Amazon Relational Database Service (Amazon RDS) para MySQL integração zero-ETL com Amazon RedShift foi anunciou em visualização no AWS re:Invent 2023 para Amazon RDS para MySQL versão 8.0.28 ou superior. Nesta postagem, fornecemos orientação passo a passo sobre como começar a realizar análises operacionais quase em tempo real usando esse recurso. Esta postagem é uma continuação da série zero-ETL que começou com Guia de conceitos básicos para análises operacionais quase em tempo real usando a integração zero-ETL do Amazon Aurora com o Amazon Redshift.
Desafios
Os clientes de todos os setores hoje procuram usar os dados para obter vantagem competitiva e aumentar a receita e o envolvimento do cliente, implementando casos de uso de análise quase em tempo real, como estratégias de personalização, detecção de fraudes, monitoramento de inventário e muito mais. Existem duas abordagens amplas para analisar dados operacionais para esses casos de uso:
- Analise os dados in-loco no banco de dados operacional (como réplicas de leitura, consulta federada e aceleradores analíticos)
- Mova os dados para um armazenamento de dados otimizado para executar consultas específicas de casos de uso, como um data warehouse
A integração zero-ETL está focada em simplificar a última abordagem.
O processo de extração, transformação e carregamento (ETL) tem sido um padrão comum para mover dados de um banco de dados operacional para um data warehouse analítico. ELT é onde os dados extraídos são carregados como estão no destino primeiro e depois transformados. Pipelines ETL e ELT podem ser caros para construir e complexos para gerenciar. Com vários pontos de contato, erros intermitentes em pipelines de ETL e ELT podem levar a longos atrasos, deixando aplicativos de data warehouse com dados obsoletos ou ausentes, levando ainda mais à perda de oportunidades de negócios.
Alternativamente, soluções que analisam dados no local podem funcionar muito bem para acelerar consultas em um único banco de dados, mas tais soluções não são capazes de agregar dados de vários bancos de dados operacionais para clientes que precisam executar análises unificadas.
Zero-ETL
Ao contrário dos sistemas tradicionais, onde os dados são isolados em um banco de dados e o usuário precisa fazer uma troca entre análise unificada e desempenho, os engenheiros de dados agora podem replicar dados de vários bancos de dados RDS for MySQL em um único data warehouse Redshift para obter insights holísticos em todos os aspectos. muitos aplicativos ou partições. As atualizações em bancos de dados transacionais são propagadas automática e continuamente para o Amazon Redshift para que os engenheiros de dados tenham as informações mais recentes quase em tempo real. Não há infraestrutura para gerenciar e a integração pode aumentar ou diminuir automaticamente com base no volume de dados.
Na AWS, temos feito um progresso constante para trazer nossos visão zero-ETL Para a vida. As seguintes fontes são atualmente suportadas para integrações de ETL zero:
Ao criar uma integração ETL zero para o Amazon Redshift, você continua pagando pelo banco de dados de origem subjacente e pelo uso do banco de dados de destino do Redshift. Referir-se Custos de integração zero-ETL (visualização) para mais detalhes.
Com integração ETL zero com o Amazon Redshift, a integração replica dados do banco de dados de origem para o data warehouse de destino. Os dados ficam disponíveis no Amazon Redshift em segundos, permitindo que você use os recursos de análise do Amazon Redshift e recursos como compartilhamento de dados, otimização autônoma de carga de trabalho, escalabilidade de simultaneidade, aprendizado de máquina e muito mais. Você pode continuar com o processamento da transação no Amazon RDS ou Aurora Amazônica ao mesmo tempo em que usa o Amazon Redshift para cargas de trabalho de análise, como relatórios e painéis.
O diagrama a seguir ilustra essa arquitetura.
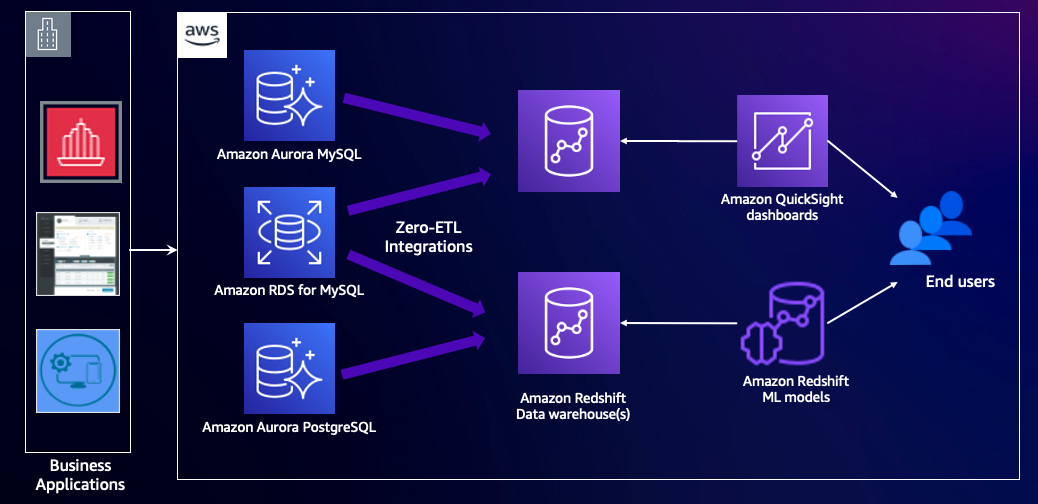
Visão geral da solução
Vamos considerar BILHETE, um site fictício onde os usuários compram e vendem ingressos online para eventos esportivos, shows e concertos. Os dados transacionais deste site são carregados em um banco de dados Amazon RDS for MySQL 8.0.28 (ou versão superior). Os analistas de negócios da empresa desejam gerar métricas para identificar o movimento dos ingressos ao longo do tempo, as taxas de sucesso dos vendedores e os eventos, locais e temporadas mais vendidos. Eles gostariam de obter essas métricas quase em tempo real usando uma integração ETL zero.
A integração é configurada entre o Amazon RDS for MySQL (origem) e o Amazon Redshift (destino). Os dados transacionais da origem são atualizados quase em tempo real no destino, que processa consultas analíticas.
Você pode usar a opção sem servidor ou um cluster RA3 criptografado para Amazon Redshift. Para esta postagem, usamos um banco de dados RDS provisionado e um data warehouse provisionado Redshift.
O diagrama a seguir ilustra a arquitetura de alto nível.
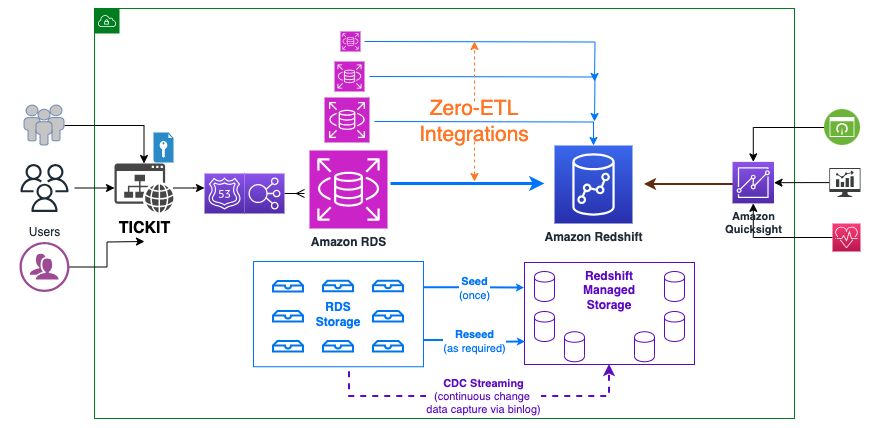
A seguir estão as etapas necessárias para configurar a integração ETL zero. Essas etapas podem ser executadas automaticamente pelo assistente ETL zero, mas será necessário reiniciar se o assistente alterar a configuração do Amazon RDS ou do Amazon Redshift. Você pode executar essas etapas manualmente, se ainda não estiver configurado, e executar as reinicializações conforme sua conveniência. Para obter os guias de introdução completos, consulte Trabalhar com integrações de ETL zero do Amazon RDS com o Amazon Redshift (pré-visualização) e Trabalhando com integrações zero-ETL.
- Configure a origem do RDS para MySQL com um grupo de parâmetros de banco de dados personalizado.
- Configure o cluster Redshift para habilitar identificadores que diferenciam maiúsculas de minúsculas.
- Configure as permissões necessárias.
- Crie a integração zero-ETL.
- Crie um banco de dados da integração no Amazon Redshift.
Configure a origem do RDS para MySQL com um grupo de parâmetros de banco de dados personalizado
Para criar um banco de dados RDS for MySQL, conclua as etapas a seguir:
- No console do Amazon RDS, crie um grupo de parâmetros de banco de dados chamado
zero-etl-custom-pg.
A integração Zero-ETL funciona usando logs binários (binlogs) gerados pelo banco de dados MySQL. Para habilitar binlogs no Amazon RDS for MySQL, um conjunto específico de parâmetros deve ser habilitado.
- Defina as seguintes configurações de parâmetro de cluster binlog:
binlog_format = ROWbinlog_row_image = FULLbinlog_checksum = NONE
Além disso, certifique-se de que o binlog_row_value_options parâmetro não está definido para PARTIAL_JSON. Por padrão, esse parâmetro não está definido.
