Aprendizado de máquina não supervisionado a análise emergiu como uma ferramenta poderosa para detecção de anomalia no cenário atual rico em dados, especialmente com o volume crescente de dados gerados por máquina. A detecção de anomalias in-stream oferece insights em tempo real sobre anomalias de dados, permitindo uma resposta proativa. Amazon OpenSearch sem servidor concentra-se em fornecer escalabilidade e gerenciamento contínuos de cargas de trabalho de pesquisa; Ingestão do Amazon OpenSearch complementa isso fornecendo uma solução robusta para detecção de anomalias em dados indexados.
Nesta postagem, fornecemos uma solução usando OpenSearch Ingestion que permite realizar detecção de anomalias in-stream em seu próprio ambiente AWS.
Detecção de anomalias in-stream com OpenSearch Ingestion
O OpenSearch Ingestion torna o processo de detecção de anomalias in-stream simples e com menor custo. A detecção de anomalias in-stream ajuda você a economizar na indexação e evita a necessidade de recursos extensos para lidar com big data. Ele permite que as organizações apliquem os recursos apropriados no momento apropriado, gerenciando grandes volumes de dados com eficiência e economizando dinheiro. O uso de encaminhadores de pares e processadores agregados pode tornar as coisas mais complexas e caras; O OpenSearch Ingestion reduz esses problemas.
Vejamos um caso de uso que mostra um YAML de configuração do OpenSearch Ingestion para detecção de anomalias in-stream.
Visão geral da solução
Neste exemplo, percorremos a configuração do OpenSearch Ingestion usando um detector de anomalias florestais de corte aleatório para monitorar contagens de logs em um período de 5 minutos. Também indexamos os logs brutos para fornecer uma demonstração abrangente do fluxo de dados recebidos. Se o seu caso de uso exigir a análise de logs brutos, você poderá agilizar o processo ignorando o pipeline inicial e focar diretamente na detecção de anomalias in-stream, indexando apenas as anomalias identificadas.
O diagrama a seguir ilustra nossa arquitetura de solução.
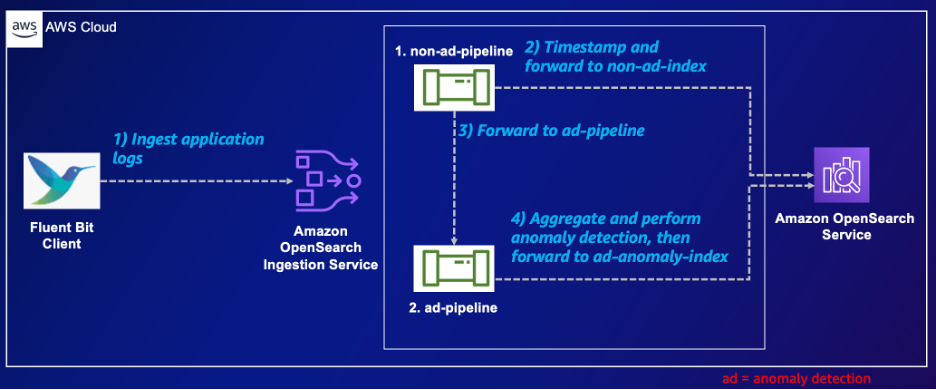
A configuração descreve dois pipelines de ingestão do OpenSearch. O primeiro, sem pipeline de anúncios, ingere dados HTTP, marca-os com carimbo de data e hora e os encaminha para o pipeline de anúncios e para um índice OpenSearch, sem índice de anúncios. O segundo, ad-pipeline, recebe esses dados, realiza a agregação com base no ID em uma janela de 5 minutos e realiza a detecção de anomalias. Os resultados são armazenados no índice ad-anomaly-index. Esta configuração apresenta processamento de dados, detecção de anomalias e armazenamento no OpenSearch Service, aprimorando os recursos de análise.
Implementar a solução
Conclua as etapas a seguir para configurar a solução:
- Criar uma função de pipeline.
- Criar uma coleção.
- Crie um pipeline no qual você especifica a função do pipeline.
