O volume de dados gerados globalmente continua a aumentar, desde jogos, varejo e finanças até manufatura, saúde e viagens. As organizações estão procurando mais maneiras de usar rapidamente o fluxo constante de dados para inovar para seus negócios e clientes. Eles precisam capturar, processar, analisar e carregar os dados de maneira confiável em uma infinidade de armazenamentos de dados, tudo em tempo real.
Apache Kafka é uma escolha popular para essas necessidades de streaming em tempo real. No entanto, pode ser um desafio configurar um cluster Kafka junto com outros componentes de processamento de dados que são dimensionados automaticamente dependendo das necessidades do seu aplicativo. Você corre o risco de provisionamento insuficiente para tráfego de pico, o que pode levar a tempo de inatividade, ou de provisionamento excessivo para carga base, levando ao desperdício. AWS oferece vários serviços sem servidor, como Amazon Managed Streaming para Apache Kafka (Amazônia MSK), Amazon Data Firehose, Amazon DynamoDB e AWS Lambda essa escala automaticamente dependendo de suas necessidades.
Neste post, explicamos como você pode usar alguns desses serviços, incluindo MSK sem servidor, para construir uma plataforma de dados sem servidor para atender às suas necessidades em tempo real.
Visão geral da solução
Vamos imaginar um cenário. Você é responsável por gerenciar milhares de modems para um provedor de serviços de Internet implantado em diversas regiões geográficas. Você deseja monitorar a qualidade da conectividade do modem que tem um impacto significativo na produtividade e na satisfação do cliente. Sua implantação inclui modems diferentes que precisam ser monitorados e mantidos para garantir tempo de inatividade mínimo. Cada dispositivo transmite milhares de registros de 1 KB a cada segundo, como uso de CPU, uso de memória, alarme e status de conexão. Você deseja acesso em tempo real a esses dados para poder monitorar o desempenho em tempo real e detectar e mitigar problemas rapidamente. Você também precisa de acesso de longo prazo a esses dados para modelos de aprendizado de máquina (ML) para executar avaliações de manutenção preditiva, encontrar oportunidades de otimização e prever a demanda.
Seus clientes que coletam os dados no local são escritos em Python e podem enviar todos os dados como tópicos do Apache Kafka para o Amazon MSK. Para acesso aos dados de baixa latência e em tempo real do seu aplicativo, você pode usar Lambda e DynamoDB. Para armazenamento de dados de longo prazo, você pode usar o serviço de conector sem servidor gerenciado Amazon Data Firehose para enviar dados para seu data lake.
O diagrama a seguir mostra como você pode construir esse aplicativo sem servidor de ponta a ponta.
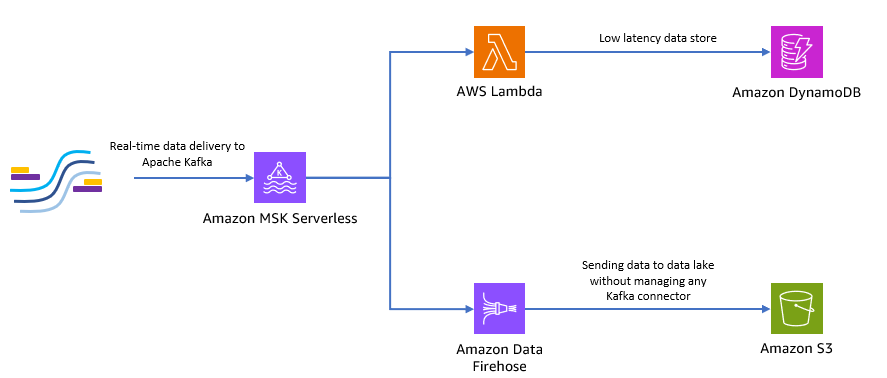
Vamos seguir as etapas nas seções a seguir para implementar essa arquitetura.
Crie um cluster Kafka sem servidor no Amazon MSK
Usamos o Amazon MSK para ingerir dados de telemetria em tempo real de modems. Criar um cluster Kafka sem servidor é simples no Amazon MSK. Leva apenas alguns minutos usando o Console de gerenciamento da AWS ou SDK da AWS. Para usar o console, consulte Introdução ao uso de clusters MSK Serverless. Você cria um cluster sem servidor, Gerenciamento de acesso e identidade da AWS (IAM) e máquina cliente.
