Fluxo de trabalho gerenciado da Amazon para Apache Airflow (Amazon MWAA) é um serviço gerenciado que permite usar um ambiente familiar Fluxo de ar Apache ambiente com escalabilidade, disponibilidade e segurança aprimoradas para aprimorar e dimensionar seus fluxos de trabalho de negócios sem a carga operacional de gerenciar a infraestrutura subjacente. No fluxo de ar, Gráficos Acíclicos Dirigidos (DAGs) são definidos como código Python. DAGs dinâmicos referem-se à capacidade de gerar DAGs dinamicamente durante o tempo de execução, normalmente com base em algumas condições, configurações ou parâmetros externos. Os DAGs dinâmicos ajudam você a criar, agendar e executar tarefas em um DAG com base em dados e configurações que podem mudar com o tempo.
Existem várias maneiras de introduzir dinamismo nos DAGs do Airflow (geração dinâmica de DAG) usando variáveis de ambiente e arquivos externos. Uma das abordagens é usar o Fábrica DAG Método de arquivo de configuração baseado em YAML. Esta biblioteca tem como objetivo facilitar a criação e configuração de novos DAGs utilizando parâmetros declarativos em YAML. Permite personalizações padrão e é de código aberto, simplificando a criação e customização de novas funcionalidades.
Neste post, exploramos o processo de criação de DAGs dinâmicos com arquivos YAML, usando o Fábrica DAG biblioteca. DAGs dinâmicos oferecem vários benefícios:
- Reutilização aprimorada de código – Ao estruturar DAGs por meio de arquivos YAML, promovemos componentes reutilizáveis, reduzindo a redundância nas definições do seu fluxo de trabalho.
- Manutenção simplificada – A geração de DAG baseada em YAML simplifica o processo de modificação e atualização de fluxos de trabalho, garantindo procedimentos de manutenção mais suaves.
- Parametrização flexível – Com o YAML, você pode parametrizar configurações de DAG, facilitando ajustes dinâmicos em fluxos de trabalho com base em requisitos variados.
- Eficiência aprimorada do agendador – DAGs dinâmicos permitem agendamento mais eficiente, otimizando a alocação de recursos e melhorando a execução geral do fluxo de trabalho
- Escalabilidade aprimorada – Os DAGs orientados por YAML permitem execuções paralelas, permitindo fluxos de trabalho escalonáveis capazes de lidar com cargas de trabalho maiores com eficiência.
Ao aproveitar o poder dos arquivos YAML e da biblioteca DAG Factory, oferecemos uma abordagem versátil para criar e gerenciar DAGs, capacitando você a criar pipelines de dados robustos, escaláveis e de fácil manutenção.
Visão geral da solução
Nesta postagem, usaremos um exemplo de arquivo DAG projetado para processar um conjunto de dados COVID-19. O processo de fluxo de trabalho envolve o processamento de um conjunto de dados de código aberto oferecido por OMS-COVID-19-Global. Depois de instalarmos o DAG-Fábrica Pacote Python, criamos um arquivo YAML que contém definições de várias tarefas. Processamos a contagem de mortes específica do país, passando Country como uma variável, que cria DAGs individuais baseados em países.
O diagrama a seguir ilustra a solução geral juntamente com os fluxos de dados dentro de blocos lógicos.

Pré-requisitos
Para este passo a passo, você deve ter os seguintes pré-requisitos:
Além disso, conclua as etapas a seguir (execute a configuração em um Região AWS onde o Amazon MWAA está disponível):
- Crie uma Ambiente Amazon MWAA (se você ainda não tiver um). Se esta for a primeira vez que você usa o Amazon MWAA, consulte Apresentando os fluxos de trabalho gerenciados da Amazon para Apache Airflow (MWAA).
Verifique se o Gerenciamento de acesso e identidade da AWS O usuário ou função (IAM) usado para configurar o ambiente tem políticas do IAM anexadas para as seguintes permissões:
As políticas de acesso mencionadas aqui são apenas para exemplo neste post. Em um ambiente de produção, forneça apenas as permissões granulares necessárias exercendo princípios de menor privilégio.
