Esta postagem foi escrita em colaboração com Pramod Nayak, LakshmiKanth Mannem e Vivek Aggarwal do Grupo de Baixa Latência do LSEG.
A análise de custos de transação (TCA) é amplamente utilizada por traders, gestores de carteiras e corretores para análises pré e pós-negociação e os ajuda a medir e otimizar os custos de transação e a eficácia de suas estratégias de negociação. Neste post, analisamos spreads de compra e venda de opções do Histórico de ticks LSEG – PCAP conjunto de dados usando Amazon Athena para Apache Spark. Mostramos como acessar dados, definir funções customizadas para aplicar aos dados, consultar e filtrar o conjunto de dados e visualizar os resultados da análise, tudo sem se preocupar em configurar a infraestrutura ou configurar o Spark, mesmo para grandes conjuntos de dados.
BACKGROUND
A Options Price Reporting Authority (OPRA) atua como um processador crucial de informações de títulos, coletando, consolidando e divulgando relatórios de última venda, cotações e informações pertinentes para opções dos EUA. Com 18 bolsas de opções ativas nos EUA e mais de 1.5 milhão de contratos elegíveis, a OPRA desempenha um papel fundamental no fornecimento de dados de mercado abrangentes.
Em 5 de fevereiro de 2024, a Securities Industry Automation Corporation (SIAC) deverá atualizar o feed OPRA de 48 para 96 canais multicast. Esta melhoria visa otimizar a distribuição de símbolos e a utilização da capacidade de linha em resposta à escalada da atividade comercial e à volatilidade no mercado de opções dos EUA. A SIAC recomendou que as empresas se preparem para taxas de dados máximas de até 37.3 GBits por segundo.
Apesar da atualização não alterar imediatamente o volume total de dados publicados, permite à OPRA divulgar dados a um ritmo significativamente mais rápido. Esta transição é crucial para responder às exigências do dinâmico mercado de opções.
OPRA se destaca como um dos feeds mais volumosos, com um pico de 150.4 bilhões de mensagens em um único dia no terceiro trimestre de 3 e um requisito de capacidade de 2023 bilhões de mensagens em um único dia. Capturar cada mensagem é fundamental para análise de custos de transação, monitoramento de liquidez de mercado, avaliação de estratégia comercial e pesquisa de mercado.
Sobre os dados
Histórico de ticks LSEG – PCAP é um repositório baseado em nuvem, superior a 30 PB, que abriga dados de mercado global de altíssima qualidade. Esses dados são meticulosamente capturados diretamente nos data centers de exchanges, empregando processos de captura redundantes estrategicamente posicionados nos principais data centers primários e de backup de exchanges em todo o mundo. A tecnologia de captura do LSEG garante captura de dados sem perdas e usa uma fonte de tempo GPS para precisão de carimbo de data e hora em nanossegundos. Além disso, técnicas sofisticadas de arbitragem de dados são empregadas para preencher perfeitamente quaisquer lacunas de dados. Após a captura, os dados passam por processamento e arbitragem meticulosos e são então normalizados no formato Parquet usando Ultra direto em tempo real da LSEG (RTUD) manipuladores de alimentação.
O processo de normalização, que é essencial para preparar os dados para análise, gera até 6 TB de arquivos Parquet compactados por dia. O enorme volume de dados é atribuído à natureza abrangente da OPRA, abrangendo múltiplas bolsas e apresentando numerosos contratos de opções caracterizados por diversos atributos. O aumento da volatilidade do mercado e da atividade de criação de mercado nas bolsas de opções contribuem ainda mais para o volume de dados publicados na OPRA.
