A manutenção preditiva é uma estratégia de manutenção orientada por dados para monitorar ativos industriais, a fim de detectar anomalias nas operações e na integridade dos equipamentos que podem levar a falhas nos equipamentos. Por meio do monitoramento proativo da condição de um ativo, o pessoal de manutenção pode ser alertado antes que ocorram problemas, evitando assim dispendiosos tempos de inatividade não planejados, o que, por sua vez, leva a um aumento na eficácia geral do equipamento (OEE).
No entanto, construir os modelos de aprendizado de máquina (ML) necessários para manutenção preditiva é complexo e demorado. Ele requer várias etapas, incluindo o pré-processamento dos dados, construção, treinamento, avaliação e, em seguida, ajuste fino de vários modelos de ML que podem prever com segurança anomalias nos dados do seu ativo. Os modelos de ML finalizados precisam ser implantados e fornecidos com dados ao vivo para previsões online (inferência). A escala desse processo para vários ativos de vários tipos e perfis operacionais costuma consumir muitos recursos para viabilizar a adoção mais ampla da manutenção preditiva.
Com o Amazon Lookout para Equipamentos, você pode analisar perfeitamente os dados do sensor de seu equipamento industrial para detectar comportamento anormal da máquina, sem a necessidade de experiência em ML.
Quando os clientes implementam casos de uso de manutenção preditiva com o Lookout for Equipment, eles normalmente escolhem entre três opções para entregar o projeto: construí-lo sozinhos, trabalhar com um parceiro da AWS ou usar os serviços profissionais da AWS. Antes de se comprometer com esses projetos, tomadores de decisão, como gerentes de fábrica, gerentes de confiabilidade ou manutenção e líderes de linha, desejam ver evidências do valor potencial que a manutenção preditiva pode revelar em suas linhas de negócios. Essa avaliação geralmente é realizada como parte de uma prova de conceito (POC) e é a base para um caso de negócios.
Esta postagem é direcionada a usuários técnicos e não técnicos: ela fornece uma abordagem eficaz para avaliar o Lookout for Equipment com seus próprios dados, permitindo que você avalie o valor comercial que ele fornece às suas atividades de manutenção preditiva.
Visão geral da solução
Nesta postagem, orientamos você pelas etapas para ingerir um conjunto de dados no Lookout for Equipment, revisar a qualidade dos dados do sensor, treinar um modelo e avaliar o modelo. A conclusão dessas etapas ajudará a obter informações sobre a integridade do seu equipamento.
Pré-requisitos
Tudo o que você precisa para começar é uma conta da AWS e um histórico de dados do sensor para ativos que podem se beneficiar de uma abordagem de manutenção preditiva. Os dados do sensor devem ser armazenados como arquivos CSV em um Serviço de armazenamento simples da Amazon (Amazon S3) da sua conta. Sua equipe de TI deve ser capaz de atender a esses pré-requisitos consultando Formatando seus dados. Para simplificar, é melhor armazenar todos os dados do sensor em um arquivo CSV onde as linhas são carimbos de data/hora e as colunas são sensores individuais (até 300).
Depois de disponibilizar seu conjunto de dados no Amazon S3, você pode acompanhar o restante desta postagem.
Adicionar um conjunto de dados
A Lookout for Equipment utiliza projetos para organizar os recursos para avaliação de equipamentos industriais. Para criar um novo projeto, conclua as seguintes etapas:
- No console Lookout for Equipment, escolha Criar projeto.

- Digite um nome de projeto e escolha Criar projeto.
Após a criação do projeto, você pode ingerir um conjunto de dados que será usado para treinar e avaliar um modelo para detecção de anomalias.
- Na página do projeto, escolha Adicionar conjunto de dados.

