Introdução
No Processamento de Linguagem Natural (PNL), o desenvolvimento de Grandes Modelos de Linguagem (LLMs) provou ser um empreendimento transformador e revolucionário. Esses modelos, equipados com parâmetros massivos e treinados em extensos conjuntos de dados, demonstraram proficiência sem precedentes em muitas tarefas de PNL. No entanto, os custos exorbitantes de treinar estes modelos a partir do zero levaram os investigadores a explorar estratégias alternativas. Uma estratégia pioneira que surgiu para aprimorar as capacidades dos Large Language Models (LLMs) é a fusão de conhecimento, um conceito explorado em profundidade no artigo de pesquisa intitulado Knowledge “Fusion of Large Language Models” de Wan, Huang, Cai, Quan e outros.
Reconhecendo a necessidade de abordar a redundância nas funcionalidades dos LLMs recentemente desenvolvidos, esta abordagem inovadora oferece uma solução atraente. O artigo investiga o intrincado processo de fusão do conhecimento de vários LLMs, apresentando um caminho promissor para refinar e ampliar o desempenho desses modelos de linguagem.
A ideia fundamental é combinar os pontos fortes e capacidades dos LLMs existentes, transcendendo as limitações dos modelos individuais. Ao mesclar LLMs pré-treinados existentes, podemos criar um modelo mais poderoso que supera os pontos fortes individuais de cada modelo de origem.

Índice
Compreendendo a fusão de conhecimento dos LLMs
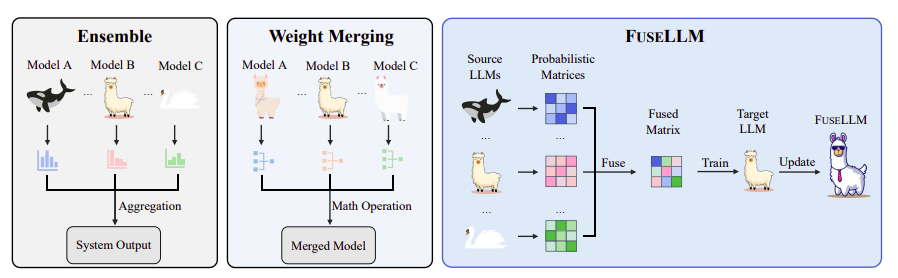
O artigo começa destacando os desafios e os custos da formação de LLMs a partir do zero. Os autores propõem a fusão do conhecimento como uma alternativa eficiente e econômica. Em vez de fundir os pesos diretamente, a abordagem centra-se na externalização do conhecimento coletivo dos LLMs de origem e na sua transferência para um modelo de destino. A pesquisa apresenta o FUSELLM, um método que aproveita as distribuições generativas de LLMs de origem, com o objetivo de aprimorar as capacidades do modelo alvo além de qualquer LLM de origem individual.
O objetivo principal da fusão de LLMs é externalizar o conhecimento inerente incorporado em LLMs de múltiplas fontes e integrar suas capacidades em um LLM alvo. O artigo enfatiza o estímulo aos LLMs para manifestar conhecimento, prevendo o próximo token em um determinado texto. As distribuições probabilísticas geradas por diferentes LLMs de origem para o mesmo texto são então fundidas em uma única representação, criando uma compreensão probabilística unificada sobre o texto.
Detalhes de implementação: estratégias de alinhamento e fusão de token
O artigo apresenta dois detalhes cruciais de implementação para garantir a fusão eficaz do conhecimento: alinhamento de tokens e estratégias de fusão.
O alinhamento de tokens é alcançado por meio de uma estratégia de Distância Mínima de Edição (MinED), aumentando a taxa de sucesso de alinhamento de tokens de diferentes LLMs.
As estratégias de fusão, nomeadamente MinCE e AvgCE, avaliam a qualidade de diferentes LLMs e atribuem vários níveis de importância às suas matrizes de distribuição com base em pontuações de entropia cruzada.
Experimentos e Avaliação
A pesquisa conduz experimentos em um cenário desafiador de fusão de LLMs, onde os modelos de origem apresentam pontos em comum mínimos. Três modelos representativos de código aberto – Lhama-2, OpenLLaMA e MPT – são selecionados como LLMs de origem para fusão, com outro Llama-2 servindo como LLM de destino. Os experimentos abrangem benchmarks que avaliam capacidades de raciocínio, bom senso e geração de código.
