Introdução
Na visão computacional, existem diferentes técnicas para detecção de objetos vivos, incluindo Faster R-CNN, SSD e YOLO. Cada técnica tem suas limitações e vantagens. Embora o Faster R-CNN possa ser excelente em precisão, ele pode não funcionar tão bem em cenários em tempo real, provocando uma mudança em direção ao Algoritmo YOLO.
A detecção de objetos é fundamental na visão computacional, permitindo que as máquinas identifiquem e localizem objetos dentro de um quadro ou tela. Ao longo dos anos, vários algoritmos de detecção de objetos foram desenvolvidos, com o YOLO emergindo como um dos mais bem-sucedidos. Recentemente, o YOLOv8 foi introduzido, aprimorando ainda mais as capacidades do algoritmo.
Neste guia abrangente, exploramos três algoritmos de detecção de objetos proeminentes: Faster R-CNN, SSD (Single Shot MultiBox Detector) e YOLOv8. Discutimos os aspectos práticos da implementação desses algoritmos, incluindo a configuração de um ambiente virtual e o desenvolvimento de um aplicativo Streamlit.
Objetivo do aprendizado
- Entenda Faster R-CNN, SSD e YOLO e analise as diferenças entre eles.
- Ganhe experiência prática na implementação de sistemas de detecção de objetos ao vivo usando OpenCV, Supervisão e YOLOv8.
- Compreender o modelo de segmentação de imagens usando a anotação Roboflow.
- Crie um aplicativo Streamlit para uma interface de usuário fácil.
Vamos explorar como fazer segmentação de imagens com YOLOv8!
Índice
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
R-CNN mais rápida
Faster R-CNN (Faster Region-based Convolutional Neural Network) é um algoritmo de detecção de objetos baseado em aprendizado profundo. É avaliado usando as estruturas R-CNN e Fast R-CNN e pode ser considerado uma extensão do Fast R-CNN.
Este algoritmo introduz a Rede de Propostas de Região (RPN) para gerar propostas de regiões, substituindo a busca seletiva usada no R-CNN. O RPN compartilha camadas convolucionais com a rede de detecção, permitindo um treinamento eficiente de ponta a ponta.
As propostas de região geradas são então alimentadas em uma rede Fast R-CNN para refinamento da caixa delimitadora e classificação de objetos.
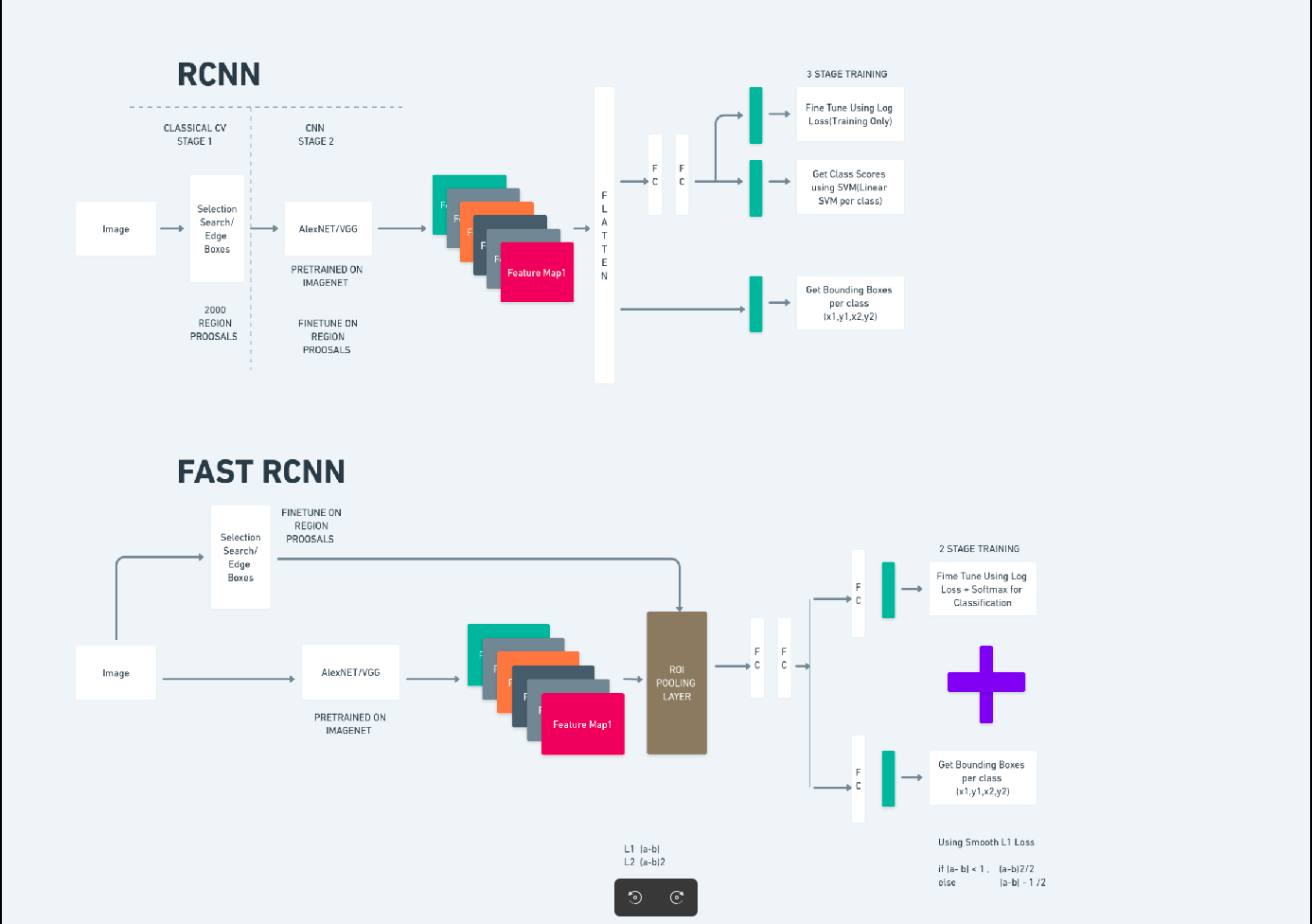
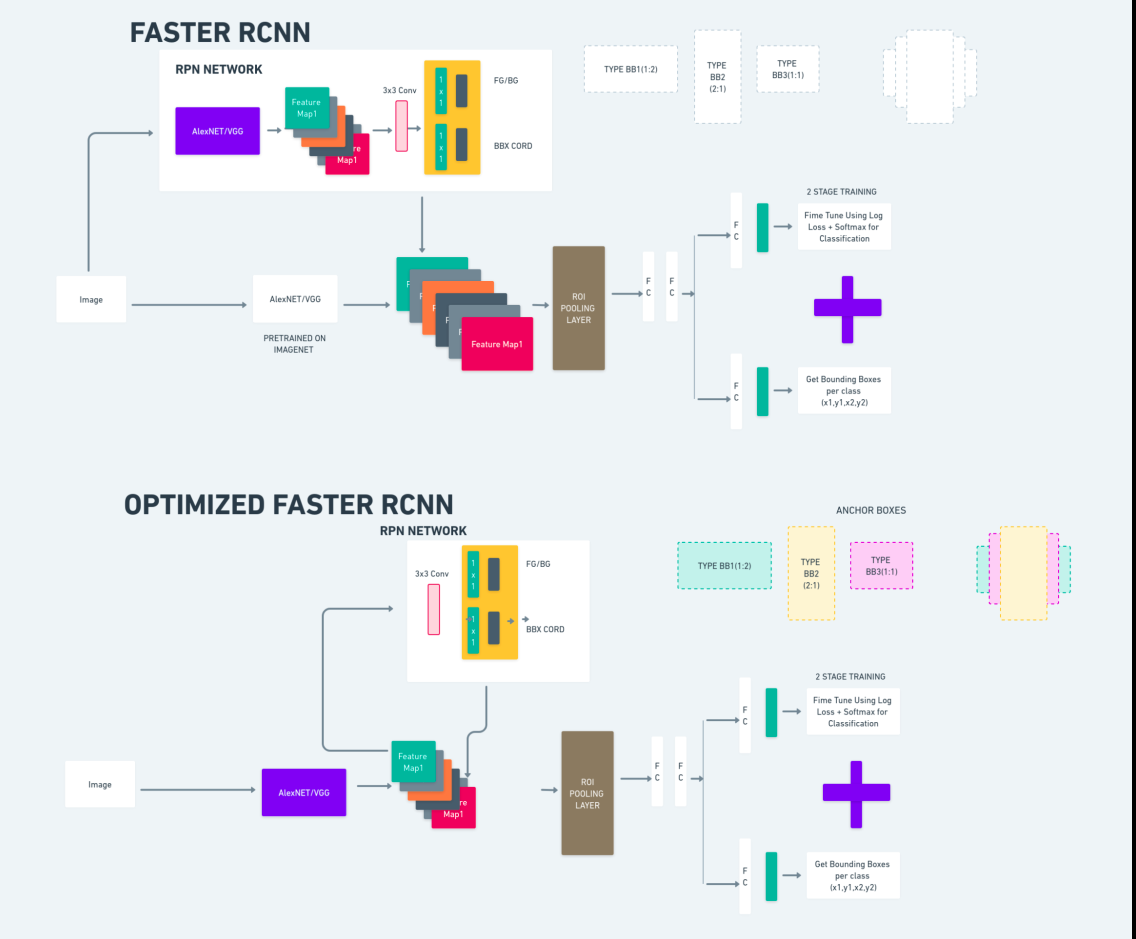
O diagrama acima ilustra a família Faster R-CNN de forma abrangente e é fácil de entender para avaliar cada algoritmo.
Detector MultiBox de disparo único (SSD)
A Detector MultiBox de disparo único (SSD) é popular na detecção de objetos e usado principalmente em tarefas de visão computacional. No método anterior, Faster R-CNN, seguimos duas etapas: a primeira envolveu a parte de detecção e a segunda envolveu a regressão. No entanto, com SSD, realizamos apenas uma única etapa de detecção. O SSD foi introduzido em 2016 para atender à necessidade de um modelo de detecção de objetos rápido e preciso.

O SSD tem várias vantagens sobre os métodos anteriores de detecção de objetos, como Faster R-CNN:
- Eficiência: O SSD é um detector de estágio único, o que significa que ele prevê diretamente caixas delimitadoras e pontuações de classe sem exigir uma etapa separada de geração de propostas. Isso o torna mais rápido em comparação com detectores de dois estágios como o Faster R-CNN.
- Treinamento ponta a ponta: O SSD pode ser treinado ponta a ponta, otimizando conjuntamente a rede base e o cabeçote de detecção, o que simplifica o processo de treinamento.
- Fusão de recursos em várias escalas: o SSD opera em mapas de recursos em múltiplas escalas, permitindo detectar objetos de tamanhos variados com mais eficiência.
O SSD atinge um bom equilíbrio entre velocidade e precisão, tornando-o adequado para aplicações em tempo real onde o desempenho e a eficiência são essenciais.
