
Imagem do autor
A Mistral AI, uma das empresas líderes mundiais em pesquisa de IA, lançou recentemente o modelo básico para Mistral 7B v0.2.
Este modelo de linguagem de código aberto foi revelado durante o evento hackathon da empresa em 23 de março de 2024.
Os modelos Mistral 7B possuem 7.3 bilhões de parâmetros, o que os torna extremamente poderosos. Eles superam o Llama 2 13B e o Llama 1 34B em quase todos os benchmarks. O modelo V0.2 mais recente apresenta uma janela de contexto de 32k, entre outros avanços, aprimorando sua capacidade de processar e gerar texto.
Além disso, a versão anunciada recentemente é o modelo básico da variante ajustada para instrução, “Mistral-7B-Instruct-V0.2”, que foi lançada no início do ano passado.
Neste tutorial, mostrarei como acessar e ajustar esse modelo de linguagem no Hugging Face.
Estaremos ajustando o modelo básico do Mistral 7B-v0.2 usando a funcionalidade AutoTrain do Hugging Face.
Abraçando o rosto é conhecida por democratizar o acesso a modelos de aprendizado de máquina, permitindo que usuários comuns desenvolvam soluções avançadas de IA.
O AutoTrain, recurso do Hugging Face, automatiza o processo de treinamento do modelo, tornando-o acessível e eficiente.
Ele ajuda os usuários a selecionar os melhores parâmetros e técnicas de treinamento ao ajustar modelos, o que é uma tarefa que, de outra forma, pode ser assustadora e demorada.
Aqui estão 5 etapas para ajustar seu modelo Mistral-7B:
1. Configurando o ambiente
Você deve primeiro criar uma conta no Hugging Face e, em seguida, criar um repositório de modelos.
Para conseguir isso, basta seguir as etapas fornecidas neste link e volte a este tutorial.
Estaremos treinando o modelo em Python. Quando se trata de selecionar um ambiente de notebook para treinamento, você pode usar Cadernos Kaggle or google colab, sendo que ambos fornecem acesso gratuito às GPUs.
Se o processo de treinamento demorar muito, você pode querer mudar para uma plataforma em nuvem como AWS Sagemaker ou Azure ML.
Por fim, execute as seguintes instalações de pip antes de começar a codificar este tutorial:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Preparando seu conjunto de dados
Neste tutorial, usaremos o Conjunto de dados Alpaca no Hugging Face, que se parece com isto:
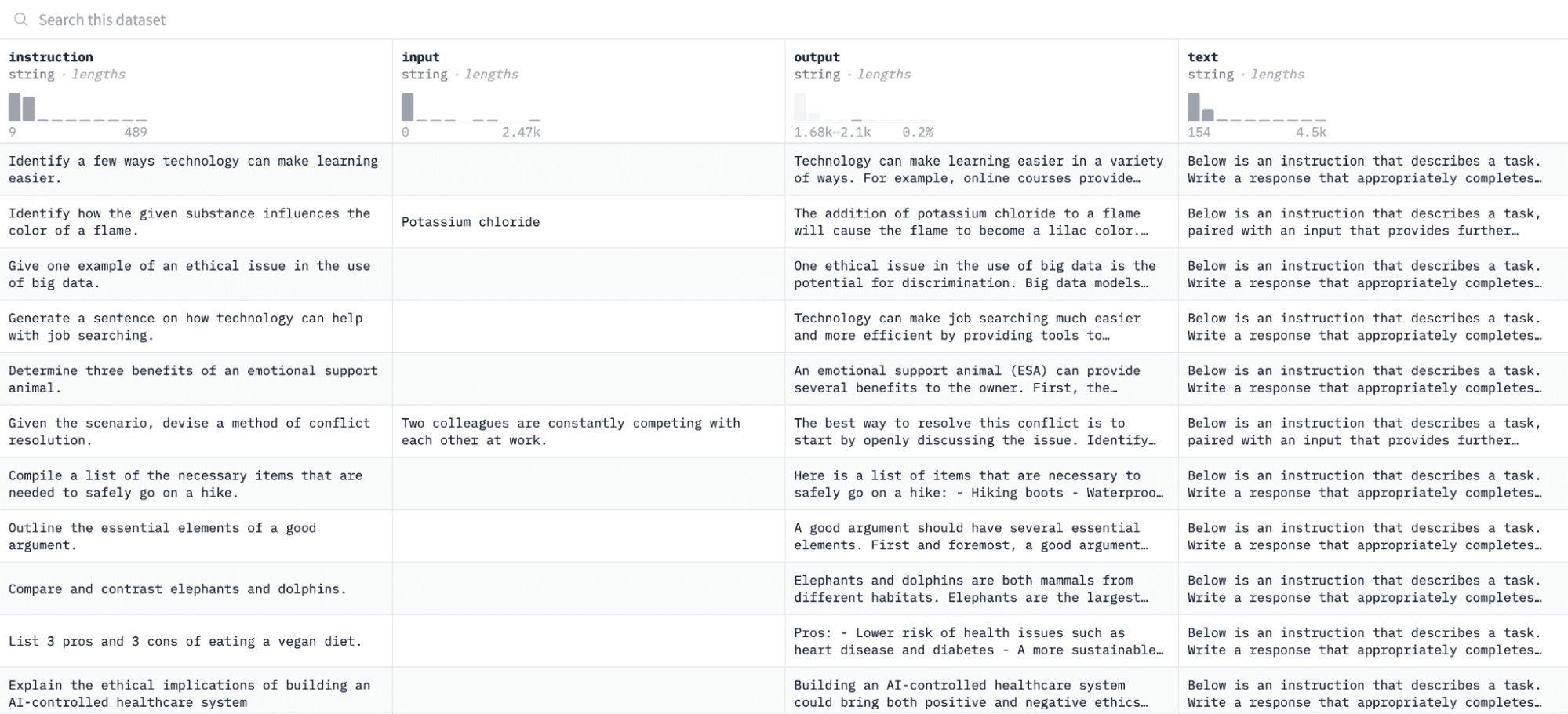
Ajustaremos o modelo em pares de instruções e resultados e avaliaremos sua capacidade de responder à instrução fornecida no processo de avaliação.