- Escolha Localização S3, insira o local do S3 (excluindo o nome do arquivo) dos seus dados.
- Escolha Método de detecção de esquema, selecione Por nome de arquivo, que assume que todos os dados do sensor para um ativo estão contidos em um único arquivo CSV no local S3 especificado.
- Mantenha as outras configurações como padrão e escolha Iniciar processamento para iniciar o processo de ingestão.
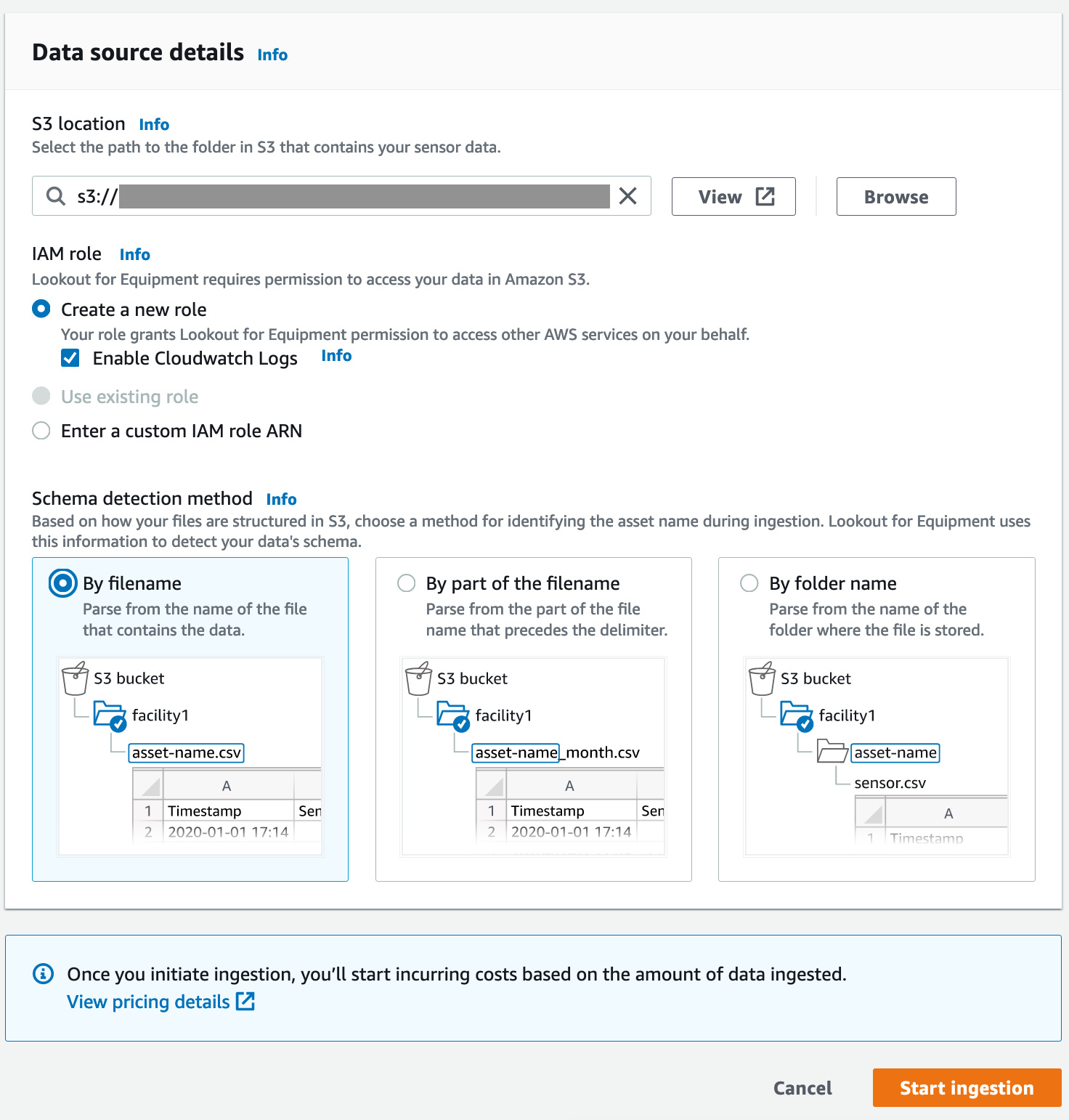
A ingestão pode levar cerca de 10 a 20 minutos para ser concluída. Em segundo plano, o Lookout for Equipment executa as seguintes tarefas:
- Ele detecta a estrutura dos dados, como nomes de sensores e tipos de dados.
- Os timestamps entre os sensores são alinhados e os valores ausentes são preenchidos (usando o último valor conhecido).
- Os timestamps duplicados são removidos (somente o último valor para cada timestamp é mantido).
- O Lookout for Equipment usa vários tipos de algoritmos para criar o modelo de detecção de anomalias de ML. Durante a fase de ingestão, ele prepara os dados para que possam ser usados para treinar esses diferentes algoritmos.
- Ele analisa os valores de medição e classifica cada sensor como de alta, média ou baixa qualidade.
- Quando a ingestão do conjunto de dados estiver concluída, inspecione-a escolhendo Ver conjunto de dados na Etapa 2 da página do projeto.