- Crie um nome de bucket do Amazon S3 exclusivo (dentro de uma conta) ao criar seu ambiente Amazon MWAA e crie pastas chamadas
dagserequirements.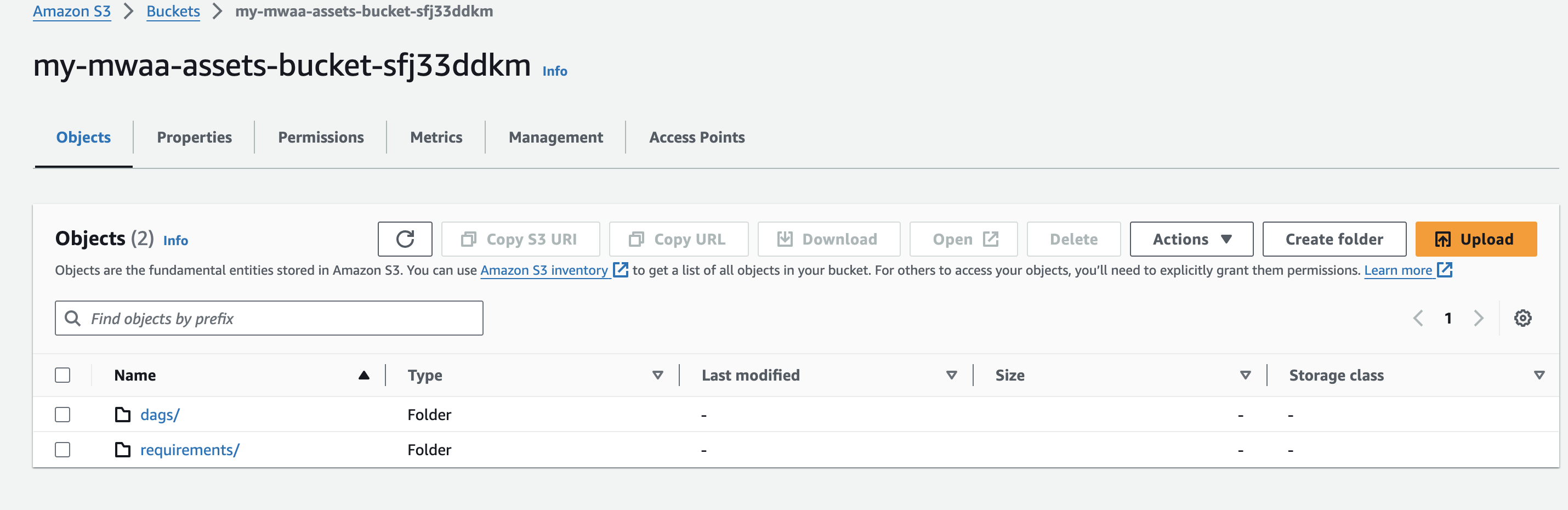
- Crie e carregue um
requirements.txtarquivo com o seguinte conteúdo para orequirementspasta. Substituir{environment-version}com o número da versão do seu ambiente e{Python-version}com a versão do Python compatível com seu ambiente:
O Pandas é necessário apenas para o exemplo de caso de uso descrito nesta postagem, e dag-factory é o único plug-in necessário. Recomenda-se verificar a compatibilidade da versão mais recente do dag-factory com Amazon MWAA. O boto e psycopg2-binary bibliotecas estão incluídas na instalação básica do Apache Airflow v2 e não precisam ser especificadas em seu requirements.txt arquivo.
- Faça o download do Arquivo de dados globais da OMS-COVID-19 para sua máquina local e carregue-o sob o
dagsprefixo do seu bucket S3.
Certifique-se de estar apontando para a versão mais recente do bucket AWS S3 do seu requirements.txt arquivo para que a instalação do pacote adicional aconteça. Isso normalmente deve levar de 15 a 20 minutos, dependendo da configuração do seu ambiente.
