À medida que as empresas se expandem, a procura de endereços IP na rede corporativa excede frequentemente a oferta. A rede de uma organização é muitas vezes concebida com alguma antecipação de requisitos futuros, mas à medida que as empresas evoluem, as suas necessidades de tecnologia de informação (TI) ultrapassam a rede anteriormente concebida. As empresas podem enfrentar o desafio de gerenciar o conjunto limitado de endereços IP.
Para cargas de trabalho de engenharia de dados quando Cola AWS é usado em uma configuração de rede tão restrita, sua equipe às vezes pode enfrentar obstáculos ao executar muitos trabalhos simultaneamente. Isso acontece porque talvez você não tenha endereços IP suficientes para suportar as conexões necessárias aos bancos de dados. Para superar essa escassez, a equipe pode obter mais endereços IP do pool de redes corporativas. Esses endereços IP obtidos podem ser únicos (não sobrepostos) ou sobrepostos, quando os endereços IP são reutilizados em sua rede corporativa.
Ao usar endereços IP sobrepostos, você precisa de um gerenciamento de rede adicional para estabelecer conectividade. As soluções de rede podem incluir opções como gateways privados de tradução de endereços de rede (NAT), AWS PrivateLinkou dispositivos NAT autogerenciados para traduzir endereços IP.
Nesta postagem, discutiremos duas estratégias para dimensionar trabalhos do AWS Glue:
- Otimizando o consumo de endereços IP dimensionando corretamente as unidades de processamento de dados (DPUs), usando o recurso Auto Scaling do AWS Glue e ajustando os trabalhos.
- Expandindo a capacidade da rede usando intervalo adicional de Classless Inter-Domain Routing (CIDR) não roteável com um gateway NAT privado.
Antes de nos aprofundarmos nessas soluções, vamos entender como o AWS Glue usa Interface de rede elástica (ENI) para estabelecer conectividade. Para permitir o acesso a armazenamentos de dados dentro de uma VPC, você precisa criar uma conexão do AWS Glue anexada à sua VPC. Quando um trabalho do AWS Glue é executado em sua VPC, o trabalho cria uma ENI dentro da VPC configurada para cada conexão de dados e essa ENI usa um endereço IP na VPC especificada. Essas ENIs têm vida curta e ficam ativas até que o trabalho seja concluído.
Agora vamos dar uma olhada na primeira solução que explica a otimização do consumo de endereços IP do AWS Glue.
Estratégias para consumo eficiente de endereços IP
No AWS Glue, o número de trabalhadores que um trabalho usa determina a contagem de endereços IP usados na sua sub-rede VPC. Isso ocorre porque cada trabalhador requer um endereço IP mapeado para uma ENI. Quando não houver intervalo CIDR suficiente alocado para a sub-rede do AWS Glue, você poderá observar erros de esgotamento de endereço IP. A seguir estão algumas práticas recomendadas para otimizar o consumo de endereços IP do AWS Glue:
- Dimensionar corretamente as DPUs do trabalho – AWS Glue é um mecanismo de processamento distribuído. Funciona de forma eficiente quando pode executar tarefas em paralelo. Se um trabalho tiver mais DPUs do que os necessários, ele nem sempre será executado mais rapidamente. Portanto, encontrar o número certo de DPUs garantirá o uso ideal dos endereços IP. Ao criar observabilidade no sistema e analisar o desempenho do trabalho, você pode obter insights sobre tendências de consumo de ENI e, em seguida, configurar a capacidade apropriada no trabalho para o tamanho certo. Para mais detalhes, consulte Monitoramento para planejamento de capacidade de DPU. A IU do Spark é uma ferramenta útil para monitorar o uso dos trabalhadores dos trabalhos do AWS Glue. Para mais detalhes, consulte Monitorando jobs usando a UI da web do Apache Spark.
- AWS Glue Auto Scaling – Muitas vezes é difícil prever antecipadamente os requisitos de capacidade de um trabalho. Habilitar o recurso Auto Scaling do AWS Glue transferirá parte dessa responsabilidade para a AWS. No tempo de execução com base nos requisitos de carga de trabalho, a tarefa escala automaticamente os nós do trabalhador até a configuração máxima definida. Se não houver necessidade adicional, o AWS Glue não fornecerá trabalhadores em excesso, economizando recursos e reduzindo custos. O recurso Auto Scaling está disponível no AWS Glue 3.0 e versões posteriores. Para obter mais informações, consulte Apresentando o AWS Glue Auto Scaling: redimensione automaticamente os recursos de computação sem servidor para um custo menor com o Apache Spark otimizado.