Os atributos do Tick History – PCAP permitem que as empresas conduzam diversas análises, incluindo as seguintes:
- Análise pré-negociação – Avalie o potencial impacto comercial e explore diferentes estratégias de execução com base em dados históricos
- Avaliação pós-negociação – Medir os custos reais de execução em relação aos benchmarks para avaliar o desempenho das estratégias de execução
- Otimizado execução – Ajustar estratégias de execução com base em padrões históricos de mercado para minimizar o impacto no mercado e reduzir os custos gerais de negociação
- Gestão de riscos – Identifique padrões de derrapagem, identifique valores discrepantes e gerencie proativamente os riscos associados às atividades de negociação
- Atribuição de desempenho – Separar o impacto das decisões de negociação das decisões de investimento ao analisar o desempenho do portfólio
O conjunto de dados LSEG Tick History – PCAP está disponível em Troca de dados da AWS e pode ser acessado em Mercado da AWS. Com AWS Data Exchange para Amazon S3, você pode acessar dados PCAP diretamente do LSEG Serviço de armazenamento simples da Amazon (Amazon S3), eliminando a necessidade de as empresas armazenarem sua própria cópia dos dados. Essa abordagem simplifica o gerenciamento e o armazenamento de dados, proporcionando aos clientes acesso imediato a PCAP de alta qualidade ou dados normalizados com facilidade de uso, integração e economias substanciais de armazenamento de dados.
Atenas para Apache Spark
Para esforços analíticos, Atenas para Apache Spark oferece uma experiência simplificada de notebook acessível por meio do console do Athena ou das APIs do Athena, permitindo criar aplicativos Apache Spark interativos. Com um tempo de execução otimizado do Spark, o Athena ajuda na análise de petabytes de dados ao dimensionar dinamicamente o número de mecanismos Spark em menos de um segundo. Além disso, bibliotecas Python comuns, como pandas e NumPy, são perfeitamente integradas, permitindo a criação de lógica de aplicação complexa. A flexibilidade se estende à importação de bibliotecas customizadas para uso em notebooks. O Athena for Spark acomoda a maioria dos formatos de dados abertos e é perfeitamente integrado ao Cola AWS Catálogo de Dados.
Conjunto de dados
Para esta análise, utilizamos o conjunto de dados LSEG Tick History – PCAP OPRA de 17 de maio de 2023. Este conjunto de dados compreende os seguintes componentes:
- Melhor lance e oferta (BBO) – Informa o lance mais alto e o pedido mais baixo de um título em uma determinada bolsa
- Melhor lance e oferta nacional (NBBO) – Informa o lance mais alto e o pedido mais baixo de um título em todas as exchanges
- Comércio – Registra negociações concluídas em todas as bolsas
O conjunto de dados envolve os seguintes volumes de dados:
- Comércio – 160 MB distribuídos em aproximadamente 60 arquivos Parquet compactados
- BBO – 2.4 TB distribuídos em aproximadamente 300 arquivos Parquet compactados
- NBBO – 2.8 TB distribuídos em aproximadamente 200 arquivos Parquet compactados
Visão geral da análise
A análise dos dados do histórico de ticks do OPRA para análise de custos de transação (TCA) envolve o exame minucioso de cotações de mercado e negociações em torno de um evento comercial específico. Usamos as seguintes métricas como parte deste estudo:
- Spread cotado (QS) – Calculado como a diferença entre o pedido do BBO e o lance do BBO
- Propagação efetiva (ES) – Calculado como a diferença entre o preço de negociação e o ponto médio do BBO (BBO bid + (BBO ask – BBO bid)/2)
- Spread efetivo/cotado (EQF) – Calculado como (ES/QS) * 100
Calculamos esses spreads antes da negociação e, adicionalmente, em quatro intervalos após a negociação (logo após, 1 segundo, 10 segundos e 60 segundos após a negociação).
Configurar o Athena para Apache Spark
Para configurar o Athena para Apache Spark, conclua as seguintes etapas:
- No console Athena, em COMECE AGORA, selecione Analise seus dados usando PySpark e Spark SQL.
- Se esta for a primeira vez que você usa o Athena Spark, escolha Criar grupo de trabalho.

- Escolha Nome do grupo de trabalho¸ insira um nome para o grupo de trabalho, como
tca-analysis. - No Mecanismo de análise seção, selecione Apache Spark.