Você só olha uma vez (YOLOv8)
Em 2015, You Only Look Once (YOLO) foi apresentado como um algoritmo de detecção de objetos em um artigo de pesquisa de Joseph Redmon, Santosh Divvala, Ross Girshick e Ali Farhadi. YOLO é um algoritmo de disparo único que classifica diretamente um objeto em uma única passagem, fazendo com que apenas uma rede neural preveja caixas delimitadoras e probabilidades de classe usando uma imagem completa como entrada.
Agora, vamos entender o YOLOv8 como avanços de última geração na detecção de objetos em tempo real com maior precisão e velocidade. O YOLOv8 permite aproveitar modelos pré-treinados, que já foram treinados em um vasto conjunto de dados como COCO (Common Objects in Context). A segmentação de imagens fornece informações em nível de pixel sobre cada objeto, permitindo uma análise e compreensão mais detalhadas do conteúdo da imagem.
Embora a segmentação de imagens possa ser cara do ponto de vista computacional, o YOLOv8 integra esse método em sua arquitetura de rede neural, permitindo uma segmentação de objetos eficiente e precisa.
Princípio de funcionamento do YOLOv8
YOLOv8 funciona primeiro dividindo a imagem de entrada em células da grade. Usando essas células da grade, YOLOv8 prevê as caixas delimitadoras (bbox) com probabilidades de classe.
Posteriormente, o YOLOv8 emprega o algoritmo NMS para reduzir a sobreposição. Por exemplo, se houver vários carros presentes na imagem, resultando em caixas delimitadoras sobrepostas, o algoritmo NMS ajuda a reduzir essa sobreposição.
Diferença entre variantes do Yolo V8: YOLOv8 está disponível em três variantes: YOLOv8, YOLOv8-L e YOLOv8-X. A principal diferença entre as variantes é o tamanho da rede backbone. YOLOv8 possui a menor rede de backbone, enquanto YOLOv8-X possui a maior rede de backbone.
Diferença entre Faster R-CNN, SSD e YOLO
| Aspecto | R-CNN mais rápida | SSD | YOLO |
|---|---|---|---|
| Arquitetura | Detector de dois estágios com RPN e Fast R-CNN | Detector de estágio único | Detector de estágio único |
| Propostas de Região | Sim | Não | Não |
| Velocidade de detecção | Mais lento em comparação com SSD e YOLO | Mais rápido em comparação com Faster R-CNN, mais lento que YOLO | Muito rápido |
| Precisão | Geralmente maior precisão | Precisão e velocidade equilibradas | Precisão decente, especialmente para aplicações em tempo real |
| Flexibilidade | Flexível, pode lidar com vários tamanhos de objetos e proporções | Pode lidar com múltiplas escalas de objetos | Pode ter dificuldades com a localização precisa de pequenos objetos |
| Detecção Unificada | Não | Não | Sim |
| Troca entre velocidade e precisão | Geralmente sacrifica a velocidade pela precisão | Equilibra velocidade e precisão | Prioriza a velocidade enquanto mantém uma precisão decente |
O que é segmentação?
Como sabemos, segmentação significa que dividimos a imagem grande em grupos menores com base em certas características. Vamos entender a segmentação de imagens, que é a técnica de visão computacional usada para particionar uma imagem em diferentes segmentos ou regiões múltiplas. Como as imagens são feitas de pixels e na segmentação de imagens, os pixels são agrupados de acordo com a semelhança de cor, intensidade, textura ou outras propriedades visuais.
Por exemplo, se uma imagem contém árvores, carros ou pessoas, a segmentação da imagem dividirá a imagem em diferentes classes que representam objetos ou partes significativas da imagem. A segmentação de imagens é amplamente utilizada em diferentes campos, como imagens médicas, análise de imagens de satélite, reconhecimento de objetos em visão computacional e muito mais.

