Para construir qualquer aplicativo generativo de IA, é fundamental enriquecer os grandes modelos de linguagem (LLMs) com novos dados. É aqui que entra a técnica Retrieval Augmented Generation (RAG). RAG é uma arquitetura de aprendizado de máquina (ML) que usa documentos externos (como a Wikipedia) para aumentar seu conhecimento e obter resultados de última geração em tarefas que exigem muito conhecimento. . Para ingerir essas fontes de dados externas, os bancos de dados vetoriais evoluíram, que podem armazenar incorporações vetoriais da fonte de dados e permitir pesquisas por similaridade.
Nesta postagem, mostramos como construir um pipeline de ingestão de extração, transformação e carregamento (ETL) RAG para ingerir grandes quantidades de dados em um Serviço Amazon OpenSearch agrupar e usar Amazon Relational Database Service (Amazon RDS) para PostgreSQL com a extensão pgvector como um armazenamento de dados vetoriais. Cada serviço implementa algoritmos de k-vizinho mais próximo (k-NN) ou vizinho mais próximo aproximado (ANN) e métricas de distância para calcular a similaridade. Apresentamos a integração de Raio no mecanismo de recuperação de documentos contextuais RAG. Ray é uma biblioteca de computação distribuída de código aberto, Python, de uso geral. Ele permite que o processamento distribuído de dados gere e armazene incorporações para uma grande quantidade de dados, paralelizando em várias GPUs. Usamos um cluster Ray com essas GPUs para executar ingestão e consulta paralela para cada serviço.
Neste experimento, tentamos analisar os seguintes aspectos do OpenSearch Service e da extensão pgvector no Amazon RDS:
- Como armazenamento de vetores, a capacidade de dimensionar e manipular um grande conjunto de dados com dezenas de milhões de registros para RAG
- Possíveis gargalos no pipeline de ingestão para RAG
- Como obter desempenho ideal nos tempos de ingestão e recuperação de consultas para OpenSearch Service e Amazon RDS
Para entender mais sobre armazenamentos de dados vetoriais e seu papel na construção de aplicativos generativos de IA, consulte O papel dos datastores vetoriais em aplicações generativas de IA.
Visão geral do serviço OpenSearch
OpenSearch Service é um serviço gerenciado para análise, pesquisa e indexação segura de dados comerciais e operacionais. O OpenSearch Service oferece suporte a dados em escala de petabytes com a capacidade de criar vários índices em dados de texto e vetoriais. Com configuração otimizada, visa alto recall para as consultas. O OpenSearch Service oferece suporte a RNA, bem como pesquisa exata de k-NN. O OpenSearch Service oferece suporte a uma seleção de algoritmos do NMSLIB, FAISS e lucene bibliotecas para alimentar a pesquisa k-NN. Criamos o índice ANN para OpenSearch com o algoritmo Hierarchical Navigable Small World (HNSW) porque é considerado o melhor método de pesquisa para grandes conjuntos de dados. Para obter mais informações sobre a escolha do algoritmo de índice, consulte Escolha o algoritmo k-NN para seu caso de uso em escala de bilhões com o OpenSearch.
Visão geral do Amazon RDS para PostgreSQL com pgvector
A extensão pgvector adiciona uma pesquisa de similaridade vetorial de código aberto ao PostgreSQL. Ao utilizar a extensão pgvector, o PostgreSQL pode realizar pesquisas de similaridade em incorporações de vetores, fornecendo às empresas uma solução rápida e eficiente. O pgvector fornece dois tipos de pesquisas por similaridade vetorial: vizinho mais próximo exato, que resulta com 100% de recall, e vizinho mais próximo aproximado (ANN), que fornece melhor desempenho do que a pesquisa exata com uma compensação na recuperação. Para pesquisas em um índice, você pode escolher quantos centros usar na pesquisa, com mais centros proporcionando melhor recuperação com uma compensação de desempenho.
Visão geral da solução
O diagrama a seguir ilustra a arquitetura da solução.

Vejamos os principais componentes com mais detalhes.
Conjunto de dados
Usamos dados OSCAR como nosso corpus e o conjunto de dados SQUAD para fornecer exemplos de perguntas. Esses conjuntos de dados são primeiro convertidos em arquivos Parquet. Em seguida, usamos um cluster Ray para converter os dados do Parquet em embeddings. Os embeddings criados são ingeridos no OpenSearch Service e no Amazon RDS com pgvector.