Desempenho em diferentes benchmarks
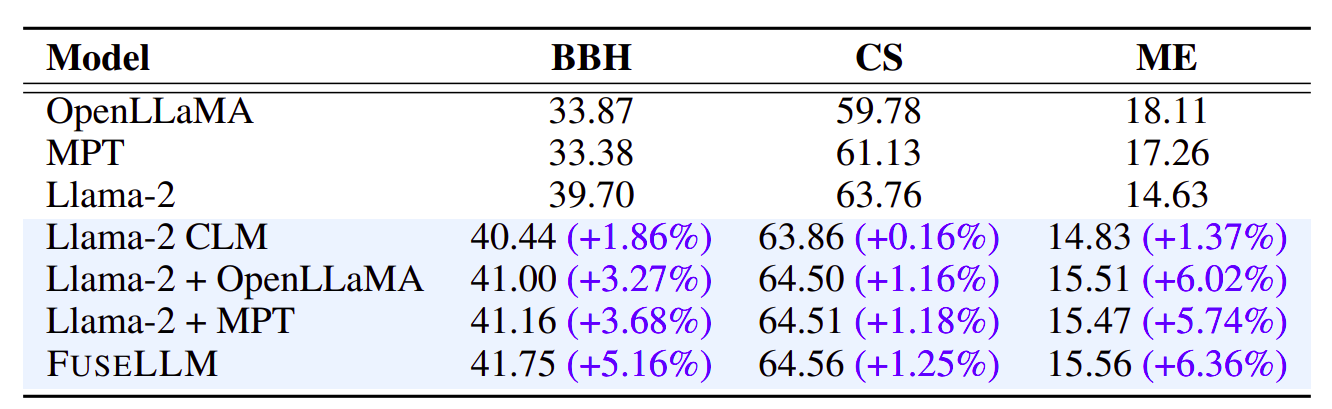
A avaliação abrangente do desempenho do FUSELLM em vários benchmarks fornece informações valiosas sobre a sua eficácia. A Tabela 1 mostra os resultados gerais do FUSELLM em comparação com os métodos de linha de base no Big-Bench Hard (BBH). Notavelmente, o FUSELLM demonstra um ganho relativo médio de desempenho de 5.16% em relação ao Llama-2 original em todas as 27 tarefas. As tarefas específicas, como Hyperbaton, apresentam melhorias substanciais, ressaltando a capacidade da FUSELLM de aproveitar o conhecimento coletivo para melhorar o desempenho.
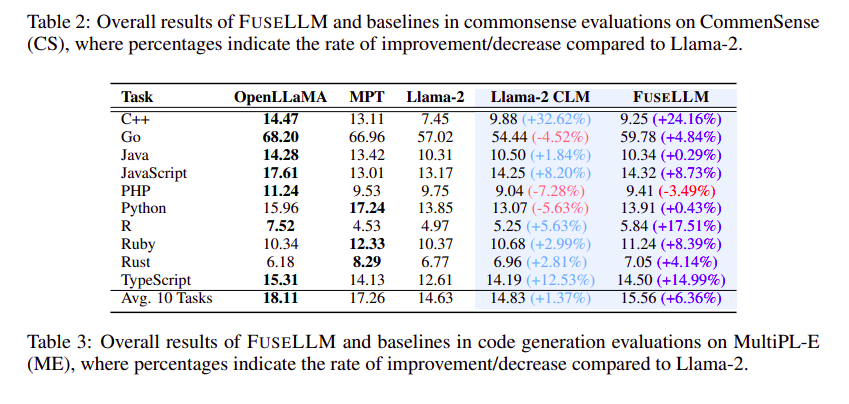
Passando para o benchmark Common Sense (CS) na Tabela 2, o FUSELLM supera consistentemente as linhas de base em todas as tarefas, alcançando uma melhoria relativa de desempenho de 1.25% em relação ao Llama-2. Esta tendência mantém-se mesmo em tarefas desafiadoras como ARC-challenge e OpenBookQA, onde o FUSELLM apresenta melhorias significativas, destacando a sua eficácia na resolução de problemas complexos.
No contexto da geração de código, a Tabela 3 ilustra o desempenho zero-shot do FUSELLM no benchmark MultiPL-E (ME). Superando o Llama-2 em 9 de 10 tarefas, o FUSELLM apresenta uma melhoria notável na pontuação pass@1, especialmente para linguagens de programação específicas como R. Apesar de uma lacuna de desempenho em comparação com OpenLLaMA ou MPT, o FUSELLM ainda alcança um notável ganho médio de desempenho de 6.36%, superando a melhoria de 1.37% observada no Llama-2 CLM.