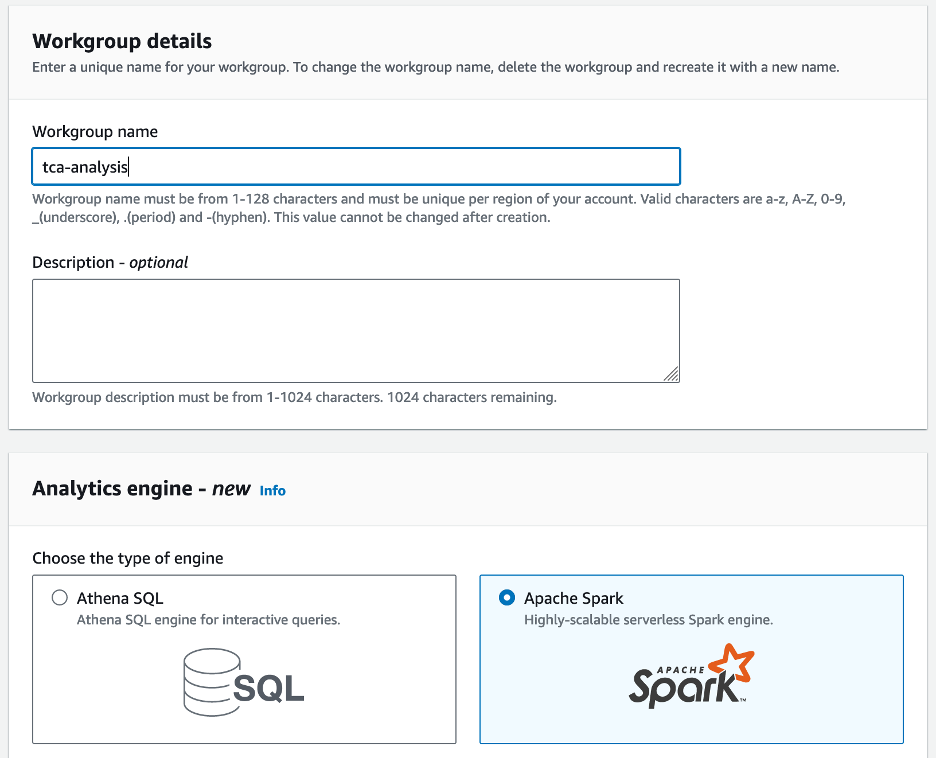
- No Configurações adicionais seção, você pode escolher Use padrões ou fornecer um personalizado Gerenciamento de acesso e identidade da AWS (IAM) e localização do Amazon S3 para resultados de cálculo.
- Escolha Criar grupo de trabalho.
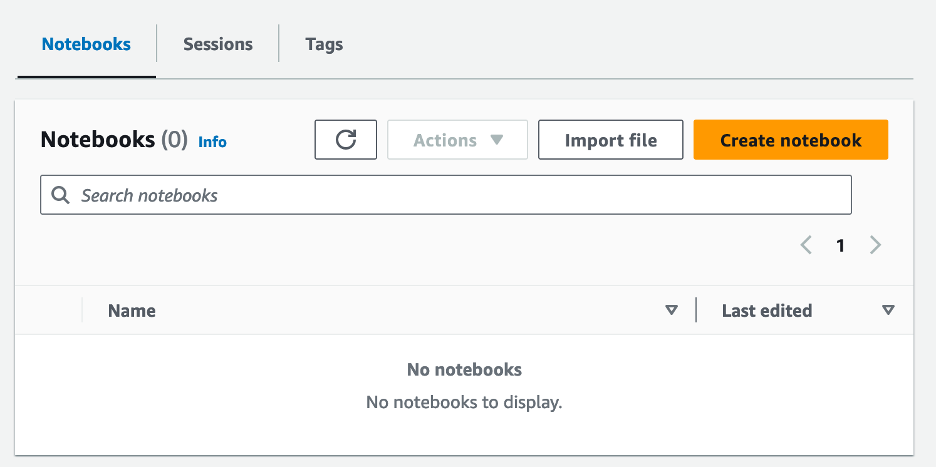
- Depois de criar o grupo de trabalho, navegue até o Notebooks aba e escolha Criar caderno.