- Escolha Bases de dados no painel de navegação e escolha Criar banco de dados.
- Escolha Versão do mecanismo, escolha MySQL 8.0.28 (ou mais alto).

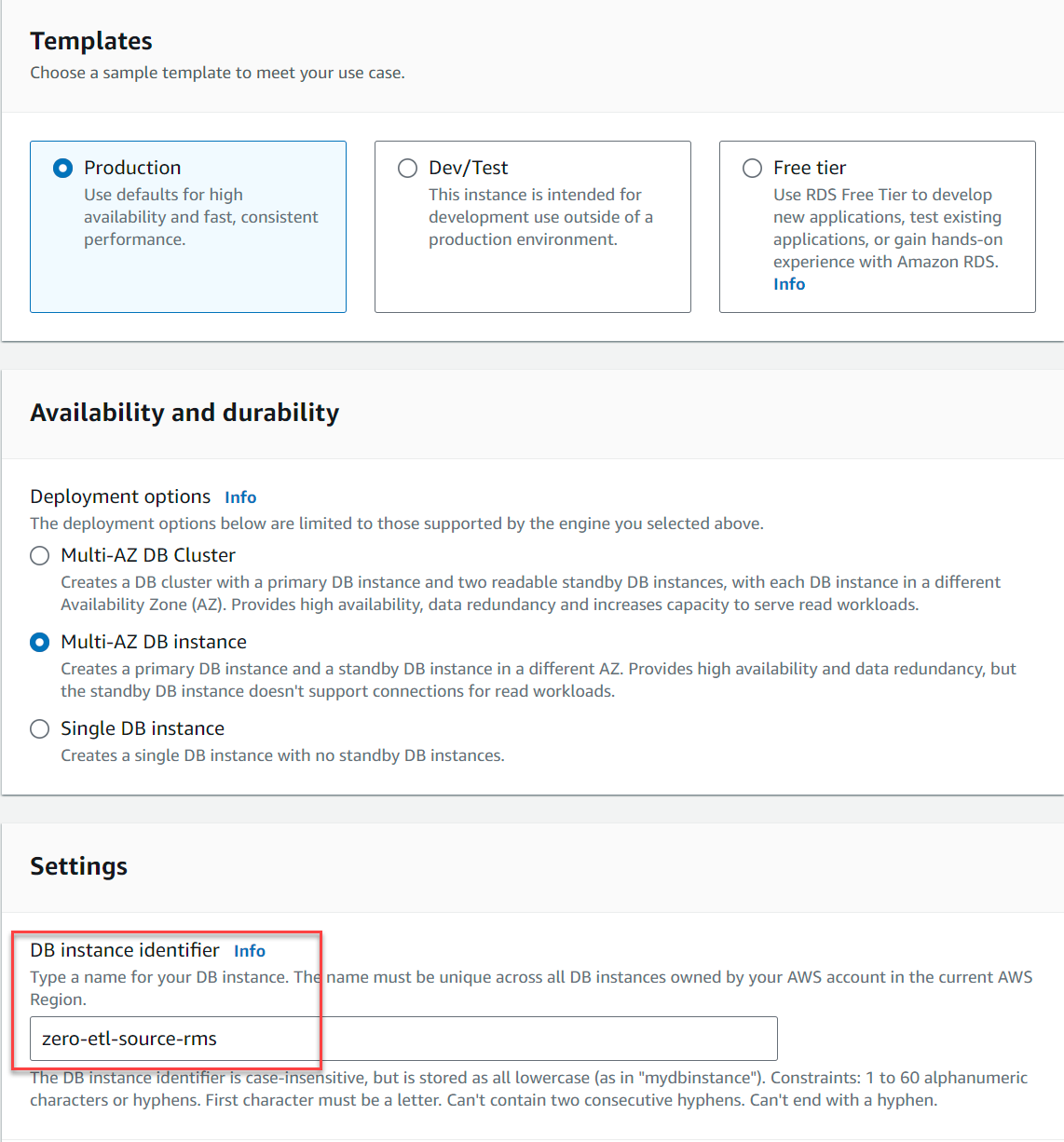
- Escolha Modelos, selecione Produção.
- Escolha Disponibilidade e durabilidade, selecione Instância de banco de dados Multi-AZ or Instância de banco de dados única (Clusters de banco de dados Multi-AZ não são suportados até o momento desta redação).
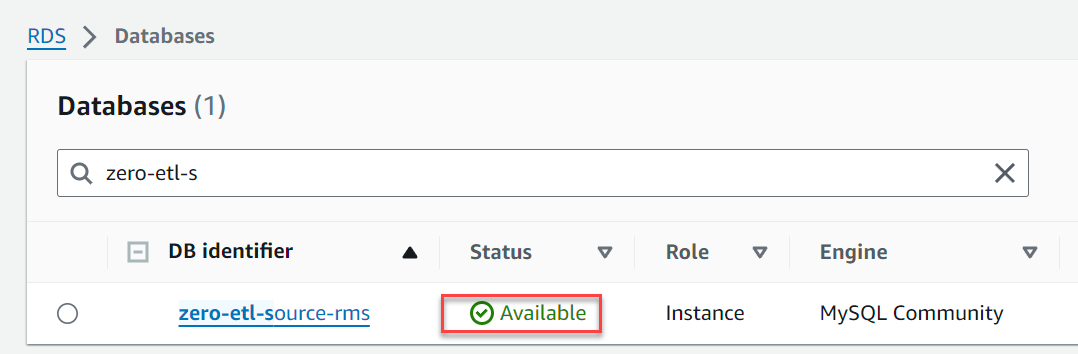
- Escolha Identificador da instância de banco de dados, entrar
zero-etl-source-rms.
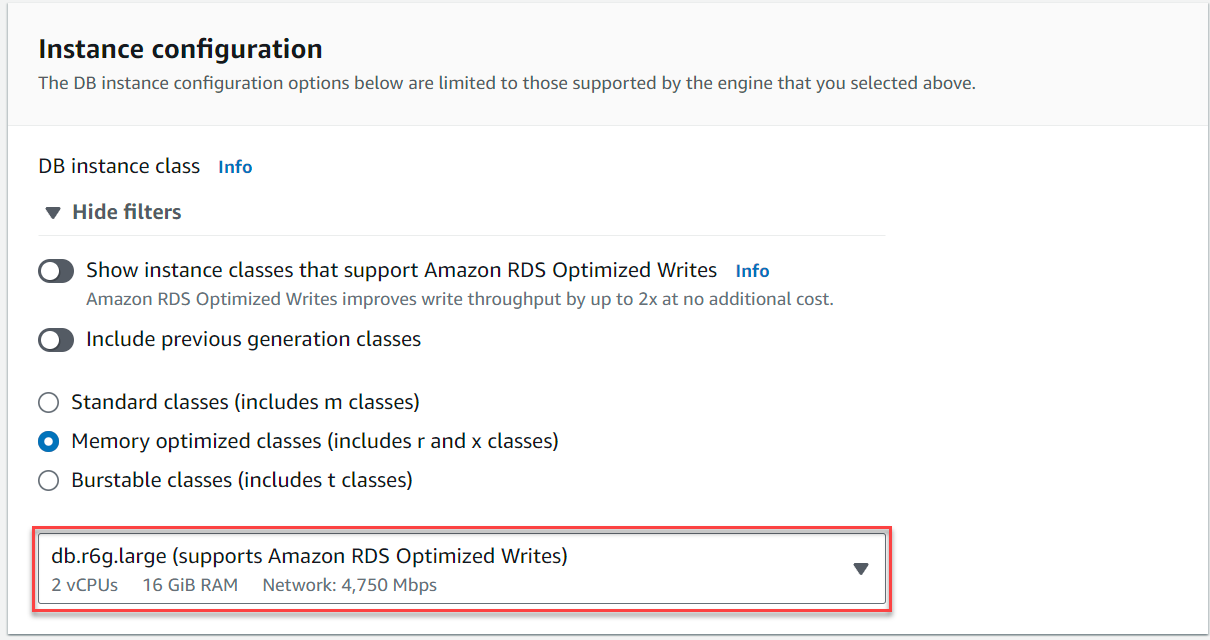
- Debaixo Configuração da instância, selecione Classes com otimização de memória e escolha a instância
db.r6g.large, o que deve ser suficiente para o caso de uso do TICKIT.
- Debaixo Configuração adicional, Por Grupo de parâmetros do cluster de banco de dados, escolha o grupo de parâmetros que você criou anteriormente (
zero-etl-custom-pg).