- Otimização em nível de trabalho – Identifique otimizações em nível de trabalho usando Métricas de trabalho do AWS Glue e aplicar as melhores práticas de Práticas recomendadas para ajuste de desempenho de trabalhos do AWS Glue para Apache Spark.
A seguir, vejamos a segunda solução que elabora a expansão da capacidade da rede.
Soluções para expansão do tamanho da rede (endereço IP)
Nesta seção, discutiremos duas soluções possíveis para expandir o tamanho da rede com mais detalhes.
Expanda os intervalos VPC CIDR com endereços roteáveis
Uma solução é adicionar mais intervalos CIDR IPv4 privados de RFC 1918 para sua VPC. Teoricamente, cada conta AWS pode ser atribuída a alguns ou todos esses CIDRs de endereços IP. Sua equipe de gerenciamento de endereços IP (IPAM) geralmente gerencia a alocação de endereços IP que cada unidade de negócios pode usar da RFC1918 para evitar a sobreposição de endereços IP em várias contas ou unidades de negócios da AWS. Se a sua cota atual de endereços IP roteáveis alocada pela equipe do IPAM não for suficiente, você poderá solicitar mais.
Se sua equipe IPAM emitir um intervalo CIDR adicional não sobreposto, você poderá adicioná-lo como um CIDR secundário à sua VPC existente ou criar uma nova VPC com ele. Se estiver planejando criar uma nova VPC, você poderá interconectar as VPCs por meio de Pareamento de VPC or AWS Transit Gateway.
Se esta capacidade adicional for suficiente para executar todos os seus trabalhos dentro do prazo definido, então é uma solução simples e económica. Caso contrário, você pode considerar a adoção de endereços IP sobrepostos com um gateway NAT privado, conforme descrito na seção a seguir. Com a solução a seguir, você deve usar o Transit Gateway para conectar VPCs, pois o peering de VPC não é possível quando há intervalos CIDR sobrepostos nessas duas VPCs.
Configurar CIDR não roteável com um gateway NAT privado
Conforme descrito no whitepaper da AWS Construindo uma infraestrutura de rede multi-VPC AWS escalável e segura, você pode expandir a capacidade da rede criando uma sub-rede de endereço IP não roteável e usando um gateway NAT privado localizado em um espaço de endereço IP roteável (não sobreposto) para rotear o tráfego. Um gateway NAT privado traduz e roteia o tráfego entre endereços IP não roteáveis e endereços IP roteáveis. O diagrama a seguir demonstra a solução com referência ao AWS Glue.
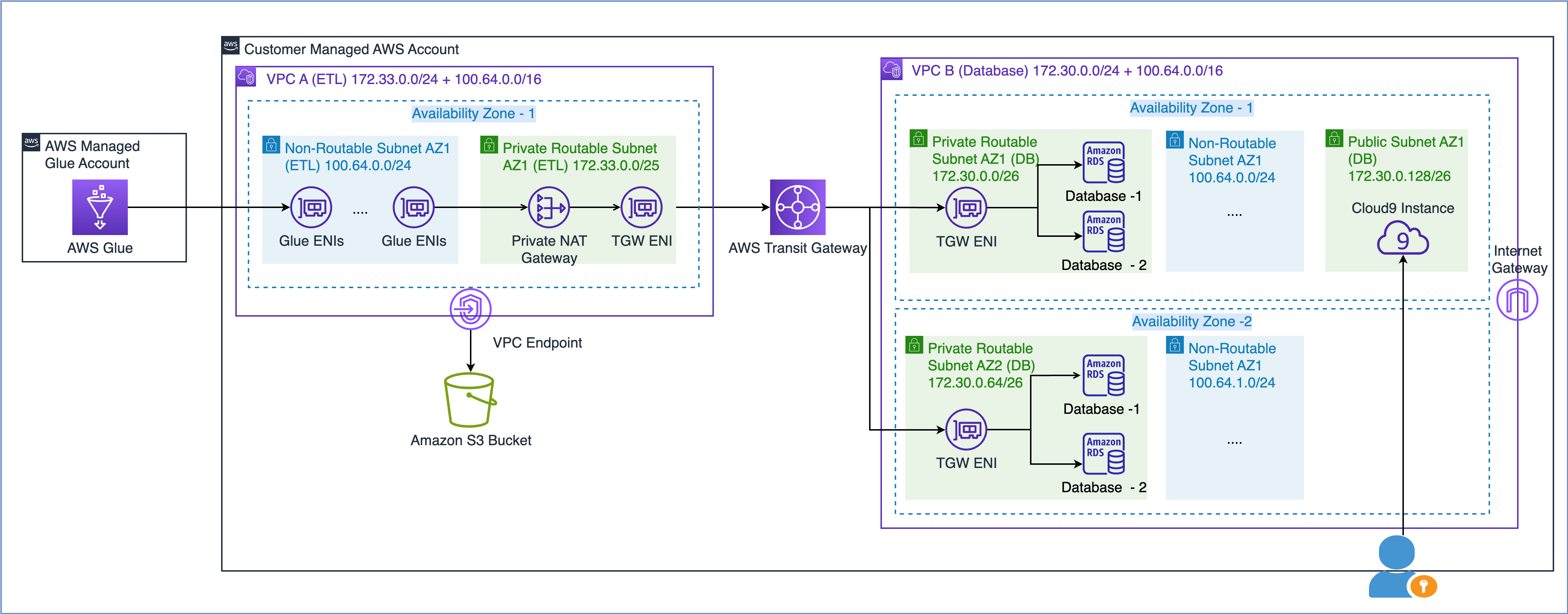
Como você pode ver no diagrama acima, a VPC A (ETL) possui dois intervalos CIDR anexados. O intervalo CIDR menor 172.33.0.0/24 é roteável porque não é reutilizado em nenhum lugar, enquanto o intervalo CIDR maior 100.64.0.0/16 não é roteável porque é reutilizado no VPC do banco de dados.