Ao criar um modelo de detecção de anomalias, selecionar os melhores sensores (aqueles que contêm a mais alta qualidade de dados) geralmente é fundamental para modelos de treinamento que fornecem insights acionáveis. O Detalhes do conjunto de dados A seção mostra a distribuição das classificações do sensor (entre alto, médio e baixo), enquanto a tabela exibe informações sobre cada sensor separadamente (incluindo o nome do sensor, intervalo de datas e classificação dos dados do sensor). Com este relatório detalhado, você pode tomar uma decisão informada sobre quais sensores usará para treinar seus modelos. Se uma grande proporção de sensores em seu conjunto de dados for classificada como média ou baixa, pode haver um problema de dados que precise ser investigado. Se necessário, você pode reenviar o arquivo de dados para o Amazon S3 e ingerir os dados novamente escolhendo Substituir conjunto de dados.

Ao escolher a entrada do grau do sensor na tabela de detalhes, você pode revisar os detalhes sobre os erros de validação que resultaram em um determinado grau. Exibir e abordar esses detalhes ajudará a garantir que as informações fornecidas ao modelo sejam de alta qualidade. Por exemplo, você pode ver que um sinal tem grandes blocos inesperados de valores ausentes. Isso é um problema de transferência de dados ou o sensor estava com defeito? Hora de mergulhar mais fundo em seus dados!

Para saber mais sobre os diferentes tipos de problemas de sensor, o Lookout for Equipment aborda ao classificar seus sensores, consulte Avaliando as notas do sensor. Os desenvolvedores também podem extrair esses insights usando o API ListSensorStatistics.
Quando estiver satisfeito com seu conjunto de dados, você pode passar para a próxima etapa de treinamento de um modelo para prever anomalias.
Treine uma modelo
Lookout for Equipment permite o treinamento de modelos para sensores específicos. Isso lhe dá a flexibilidade de experimentar diferentes combinações de sensores ou excluir sensores com classificação baixa. Conclua as seguintes etapas:
- No Detalhes por sensor seção na página do conjunto de dados, selecione os sensores para incluir em seu modelo e escolha Criar modelo.

- Escolha Nome do modelo, insira um nome de modelo e escolha Próximo.

- No Configurações de treinamento e avaliação seção, configure os dados de entrada do modelo.
Para treinar efetivamente os modelos, os dados precisam ser divididos em conjuntos separados de treinamento e avaliação. Você pode definir intervalos de datas para esta divisão nesta seção, juntamente com uma taxa de amostragem para os sensores. Como você escolhe essa divisão? Considere o seguinte:
- O Lookout for Equipment espera pelo menos 3 meses de dados no intervalo de treinamento, mas a quantidade ideal de dados é determinada pelo seu caso de uso. Mais dados podem ser necessários para contabilizar qualquer tipo de sazonalidade ou ciclos operacionais pelos quais sua produção passa.
- Não há restrições no intervalo de avaliação. No entanto, recomendamos configurar um intervalo de avaliação que inclua anomalias conhecidas. Dessa forma, você pode testar se o Lookout for Equipment é capaz de capturar quaisquer eventos de interesse que levem a essas anomalias.
Ao especificar a taxa de amostragem, o Lookout for Equipment reduz efetivamente a amostragem dos dados do sensor, o que pode reduzir significativamente o tempo de treinamento. A taxa de amostragem ideal depende dos tipos de anomalias que você suspeita em seus dados: para anomalias de tendência lenta, selecionar uma taxa de amostragem entre 1 a 10 minutos geralmente é um bom ponto de partida. A escolha de valores mais baixos (aumento da taxa de amostragem) resulta em tempos de treinamento mais longos, enquanto valores mais altos (taxa de amostragem baixa) encurtam o tempo de treinamento com o risco de cortar os principais indicadores de seus dados relevantes para prever as anomalias.