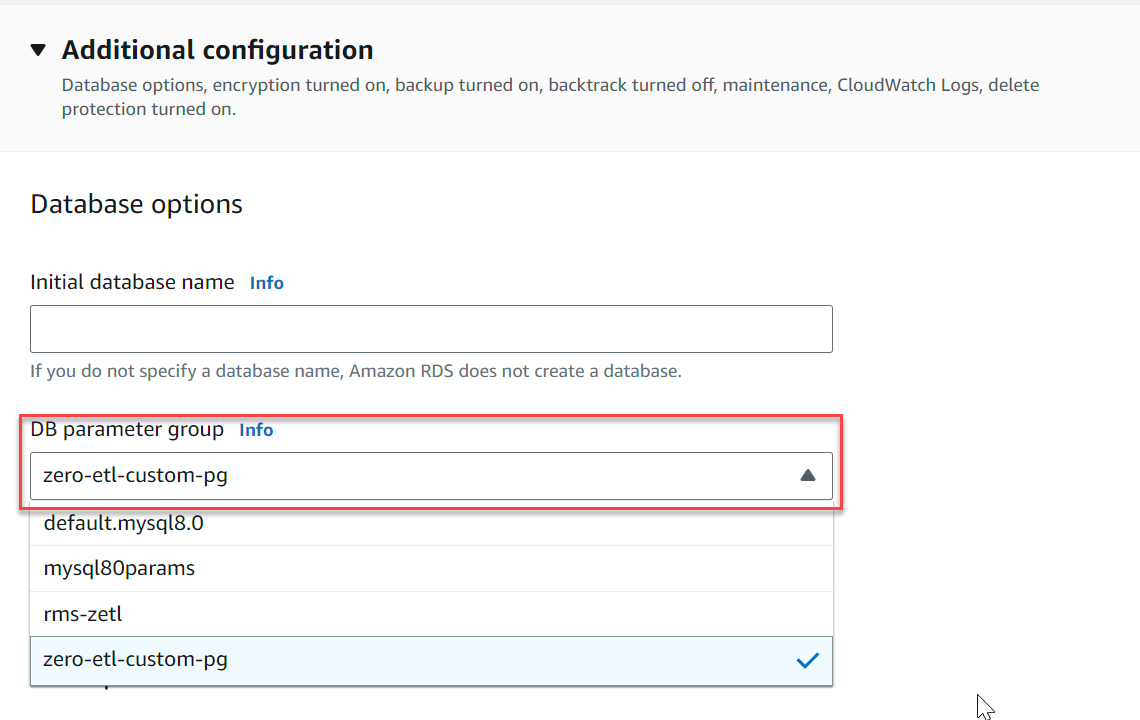
- Escolha Criar banco de dados.
Em alguns minutos, ele deverá ativar um banco de dados RDS para MySQL como fonte para integração ETL zero.
Configurar o destino do Redshift
Depois de criar o cluster de banco de dados de origem, você deverá criar e configurar um data warehouse de destino no Amazon Redshift. O data warehouse deve atender aos seguintes requisitos:
- Usando um tipo de nó RA3 (
ra3.16xlarge,ra3.4xlargeoura3.xlplus) ou Sem servidor Amazon Redshift - Criptografado (se estiver usando um cluster provisionado)
Para nosso caso de uso, crie um cluster Redshift concluindo as seguintes etapas:
- No console do Amazon Redshift, escolha configurações e depois escolha Gerenciamento de carga de trabalho.
- Na seção do grupo de parâmetros, escolha Crie.
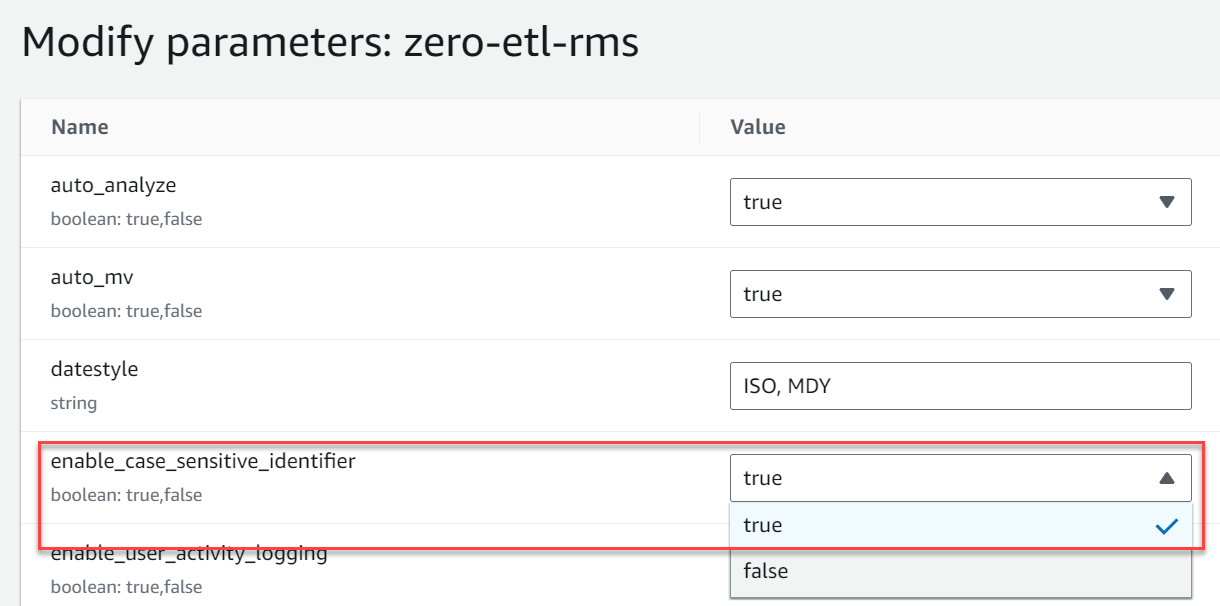
- Crie um novo grupo de parâmetros chamado
zero-etl-rms. - Escolha Editar parâmetros e mudar o valor de
enable_case_sensitive_identifierparaTrue. - Escolha Salvar.
Você também pode usar o Interface de linha de comando da AWS Comando (AWS CLI) grupo de trabalho de atualização para Redshift sem servidor:
- Escolha Painel de clusters provisionados.
Na parte superior da janela do console, você verá um Experimente os novos recursos do Amazon Redshift na visualização bandeira.
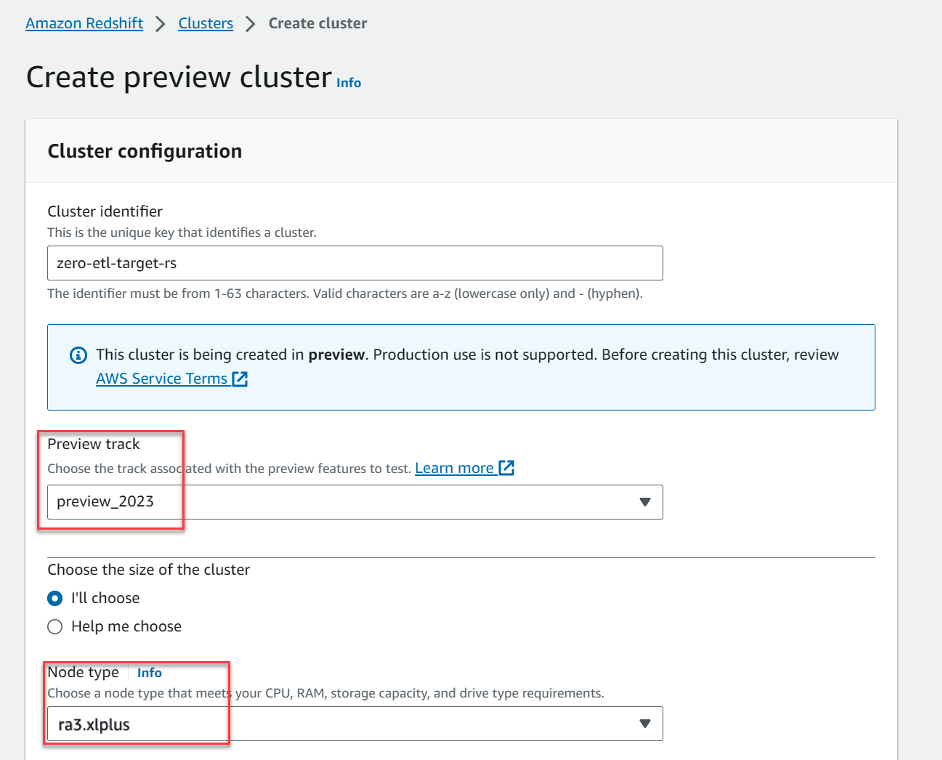
- Escolha Criar cluster de visualização.

- Escolha Faixa de visualização, escolheu
preview_2023. - Escolha Tipo de nó, escolha um dos tipos de nós suportados (para esta postagem, usamos
ra3.xlplus).
- Debaixo Configurações adicionais, expandir Configurações de banco de dados.
- Escolha Grupos de parâmetros, escolha
zero-etl-rms. - Escolha Criptografia, selecione Use o serviço de gerenciamento de chaves da AWS.