Crie um tópico Kafka usando Python
Quando o cluster e a máquina cliente estiverem prontos, faça SSH na máquina cliente e instale o Kafka Python e a biblioteca MSK IAM para Python.
- Execute os seguintes comandos para instalar o Kafka Python e o Biblioteca MSK IAM:
- Crie um novo arquivo chamado
createTopic.py. - Copie o código a seguir neste arquivo, substituindo o
bootstrap_serverseregioninformações com os detalhes do seu cluster. Para obter instruções sobre como recuperar obootstrap_serversinformações para seu cluster MSK, consulte Obtendo os agentes de bootstrap para um cluster do Amazon MSK.
- execute o
createTopic.pyscript para criar um novo tópico Kafka chamadomytopicem seu cluster sem servidor:
Produza registros usando Python
Vamos gerar alguns exemplos de dados de telemetria do modem.
- Crie um novo arquivo chamado
kafkaDataGen.py. - Copie o código a seguir neste arquivo, atualizando o
BROKERSeregioninformações com os detalhes do seu cluster:
- execute o
kafkaDataGen.pypara gerar continuamente dados aleatórios e publicá-los no tópico Kafka especificado:
Armazenar eventos no Amazon S3
Agora você armazena todos os dados brutos do evento em um Serviço de armazenamento simples da Amazon (Amazon S3) data lake para análise. Você pode usar os mesmos dados para treinar modelos de ML. O integração com Amazon Data Firehose permite que o Amazon MSK carregue perfeitamente dados de clusters Apache Kafka em um data lake S3. Conclua as etapas a seguir para transmitir dados continuamente do Kafka para o Amazon S3, eliminando a necessidade de criar ou gerenciar seus próprios aplicativos de conector:
- No console do Amazon S3, crie um novo bucket. Você também pode usar um bucket existente.
- Crie uma nova pasta em seu bucket S3 chamada
streamingDataLake. - No console do Amazon MSK, escolha seu cluster MSK Serverless.
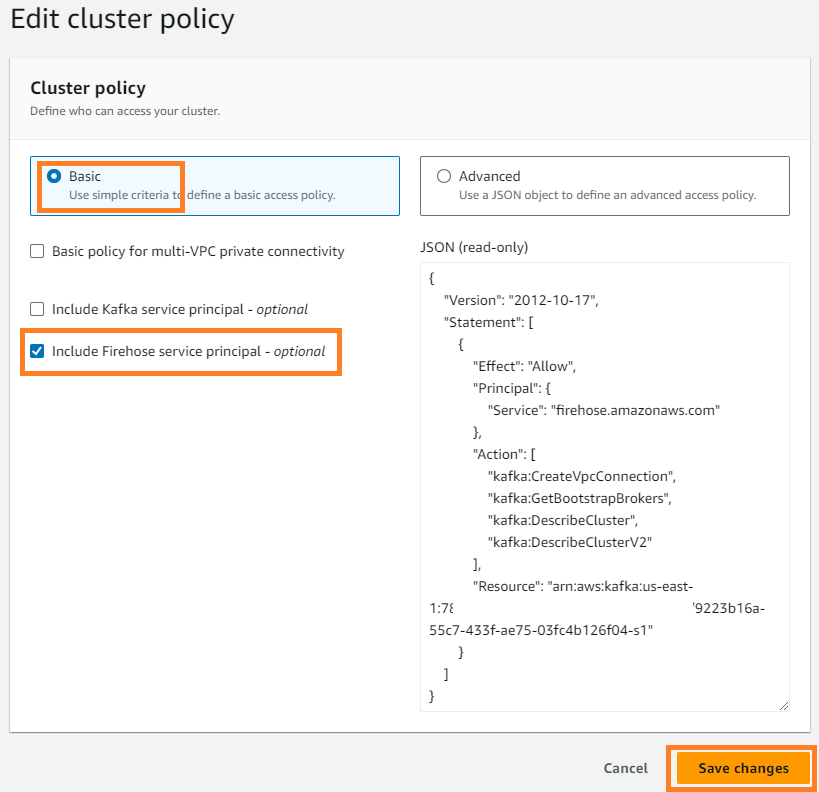
- No Opções menu, escolha Editar política de cluster.