Para treinar apenas em partes relevantes de seus dados onde o equipamento industrial estava em operação, você pode realizar a detecção de desligamento selecionando um sensor e definindo um limite indicando se o equipamento estava no estado ligado ou desligado. Isso é crítico porque permite que o Lookout for Equipment filtre os períodos de treinamento quando a máquina está desligada. Isso significa que o modelo aprende apenas estados operacionais relevantes e não apenas quando a máquina está desligada.
- Especifique sua detecção de folga e escolha Próximo.

Opcionalmente, você pode fornecer rótulos de dados, que indicam períodos de manutenção ou tempos conhecidos de falha do equipamento. Se você tiver esses dados disponíveis, poderá criar um arquivo CSV com os dados em um formato documentado, carregue-o no Amazon S3 e use-o para treinamento de modelo. Fornecer rótulos pode melhorar a precisão do modelo treinado informando ao Lookout for Equipment onde ele deve esperar encontrar anomalias conhecidas.
- Especifique quaisquer rótulos de dados e escolha Próximo.

- Revise suas configurações na etapa final. Se tudo estiver bem, você pode começar o treinamento.
Dependendo do tamanho do seu conjunto de dados, do número de sensores e da taxa de amostragem, o treinamento do modelo pode levar alguns instantes ou até algumas horas. Por exemplo, se você usar 1 ano de dados a uma taxa de amostragem de 5 minutos com 100 sensores e sem rótulos, o treinamento de um modelo levará menos de 15 minutos. Por outro lado, se seus dados contiverem um grande número de rótulos, o tempo de treinamento poderá aumentar significativamente. Em tal situação, você pode diminuir o tempo de treinamento mesclando períodos de etiquetas adjacentes para diminuir seu número.
Você acabou de treinar seu primeiro modelo de detecção de anomalias sem nenhum conhecimento de ML! Agora vamos ver os insights que você pode obter de um modelo treinado.
Avalie um modelo treinado
Quando o treinamento do modelo terminar, você poderá visualizar os detalhes do modelo escolhendo Ver modelos na página do projeto e, em seguida, escolhendo o nome do modelo.
Além de informações gerais como nome, status e tempo de treinamento, a página do modelo resume os dados de desempenho do modelo, como o número de eventos rotulados detectados (supondo que você forneceu rótulos), o tempo médio de aviso prévio e o número de eventos de equipamentos anômalos detectados fora do os intervalos de rótulos. A captura de tela a seguir mostra um exemplo. Para melhor visibilidade, os eventos detectados são visualizados (as barras vermelhas na parte superior da faixa de opções) juntamente com os eventos rotulados (as barras azuis na parte inferior da faixa de opções).

Você pode selecionar eventos detectados escolhendo as áreas vermelhas que representam anomalias na exibição da linha do tempo para obter informações adicionais. Isso inclui:
- Os horários de início e término do evento junto com sua duração.
- Um gráfico de barras com os sensores que o modelo acredita serem mais relevantes para a ocorrência de uma anomalia. As pontuações percentuais representam a contribuição geral calculada.

Esses insights permitem que você trabalhe com seus engenheiros de processo ou confiabilidade para fazer uma avaliação mais aprofundada da causa raiz dos eventos e, finalmente, otimizar as atividades de manutenção, reduzir paradas não planejadas e identificar condições operacionais abaixo do ideal.
Para oferecer suporte à manutenção preditiva com insights em tempo real (inferência), o Lookout for Equipment oferece suporte à avaliação ao vivo de dados online por meio de programações de inferência. Isso requer que os dados do sensor sejam carregados no Amazon S3 periodicamente e, em seguida, o Lookout for Equipment realize inferência nos dados com o modelo treinado, fornecendo pontuação de anomalia em tempo real. Os resultados da inferência, incluindo um histórico de eventos anômalos detectados, podem ser visualizados no console Lookout for Equipment.