Para acessar e preparar este conjunto de dados, execute as seguintes linhas de código:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")A primeira função irá carregar o conjunto de dados Alpaca usando a biblioteca “datasets” e limpá-lo para garantir que não estamos incluindo nenhuma instrução vazia. A segunda função estrutura seus dados em um formato que o AutoTrain possa entender.
Após executar o código acima, o conjunto de dados será carregado, formatado e salvo no caminho especificado. Ao abrir seu conjunto de dados formatado, você verá uma única coluna chamada “formatted_text”.
3. Configurando seu ambiente de treinamento
Agora que você preparou o conjunto de dados com êxito, vamos prosseguir com a configuração do ambiente de treinamento do modelo.
Para fazer isso, você deve definir os seguintes parâmetros:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Aqui está uma análise das especificações acima:
- Você pode especificar qualquer Nome do Projeto. É aqui que todos os seus arquivos de projeto e treinamento serão armazenados.
- A nome_modelo parâmetro é o modelo que você deseja ajustar. Neste caso, especifiquei um caminho para o Modelo básico Mistral-7B v0.2 no rosto abraçado.
- A hf_token variável deve ser definida como seu token Hugging Face, que pode ser obtido navegando até este link.
- investimentos id_repositório deve ser definido como o repositório do modelo Hugging Face que você criou na primeira etapa deste tutorial. Por exemplo, meu ID de repositório é NatashaS/Modelo2.
4. Configurando parâmetros do modelo
Antes de ajustar nosso modelo, devemos definir os parâmetros de treinamento, que controlam aspectos do comportamento do modelo, como duração e regularização do treinamento.
Esses parâmetros influenciam aspectos importantes como quanto tempo o modelo treina, como ele aprende com os dados e como evita o overfitting.
Você pode definir os seguintes parâmetros para o seu modelo:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Configurando variáveis de ambiente
Vamos agora preparar nosso ambiente de treinamento definindo algumas variáveis de ambiente.
Esta etapa garante que o recurso AutoTrain use as configurações desejadas para ajustar o modelo, como o nome do projeto e as preferências de treinamento:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Inicie o treinamento do modelo
Finalmente, vamos começar a treinar o modelo usando o autotreinamento comando. Esta etapa envolve a especificação de seu modelo, conjunto de dados e configurações de treinamento, conforme exibido abaixo:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Certifique-se de alterar o caminho de dados para onde seu conjunto de dados de treinamento está localizado.
7. Avaliando o modelo
Depois que seu modelo terminar o treinamento, você verá uma pasta aparecer em seu diretório com o mesmo título do nome do seu projeto.