Na VPC B (banco de dados), hospedamos dois bancos de dados nas sub-redes roteáveis 172.30.0.0/26 e 172.30.0.64/26. Essas duas sub-redes estão em duas zonas de disponibilidade separadas para alta disponibilidade. Também temos duas sub-redes adicionais não utilizadas 100.64.0.0/24 e 100.64.1.0/24 para simular uma configuração não roteável.
Você pode escolher o tamanho do intervalo CIDR não roteável com base nos seus requisitos de capacidade. Como é possível reutilizar endereços IP, você pode criar uma sub-rede muito grande conforme necessário. Por exemplo, uma máscara CIDR de /16 forneceria aproximadamente 65,000 endereços IPv4. Você pode trabalhar com sua equipe de engenharia de rede e dimensionar as sub-redes.
Resumindo, você pode configurar trabalhos do AWS Glue para usar sub-redes roteáveis e não roteáveis em sua VPC para maximizar o pool de endereços IP disponíveis.
Agora vamos entender como os ENIs do Glue que estão em uma sub-rede não roteável se comunicam com fontes de dados em outra VPC.
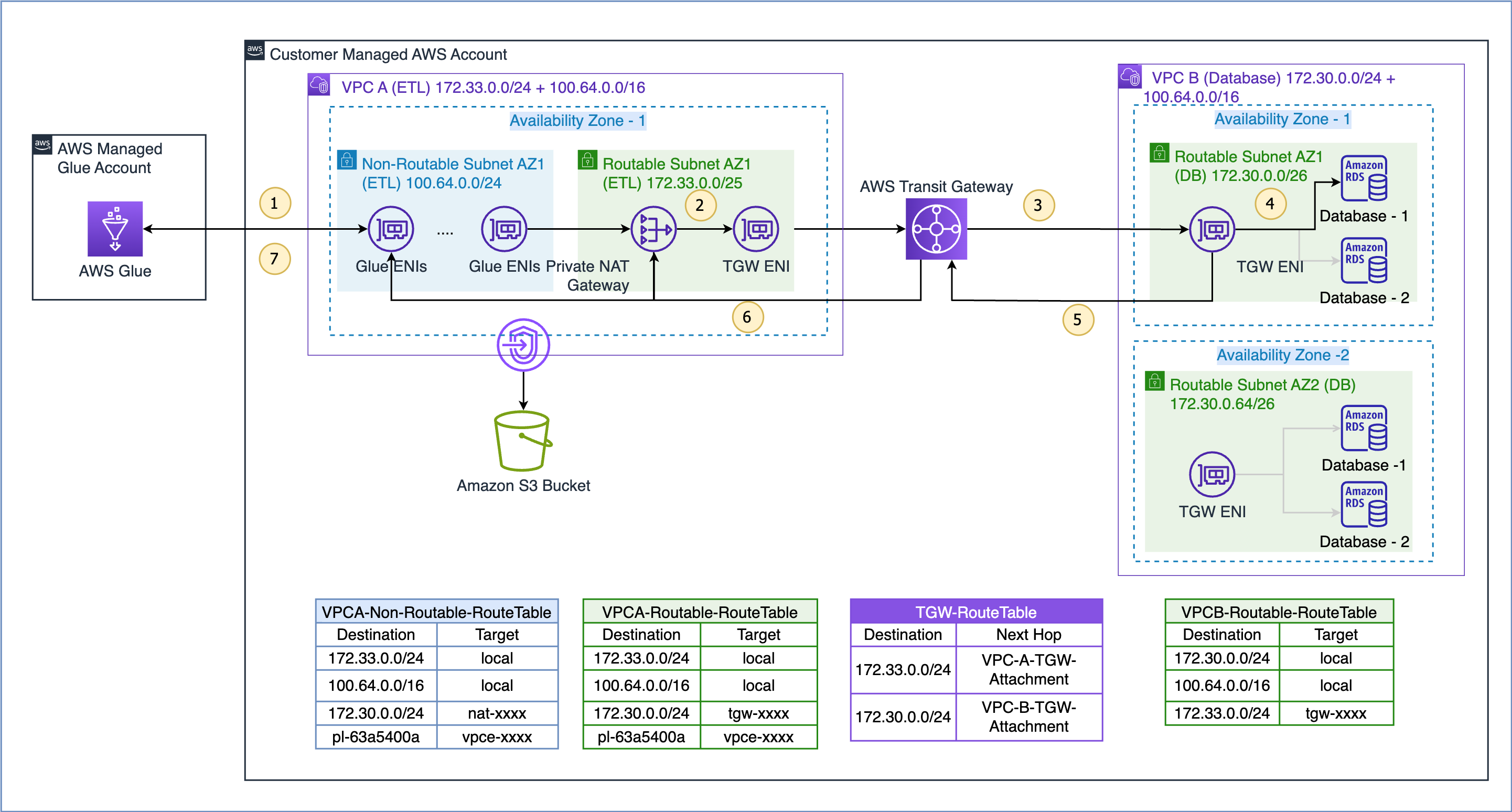
O fluxo de dados para o caso de uso demonstrado aqui é o seguinte (referindo-se às etapas numeradas na figura acima):
- Quando um trabalho do AWS Glue precisa acessar uma fonte de dados, ele primeiro usa a conexão do AWS Glue no trabalho e cria os ENIs na sub-rede não roteável 100.64.0.0/24 na VPC A. Posteriormente, o AWS Glue usa a configuração de conexão do banco de dados e tenta se conectar ao banco de dados na VPC B 172.30.0.0/24.
- De acordo com a tabela de rotas
VPCA-Non-Routable-RouteTableo destino 172.30.0.0/24 está configurado para um gateway NAT privado. A solicitação é enviada ao gateway NAT, que então traduz o endereço IP de origem de um endereço IP não roteável para um endereço IP roteável. O tráfego é então enviado para o anexo do gateway de trânsito na VPC A porque está associado aoVPCA-Routable-RouteTabletabela de rotas na VPC A. - O Transit Gateway usa a rota 172.30.0.0/24 e envia o tráfego para o anexo do transit gateway da VPC B.