Valide os DAGs
Quando o ambiente do Amazon MWAA é exibido como Disponível no console do Amazon MWAA, navegue até a UI do Airflow escolhendo Abra a IU do Airflow próximo ao seu ambiente.

Verifique os DAGs existentes navegando até a guia DAGs.
Configure seus DAGs
Conclua as seguintes etapas:
- Crie arquivos vazios nomeados
dynamic_dags.yml,example_dag_factory.pyeprocess_s3_data.pyem sua máquina local. - Edite o
process_s3_data.pyarquivo e salve-o com o seguinte conteúdo de código e, em seguida, carregue o arquivo de volta para o bucket do Amazon S3dagspasta. Estamos fazendo algum processamento básico de dados no código:- Leia o arquivo em um local do Amazon S3
- Renomeie o
Country_codecoluna conforme apropriado ao país. - Filtre os dados por determinado país.
- Escreva os dados finais processados no formato CSV e faça upload de volta para o prefixo S3.
- Edite o
dynamic_dags.ymle salve-o com o seguinte conteúdo de código e, em seguida, carregue o arquivo de volta para odagspasta. Estamos costurando vários DAGs com base no país da seguinte forma:- Defina os argumentos padrão que são passados para todos os DAGs.
- Crie uma definição de DAG para países individuais passando
op_args - Mapeie o
process_s3_datafuncionar compython_callable_name. - Use Operador Python para processar dados de arquivo csv armazenados no bucket do Amazon S3.
- Nós definimos
schedule_intervalcomo 10 minutos, mas sinta-se à vontade para ajustar esse valor conforme necessário.
- Edite o arquivo
example_dag_factory.pye salve-o com o seguinte conteúdo de código e, em seguida, carregue o arquivo de volta paradagspasta. O código limpa os DAGs existentes e geraclean_dags()método e a criação de novos DAGs usando ogenerate_dags()método doDagFactoryinstância.
- Depois de fazer upload dos arquivos, volte para o console da UI do Airflow e navegue até a guia DAGs, onde você encontrará novos DAGs.
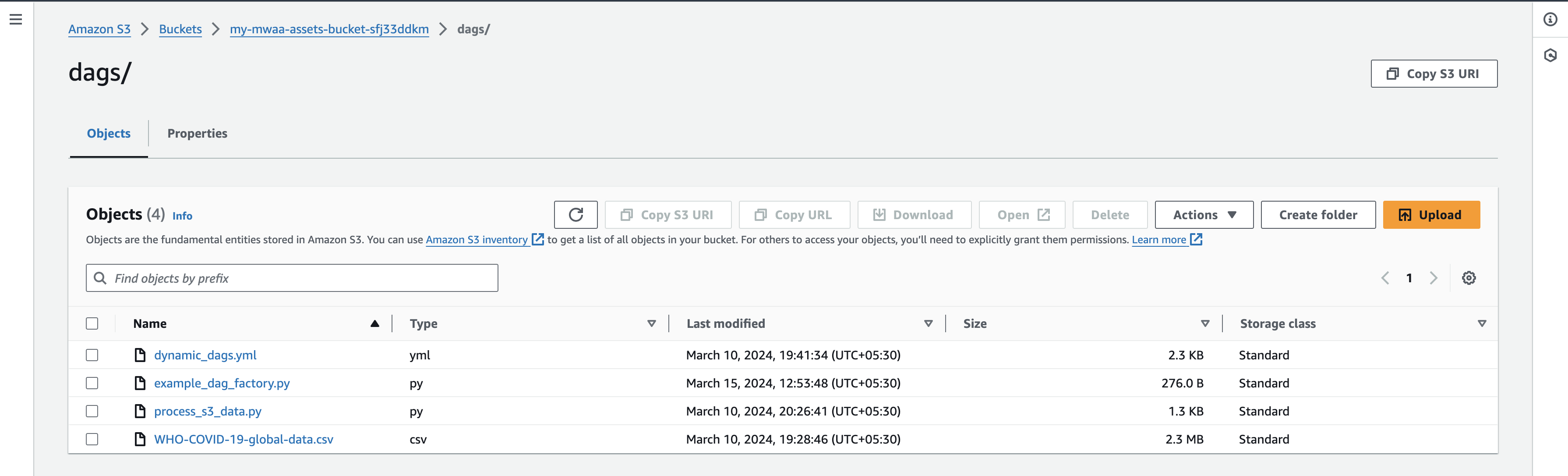
- Depois de fazer upload dos arquivos, volte para o console da interface do Airflow e na guia DAGs você encontrará novos DAGs aparecendo conforme mostrado abaixo:

Você pode habilitar DAGs ativando-os e testando-os individualmente. Após a ativação, um arquivo CSV adicional chamado count_death_{COUNTRY_CODE}.csv é gerado na pasta dags.