- Selecionar Incluir entidade de serviço Firehose e escolha Salvar as alterações .
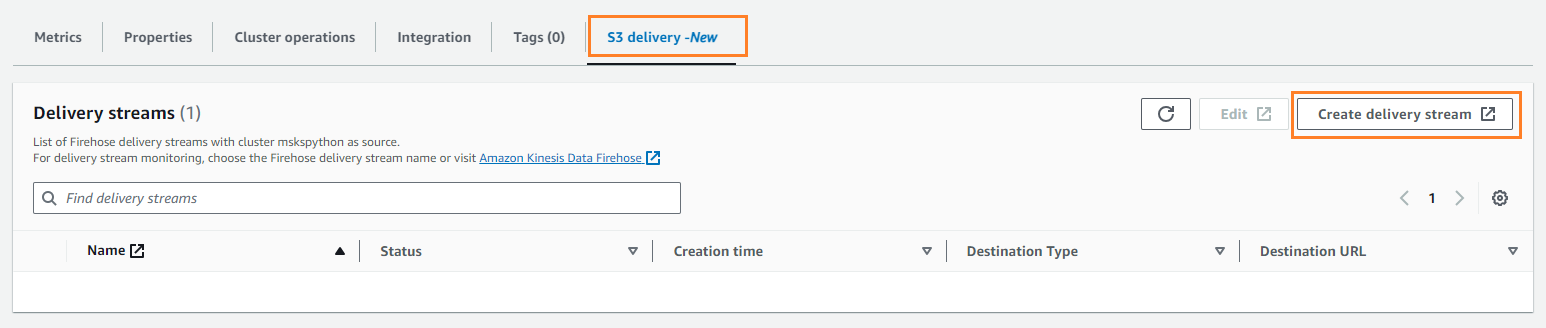
- No Entrega S3 guia, escolha Criar fluxo de entrega.
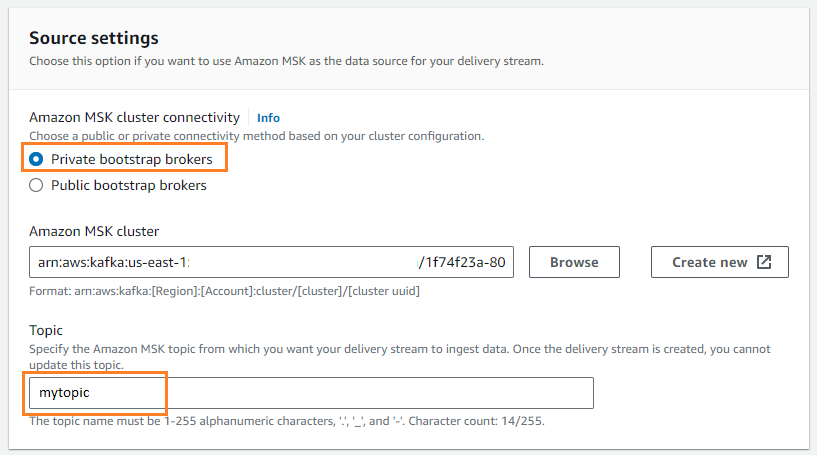
- Escolha fonte, escolha Amazon MSK.
- Escolha Destino, escolha Amazon S3.

- Escolha Conectividade de cluster do Amazon MSK, selecione Corretores de bootstrap privados.
- Escolha Tema, insira um nome de tópico (para esta postagem,
mytopic).
- Escolha Caçamba S3, escolha Procurar e escolha seu bucket do S3.
- Entrar
streamingDataLakecomo seu prefixo de bucket S3. - Entrar
streamingDataLakeErrcomo seu prefixo de saída de erro do bucket S3.

- Escolha Criar fluxo de entrega.