- O gateway de trânsito ENI na VPC B usa a rota local da VPC B para se conectar ao endpoint do banco de dados e consultar os dados.
- Quando a consulta for concluída, a resposta será enviada de volta para a VPC A. O tráfego de resposta será roteado para o anexo do gateway de trânsito na VPC B e, em seguida, o Transit Gateway usará a rota 172.33.0.0/24 e enviará o tráfego para o anexo do gateway de trânsito da VPC A. .
- O gateway de trânsito ENI na VPC A usa a rota local para encaminhar o tráfego para o gateway NAT privado, que traduz o endereço IP de destino para aquele dos ENIs na sub-rede não roteável.
- Por fim, o trabalho do AWS Glue recebe os dados e continua o processamento.
A solução de gateway NAT privado é uma opção se você precisar de endereços IP extras quando não puder obtê-los de uma rede roteável em sua organização. Às vezes, com cada serviço adicional, há um custo adicional e essa compensação é necessária para atingir seus objetivos. Consulte a seção de preços do Gateway NAT no Página de preços da Amazon VPC para obter mais informações.
Pré-requisitos
Para concluir o passo a passo da solução de gateway NAT privado, você precisa do seguinte:
Implante a solução
Para implementar a solução, conclua as seguintes etapas:
- Faça login no console de gerenciamento da AWS.
- Implante a solução clicando em
 . Esta pilha tem como padrão
. Esta pilha tem como padrão us-east-1, você pode selecionar a região desejada. - Clique Próximo e especifique os detalhes da pilha. Você pode manter os parâmetros de entrada com os valores padrão pré-preenchidos ou alterá-los conforme necessário.