- Digite um nome para o seu notebook, como
tca-analysis-with-tick-history. - Escolha Crie para criar seu caderno.
Inicie seu notebook
Se você já criou um grupo de trabalho Spark, selecione Iniciar editor de notebook para COMECE AGORA.
![]()
Depois que seu notebook for criado, você será redirecionado para o editor de notebook interativo.
![]()
Agora podemos adicionar e executar o seguinte código em nosso notebook.
Crie uma análise
Conclua as etapas a seguir para criar uma análise:
- Importe bibliotecas comuns:
- Crie nossos quadros de dados para BBO, NBBO e negociações:
- Agora podemos identificar uma negociação a ser usada para análise de custos de transação:
Obtemos a seguinte saída:
Usamos as informações comerciais destacadas daqui para frente para o produto comercial (tp), preço comercial (tpr) e tempo de negociação (tt).
- Aqui criamos uma série de funções auxiliares para nossa análise
- Na função a seguir, criamos o conjunto de dados que contém todas as cotações antes e depois da negociação. O Athena Spark determina automaticamente quantas DPUs serão iniciadas para processar nosso conjunto de dados.
- Agora vamos chamar a função de análise do TCA com as informações da nossa negociação selecionada:
Visualize os resultados da análise
Agora vamos criar os quadros de dados que usaremos para nossa visualização. Cada quadro de dados contém cotações para um dos cinco intervalos de tempo para cada feed de dados (BBO, NBBO):
Nas seções a seguir, fornecemos código de exemplo para criar diferentes visualizações.
Traçar QS e NBBO antes da negociação
Use o código a seguir para traçar o spread cotado e o NBBO antes da negociação:
![]()
Trace QS para cada mercado e NBBO após a negociação
Use o código a seguir para traçar o spread cotado para cada mercado e NBBO imediatamente após a negociação:
![]()
Plote QS para cada intervalo de tempo e cada mercado para BBO
Use o código a seguir para traçar o spread cotado para cada intervalo de tempo e cada mercado para BBO:
![]()
Plotar ES para cada intervalo de tempo e mercado para BBO
Use o código a seguir para traçar o spread efetivo para cada intervalo de tempo e mercado para BBO:
Plote o EQF para cada intervalo de tempo e mercado para BBO
Use o código a seguir para traçar o spread efetivo/cotado para cada intervalo de tempo e mercado para BBO:
Desempenho de cálculo do Athena Spark
Quando você executa um bloco de código, o Athena Spark determina automaticamente quantas DPUs são necessárias para concluir o cálculo. No último bloco de código, onde chamamos o tca_analysis função, na verdade estamos instruindo o Spark a processar os dados e, em seguida, convertemos os dataframes resultantes do Spark em dataframes Pandas. Isso constitui a parte de processamento mais intensivo da análise e, quando o Athena Spark executa esse bloco, ele mostra a barra de progresso, o tempo decorrido e quantas DPUs estão processando dados no momento. Por exemplo, no cálculo a seguir, o Athena Spark utiliza 18 DPUs.
![]()
Ao configurar seu notebook Athena Spark, você tem a opção de definir o número máximo de DPUs que ele pode usar. O padrão é 20 DPUs, mas testamos esse cálculo com 10, 20 e 40 DPUs para demonstrar como o Athena Spark é dimensionado automaticamente para executar nossa análise. Observamos que o Athena Spark é dimensionado linearmente, levando 15 minutos e 21 segundos quando o notebook foi configurado com no máximo 10 DPUs, 8 minutos e 23 segundos quando o notebook foi configurado com 20 DPUs e 4 minutos e 44 segundos quando o notebook foi configurado com 40 DPUs. Como o Athena Spark cobra com base no uso de DPU, com granularidade por segundo, o custo desses cálculos é semelhante, mas se você definir um valor máximo de DPU mais alto, o Athena Spark poderá retornar o resultado da análise com muito mais rapidez. Para obter mais detalhes sobre os preços do Athena Spark, clique SUA PARTICIPAÇÃO FAZ A DIFERENÇA.