OSCAR (Open Super-large Crawled Aggregated corpus) é um enorme corpus multilíngue obtido pela classificação linguística e filtragem do Rastreio comum corpus usando o não-goliante arquitetura. Os dados são distribuídos por idioma na forma original e desduplicada. O conjunto de dados Oscar Corpus tem aproximadamente 609 milhões de registros e ocupa cerca de 4.5 TB como arquivos JSONL brutos. Os arquivos JSONL são então convertidos para o formato Parquet, o que minimiza o tamanho total para 1.8 TB. Reduzimos ainda mais o conjunto de dados para 25 milhões de registros para economizar tempo durante a ingestão.
SQuAD (Stanford Question Answering Dataset) é um conjunto de dados de compreensão de leitura que consiste em perguntas feitas por trabalhadores coletivos em um conjunto de artigos da Wikipedia, onde a resposta a cada pergunta é um segmento de texto, ou palmo, da passagem de leitura correspondente, ou a pergunta pode ficar sem resposta. Nós usamos PELOTÃO, licenciado como CC-BY-SA 4.0, para fornecer exemplos de perguntas. Tem aproximadamente 100,000 perguntas com mais de 50,000 perguntas sem resposta escritas por trabalhadores coletivos para parecerem semelhantes às respondidas.
Cluster Ray para ingestão e criação de embeddings vetoriais
Em nossos testes, descobrimos que as GPUs causam o maior impacto no desempenho ao criar os embeddings. Portanto, decidimos usar um cluster Ray para converter nosso texto bruto e criar os embeddings. Raio é uma estrutura de computação unificada de código aberto que permite que engenheiros de ML e desenvolvedores Python dimensionem aplicativos Python e acelerem cargas de trabalho de ML. Nosso cluster consistia em 5 g4dn.12xlarge Amazon Elastic Compute Nuvem (Amazon EC2). Cada instância foi configurada com 4 GPUs NVIDIA T4 Tensor Core, 48 vCPU e 192 GiB de memória. Para nossos registros de texto, acabamos dividindo cada um em 1,000 pedaços com uma sobreposição de 100 pedaços. Isso chega a aproximadamente 200 por registro. Para o modelo utilizado para criar embeddings, optamos por tudo-mpnet-base-v2 para criar um espaço vetorial de 768 dimensões.
Configuração de infraestrutura
Usamos os seguintes tipos de instância RDS e configurações de cluster de serviço OpenSearch para configurar nossa infraestrutura.
A seguir estão nossas propriedades de tipo de instância RDS:
- Tipo de instância: db.r7g.12xlarge
- Armazenamento alocado: 20 TB
- Multi-AZ: Verdadeiro
- Armazenamento criptografado: Verdadeiro
- Ativar insights de desempenho: verdadeiro
- Retenção do Performance Insight: 7 dias
- Tipo de armazenamento: gp3
- IOPS provisionados: 64,000
- Tipo de índice: FIV
- Número de listas: 5,000
- Função distância: L2
A seguir estão nossas propriedades de cluster do OpenSearch Service:
- Versão: 2.5
- Nós de dados: 10
- Tipo de instância do nó de dados: r6g.4xlarge
- Nós primários: 3
- Tipo de instância do nó primário: r6g.xlarge
- Índice: motor HNSW:
nmslib - Intervalo de atualização: 30 segundos
ef_construction256- telefone: 16
- Função distância: L2
Usamos configurações grandes para o cluster do OpenSearch Service e instâncias RDS para evitar gargalos de desempenho.
Implantamos a solução usando um Kit de desenvolvimento em nuvem da AWS (AWSCDK) pilha, conforme descrito na seção a seguir.
Implante a pilha do AWS CDK
A pilha AWS CDK nos permite escolher OpenSearch Service ou Amazon RDS para ingestão de dados.
Pré-requisitos
Antes de prosseguir com a instalação, em cdk, bin, src.tc, altere os valores booleanos do Amazon RDS e OpenSearch Service para verdadeiro ou falso, dependendo de sua preferência.