- Escolha
DatabaseUserPassword, insira uma senha alfanumérica de sua escolha e anote-a para uso posterior. - Escolha
S3BucketName, insira um único Serviço de armazenamento simples da Amazon (Amazon S3) nome do intervalo. Este bucket armazena o script de trabalho do AWS Glue que será copiado de um repositório de código público da AWS.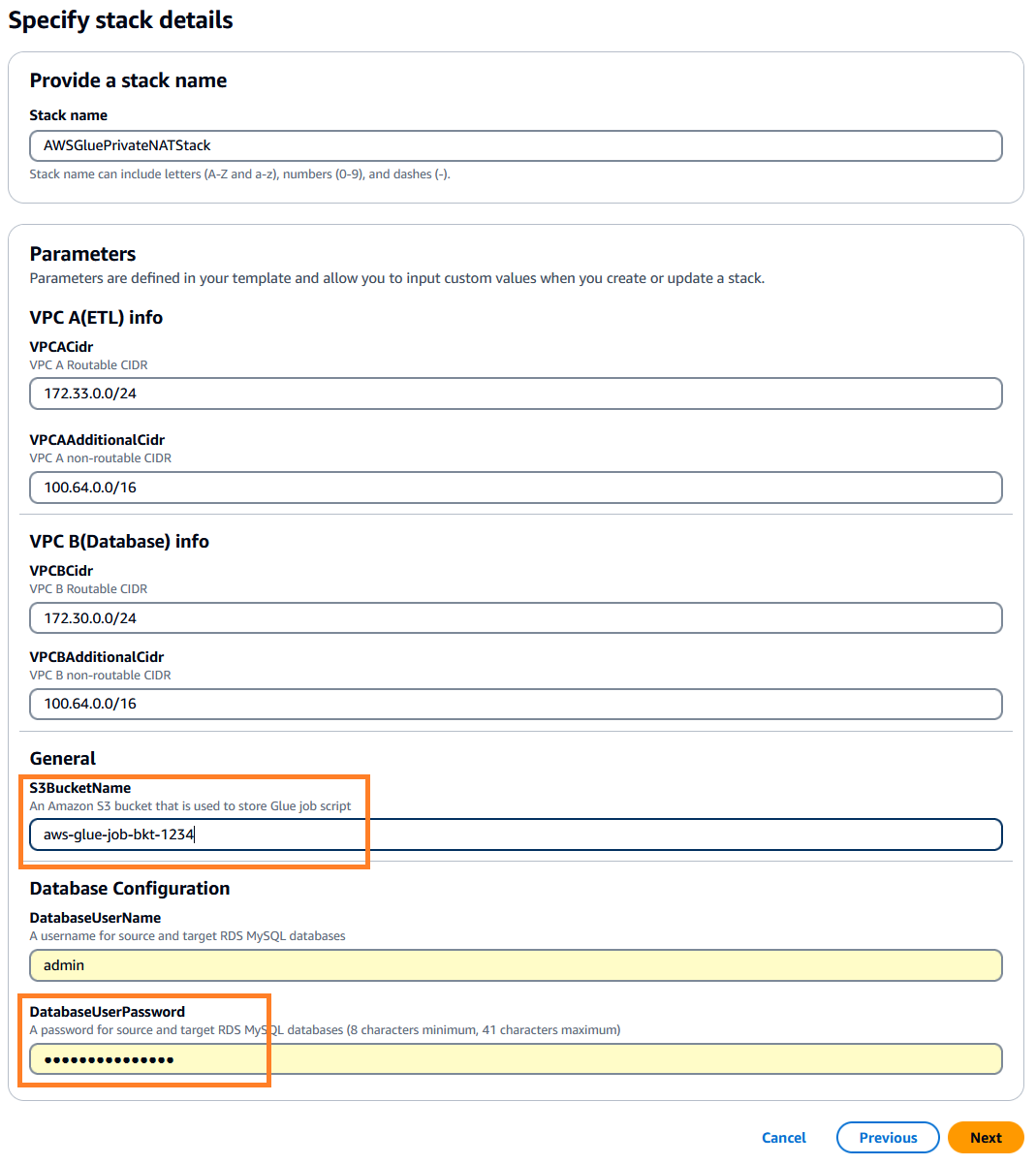
- Clique Próximo.
- Deixe os valores padrão e clique Próximo novamente.
- Revise os detalhes, confirme a criação de recursos do IAM e clique em enviar para iniciar a implantação.
Você pode monitorar os eventos para ver os recursos sendo criados no console do AWS CloudFormation. Pode levar cerca de 20 minutos para que os recursos da pilha sejam criados.
Após a conclusão da criação da pilha, acesse a guia Saídas no console do AWS CloudFormation e anote os seguintes valores para uso posterior:
DBSourceDBTargetSourceCrawlerTargetCrawler
Conecte-se a uma instância do AWS Cloud9
Em seguida, precisamos preparar as tabelas de origem e destino do Amazon RDS for MySQL usando um Nuvem AWS9 instância. Conclua as seguintes etapas:
- Na página do console do AWS Cloud9, localize o
aws-glue-cloud9ambiente. - Na coluna Cloud9 IDE, clique em Abra para iniciar sua instância do AWS Cloud9 em um novo navegador da web.