Conclusão
Nesta postagem, demonstramos como você pode usar dados OPRA de alta fidelidade do Tick History-PCAP da LSEG para realizar análises de custos de transação usando Athena Spark. A disponibilidade oportuna de dados OPRA, complementada com inovações de acessibilidade do AWS Data Exchange para Amazon S3, reduz estrategicamente o tempo de análise para empresas que buscam criar insights acionáveis para decisões comerciais críticas. A OPRA gera cerca de 7 TB de dados normalizados do Parquet todos os dias, e gerenciar a infraestrutura para fornecer análises baseadas em dados da OPRA é um desafio.
A escalabilidade do Athena no processamento de dados em larga escala para Tick History – PCAP para dados OPRA o torna uma escolha atraente para organizações que buscam soluções analíticas rápidas e escaláveis na AWS. Esta postagem mostra a interação perfeita entre o ecossistema AWS e os dados Tick History-PCAP e como as instituições financeiras podem aproveitar essa sinergia para impulsionar a tomada de decisões baseada em dados para estratégias críticas de negociação e investimento.
Sobre os autores
![]() Pramod Nayak é o Diretor de Gestão de Produtos do Grupo de Baixa Latência da LSEG. Pramod tem mais de 10 anos de experiência no setor de tecnologia financeira, com foco em desenvolvimento de software, análise e gerenciamento de dados. Pramod é ex-engenheiro de software e apaixonado por dados de mercado e negociação quantitativa.
Pramod Nayak é o Diretor de Gestão de Produtos do Grupo de Baixa Latência da LSEG. Pramod tem mais de 10 anos de experiência no setor de tecnologia financeira, com foco em desenvolvimento de software, análise e gerenciamento de dados. Pramod é ex-engenheiro de software e apaixonado por dados de mercado e negociação quantitativa.
![]() Lakshmi, Kanth Mannem é Gerente de Produto no Grupo de Baixa Latência do LSEG. Ele se concentra em produtos de dados e plataformas para o setor de dados de mercado de baixa latência. LakshmiKanth ajuda os clientes a construir as soluções mais ideais para suas necessidades de dados de mercado.
Lakshmi, Kanth Mannem é Gerente de Produto no Grupo de Baixa Latência do LSEG. Ele se concentra em produtos de dados e plataformas para o setor de dados de mercado de baixa latência. LakshmiKanth ajuda os clientes a construir as soluções mais ideais para suas necessidades de dados de mercado.
![]() Vivek Aggarwal é Engenheiro de Dados Sênior no Grupo de Baixa Latência do LSEG. Vivek trabalha no desenvolvimento e manutenção de pipelines de dados para processamento e entrega de feeds de dados de mercado capturados e feeds de dados de referência.
Vivek Aggarwal é Engenheiro de Dados Sênior no Grupo de Baixa Latência do LSEG. Vivek trabalha no desenvolvimento e manutenção de pipelines de dados para processamento e entrega de feeds de dados de mercado capturados e feeds de dados de referência.
![]() Alket Memushaj é arquiteto principal da equipe de desenvolvimento de mercado de serviços financeiros da AWS. Alket é responsável pela estratégia técnica, trabalhando com parceiros e clientes para implantar até mesmo as cargas de trabalho mais exigentes do mercado de capitais na Nuvem AWS.
Alket Memushaj é arquiteto principal da equipe de desenvolvimento de mercado de serviços financeiros da AWS. Alket é responsável pela estratégia técnica, trabalhando com parceiros e clientes para implantar até mesmo as cargas de trabalho mais exigentes do mercado de capitais na Nuvem AWS.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/