Os resultados também são gravados em arquivos no Amazon S3, permitindo a integração com outros sistemas, por exemplo, um sistema computadorizado de gerenciamento de manutenção (CMMS), ou para notificar o pessoal de operações e manutenção em tempo real.
À medida que aumenta a adoção do Lookout for Equipment, você precisará gerenciar um número maior de modelos e programações de inferência. Para facilitar esse processo, o Cronogramas de inferência A página lista todos os planejadores atualmente configurados para um projeto em uma única exibição.

limpar
Quando terminar de avaliar o Lookout for Equipment, recomendamos a limpeza de todos os recursos. Você pode excluir o projeto Lookout for Equipment junto com o conjunto de dados e quaisquer modelos criados selecionando o projeto, escolhendo Apagar, e confirmando a ação.
Resumo
Nesta postagem, percorremos as etapas de ingestão de um conjunto de dados no Lookout for Equipment, treinando um modelo nele e avaliando seu desempenho para entender o valor que pode revelar para ativos individuais. Especificamente, exploramos como o Lookout for Equipment pode informar os processos de manutenção preditiva que resultam na redução do tempo de inatividade não planejado e maior OEE.
Se você acompanhou seus próprios dados e está animado com as perspectivas de usar o Lookout for Equipment, a próxima etapa é iniciar um projeto piloto, com o suporte de sua organização de TI, seus principais parceiros ou nossas equipes de serviços profissionais da AWS. Este piloto deve visar um número limitado de equipamentos industriais e, em seguida, escalar para eventualmente incluir todos os ativos no escopo da manutenção preditiva.
Sobre os autores
 Johann Fuchsl é arquiteto de soluções da Amazon Web Services. Ele orienta clientes corporativos no setor de manufatura na implementação de casos de uso de IA/ML, no design de arquiteturas de dados modernas e na criação de soluções nativas de nuvem que fornecem valor comercial tangível. Johann tem formação em matemática e modelagem quantitativa, que combina com 10 anos de experiência em TI. Fora do trabalho, ele gosta de passar tempo com sua família e estar na natureza.
Johann Fuchsl é arquiteto de soluções da Amazon Web Services. Ele orienta clientes corporativos no setor de manufatura na implementação de casos de uso de IA/ML, no design de arquiteturas de dados modernas e na criação de soluções nativas de nuvem que fornecem valor comercial tangível. Johann tem formação em matemática e modelagem quantitativa, que combina com 10 anos de experiência em TI. Fora do trabalho, ele gosta de passar tempo com sua família e estar na natureza.
 Michael Hoarau é um arquiteto de soluções especialista em IA/ML industrial da AWS que alterna entre cientista de dados e arquiteto de aprendizado de máquina, dependendo do momento. Ele é apaixonado por trazer o poder da IA/ML para os chãos de fábrica de seus clientes industriais e trabalhou em uma ampla variedade de casos de uso de ML, desde a detecção de anomalias até a qualidade preditiva do produto ou a otimização da fabricação. Quando não está ajudando os clientes a desenvolver as próximas melhores experiências de aprendizado de máquina, ele gosta de observar as estrelas, viajar ou tocar piano.
Michael Hoarau é um arquiteto de soluções especialista em IA/ML industrial da AWS que alterna entre cientista de dados e arquiteto de aprendizado de máquina, dependendo do momento. Ele é apaixonado por trazer o poder da IA/ML para os chãos de fábrica de seus clientes industriais e trabalhou em uma ampla variedade de casos de uso de ML, desde a detecção de anomalias até a qualidade preditiva do produto ou a otimização da fabricação. Quando não está ajudando os clientes a desenvolver as próximas melhores experiências de aprendizado de máquina, ele gosta de observar as estrelas, viajar ou tocar piano.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/enable-predictive-maintenance-for-line-of-business-users-with-amazon-lookout-for-equipment/