As Distribuições Probabilísticas Fundidas: Acelerando a Otimização

Um aspecto crucial do sucesso do FUSELLM reside na sua capacidade de utilizar distribuições probabilísticas fundidas de múltiplos LLMs. A Figura 2 compara o desempenho da Cadeia de Pensamento (CoT) de poucos disparos entre Llama-2 CLM e FUSELLM com escalas variadas de dados de treinamento no BBH. O FUSELLM aumenta significativamente a precisão da correspondência exata (EM) em 2.5%, alcançando o melhor desempenho do Llama-2 CLM em 0.52 bilhão de tokens. Isso representa uma redução de 3.9x nos requisitos de token em comparação com o Llama-2 CLM, indicando que as distribuições probabilísticas derivadas dos LLMs contêm conhecimento mais facilmente aprendível do que as sequências de texto originais, acelerando assim o processo de otimização.
Análise do Processo de Implementação
A análise dos detalhes da implementação do FUSELLM revela considerações críticas para o seu sucesso. O número de LLMs de origem, os critérios de alinhamento de tokens e a escolha da função de fusão desempenham papéis essenciais na definição do desempenho do FUSELLM.
- Número de LLMs de origem: A Tabela 4 demonstra a melhoria de desempenho do FUSELLM com vários números de modelos. Os resultados mostram uma aparente melhoria à medida que o número de modelos aumenta de 1 para 3, com melhorias consistentes observadas no BBH.
- Critérios para alinhamento de token: O alinhamento adequado do token é crucial durante a fusão de LLMs. O método MinED proposto supera consistentemente o método EM, mostrando a eficácia do MinED no alinhamento de tokens de vários modelos.
- Função de fusão: A escolha da função de fusão é crítica e o FUSELLM com MinCE supera consistentemente o AvgCE em todos os benchmarks. Isto enfatiza a importância da função de fusão na preservação das vantagens distintas dos LLMs individuais.
FUSELLM vs. Destilação e conjunto/fusão de conhecimento
Análises comparativas com técnicas tradicionais como destilação de conhecimento e conjunto/fusão lançam luz sobre os pontos fortes únicos da FUSELLM.
- FUSELLM vs. Destilação de Conhecimento: A FUSELLM supera a destilação de conhecimento, especialmente em BBH, onde a melhoria alcançada pela FUSELLM (5.16%) supera o modesto ganho da destilação de conhecimento (2.97%). Isto destaca a capacidade da FUSELLM de aproveitar o conhecimento coletivo de vários LLMs de forma mais eficaz.
- FUSELLM vs. Conjunto/Fusão: Em cenários onde vários LLMs se originaram do mesmo modelo base, mas foram treinados em corpora distintos, o FUSELLM atinge consistentemente a perplexidade média mais baixa em três domínios em comparação com os métodos de combinação de conjuntos e pesos. Isto reforça o potencial do FUSELLM para alavancar o conhecimento coletivo de forma mais eficaz do que os métodos tradicionais de fusão.
Você pode encontrar o código, pesos do modelo e dados públicos aqui: GitHub FUSELLM

Conclusão: revelando possibilidades futuras
O artigo conclui com resultados convincentes, mostrando a eficácia do FUSELLM em relação aos LLMs de fontes individuais e às linhas de base estabelecidas. O estudo abre um caminho promissor para exploração futura na fusão de LLMs. As descobertas enfatizam o potencial de combinar as diversas capacidades e pontos fortes de LLMs estruturalmente diferentes, lançando luz sobre uma abordagem poderosa e econômica para o desenvolvimento de grandes modelos de linguagem.
A fusão do conhecimento de grandes modelos linguísticos é uma solução inovadora num mundo onde a procura por capacidades avançadas de processamento de linguagem natural continua a aumentar. Esta pesquisa abre caminho para esforços futuros na criação de modelos unificados que aproveitem a inteligência coletiva de diversos LLMs, ampliando os limites do que é alcançável no domínio da compreensão e geração de linguagem natural.
Estou ansioso para saber suas opiniões sobre a fusão de conhecimento de modelos de grandes linguagens (LLMs). Sinta-se à vontade para compartilhar suas idéias sobre quaisquer outros artigos notáveis e informativos que você possa ter encontrado na seção de comentários.
Veja também: Um guia abrangente para o ajuste fino de modelos de linguagem grandes
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/02/knowledge-fusion-of-large-language-models-llms/