Você também precisa de um serviço vinculado Gerenciamento de acesso e identidade da AWS (IAM) para o domínio do OpenSearch Service. Para mais detalhes, consulte Biblioteca de construção do Amazon OpenSearch Service. Você também pode executar o seguinte comando para criar a função:
Esta pilha AWS CDK implantará a seguinte infraestrutura:
- Uma VPC
- Um host de salto (dentro da VPC)
- Um cluster do OpenSearch Service (se estiver usando o serviço OpenSearch para ingestão)
- Uma instância do RDS (se estiver usando o Amazon RDS para ingestão)
- An Gerente de Sistemas AWS documento para implantação do cluster Ray
- An Serviço de armazenamento simples da Amazon (Amazon S3) balde
- An Cola AWS trabalho para converter os arquivos JSONL do conjunto de dados OSCAR em arquivos Parquet
- Amazon CloudWatch painéis
Faça o download dos dados
Execute os seguintes comandos no host de salto:
Antes de clonar o repositório git, certifique-se de ter um perfil Hugging Face e acesso ao corpus de dados OSCAR. Você precisa usar o nome de usuário e senha para clonar os dados OSCAR:
Converter arquivos JSONL em Parquet
A pilha AWS CDK criou o trabalho AWS Glue ETL oscar-jsonl-parquet para converter os dados OSCAR do formato JSONL para Parquet.
Depois de executar o oscar-jsonl-parquet job, os arquivos no formato Parquet deverão estar disponíveis na pasta parquet no bucket S3.
Baixe as perguntas
No host de salto, baixe os dados das perguntas e carregue-os no bucket S3:
Configure o cluster Ray
Como parte da implantação da pilha AWS CDK, criamos um documento do Systems Manager chamado CreateRayCluster.
Para executar o documento, execute as seguintes etapas:
- No console do Systems Manager, em DOCUMENTOS no painel de navegação, escolha De minha propriedade.
- Abra o
CreateRayClusterdocumento. - Escolha Execute.
A página de comando de execução terá os valores padrão preenchidos para o cluster.
A configuração padrão solicita 5 g4dn.12xlarge. Certifique-se de que sua conta tenha limites para suportar isso. O limite de serviço relevante é a execução de instâncias G e VT sob demanda. O padrão para isso é 64, mas esta configuração requer 240 CPUS.
- Depois de revisar a configuração do cluster, selecione o host de salto como o destino para o comando de execução.
Este comando executará as seguintes etapas:
- Copie os arquivos do cluster Ray
- Configure o cluster Ray
- Configure os índices do OpenSearch Service
- Configure as tabelas RDS
É possível monitorar a saída dos comandos no console do Systems Manager. Este processo levará de 10 a 15 minutos para o lançamento inicial.
Executar ingestão
No host de salto, conecte-se ao cluster Ray:
Na primeira vez que se conectar ao host, instale os requisitos. Esses arquivos já devem estar presentes no nó principal.
Para qualquer um dos métodos de ingestão, se você receber um erro como o seguinte, ele estará relacionado a credenciais expiradas. A solução alternativa atual (no momento em que este livro foi escrito) é colocar arquivos de credenciais no nó principal do Ray. Para evitar riscos de segurança, não use usuários IAM para autenticação ao desenvolver software específico ou trabalhar com dados reais. Em vez disso, use a federação com um provedor de identidade como AWS IAM Identity Center (sucessor do AWS Single Sign-On).
Normalmente, as credenciais são armazenadas no arquivo ~/.aws/credentials em sistemas Linux e macOS, e %USERPROFILE%.awscredentials no Windows, mas são credenciais de curto prazo com um token de sessão. Você também não pode substituir o arquivo de credenciais padrão e, portanto, precisa criar credenciais de longo prazo sem o token de sessão usando um novo usuário do IAM.
Para criar credenciais de longo prazo, você precisa gerar uma chave de acesso da AWS e uma chave de acesso secreta da AWS. Você pode fazer isso no console do IAM. Para obter instruções, consulte Autenticar com credenciais de usuário do IAM.
Depois de criar as chaves, conecte-se ao host de salto usando Session Manager, um recurso do Systems Manager, e execute o seguinte comando:
Agora você pode executar novamente as etapas de ingestão.
Ingerir dados no OpenSearch Service
Se você estiver usando o serviço OpenSearch, execute o seguinte script para ingerir os arquivos:
Quando terminar, execute o script que executa consultas simuladas:
Ingerir dados no Amazon RDS
Se você estiver usando o Amazon RDS, execute o seguinte script para ingerir os arquivos:
Quando estiver concluído, certifique-se de executar um vácuo completo na instância do RDS.