Na parte de segmentação, criamos inicialmente o primeiro modelo de segmentação YOLOv8 usando Robflow. Em seguida, importamos o modelo de segmentação para realizar a tarefa de segmentação. Surge a questão: por que criamos o modelo de segmentação quando a tarefa poderia ser concluída apenas com um algoritmo de detecção?
A segmentação nos permite obter a imagem corporal completa de uma turma. Embora os algoritmos de detecção se concentrem na detecção da presença de objetos, a segmentação fornece uma compreensão mais precisa ao delinear os limites exatos dos objetos. Isso leva a uma localização e compreensão mais precisas dos objetos presentes na imagem.
No entanto, a segmentação normalmente envolve maior complexidade de tempo em comparação com algoritmos de detecção porque requer etapas adicionais, como separar anotações e criar o modelo. Apesar desta desvantagem, a maior precisão oferecida pela segmentação pode compensar o custo computacional em tarefas onde o delineamento preciso do objeto é crucial.
Detecção ao vivo passo a passo e segmentação de imagens com YOLOv8
Neste conceito estamos explorando as etapas para criar um ambiente virtual usando conda, ativando o venv e instalando os pacotes de requisitos usando pip. primeiro criando o script python normal e depois criamos o aplicativo streamlit.
Passo 1: Crie um ambiente virtual usando Conda
conda create -p ./venv python=3.8 -yPasso 2: Ative o ambiente virtual
conda activate ./venv
Etapa 3: criar requisitos.txt
Abra o terminal e cole o script abaixo:
touch requirements.txtEtapa 4: use o comando Nano e edite o arquivo requirements.txt
Depois de criar o require.txt, digite o seguinte comando para editar o require.txt
nano requirements.txtDepois de executar o script acima, você poderá ver esta IU.
Escreva os pacotes necessários para ela.
ultralytics==8.0.32
supervision==0.2.1
streamlitEm seguida, pressione o botão “ctrl+o”(este comando salva a parte de edição) e pressione o botão "Entrar"
Após pressionar o botão “Ctrl+x”. você pode sair do arquivo. e indo para o caminho principal.
Etapa 5: Instalando o require.txt
pip install -r requirements.txtEtapa 6: Crie o script Python
No terminal escreva o seguinte script ou podemos dizer comando.
touch main.pyDepois de criar main.py, abra o código vs e use o comando write no terminal,
code Passo 7: Escrevendo o script Python
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Depois de executar este comando você poderá ver que sua câmera está aberta e detectando parte de você. como gênero e partes de fundo.
Passo 7: Criar aplicativo streamlit
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
Neste script, estamos criando o aplicativo streamlit e criando o botão para que após pressionar o botão a câmera do seu dispositivo fique aberta e detectando a parte no quadro.
Execute este script usando este comando.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Depois de executar o comando acima, suponha que você tenha recebido o erro de alcance como,
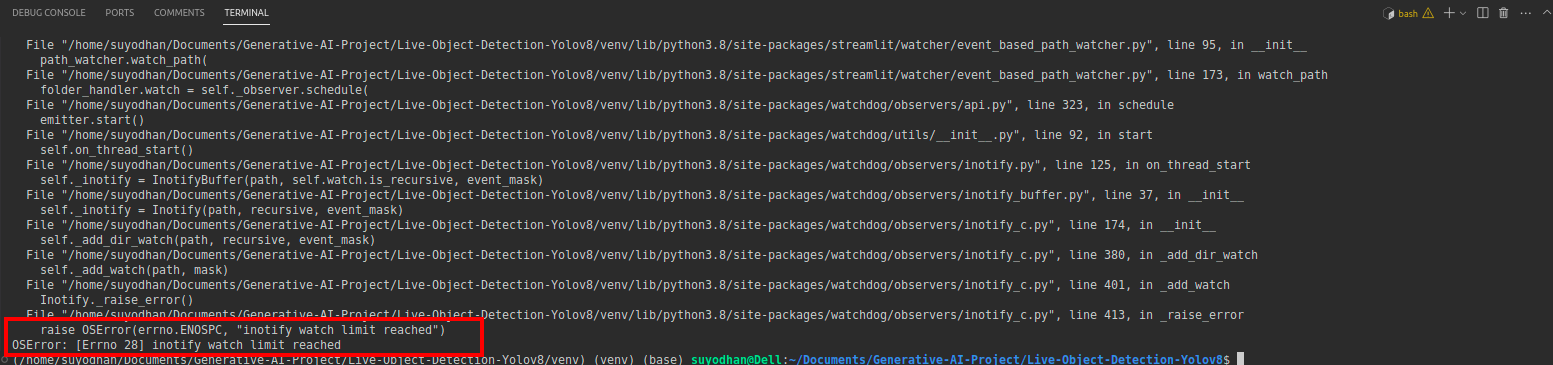
então pressione este comando,
sudo sysctl fs.inotify.max_user_watches=524288Depois de clicar no comando que você deseja escrever sua senha porque estamos usando o comando sudo sudo é deus :)
Execute o script novamente. e você pode ver o aplicativo streamlit.
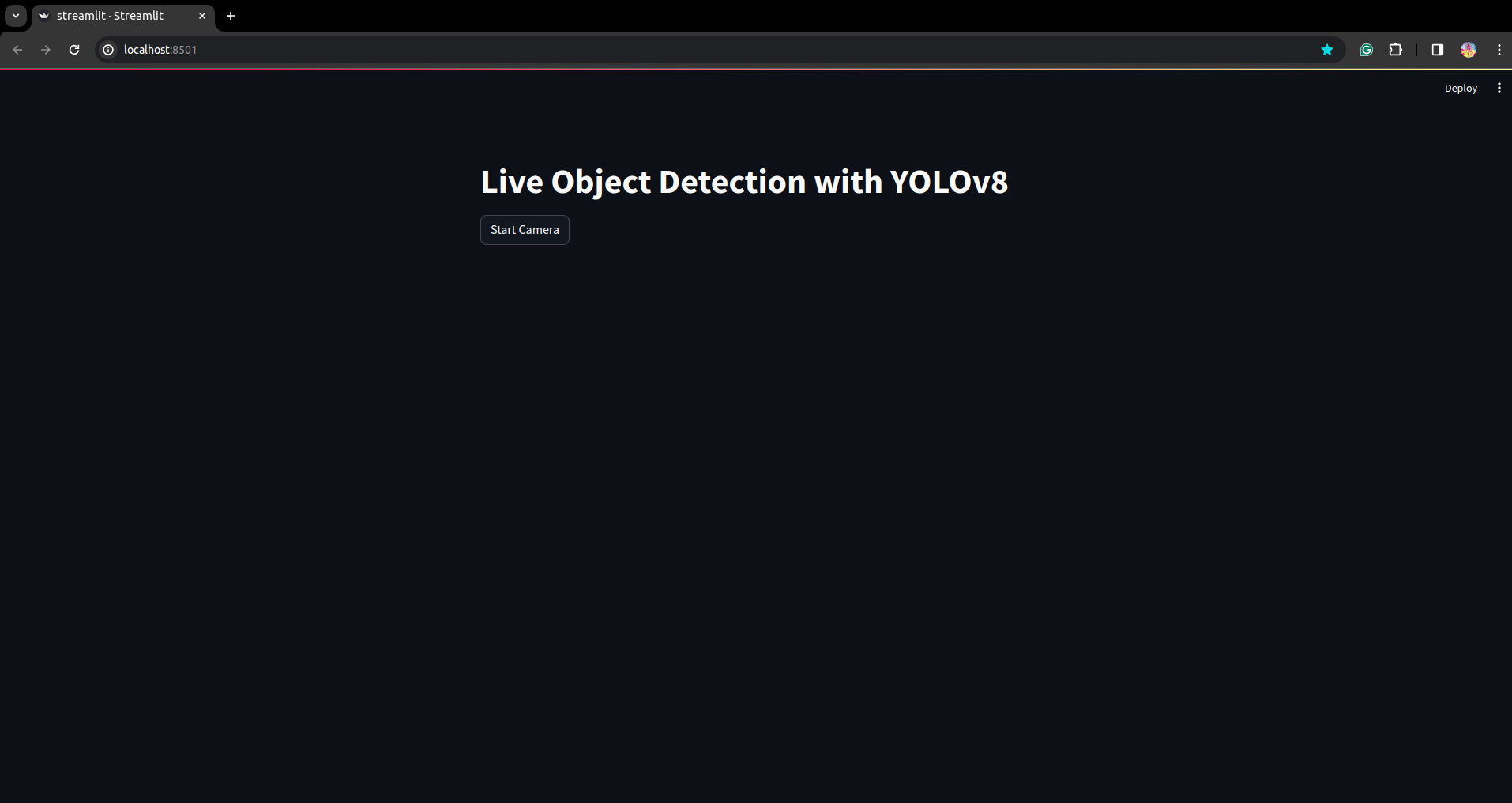
Aqui podemos criar um aplicativo de detecção ao vivo bem-sucedido. Na próxima parte veremos a parte de segmentação.