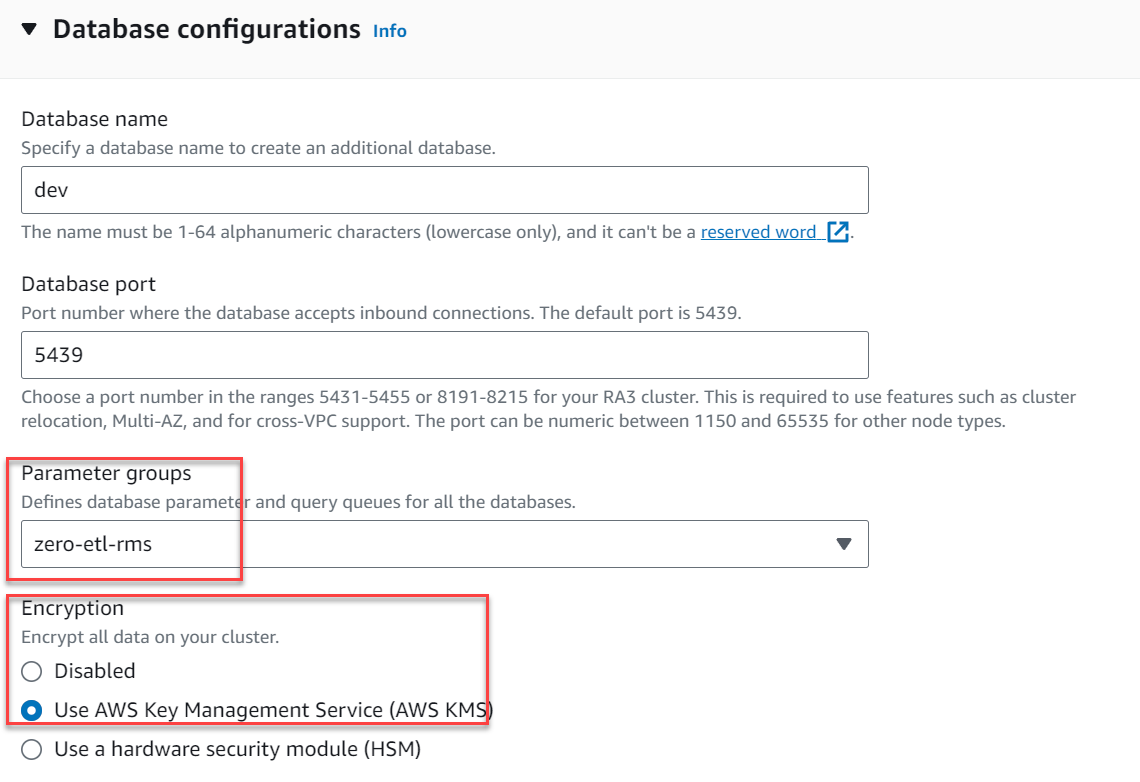
- Escolha Criar cluster.
O cluster deve se tornar Disponível em alguns minutos.

- Navegue até o namespace
zero-etl-target-rs-nse escolha o política de recursos aba. - Escolha Adicionar principais autorizados.
- Insira o nome de recurso da Amazon (ARN) do usuário ou função da AWS ou o ID da conta da AWS (principais do IAM) que têm permissão para criar integrações.
Um ID de conta é armazenado como um ARN com usuário root.
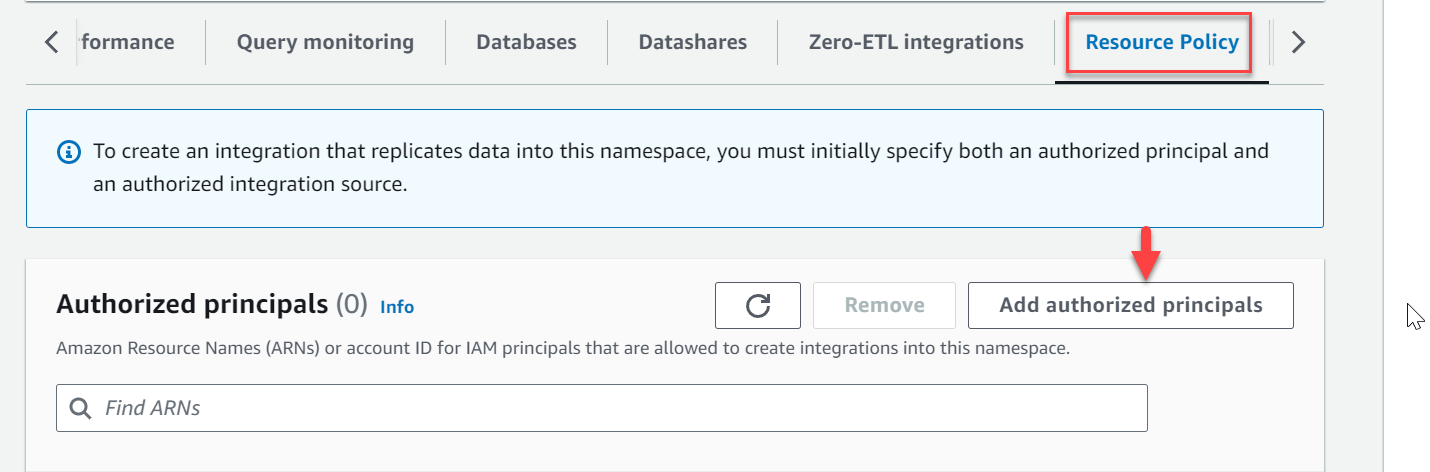
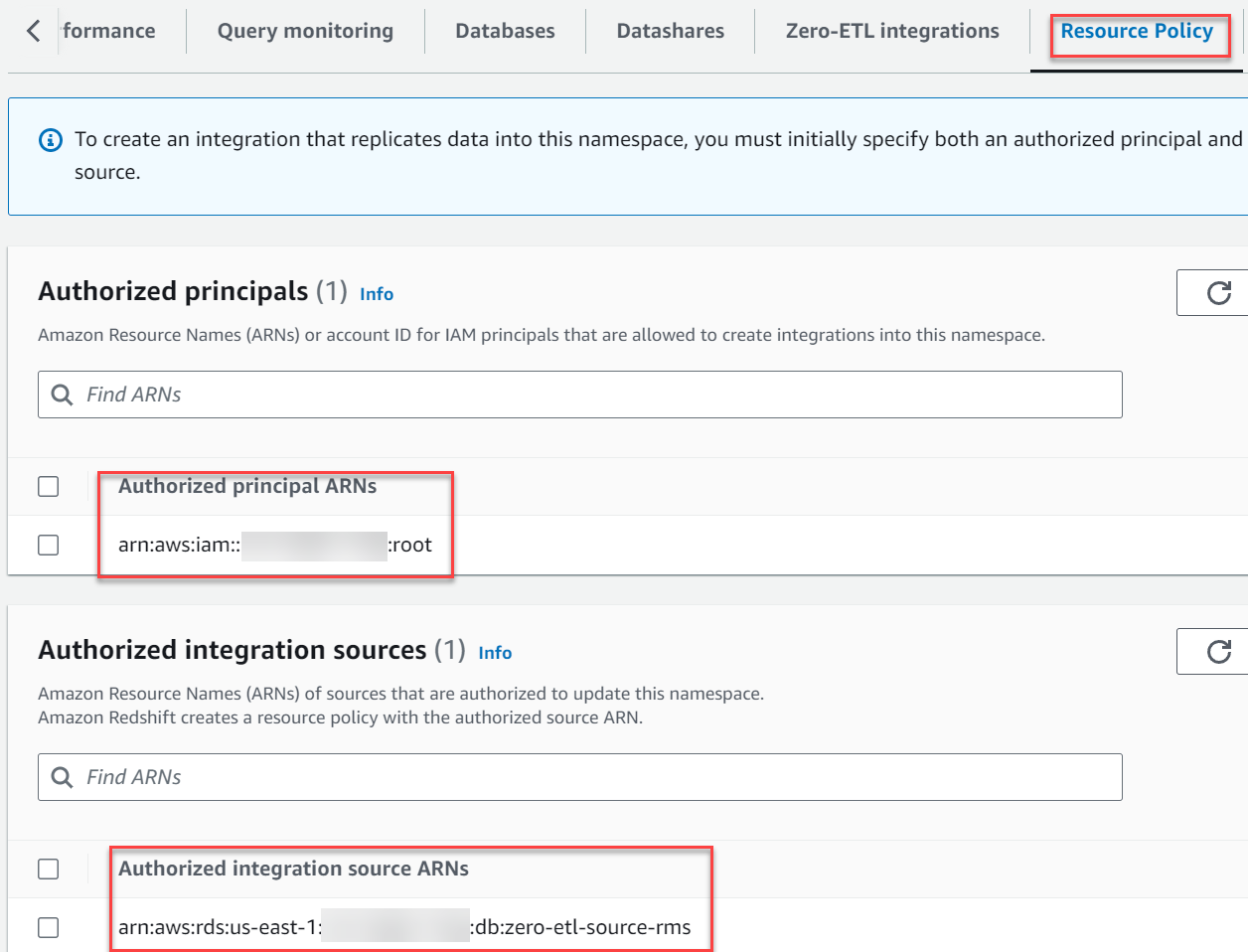
- No Fontes de integração autorizadas seção, escolha Adicionar fonte de integração autorizada para adicionar o ARN da instância de banco de dados do RDS for MySQL que é a fonte de dados para a integração de ETL zero.
Você pode encontrar esse valor acessando o console do Amazon RDS e navegando até o Configuração guia do zero-etl-source-rms Instância de banco de dados.

Sua política de recursos deve ser semelhante à captura de tela a seguir.
Configurar as permissões necessárias
Para criar uma integração zero-ETL, seu usuário ou função deve ter um anexo política baseada em identidade com o apropriado Gerenciamento de acesso e identidade da AWS (IAM). O proprietário de uma conta da AWS pode configurar as permissões necessárias para usuários ou funções que podem criar integrações sem ETL. A política de amostra permite que o principal associado execute as seguintes ações:
- Crie integrações sem ETL para a instância de banco de dados RDS for MySQL de origem.