No meu caso, esta pasta é intitulada “mistralai”, como pode ser visto na imagem abaixo:
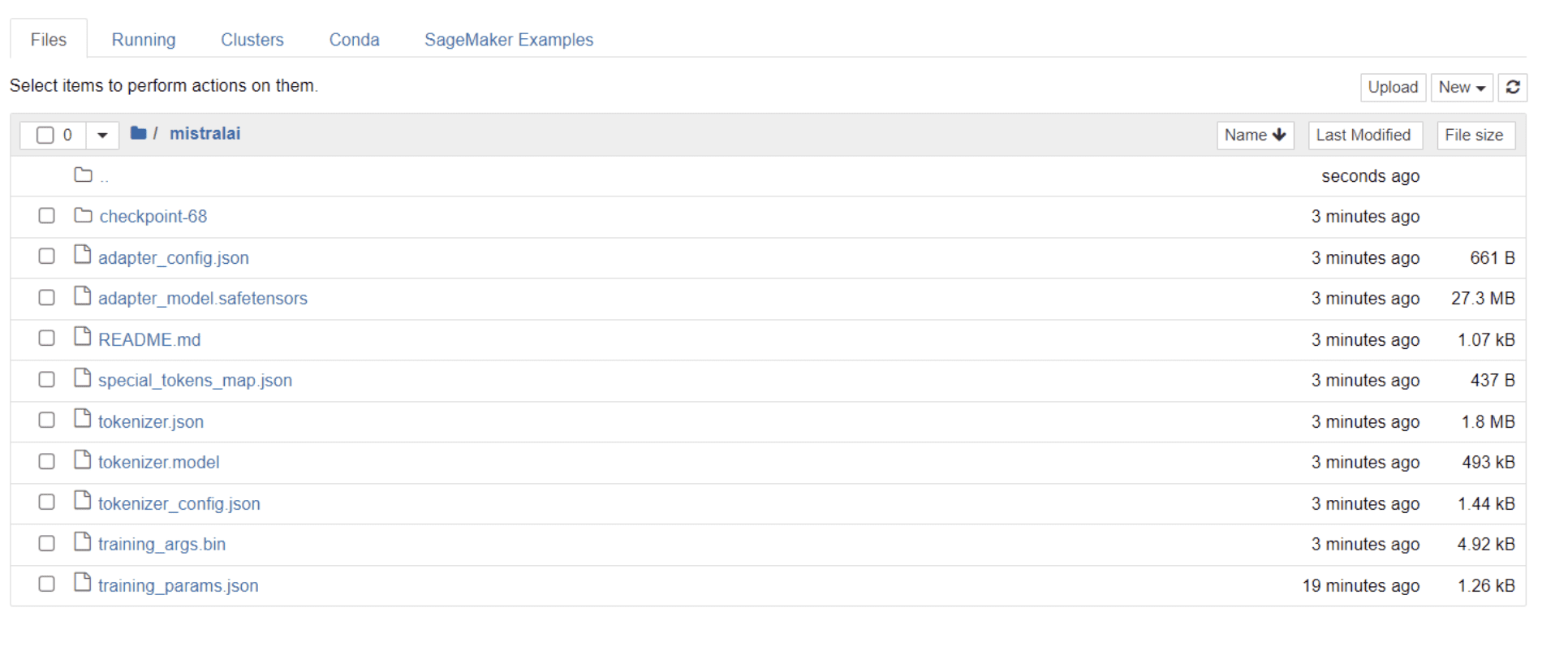
Dentro desta pasta, você pode encontrar arquivos que abrangem pesos de modelo, hiperparâmetros e detalhes de arquitetura.
Vamos agora verificar se este modelo ajustado é capaz de responder com precisão a uma pergunta em nosso conjunto de dados. Para conseguir isso, primeiro precisamos executar as seguintes linhas de código para gerar 5 exemplos de entradas e saídas de nosso conjunto de dados:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")Você deverá ver uma resposta semelhante a esta, apresentando 5 pontos de dados de amostra:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.Vamos digitar uma das instruções acima no modelo e verificar se ela gera um resultado preciso. Aqui está uma função para fornecer uma instrução ao modelo e obter uma resposta dele:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerPor fim, insira uma pergunta nesta função conforme exibido abaixo:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Seu modelo deve gerar uma resposta idêntica à saída correspondente no conjunto de dados de treinamento, conforme exibido abaixo:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andObserve que a resposta pode parecer incompleta ou cortada devido ao número de tokens que especificamos. Sinta-se à vontade para ajustar o valor “max_length” para permitir uma resposta mais estendida.
Se você chegou até aqui, parabéns!
Você ajustou com sucesso um modelo de linguagem de última geração, aproveitando o poder do Mistral 7B v-0.2 junto com os recursos do Hugging Face.
Mas a jornada não termina aqui.
Como próxima etapa, recomendo experimentar diferentes conjuntos de dados ou ajustar certos parâmetros de treinamento para otimizar o desempenho do modelo. O ajuste fino de modelos em maior escala aumentará sua utilidade, então experimente experimentar conjuntos de dados maiores ou formatos variados, como PDFs e arquivos de texto.
Essa experiência torna-se inestimável quando se trabalha com dados do mundo real nas organizações, que muitas vezes são confusos e desestruturados.
Natasha Selvaraj é um cientista de dados autodidata com paixão por escrever. Natasha escreve sobre tudo relacionado à ciência de dados, uma verdadeira mestre em todos os tópicos de dados. Você pode se conectar com ela em LinkedIn ou dê uma olhada nela Canal no YouTube.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