Em seguida, execute o seguinte script para executar consultas simuladas:
Configure o painel do Ray
Antes de configurar o painel do Ray, você deve instalar o Interface de linha de comando da AWS (AWS CLI) em sua máquina local. Para obter instruções, consulte Instale ou atualize a versão mais recente da AWS CLI.
Conclua as etapas a seguir para configurar o painel:
- Instale o Plug-in do Gerenciador de Sessão para a AWS CLI.
- Na conta Isengard, copie as credenciais temporárias para bash/zsh e execute em seu terminal local.
- Crie um arquivo session.sh em sua máquina e copie o seguinte conteúdo para o arquivo:
- Altere o diretório onde este arquivo session.sh está armazenado.
- Execute o comando
Chmod +xpara dar permissão executável ao arquivo. - Execute o seguinte comando:
Por exemplo:
Você verá uma mensagem como a seguinte:
Abra uma nova aba no seu navegador e digite localhost:8265.
Você verá o painel do Ray e as estatísticas dos trabalhos e cluster em execução. Você pode acompanhar as métricas aqui.
Por exemplo, você pode usar o painel Ray para observar a carga no cluster. Conforme mostrado na captura de tela a seguir, durante a ingestão, as GPUs estão funcionando com quase 100% de utilização.
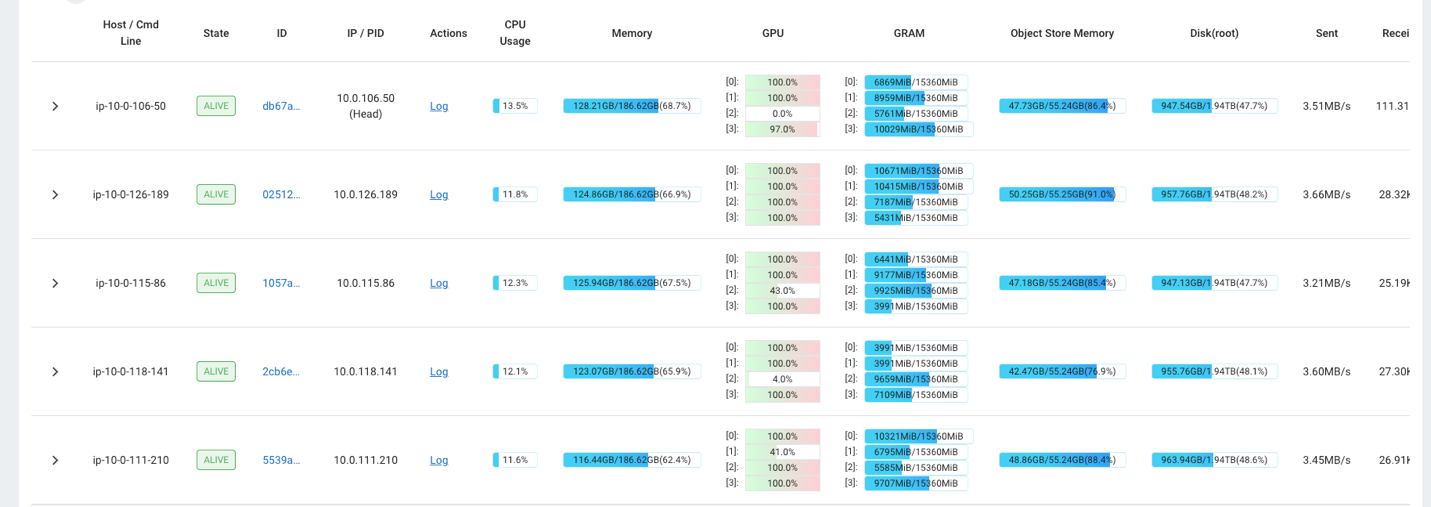
Você também pode usar o RAG_Benchmarks Painel do CloudWatch para ver a taxa de ingestão e os tempos de resposta da consulta.
Extensibilidade da solução
Você pode estender esta solução para conectar outros armazenamentos de vetores da AWS ou de terceiros. Para cada novo armazenamento de vetores, você precisará criar scripts para configurar o armazenamento de dados, bem como para ingerir dados. O restante do pipeline pode ser reutilizado conforme necessário.