Etapas para anotação
Etapa 1: configuração do Roboflow
Depois de assinar o “Criar Projeto”. aqui você pode criar o projeto e o grupo de anotações.

Etapa 2: download do conjunto de dados
Aqui consideramos o exemplo simples, mas você deseja usá-lo na definição do problema, então estou usando aqui o conjunto de dados duck.
Vá isso link e baixe o conjunto de dados do pato.

Extraia a pasta lá você pode ver as três pastas: treinar, testar e val.
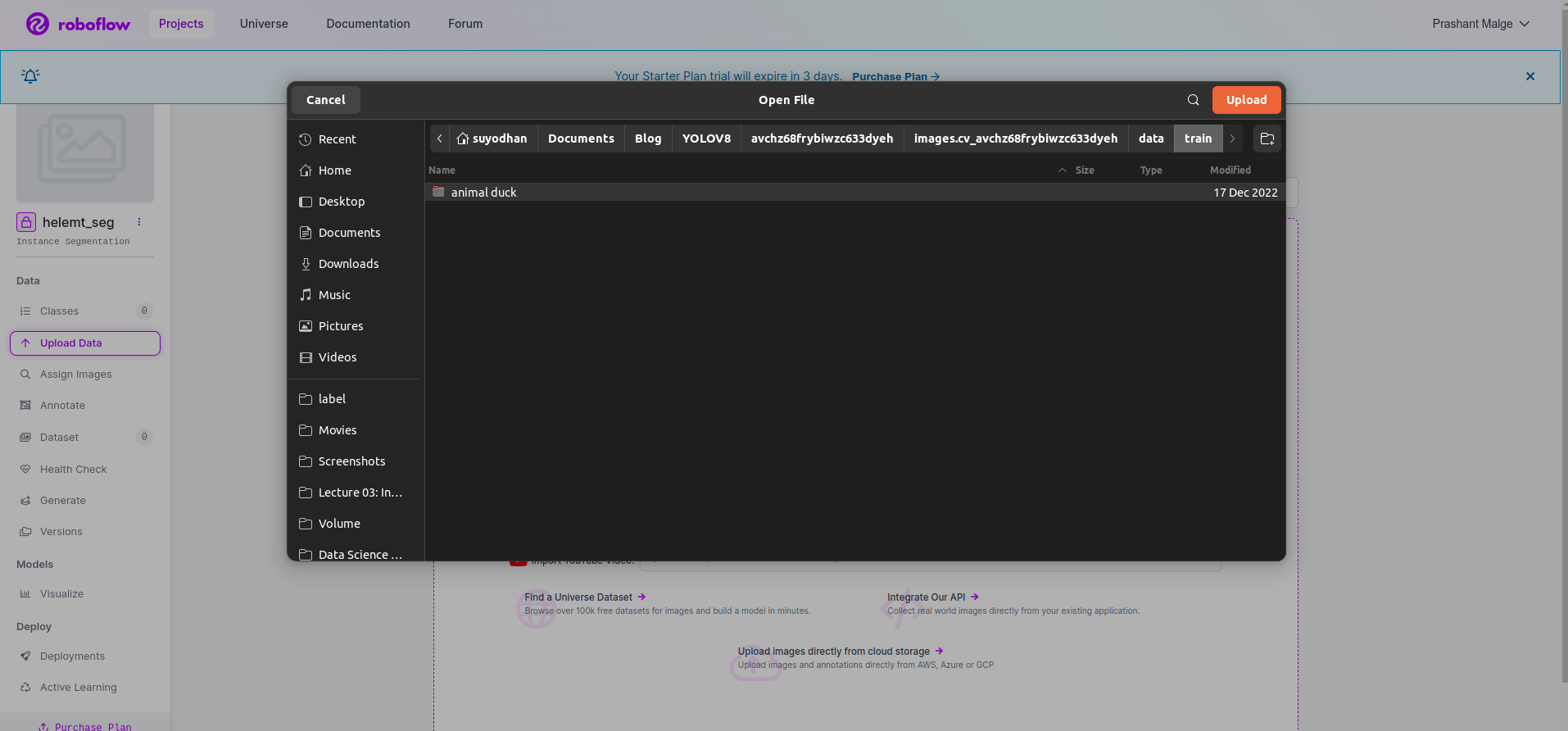
Etapa 3: Carregando o conjunto de dados no roboflow
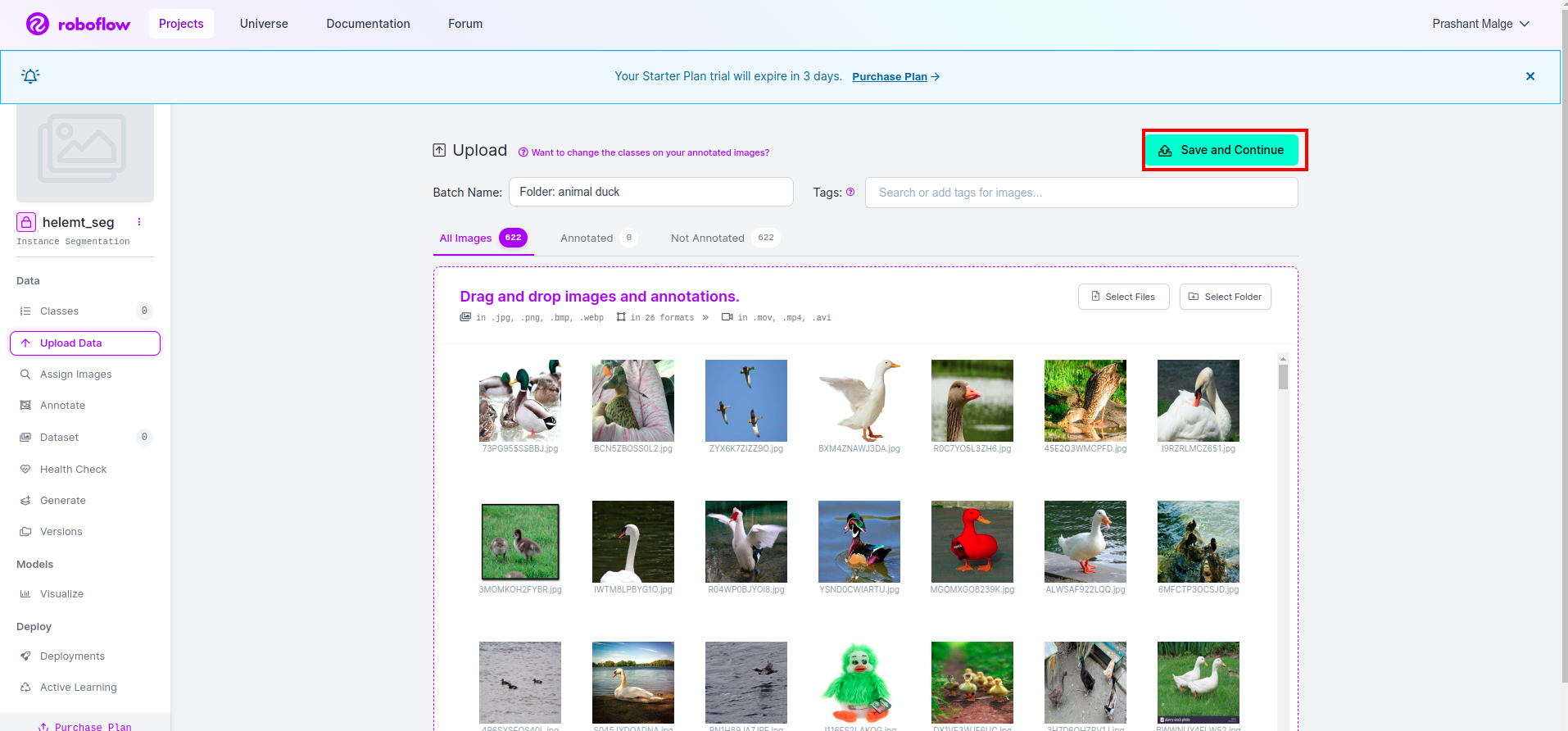