Você pode verificar se os dados foram gravados em seu bucket S3. Você deveria ver que o streamingDataLake diretório foi criado e os arquivos são armazenados em partições.
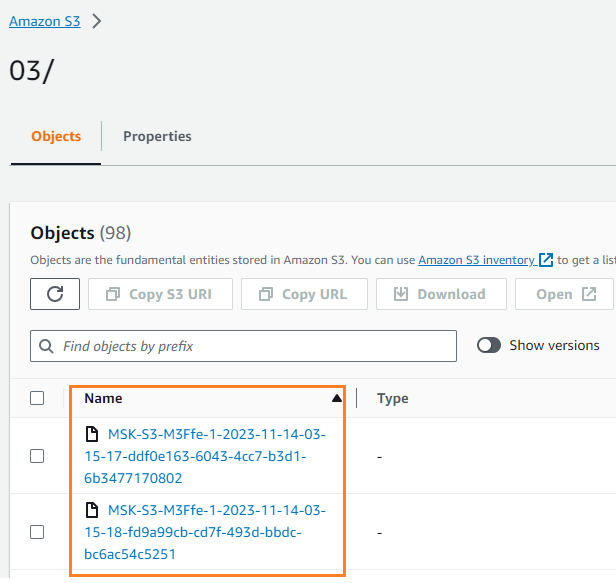
Armazenar eventos no DynamoDB
Na última etapa, você armazena os dados mais recentes do modem no DynamoDB. Isso permite que a aplicação cliente acesse o status do modem e interaja com ele remotamente de qualquer lugar, com baixa latência e alta disponibilidade. Lambda funciona perfeitamente com Amazon MSK. O Lambda pesquisa internamente novas mensagens da origem do evento e, em seguida, invoca de forma síncrona a função Lambda de destino. O Lambda lê as mensagens em lotes e as fornece à sua função como uma carga de evento.
Vamos primeiro criar uma tabela no DynamoDB. Referir-se Permissões da API DynamoDB: referência de ações, recursos e condições para verificar se sua máquina cliente tem as permissões necessárias.
- Crie um novo arquivo chamado
createTable.py. - Copie o código a seguir no arquivo, atualizando o
regioninformações:
- execute o
createTable.pyscript para criar uma tabela chamadadevice_statusno DynamoDB:
Agora vamos configurar a função Lambda.
- No console do Lambda, escolha Funções no painel de navegação.
- Escolha Criar função.
- Selecionar Autor do zero.
- Escolha Nome da função¸ insira um nome (por exemplo,
my-notification-kafka). - Escolha Runtime, escolha Python 3.11.
- Escolha Permissões, selecione Use uma função existente e escolha um papel com permissões para ler do seu cluster.
- Crie a função.
Na página de configuração da função Lambda, agora você pode configurar fontes, destinos e o código do seu aplicativo.
- Escolha Adicionar gatilho.
- Escolha Configuração do gatilho, entrar
MSKpara configurar o Amazon MSK como um gatilho para a função de origem do Lambda. - Escolha Cluster MSK, entrar
myCluster. - Desmarcar Ativar gatilho, porque você ainda não configurou sua função Lambda.
- Escolha Tamanho do batch, entrar
100. - Escolha Posicão inicial, escolha ÚLTIMAS.
- Escolha Nome do tópico¸ insira um nome (por exemplo,
mytopic). - Escolha Adicionar.
- Na página de detalhes da função Lambda, na guia Code guia, digite o seguinte código:
- Implante a função Lambda.
- No Configuração guia, escolha Editar para editar o gatilho.