- Visualize e exclua todas as integrações zero-ETL.
- Crie integrações de entrada no data warehouse de destino. Essa permissão não será necessária se a mesma conta for proprietária do data warehouse do Redshift e essa conta for uma entidade autorizada para esse data warehouse. Observe também que o Amazon Redshift tem um formato de ARN diferente para clusters provisionados e sem servidor:
- Provisionado -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - Serverless -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
- Provisionado -
Conclua as etapas a seguir para configurar as permissões:
- No console IAM, escolha Políticas internas no painel de navegação.
- Escolha Criar política.
- Crie uma nova política chamada
rds-integrationsusando o seguinte JSON (substituaregioneaccount-idcom seus valores reais):
{
"Version": "2012-10-17",
"Statement": [{
"Effect": "Allow",
"Action": [
"rds:CreateIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:db:source-instancename",
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"rds:DescribeIntegration"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"rds:DeleteIntegration"
],
"Resource": [
"arn:aws:rds:{region}:{account-id}:integration:*"
]
},
{
"Effect": "Allow",
"Action": [
"redshift:CreateInboundIntegration"
],
"Resource": [
"arn:aws:redshift:{region}:{account-id}:cluster:namespace-uuid"
]
}]
}
- Anexe a política que você criou às permissões de função ou usuário do IAM.
Criar a integração zero-ETL
Para criar a integração zero-ETL, conclua as seguintes etapas:
- No console do Amazon RDS, escolha Integrações Zero-ETL no painel de navegação.
- Escolha Criar integração zero-ETL.

- Escolha Identificador de integração, insira um nome, por exemplo
zero-etl-demo.
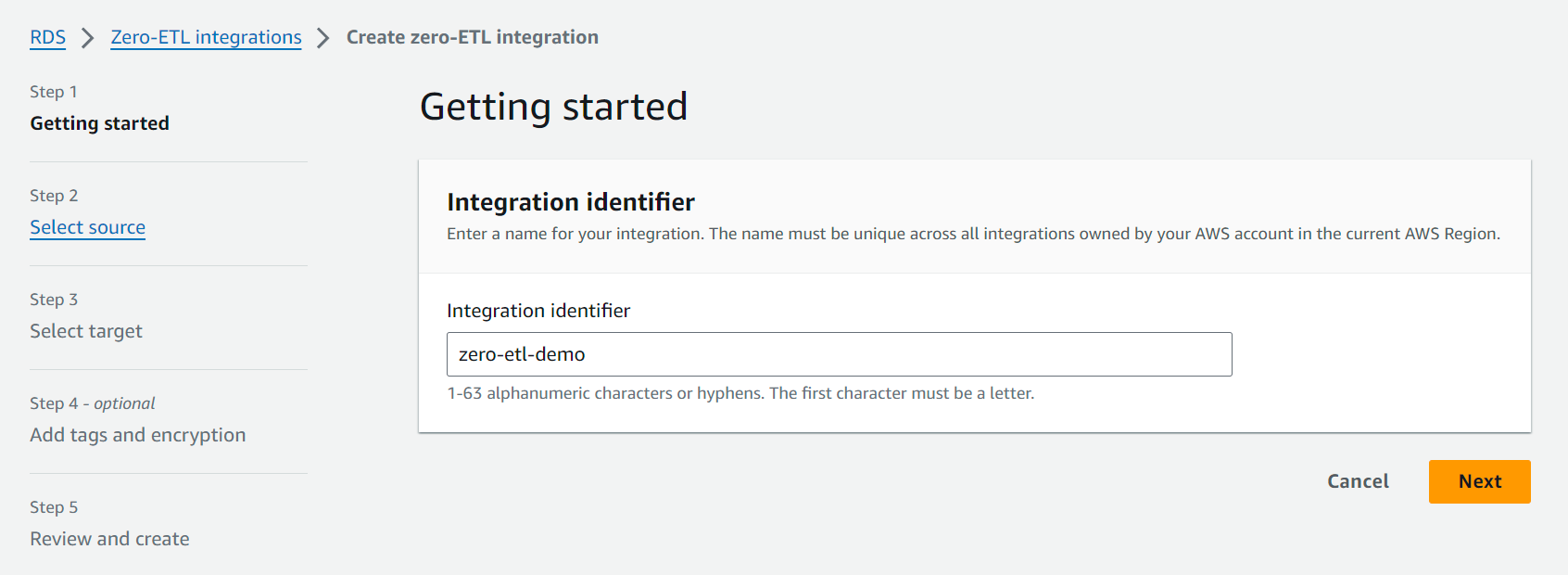
- Escolha Banco de dados fonte, escolha Navegue pelos bancos de dados RDS e escolha o cluster de origem
zero-etl-source-rms. - Escolha Próximo.

- Debaixo Target, Por Armazenamento de dados do Amazon Redshift, escolha Navegue pelos data warehouses do Redshift e escolha o data warehouse Redshift (
zero-etl-target-rs). - Escolha Próximo.
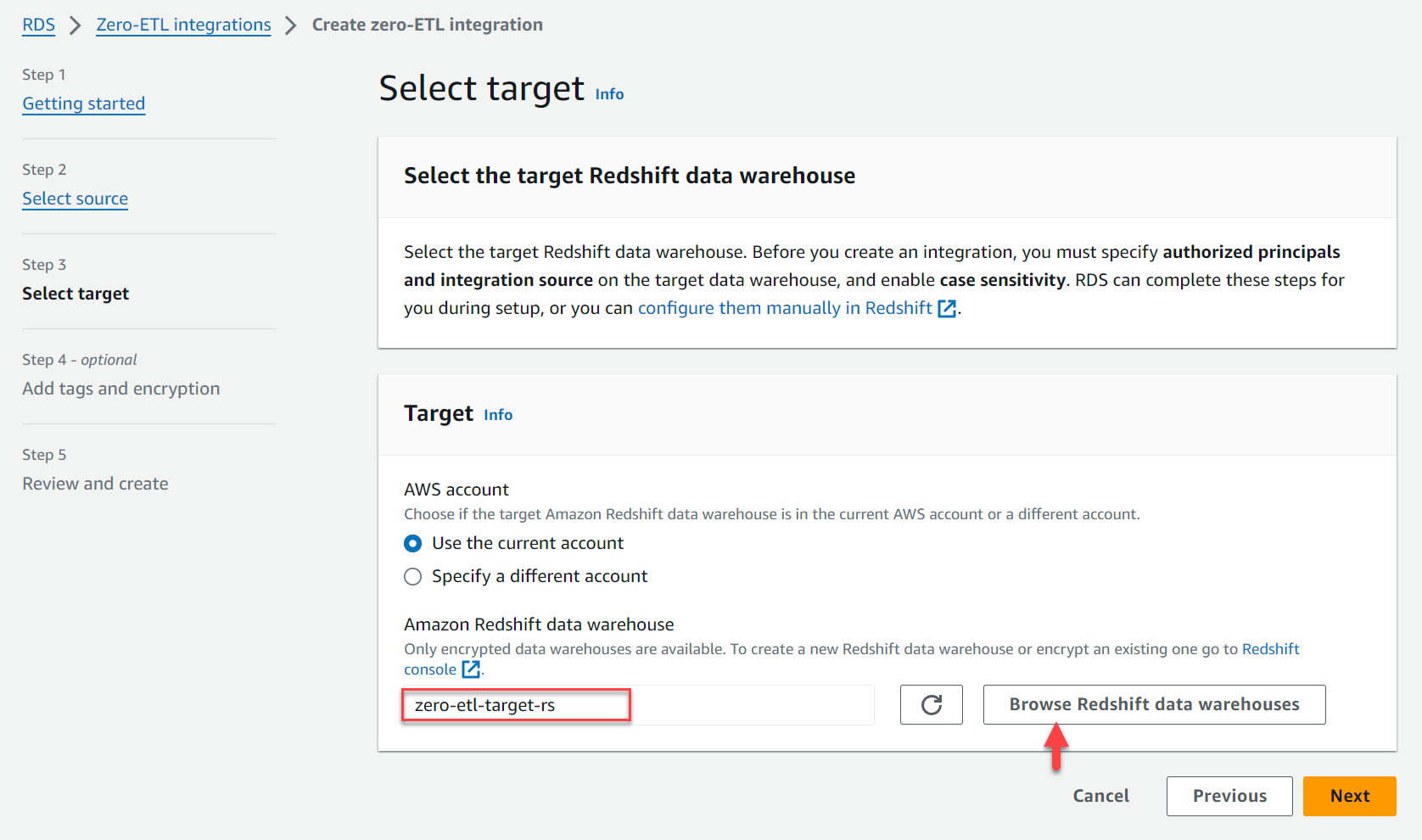
- Adicione tags e criptografia, se aplicável.
- Escolha Próximo.
- Verifique o nome da integração, origem, destino e outras configurações.
- Escolha Criar integração zero-ETL.