Depois de criar o projeto no roboflow, você pode ver esta UI aqui, você pode fazer upload do seu conjunto de dados, portanto, ao fazer upload apenas de imagens da parte do trem, selecione “selecione a pasta" opção.
Em seguida, clique no botão “Salve e continue" opção conforme marquei em uma caixa retangular vermelha
Etapa 4: adicione o nome da classe
Em seguida, vá para o parte da aula no lado esquerdo marque a caixa vermelha. e escreva o nome da classe como pato, depois de clicar na caixa verde.
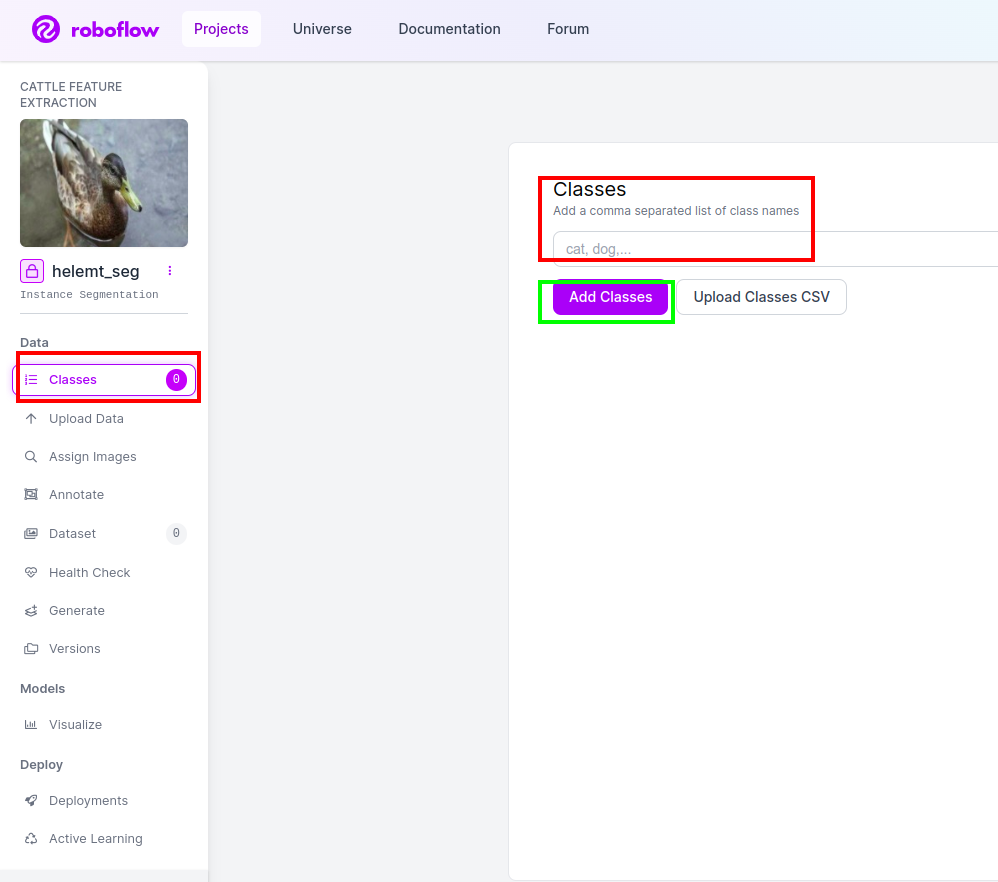
Agora nossa configuração está concluída e a próxima parte, como a parte de anotação, também é simples.