Conclusão
Nesta postagem, compartilhamos um pipeline ETL que você pode usar para colocar dados RAG vetorizados no OpenSearch Service e também no Amazon RDS com a extensão pgvector como datastores vetoriais. A solução usou um cluster Ray para fornecer o paralelismo necessário para ingerir um grande corpus de dados. Você pode usar esta metodologia para integrar qualquer banco de dados vetorial de sua escolha para construir pipelines RAG.
Sobre os autores
 Randy De Fauw é arquiteto de soluções principal sênior na AWS. Ele possui um MSEE pela Universidade de Michigan, onde trabalhou em visão computacional para veículos autônomos. Ele também possui MBA pela Colorado State University. Randy ocupou diversos cargos na área de tecnologia, desde engenharia de software até gerenciamento de produtos. Ele entrou no espaço de big data em 2013 e continua a explorar essa área. Ele está trabalhando ativamente em projetos na área de ML e fez apresentações em diversas conferências, incluindo Strata e GlueCon.
Randy De Fauw é arquiteto de soluções principal sênior na AWS. Ele possui um MSEE pela Universidade de Michigan, onde trabalhou em visão computacional para veículos autônomos. Ele também possui MBA pela Colorado State University. Randy ocupou diversos cargos na área de tecnologia, desde engenharia de software até gerenciamento de produtos. Ele entrou no espaço de big data em 2013 e continua a explorar essa área. Ele está trabalhando ativamente em projetos na área de ML e fez apresentações em diversas conferências, incluindo Strata e GlueCon.
 David Christian é arquiteto de soluções principal baseado no sul da Califórnia. Ele é bacharel em Segurança da Informação e apaixonado por automação. Suas áreas de foco são cultura e transformação DevOps, infraestrutura como código e resiliência. Antes de ingressar na AWS, ele ocupou cargos em segurança, DevOps e engenharia de sistemas, gerenciando ambientes de nuvem pública e privada em grande escala.
David Christian é arquiteto de soluções principal baseado no sul da Califórnia. Ele é bacharel em Segurança da Informação e apaixonado por automação. Suas áreas de foco são cultura e transformação DevOps, infraestrutura como código e resiliência. Antes de ingressar na AWS, ele ocupou cargos em segurança, DevOps e engenharia de sistemas, gerenciando ambientes de nuvem pública e privada em grande escala.
 Prachi Kulkarni é arquiteto de soluções sênior na AWS. Sua especialização é aprendizado de máquina e ela está trabalhando ativamente no design de soluções usando várias ofertas de AWS ML, big data e análises. Prachi tem experiência em vários domínios, incluindo saúde, benefícios, varejo e educação, e trabalhou em diversos cargos em engenharia e arquitetura de produtos, gerenciamento e sucesso de clientes.
Prachi Kulkarni é arquiteto de soluções sênior na AWS. Sua especialização é aprendizado de máquina e ela está trabalhando ativamente no design de soluções usando várias ofertas de AWS ML, big data e análises. Prachi tem experiência em vários domínios, incluindo saúde, benefícios, varejo e educação, e trabalhou em diversos cargos em engenharia e arquitetura de produtos, gerenciamento e sucesso de clientes.
 Richa Gupta é arquiteto de soluções na AWS. Ela é apaixonada por arquitetar soluções ponta a ponta para os clientes. Sua especialização é aprendizado de máquina e como ele pode ser usado para construir novas soluções que levem à excelência operacional e gerem receita de negócios. Antes de ingressar na AWS, ela trabalhou como engenheira de software e arquiteta de soluções, criando soluções para grandes operadoras de telecomunicações. Fora do trabalho, ela gosta de explorar novos lugares e adora atividades de aventura.
Richa Gupta é arquiteto de soluções na AWS. Ela é apaixonada por arquitetar soluções ponta a ponta para os clientes. Sua especialização é aprendizado de máquina e como ele pode ser usado para construir novas soluções que levem à excelência operacional e gerem receita de negócios. Antes de ingressar na AWS, ela trabalhou como engenheira de software e arquiteta de soluções, criando soluções para grandes operadoras de telecomunicações. Fora do trabalho, ela gosta de explorar novos lugares e adora atividades de aventura.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