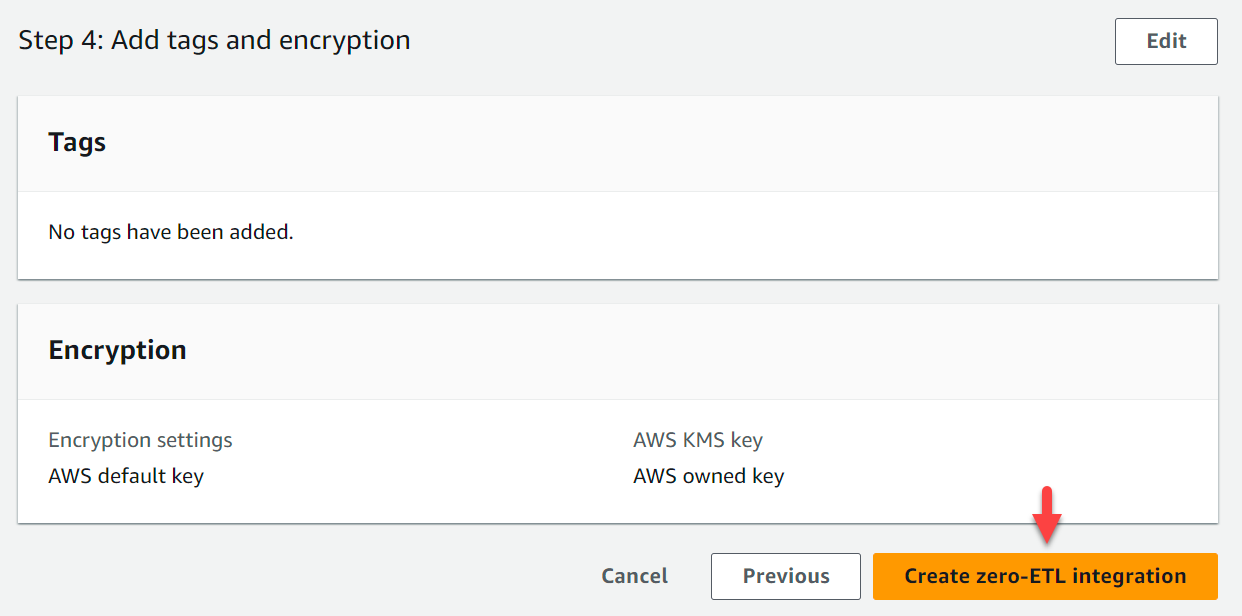
Você pode escolher a integração para visualizar os detalhes e monitorar seu andamento. Demorou cerca de 30 minutos para o status mudar de Criar para Ativo.

O tempo irá variar dependendo do tamanho do seu conjunto de dados na origem.
Crie um banco de dados a partir da integração no Amazon Redshift
Para criar seu banco de dados a partir da integração zero-ETL, conclua as seguintes etapas:
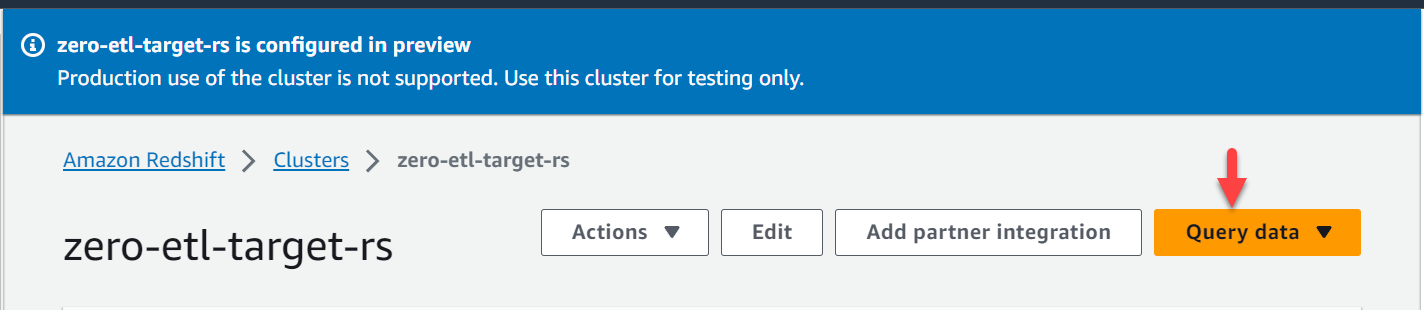
- No console do Amazon Redshift, escolha Clusters no painel de navegação.
- Abra o
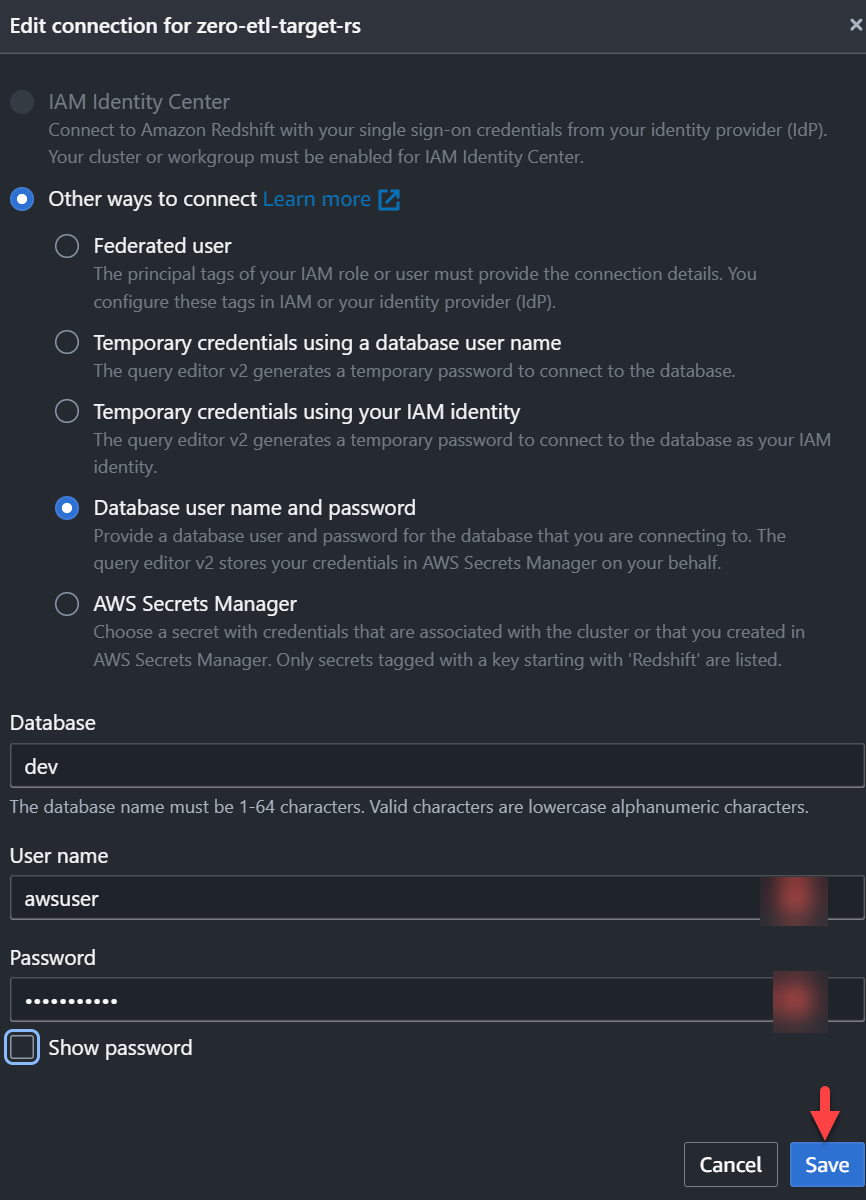
zero-etl-target-rsgrupo. - Escolha Dados de consulta para abrir o editor de consultas v2.
- Conecte-se ao data warehouse do Redshift escolhendo Salvar.