Prepare a tabela MySQL de origem
Conclua as etapas a seguir para preparar sua tabela de origem:
- No terminal AWS Cloud9, instale o cliente MySQL usando o seguinte comando:
sudo yum update -y && sudo yum install -y mysql - Conecte-se ao banco de dados de origem usando o comando a seguir. Substitua o nome do host de origem pelo valor DBSource capturado anteriormente. Quando solicitado, insira a senha do banco de dados especificada durante a criação da pilha.
mysql -h <Source Hostname> -P 3306 -u admin -p - Execute os seguintes scripts para criar a fonte
emptabela e carregue os dados de teste:-- connect to source database USE srcdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid)); -- Create a stored procedure to load sample records into emp table DELIMITER $$ CREATE PROCEDURE sp_load_emp_source_data() BEGIN DECLARE empid INT; DECLARE ename VARCHAR(100); DECLARE edept VARCHAR(50); DECLARE cnt INT DEFAULT 1; -- Initialize counter to 1 to auto-increment the PK DECLARE rec_count INT DEFAULT 1000; -- Initialize sample records counter TRUNCATE TABLE emp; -- Truncate the emp table WHILE cnt <= rec_count DO -- Loop and load the required number of sample records SET ename = CONCAT('Employee_', FLOOR(RAND() * 100) + 1); -- Generate random employee name SET edept = CONCAT('Dept_', FLOOR(RAND() * 100) + 1); -- Generate random employee department -- Insert record with auto-incrementing empid INSERT INTO emp (ename, edept) VALUES (ename, edept); -- Increment counter for next record SET cnt = cnt + 1; END WHILE; COMMIT; END$$ DELIMITER ; -- Call the above stored procedure to load sample records into emp table CALL sp_load_emp_source_data(); - Verifique a fonte
empcontagem da tabela usando a consulta SQL abaixo (você precisará disso em uma etapa posterior para verificação).select count(*) from emp; - Execute o seguinte comando para sair do utilitário cliente MySQL e retornar ao terminal da instância do AWS Cloud9:
quit;
Prepare a tabela MySQL de destino
Conclua as etapas a seguir para preparar a tabela de destino:
- Conecte-se ao banco de dados de destino usando o comando a seguir. Substitua o nome do host de destino pelo valor DBTarget capturado anteriormente. Quando solicitado, insira a senha do banco de dados especificada durante a criação da pilha.
mysql -h <Target Hostname> -P 3306 -u admin -p - Execute os seguintes scripts para criar o destino
empmesa. Esta tabela será carregada pelo trabalho do AWS Glue na etapa subsequente.-- connect to the target database USE targetdb; -- Drop emp table if it exists DROP TABLE IF EXISTS emp; -- Create the emp table CREATE TABLE emp (empid INT AUTO_INCREMENT, ename VARCHAR(100) NOT NULL, edept VARCHAR(100) NOT NULL, PRIMARY KEY (empid) );
Verifique a configuração de rede (opcional)
As etapas a seguir são úteis para entender o gateway NAT, as tabelas de rotas e as configurações do gateway de trânsito da solução de gateway NAT privada. Esses componentes foram criados durante a criação da pilha do CloudFormation.
- Na página do console Amazon VPC, navegue até a seção Virtual private cloud e localize os gateways NAT.
- Procure NAT Gateway com nome
Glue-OverlappingCIDR-NATGWe explorá-lo ainda mais. Como você pode ver na captura de tela a seguir, o gateway NAT foi criado na VPC A (ETL) na sub-rede roteável.
- No painel de navegação esquerdo, navegue até Tabelas de rotas na seção nuvem privada virtual.