O pipeline assume essa função para assinar solicitações para o endpoint de coleta do OpenSearch Serverless. Especifique os valores das chaves na seguinte configuração de pipeline:
- Escolha
sts_role_arn, especifique o nome de recurso da Amazon (ARN) da função de pipeline que você criou. - Escolha
hosts, especifique o terminal da coleção que você criou. - Conjunto
serverlessa verdade.
Para obter um guia detalhado sobre os parâmetros necessários e quaisquer limitações, consulte Plug-ins e opções compatíveis com pipelines de ingestão do Amazon OpenSearch.
- Depois de atualizar a configuração, confirme a validade das configurações do pipeline escolhendo Validar pipeline.
Uma validação bem-sucedida exibirá uma mensagem informando "Validação de configuração de pipeline bem-sucedida.” conforme mostrado na imagem a seguir.

Se a validação falhar, consulte Solução de problemas do Amazon OpenSearch Service para solução de problemas e orientação.
Estimativa de custo para ingestão do OpenSearch
Você só será cobrado pelo número de Ingestão de unidades de computação OpenSearch (OCUs de ingestão) que são alocadas a um pipeline, independentemente de haver dados fluindo pelo pipeline. O OpenSearch Ingestion acomoda imediatamente suas cargas de trabalho aumentando ou diminuindo a capacidade do pipeline com base no uso. Para uma visão geral das despesas, consulte Ingestão do Amazon OpenSearch.
A tabela a seguir mostra os custos mensais aproximados com base nas taxas de transferência e nas necessidades de computação especificadas. Vamos supor que a operação ocorra das 8h às 00h durante a semana, com um custo de US$ 8 por OCU por hora.
A fórmula seria: Custo total/mês = Requisito de OCU * Preço de OCU * Horas/dia * Dias/mês.
| Produtividade | Computação necessária (OCUs) | Custo total/mês (USD) |
| 1 Gbps | 10 | 576 |
| 10 Gbps | 100 | 5760 |
| 50 Gbps | 500 | 28800 |
| 100 Gbps | 1000 | 57600 |
| 500 Gbps | 5000 | 288000 |
limpar
Quando terminar de usar a solução, exclua os recursos criados, incluindo a função do pipeline, o pipeline e a coleção.
Resumo
Com o OpenSearch Ingestion, você pode explorar a detecção de anomalias in-stream com o OpenSearch Service. O caso de uso nesta postagem demonstra como o OpenSearch Ingestion simplifica o processo, alcançando mais com menos recursos. Ele mostra a capacidade do serviço de analisar taxas de log, gerar notificações de anomalias e capacitar respostas proativas a anomalias. Com o OpenSearch Ingestion, você pode melhorar a eficiência operacional e aprimorar os recursos de gerenciamento de riscos em tempo real.
Deixe quaisquer pensamentos e perguntas nos comentários.
Sobre os autores
 Rupesh Tiwari, arquiteto de soluções da AWS, é especializado na modernização de aplicativos com foco em análise de dados, OpenSearch e IA generativa. Ele é conhecido por criar soluções escaláveis e seguras que aproveitam a tecnologia de nuvem para resultados de negócios transformadores, dedicando também tempo ao envolvimento da comunidade e ao compartilhamento de conhecimentos.
Rupesh Tiwari, arquiteto de soluções da AWS, é especializado na modernização de aplicativos com foco em análise de dados, OpenSearch e IA generativa. Ele é conhecido por criar soluções escaláveis e seguras que aproveitam a tecnologia de nuvem para resultados de negócios transformadores, dedicando também tempo ao envolvimento da comunidade e ao compartilhamento de conhecimentos.
 Muthu Pitchaimani é um especialista em pesquisa do Amazon OpenSearch Service. Ele cria aplicativos e soluções de pesquisa em larga escala. Muthu está interessado nos tópicos de rede e segurança e mora em Austin, Texas.
Muthu Pitchaimani é um especialista em pesquisa do Amazon OpenSearch Service. Ele cria aplicativos e soluções de pesquisa em larga escala. Muthu está interessado nos tópicos de rede e segurança e mora em Austin, Texas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/in-stream-anomaly-detection-with-amazon-opensearch-ingestion-and-amazon-opensearch-serverless/