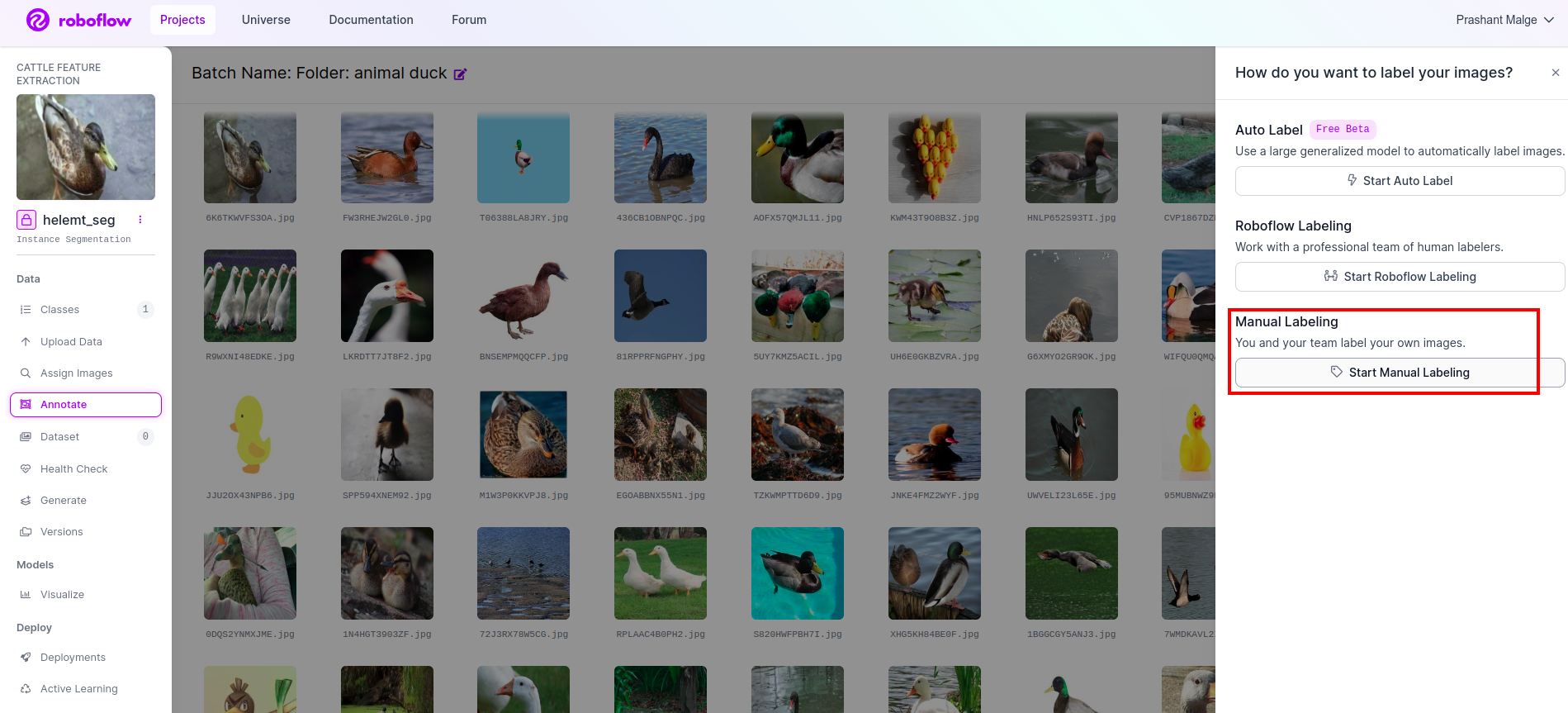
Passo 5: Inicie o parte de anotação
Vou ao opção de anotação Marquei na caixa vermelha e cliquei em iniciar a parte da anotação conforme marquei na caixa verde.
Clique na primeira imagem para ver esta IU. Depois de ver isso, clique na opção de anotação manual.
Em seguida, adicione seu ID de e-mail ou o nome do seu colega de equipe para poder atribuir a tarefa.
Clique na primeira imagem para ver esta IU. aqui clique na caixa vermelha para selecionar o modelo multipolinomial.
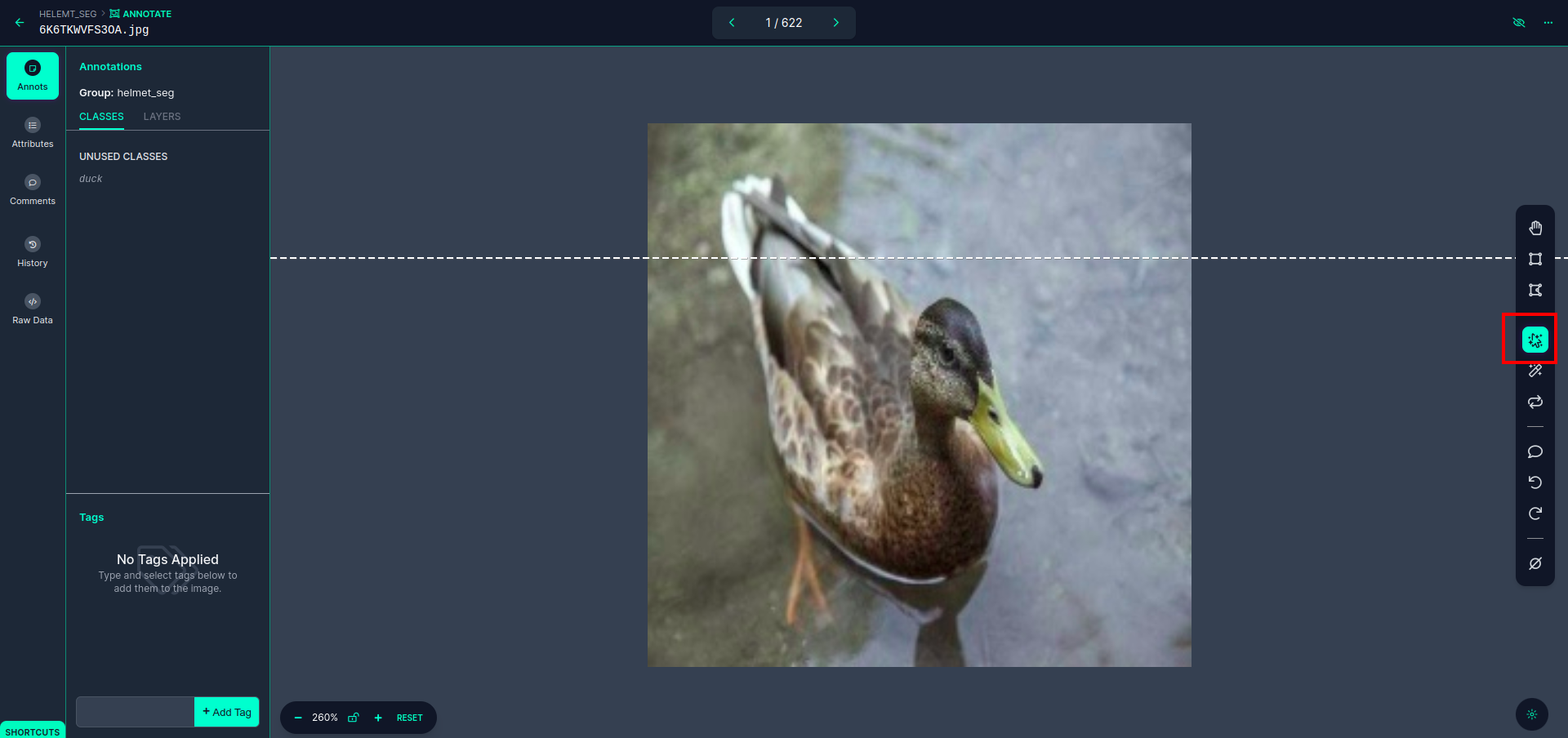
Após clicar na caixa vermelha, selecione o modelo padrão e clique no objeto pato. Isso segmentará automaticamente a imagem. Em seguida, clique na próxima parte e salve-a. Você verá então o lado esquerdo marcado em uma caixa vermelha, onde poderá ver o nome da classe.