- Procurar por
VPCA-Non-Routable-RouteTablee explorá-lo ainda mais. Você pode ver que a tabela de rotas está configurada para converter o tráfego de CIDR sobreposto usando o gateway NAT.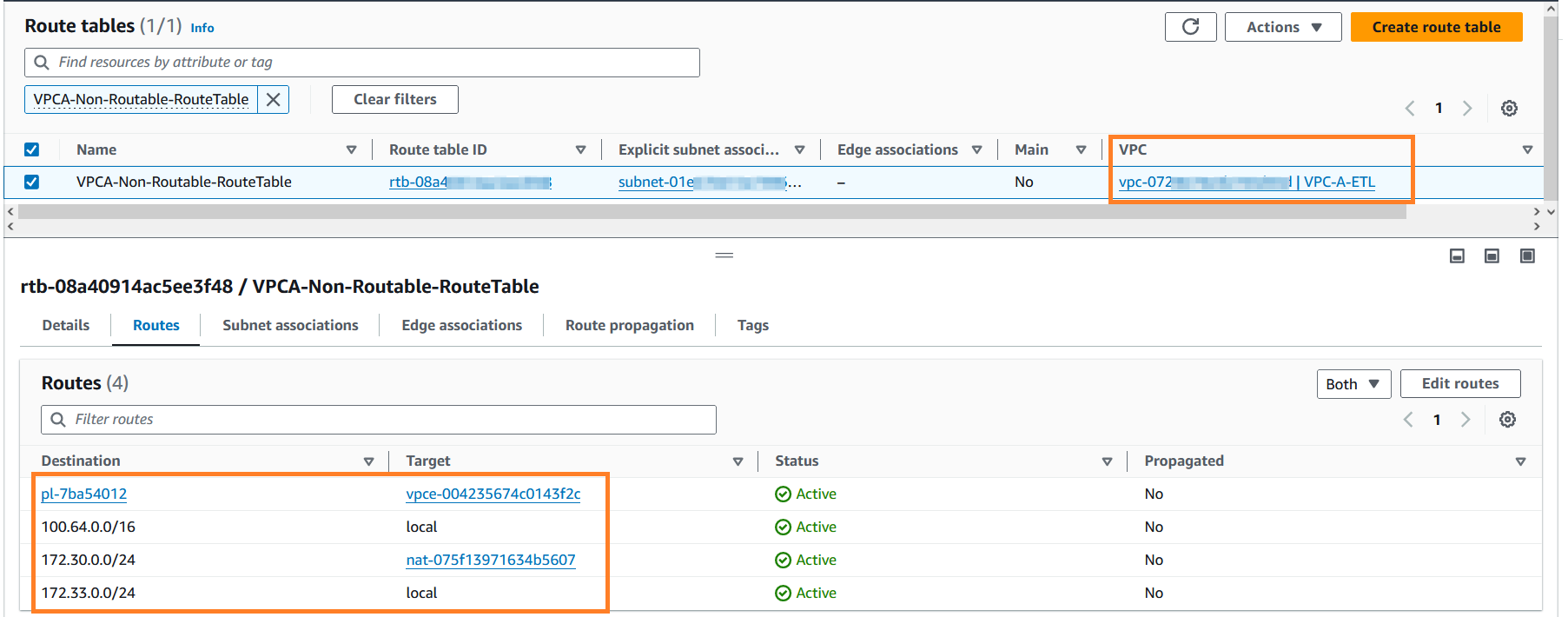
- No painel de navegação esquerdo, navegue até a seção Transit gateways e clique em Transit gateway attachments. Digitar
VPC-na caixa de pesquisa e localize os dois anexos de gateway de trânsito recém-criados. - Você pode explorar mais esses anexos para aprender suas configurações.
Execute os rastreadores do AWS Glue
Conclua as etapas a seguir para executar os crawlers do AWS Glue necessários para catalogar a origem e o destino emp tabelas. Esta é uma etapa de pré-requisito para executar o trabalho do AWS Glue.
- Na página do console do AWS Glue, na seção Catálogo de dados no painel de navegação, clique em Rastreadores.
- Localize os crawlers de origem e de destino que você anotou anteriormente.
- Selecione esses rastreadores e clique em Execute para criar as respectivas tabelas do AWS Glue Data Catalog.
- Você pode monitorar os rastreadores do AWS Glue para a conclusão bem-sucedida. Pode levar cerca de 3 a 4 minutos para que ambos os rastreadores sejam concluídos. Quando terminar, o status da última execução do trabalho muda para Bem-sucedido, e você também pode ver que há duas tabelas de catálogo do AWS Glue criadas a partir dessa execução.

Execute o trabalho de ETL do AWS Glue
Depois de configurar as tabelas e concluir as etapas de pré-requisito, você estará pronto para executar o trabalho do AWS Glue criado usando o modelo CloudFormation. Este trabalho se conecta ao banco de dados RDS for MySQL de origem, extrai os dados e carrega os dados no banco de dados RDS for MySQL de destino. Este trabalho lê dados de uma tabela MySQL de origem e os carrega na tabela MySQL de destino usando uma solução de gateway NAT privada. Para executar o trabalho do AWS Glue, conclua as seguintes etapas:
- No console do AWS Glue, clique em Trabalhos de ETL no painel de navegação.
- Clique no trabalho
glue-private-nat-job. - Clique Execute para iniciá-lo.
