiu 9 anos de codificação, trabalhando com tecnologias de código aberto como JavaScript, Python e PHP.
Sharad Pai é consultor técnico líder na AWS. Ele é especialista em análise de streaming e ajuda os clientes a criar soluções escaláveis usando Amazon MSK e Amazon Kinesis. Ele tem mais de 16 anos de experiência no setor e atualmente trabalha com clientes de mídia que hospedam plataformas de streaming ao vivo na AWS, gerenciando picos de simultaneidade de mais de 50 milhões. Antes de ingressar na AWS, a carreira de Sharad como desenvolvedor líder de software incluiu 9 anos de codificação, trabalhando com tecnologias de código aberto como JavaScript, Python e PHP.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/simplify-data-streaming-ingestion-for-analytics-using-amazon-msk-and-amazon-redshift/