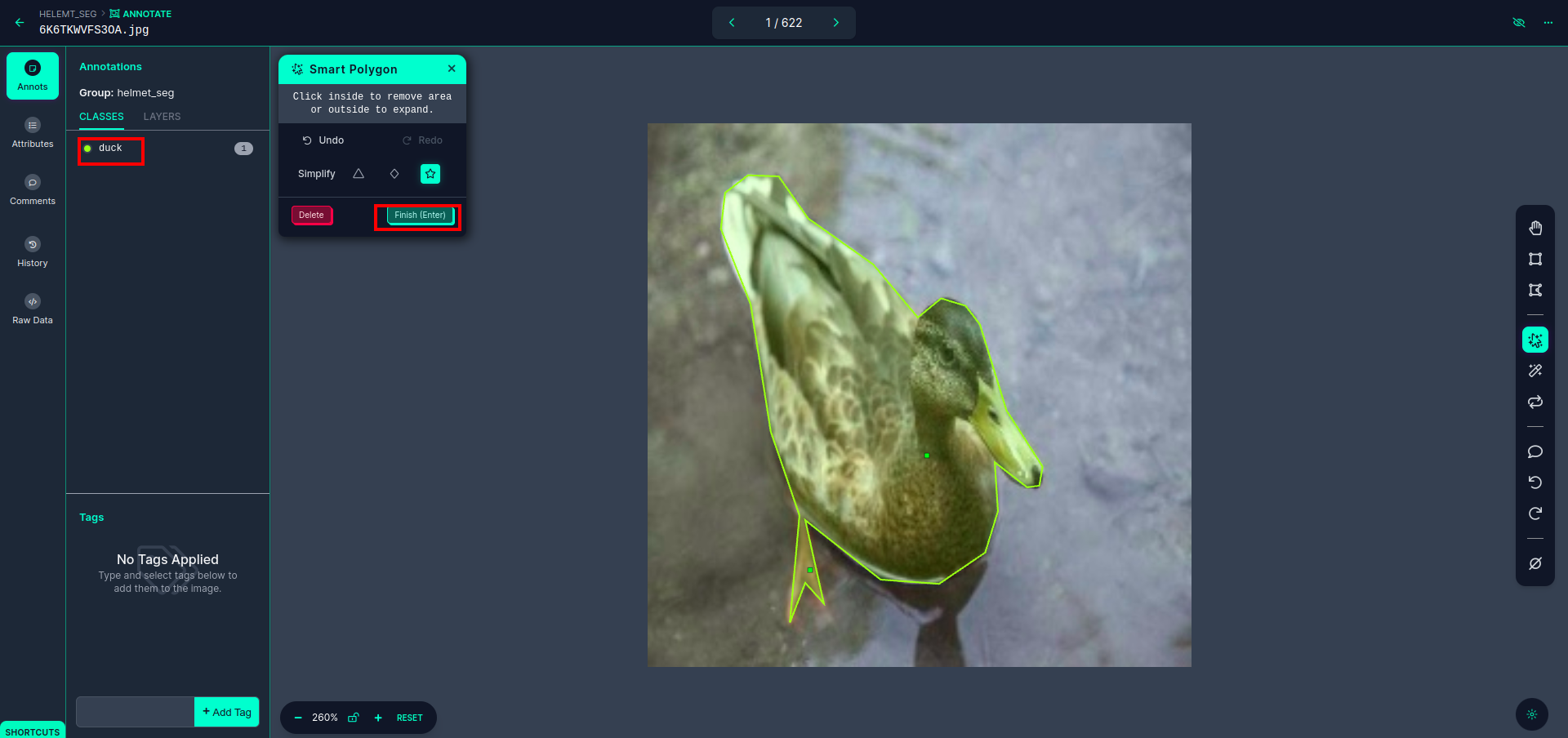
Clique na salvar e entrar opção. anote todas as imagens.
Adicione as imagens para o formato YOLOv8. No lado direito, você verá a opção de adicionar imagens na seção de anotações. Aqui, são criadas duas partes: uma para imagens anotadas e outra para imagens não anotadas.
- Primeiro, clique no lado esquerdo “anotar" opção então adicionar as imagens para o conjunto de dados.
- Em seguida, clique no próximo “Adicionar imagens".
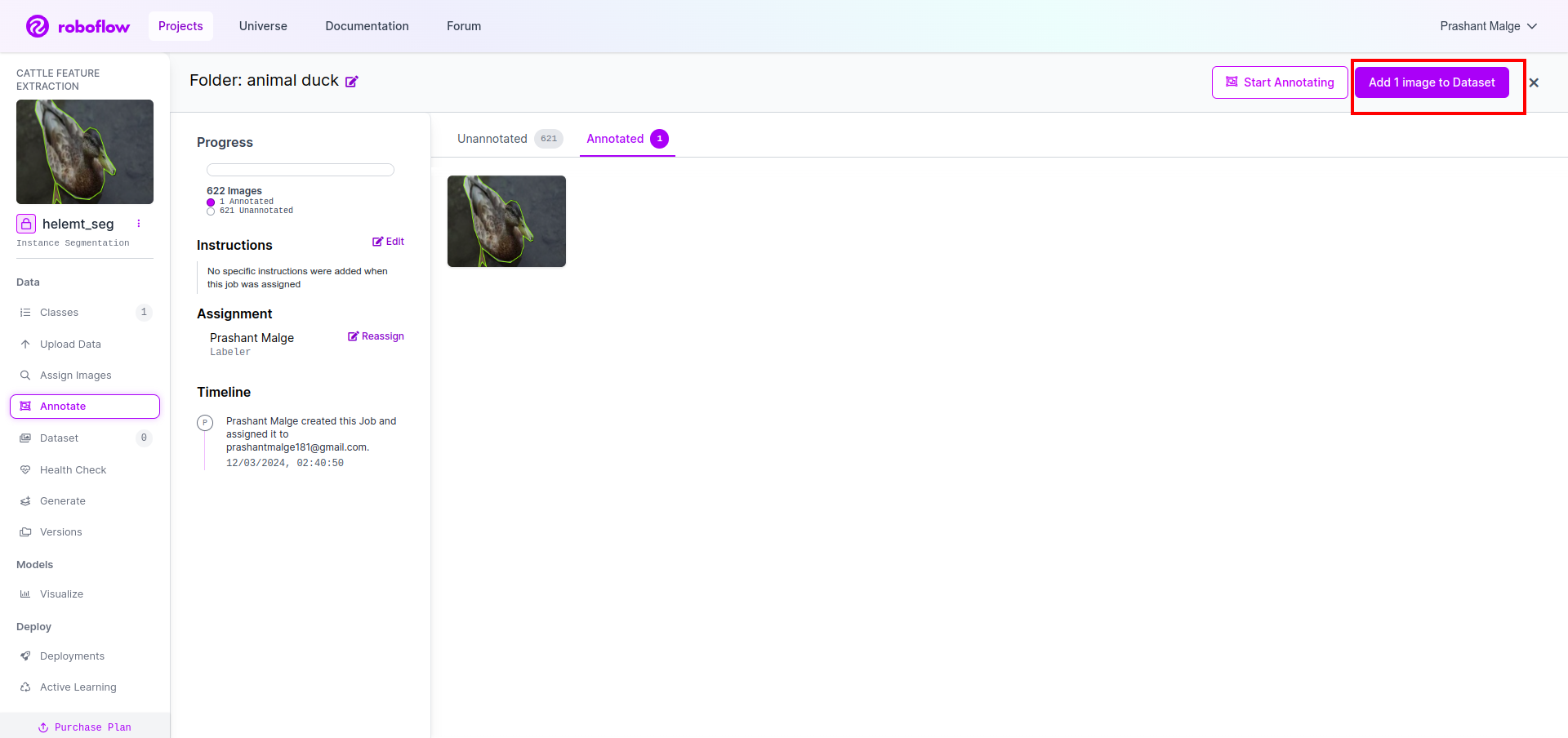
Por último, criamos o conjunto de dados então clique na opção “Gerar” no lado esquerdo, marque a opção e pressione a opção conitune.