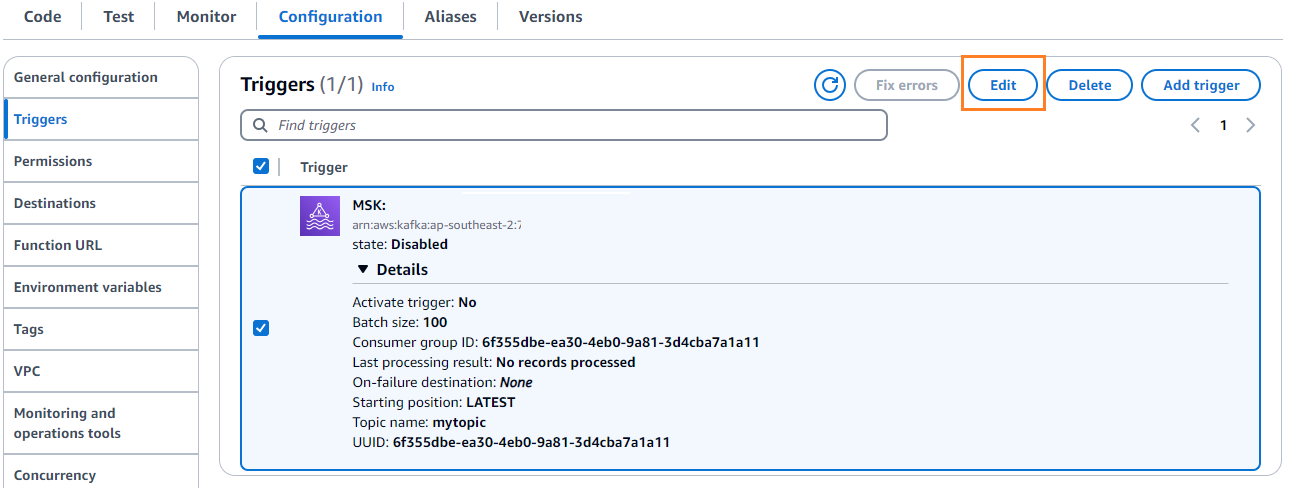
- Selecione o gatilho e escolha Salvar.
- No console do DynamoDB, escolha Explorar itens no painel de navegação.
- Selecione a mesa
device_status.
Você verá que o Lambda está gravando eventos gerados no tópico Kafka no DynamoDB.

Resumo
Pipelines de dados de streaming são essenciais para a construção de aplicativos em tempo real. No entanto, configurar e gerenciar a infraestrutura pode ser assustador. Nesta postagem, explicamos como construir um pipeline de streaming sem servidor na AWS usando Amazon MSK, Lambda, DynamoDB, Amazon Data Firehose e outros serviços. Os principais benefícios são a ausência de servidores para gerenciar, a escalabilidade automática da infraestrutura e um modelo pré-pago usando serviços totalmente gerenciados.
Pronto para construir seu próprio pipeline em tempo real? Comece hoje mesmo com uma conta AWS gratuita. Com o poder do serverless, você pode se concentrar na lógica do seu aplicativo enquanto a AWS cuida do trabalho pesado indiferenciado. Vamos construir algo incrível na AWS!
Sobre os autores
 Masudur Rahaman Sayem é arquiteto de dados de streaming na AWS. Ele trabalha com clientes da AWS em todo o mundo para projetar e construir arquiteturas de streaming de dados para resolver problemas de negócios do mundo real. Ele é especialista em otimizar soluções que usam serviços de streaming de dados e NoSQL. Sayem é muito apaixonado por computação distribuída.
Masudur Rahaman Sayem é arquiteto de dados de streaming na AWS. Ele trabalha com clientes da AWS em todo o mundo para projetar e construir arquiteturas de streaming de dados para resolver problemas de negócios do mundo real. Ele é especialista em otimizar soluções que usam serviços de streaming de dados e NoSQL. Sayem é muito apaixonado por computação distribuída.
 Michael Oguike é gerente de produto do Amazon MSK. Ele é apaixonado por usar dados para descobrir insights que impulsionam ações. Ele gosta de ajudar clientes de diversos setores a melhorar seus negócios usando streaming de dados. Michael também adora aprender sobre ciência comportamental e psicologia em livros e podcasts.
Michael Oguike é gerente de produto do Amazon MSK. Ele é apaixonado por usar dados para descobrir insights que impulsionam ações. Ele gosta de ajudar clientes de diversos setores a melhorar seus negócios usando streaming de dados. Michael também adora aprender sobre ciência comportamental e psicologia em livros e podcasts.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-serverless-streaming-pipeline-with-apache-kafka-on-amazon-msk-using-python/