A seguir está o script PySpark para este trabalho ETL:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ["JOB_NAME"])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args["JOB_NAME"], args)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.create_dynamic_frame.from_catalog(
database="glue_cat_db_source",
table_name="srcdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
# Script generated for node Change Schema
ChangeSchema_node = ApplyMapping.apply(
frame=AWSGlueDataCatalog_node,
mappings=[
("empid", "int", "empid", "int"),
("ename", "string", "ename", "string"),
("edept", "string", "edept", "string"),
],
transformation_ctx="ChangeSchema_node",
)
# Script generated for node AWS Glue Data Catalog
AWSGlueDataCatalog_node = glueContext.write_dynamic_frame.from_catalog(
frame=ChangeSchema_node,
database="glue_cat_db_target",
table_name="targetdb_emp",
transformation_ctx="AWSGlueDataCatalog_node",
)
job.commit()
Com base na configuração de DPU do trabalho, o AWS Glue cria um conjunto de ENIs na sub-rede não roteável configurada na conexão do AWS Glue. Você pode monitorar esses ENIs na página Interfaces de Rede do Amazon Elastic Compute Nuvem (Amazon EC2).
A captura de tela abaixo mostra os 10 ENIs que foram criados para a execução do trabalho para corresponder ao número solicitado de trabalhadores configurados nos parâmetros do trabalho. Como esperado, as ENIs foram criadas na sub-rede não roteável da VPC A, possibilitando escalabilidade de endereços IP. Após a conclusão do trabalho, esses ENIs serão liberados automaticamente pelo AWS Glue.
Quando o trabalho do AWS Glue estiver em execução, você poderá monitorar seu status. Após a conclusão bem-sucedida, o status do trabalho muda para Sucedido.
Verifique os resultados
Após a conclusão do trabalho do AWS Glue, conecte-se ao banco de dados MySQL de destino. Verifique se a contagem de registros de destino corresponde à origem. Você pode usar a consulta SQL abaixo no terminal AWS Cloud9.
USE targetdb;
SELECT count(*) from emp;Por fim, saia do utilitário cliente MySQL usando o seguinte comando e retorne ao terminal AWS Cloud9: quit;
Agora você pode confirmar se o AWS Glue concluiu com êxito um trabalho para carregar dados em um banco de dados de destino usando os endereços IP de uma sub-rede não roteável. Isso conclui os testes completos da solução de gateway NAT privado.
limpar
Para evitar cobranças futuras, exclua o recurso criado por meio da pilha do CloudFormation concluindo as seguintes etapas:
- No console do AWS CloudFormation, clique em Pilhas no painel de navegação.
- Selecione a pilha
AWSGluePrivateNATStack. - Clique em Excluir para excluir a pilha. Quando solicitado, confirme a exclusão da pilha.
Conclusão
Nesta postagem, demonstramos como você pode dimensionar trabalhos do AWS Glue otimizando o consumo de endereços IP e expandindo a capacidade da sua rede usando uma solução de gateway NAT privada. Essa abordagem dupla ajuda você a ser desbloqueado em um ambiente que possui restrições de capacidade de endereço IP. As opções discutidas na seção de otimização de endereço IP do AWS Glue são complementares às soluções de expansão de endereço IP e você pode construir iterativamente para amadurecer sua plataforma de dados.
Saiba mais sobre as técnicas de otimização de trabalhos do AWS Glue em Monitore e otimize custos no AWS Glue for Apache Spark e Práticas recomendadas para dimensionar trabalhos do Apache Spark e particionar dados com o AWS Glue.
Sobre os autores
 Sushanth Kothapally é arquiteto de soluções na Amazon Web Services, oferecendo suporte a clientes automotivos e de manufatura. Ele é apaixonado por projetar soluções de tecnologia para atender às metas de negócios e tem grande interesse em arquiteturas sem servidor e orientadas a eventos.
Sushanth Kothapally é arquiteto de soluções na Amazon Web Services, oferecendo suporte a clientes automotivos e de manufatura. Ele é apaixonado por projetar soluções de tecnologia para atender às metas de negócios e tem grande interesse em arquiteturas sem servidor e orientadas a eventos.
 Senthil Kamala Rathinam é arquiteto de soluções na Amazon Web Services, especializado em dados e análises. Ele é apaixonado por ajudar os clientes a projetar e construir plataformas de dados modernas. Nas horas vagas, Senthil adora ficar com a família e jogar badminton.
Senthil Kamala Rathinam é arquiteto de soluções na Amazon Web Services, especializado em dados e análises. Ele é apaixonado por ajudar os clientes a projetar e construir plataformas de dados modernas. Nas horas vagas, Senthil adora ficar com a família e jogar badminton.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/scale-aws-glue-jobs-by-optimizing-ip-address-consumption-and-expanding-network-capacity-using-a-private-nat-gateway/