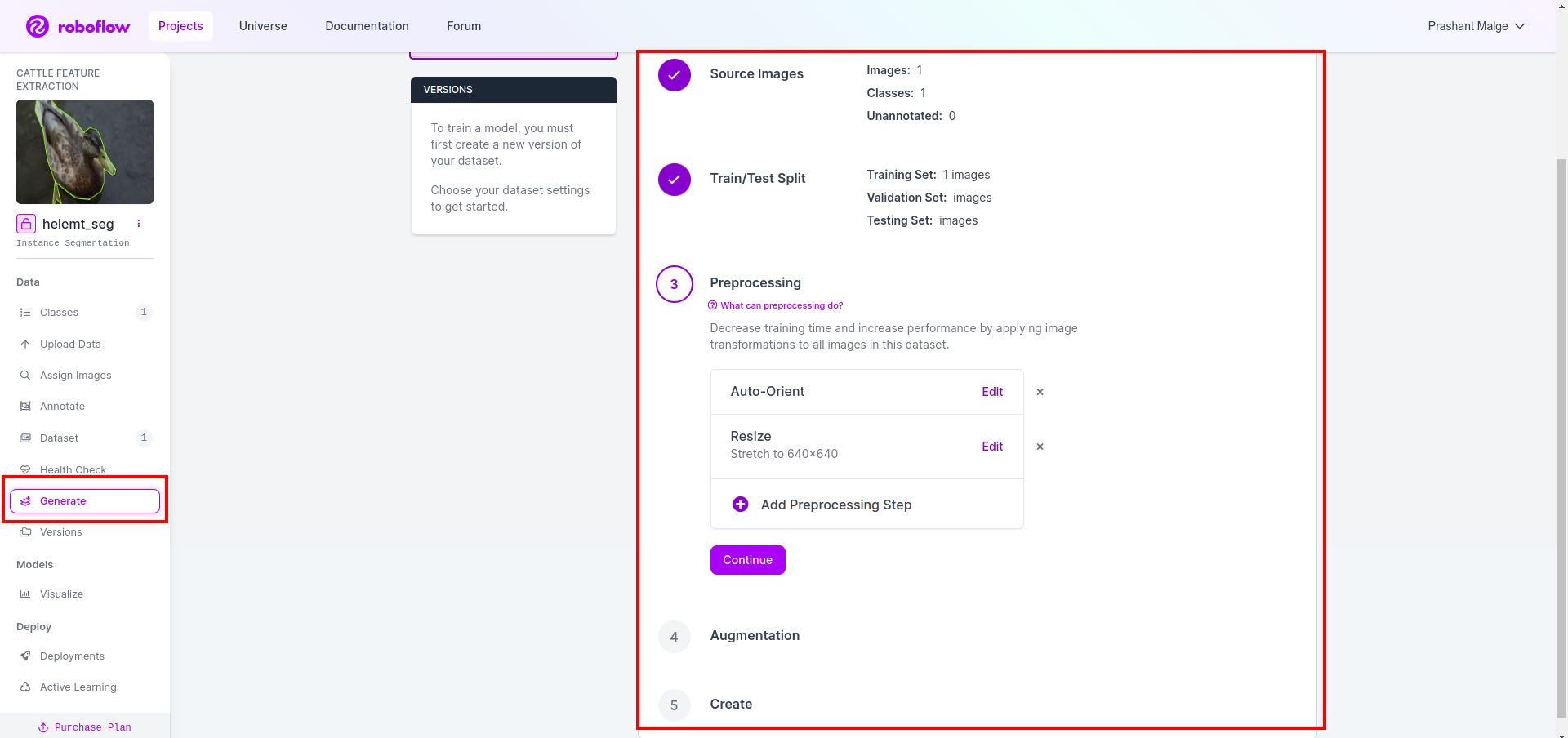
Então você obtém a interface do usuário da opção de divisão do conjunto de dados aqui e pode verificar as pastas train, test e val e suas imagens são divididas automaticamente. e clique na caixa vermelha acima Opção Exportar conjunto de dados e baixe o arquivo zip. a estrutura da pasta do arquivo zip é como…
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Etapa 6: Escreva o script para treinar o modelo de segmentação de imagens
Nesta parte, primeiro você cria o arquivo Google Collab usando o Drive e depois carrega seu conjunto de dados. e mude o Google Drive usando o Google Collab.
1. Use este comando para Monte o Google Drive
from google.colab import drive
drive.mount('/content/gdrive')2. Definir diretório de dados Use a variável constante.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Instalando o pacote necessário, Instale ultralíticos
!pip install ultralytics4. Importando as bibliotecas
import os
from ultralytics import YOLO5. Carga YOLOv8 pré-treinado modelo (aqui temos modelos diferentes também verifique a documentação oficial lá você pode ver os diferentes modelos)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Treine o modelo
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Não, verifique sua unidade. A pasta com o nome do modelo é criada e o modelo é salvo para a previsão que desejamos para este modelo.
7. Preveja o modelo
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Aqui você pode ver que a imagem de segmentação foi salva.

Agora, finalmente, podemos construir modelos de detecção ao vivo e de segmentação de imagens.
Conclusão
Neste blog, exploramos a detecção de objetos ao vivo e a segmentação de imagens com YOLOv8. Para detecção ao vivo, importamos um modelo YOLOv8 pré-treinado e utilizamos a biblioteca de visão computacional, OpenCV, para abrir a câmera e detectar objetos. Além disso, criamos um aplicativo Streamlit para uma interface de usuário atraente.
A seguir, nos aprofundamos na segmentação de imagens com YOLOv8. Importamos um modelo pré-treinado e realizamos aprendizagem por transferência em um conjunto de dados personalizado. Antes disso, exploramos o Roboflow para anotação de conjuntos de dados, fornecendo uma alternativa fácil de usar para ferramentas como EtiquetaImg.
Finalmente, prevemos uma imagem contendo um pato. Embora o objeto na imagem pareça ser um pássaro, especificamos o nome da classe como “pato”Para fins de demonstração.
Principais lições
- Aprendendo sobre modelos de detecção de objetos como Faster R-CNN, SSD e o mais recente YOLOv8.
- Compreender a ferramenta de anotação Roboflow e seu papel na criação de conjuntos de dados para modelos de segmentação YOLOv8.
- Explorando a detecção de objetos vivos usando OpenCV (cv2) e Supervisão, aprimorando habilidades práticas.
- Treinar e implantar um modelo de segmentação usando YOLOv8, ganhando experiência prática.
Perguntas Frequentes
A. A detecção de objetos envolve a identificação e localização de vários objetos em uma imagem, normalmente desenhando caixas delimitadoras ao redor deles. A segmentação de imagens, por outro lado, divide uma imagem em segmentos ou regiões com base na similaridade de pixels, proporcionando uma compreensão mais detalhada dos limites do objeto.
R. O YOLOv8 melhora as versões anteriores, incorporando avanços na arquitetura de rede, técnicas de treinamento e otimização. Pode oferecer melhor precisão, velocidade e eficiência em comparação com YOLOv3.
R. O YOLOv8 pode ser usado para detecção de objetos em tempo real em dispositivos incorporados, dependendo dos recursos de hardware e da otimização do modelo. No entanto, pode exigir otimizações, como remoção de modelo ou quantização, para obter desempenho em tempo real em dispositivos com recursos limitados.
R. O Roboflow oferece ferramentas de anotação intuitivas, recursos de gerenciamento de conjunto de dados e suporte para vários formatos de anotação. Ele agiliza o processo de anotação, permite a colaboração e fornece controle de versão, facilitando a criação e o gerenciamento de conjuntos de dados para projetos de visão computacional.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