Limpando
Pode haver custos associados ao uso dos vários serviços da AWS discutidos nesta postagem. Para evitar cobranças futuras, exclua o ambiente Amazon MWAA depois de concluir as tarefas descritas nesta postagem e esvazie e exclua o bucket S3.
Conclusão
Nesta postagem do blog demonstramos como usar o fábrica dag biblioteca para criar DAGs dinâmicos. Os DAGs dinâmicos são caracterizados pela capacidade de gerar resultados com cada análise do arquivo DAG com base nas configurações. Considere usar DAGs dinâmicos nos seguintes cenários:
- Automatizando a migração de um sistema legado para o Airflow, onde a flexibilidade na geração de DAG é crucial
- Situações onde apenas um parâmetro muda entre diferentes DAGs, agilizando o processo de gestão do fluxo de trabalho
- Gerenciar DAGs que dependem da estrutura em evolução de um sistema de origem, proporcionando adaptabilidade às mudanças
- Estabelecer práticas padronizadas para DAGs em toda a sua equipe ou organização, criando esses modelos, promovendo consistência e eficiência
- Adotando declarações baseadas em YAML em vez de codificação Python complexa, simplificando processos de configuração e manutenção de DAG
- Criação de fluxos de trabalho orientados por dados que se adaptam e evoluem com base nas entradas de dados, permitindo uma automação eficiente
Ao incorporar DAGs dinâmicos ao seu fluxo de trabalho, você pode aprimorar a automação, a adaptabilidade e a padronização, melhorando, em última análise, a eficiência e a eficácia do gerenciamento do pipeline de dados.
Para saber mais sobre a Amazon MWAA DAG Factory, visite Workshop Amazon MWAA para Analytics: DAG Factory. Para obter detalhes adicionais e exemplos de código no Amazon MWAA, visite o Guia do usuário do Amazon MWAA e os votos de Exemplos do Amazon MWAA GitHub repositório.
Sobre os autores
 Jayesh Shinde é arquiteto de aplicativos sênior da AWS ProServe Índia. Ele é especialista na criação de várias soluções centradas na nuvem usando práticas modernas de desenvolvimento de software, como serverless, DevOps e análises.
Jayesh Shinde é arquiteto de aplicativos sênior da AWS ProServe Índia. Ele é especialista na criação de várias soluções centradas na nuvem usando práticas modernas de desenvolvimento de software, como serverless, DevOps e análises.
 Dura Yeola é arquiteto sênior de nuvem da AWS ProServe Índia, ajudando clientes a migrar e modernizar sua infraestrutura para a AWS. Ele é especialista na construção de DevSecOps e infraestrutura escalonável usando contêineres, AIOPs e ferramentas e serviços para desenvolvedores da AWS.
Dura Yeola é arquiteto sênior de nuvem da AWS ProServe Índia, ajudando clientes a migrar e modernizar sua infraestrutura para a AWS. Ele é especialista na construção de DevSecOps e infraestrutura escalonável usando contêineres, AIOPs e ferramentas e serviços para desenvolvedores da AWS.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/dynamic-dag-generation-with-yaml-and-dag-factory-in-amazon-mwaa/