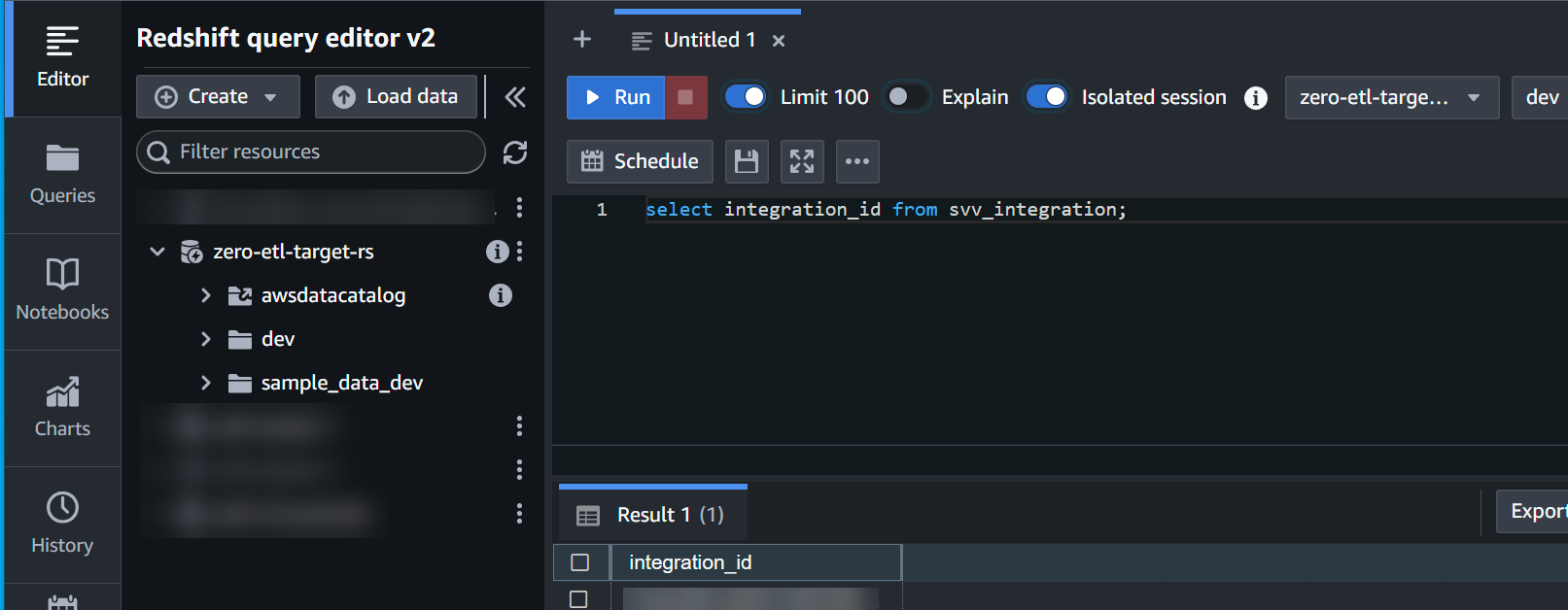
- Obtenha o
integration_iddosvv_integrationtabela do sistema:
select integration_id from svv_integration; -- copy this result, use in the next sql
- Use o
integration_idda etapa anterior para criar um novo banco de dados a partir da integração:
CREATE DATABASE zetl_source FROM INTEGRATION '<result from above>';
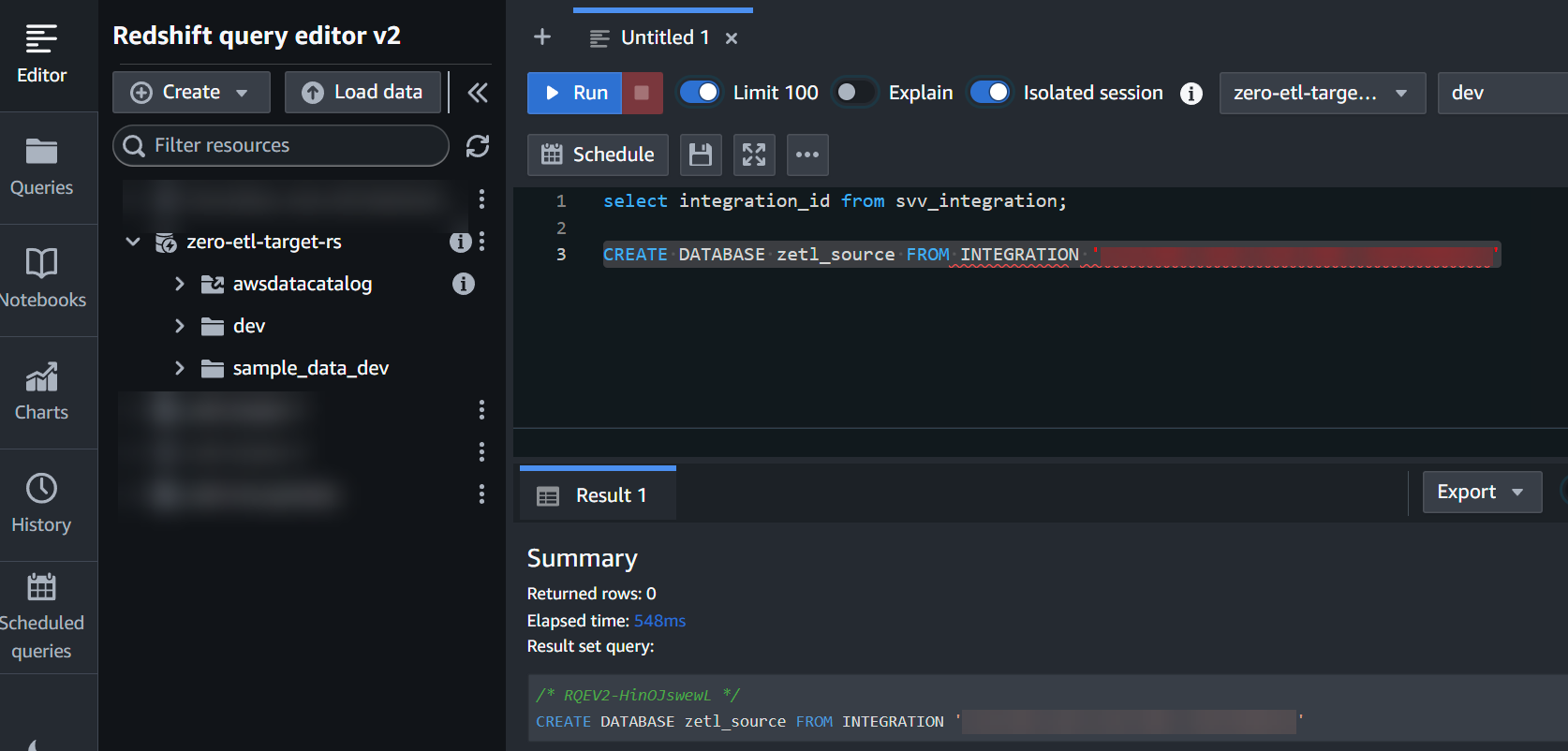
A integração agora está concluída e um instantâneo completo da origem refletirá como está no destino. As alterações em andamento serão sincronizadas quase em tempo real.
Analise os dados transacionais quase em tempo real
Agora podemos executar análises nos dados operacionais do TICKIT.
Preencha os dados TICKIT de origem
Para preencher os dados de origem, conclua as seguintes etapas:
- Copie os arquivos de dados de entrada CSV em um diretório local. A seguir está um exemplo de comando:
aws s3 cp 's3://redshift-blogs/zero-etl-integration/data/tickit' . --recursive
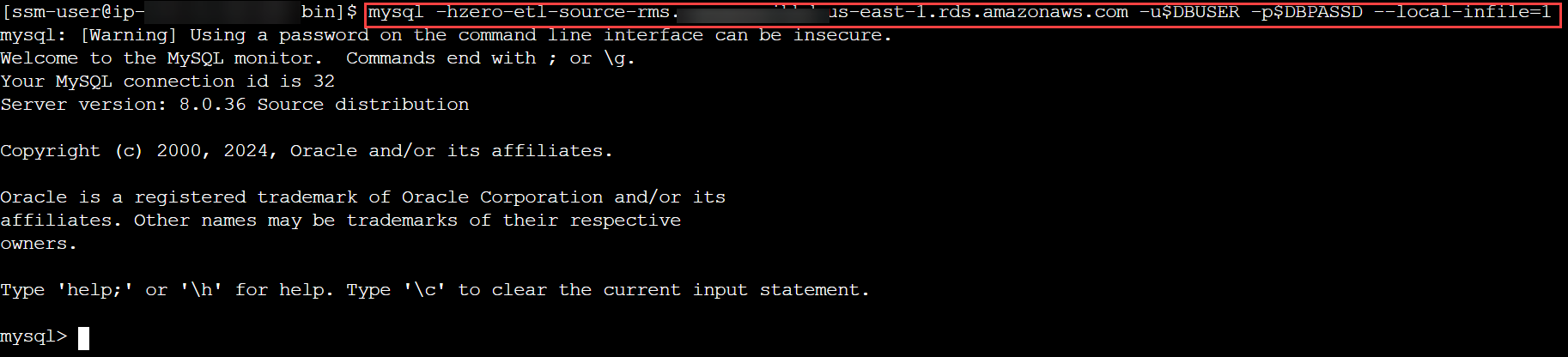
- Conecte-se ao cluster do RDS for MySQL e crie um banco de dados ou esquema para o modelo de dados TICKIT, verifique se as tabelas nesse esquema têm uma chave primária e inicie o processo de carregamento:
mysql -h <rds_db_instance_endpoint> -u admin -p password --local-infile=1
- Use o seguinte Comandos CREATE TABLE.
- Carregue os dados dos arquivos locais usando o comando LOAD DATA.
O seguinte é um exemplo. Observe que o arquivo CSV de entrada está dividido em vários arquivos. Este comando deve ser executado para cada arquivo se você quiser carregar todos os dados. Para fins de demonstração, um carregamento parcial de dados também deve funcionar.

Analise os dados TICKIT de origem no destino
No console do Amazon Redshift, abra o editor de consultas v2 usando o banco de dados criado como parte da configuração da integração. Use o código a seguir para validar a atividade seed ou CDC:

Agora você pode aplicar sua lógica de negócios para transformações diretamente nos dados que foram replicados no data warehouse. Você também pode usar técnicas de otimização de desempenho, como a criação de uma visualização materializada do Redshift que une as tabelas replicadas e outras tabelas locais para melhorar o desempenho das consultas analíticas.
do Paciente
Você pode consultar as seguintes visualizações e tabelas do sistema no Amazon Redshift para obter informações sobre suas integrações de ETL zero com o Amazon Redshift:
Para visualizar as métricas relacionadas à integração publicadas no Amazon CloudWatch, abra o console do Amazon Redshift. Escolher Integrações Zero-ETL no painel de navegação e escolha a integração para exibir métricas de atividade.
