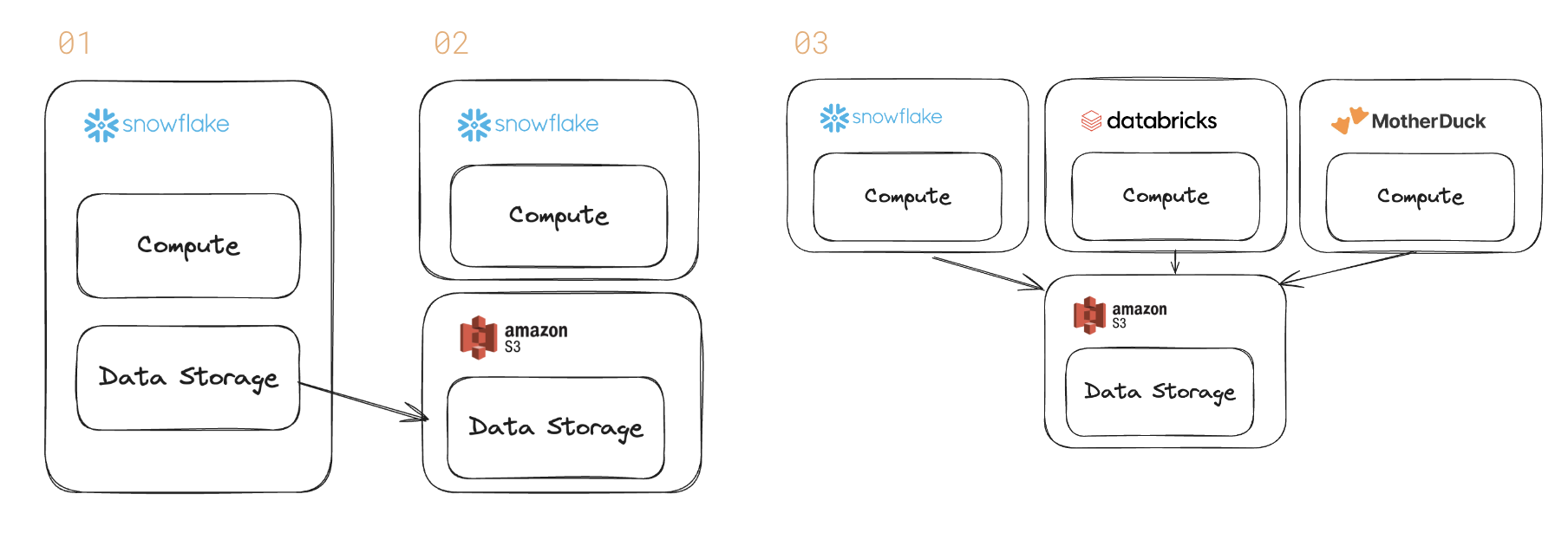
O banco de dados está sendo desagregado. Historicamente, um banco de dados como o Snowflake vendia armazenamento de dados e um mecanismo de consulta (e o poder de computação para executar a consulta). Essa é a etapa 1 acima.
Porém, os clientes estão pressionando por uma separação mais profunda entre computação e armazenamento. A recente teleconferência de resultados da Snowflake destacou a tendência. Os clientes maiores preferem formatos abertos para interoperabilidade (etapas 2 e 3).
Muitos grandes clientes desejam ter formatos de arquivo abertos para lhes dar opções... Portanto, a interoperabilidade de dados é uma coisa importante e nossos produtos de IA geralmente também podem atuar em dados que estão armazenados em nuvem.
Esperamos que vários de nossos grandes clientes adotem formatos Iceberg e movam seus dados para fora do Snowflake, onde perderemos a receita de armazenamento e também a receita de computação associada à movimentação desses dados para o Snowflake.
Em vez de bloquear os dados em um banco de dados, os clientes preferem tê-los em formatos abertos como Apache Arrow, Apache Parquet, Apache Iceberg.
À medida que o uso de dados dentro de uma empresa se expandiu, também aumentou a diversidade de demandas sobre esses dados.
Em vez de copiá-los a cada vez para uma finalidade diferente, seja análise exploratória, inteligência de negócios ou cargas de trabalho de IA, por que não centralizar os dados e fazer com que muitos sistemas diferentes os acessem?
Isso economiza dinheiro: o armazenamento total é de cerca de US$ 280 milhões a 300 milhões para a Snowflake.
Recorde-se que cerca de 10% a 11% da nossa receita global está associada ao armazenamento.
Mas também simplifica arquiteturas.
Também inaugura uma época em que os mecanismos de consulta competirão por diferentes cargas de trabalho com preço e desempenho. O Snowflake pode ser melhor para BI em larga escala; Spark da Databricks para pipelines de dados de IA; MãePata para análises interativas.
Os fornecedores de data warehouse comercializaram o separação de armazenamento e computação no passado. Mas essa mensagem era sobre dimensionar o sistema para lidar com dados maiores em seu próprio produto.
Os clientes exigem uma separação mais profunda – um mundo em que os bancos de dados não cobrem pelo armazenamento.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.tomtunguz.com/why-databases-wont-charge-storage/