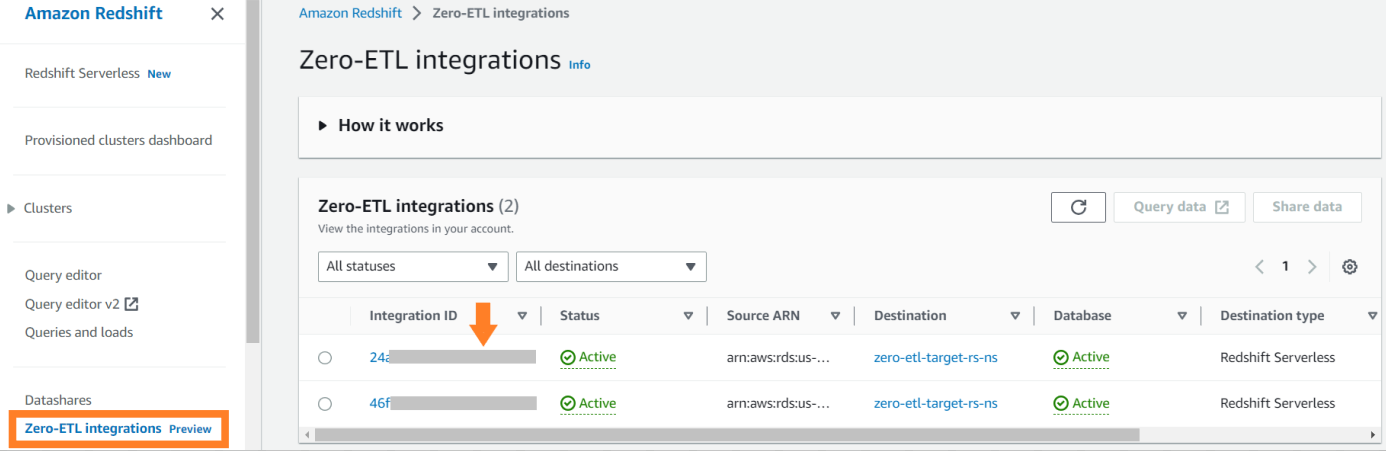
As métricas disponíveis no console do Amazon Redshift são métricas de integração e estatísticas de tabela, com estatísticas de tabela fornecendo detalhes de cada tabela replicada do Amazon RDS for MySQL para o Amazon Redshift.

As métricas de integração contêm contagens de sucesso e falha na replicação da tabela e detalhes de atraso.
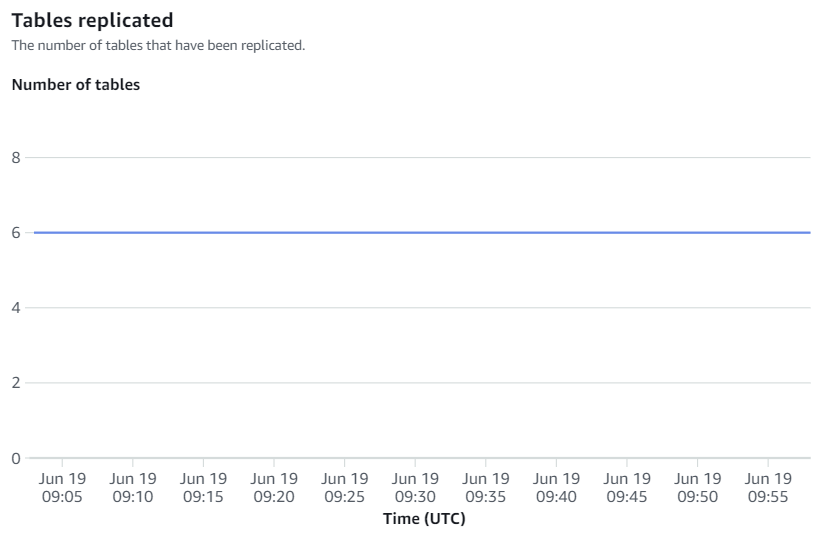
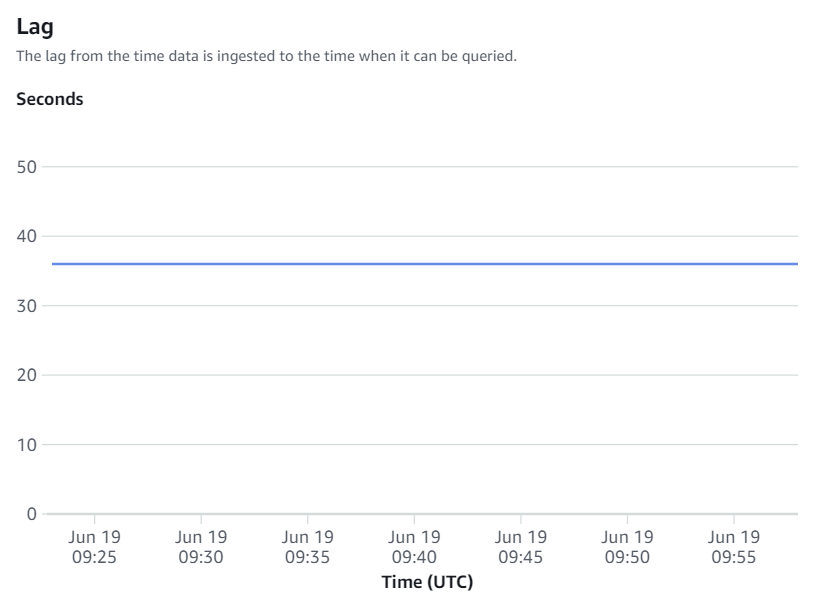
Ressincronizações manuais
A integração zero-ETL iniciará automaticamente uma ressincronização se o estado de sincronização de uma tabela for exibido como com falha ou se a ressincronização for necessária. Mas caso a ressincronização automática falhe, você pode iniciar uma ressincronização na granularidade no nível da tabela:
ALTER DATABASE zetl_source INTEGRATION REFRESH TABLES tbl1, tbl2;
Uma tabela pode entrar em estado de falha por vários motivos:
- A chave primária foi removida da tabela. Nesses casos, você precisa adicionar novamente a chave primária e executar o comando ALTER mencionado anteriormente.
- Um valor inválido é encontrado durante a replicação ou uma nova coluna é adicionada à tabela com um tipo de dados não suportado. Nesses casos, você precisa remover a coluna com o tipo de dados não suportado e executar o comando ALTER mencionado anteriormente.
- Um erro interno, em casos raros, pode causar falha na tabela. O comando ALTER deve corrigir isso.
limpar
Quando você exclui uma integração sem ETL, seus dados transacionais não são excluídos dos bancos de dados de origem do RDS ou de destino do Redshift, mas o Amazon RDS não envia novas alterações ao Amazon Redshift.
Para excluir uma integração zero-ETL, conclua as seguintes etapas:
- No console do Amazon RDS, escolha Integrações Zero-ETL no painel de navegação.
- Selecione a integração zero-ETL que você deseja excluir e escolha Apagar.
- Para confirmar a exclusão, selecione Apagar.

Conclusão
Nesta postagem, mostramos como configurar uma integração ETL zero do Amazon RDS for MySQL com o Amazon Redshift. Isso minimiza a necessidade de manter pipelines de dados complexos e permite análises quase em tempo real de dados transacionais e operacionais.
Para saber mais sobre a integração zero-ETL do Amazon RDS com o Amazon Redshift, consulte Trabalhar com integrações de ETL zero do Amazon RDS com o Amazon Redshift (pré-visualização).
Sobre os autores
 Milind Oke é arquiteto sênior de soluções especializadas em Redshift e trabalha na Amazon Web Services há três anos. Ele é um SA Associate certificado pela AWS, detentor de certificação de especialidade de segurança e especialidade de análise, baseado em Queens, Nova York.
Milind Oke é arquiteto sênior de soluções especializadas em Redshift e trabalha na Amazon Web Services há três anos. Ele é um SA Associate certificado pela AWS, detentor de certificação de especialidade de segurança e especialidade de análise, baseado em Queens, Nova York.
 Aditya Samant é um veterano do setor de bancos de dados relacionais com mais de 2 décadas de experiência trabalhando com bancos de dados comerciais e de código aberto. Atualmente, ele trabalha na Amazon Web Services como arquiteto principal de soluções especialista em banco de dados. Em sua função, ele passa tempo trabalhando com clientes projetando arquiteturas nativas de nuvem escaláveis, seguras e robustas. Aditya trabalha em estreita colaboração com as equipes de serviço e colabora no design e na entrega de novos recursos para os bancos de dados gerenciados da Amazon.
Aditya Samant é um veterano do setor de bancos de dados relacionais com mais de 2 décadas de experiência trabalhando com bancos de dados comerciais e de código aberto. Atualmente, ele trabalha na Amazon Web Services como arquiteto principal de soluções especialista em banco de dados. Em sua função, ele passa tempo trabalhando com clientes projetando arquiteturas nativas de nuvem escaláveis, seguras e robustas. Aditya trabalha em estreita colaboração com as equipes de serviço e colabora no design e na entrega de novos recursos para os bancos de dados gerenciados da Amazon.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/unlock-insights-on-amazon-rds-for-mysql-data-with-zero-etl-integration-to-amazon-redshift/

