
Imagem do autor
Supervisionado é uma subcategoria de aprendizado de máquina em que o computador aprende com o conjunto de dados rotulado que contém tanto a entrada quanto a saída correta. Ele tenta encontrar a função de mapeamento que relaciona a entrada (x) à saída (y). Você pode pensar nisso como ensinar seu irmão ou irmã mais novo a reconhecer diferentes animais. Você vai mostrar a eles algumas fotos (x) e dizer como se chama cada animal (y). Depois de um certo tempo, eles aprenderão as diferenças e serão capazes de reconhecer corretamente a nova imagem. Esta é a intuição básica por trás da aprendizagem supervisionada. Antes de prosseguirmos, vamos dar uma olhada mais profunda em seu funcionamento.
Como funciona a aprendizagem supervisionada?
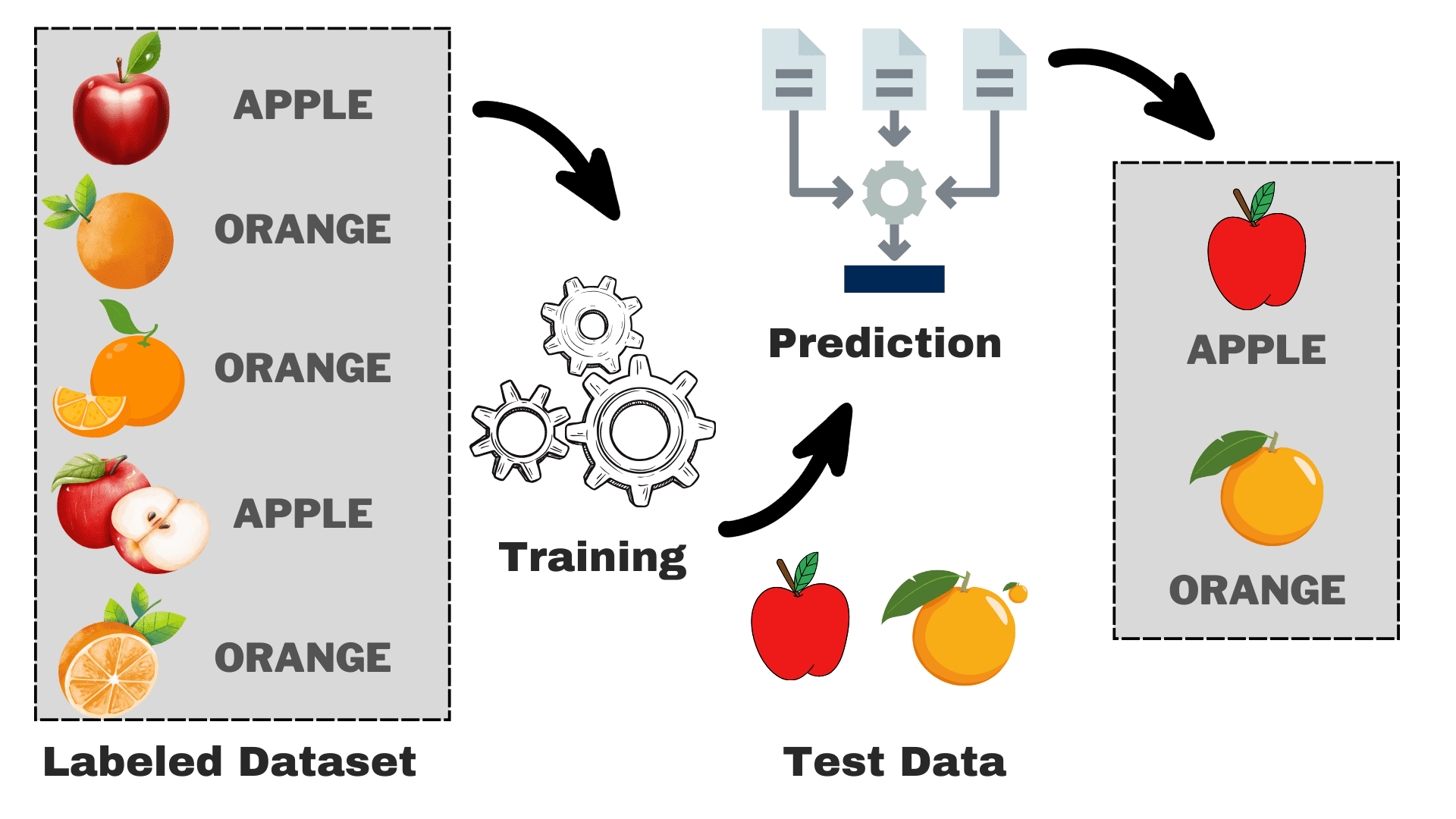
Imagem do autor
Suponha que você queira construir um modelo que possa diferenciar entre maçãs e laranjas com base em algumas características. Podemos dividir o processo nas seguintes tarefas:
- Coleção de dados: Reúna um conjunto de dados com imagens de maçãs e laranjas e cada imagem será rotulada como “maçã” ou “laranja”.
- Seleção de modelo: Temos que escolher o classificador certo aqui, geralmente conhecido como o algoritmo de aprendizado de máquina supervisionado certo para sua tarefa. É como escolher os óculos certos que o ajudarão a ver melhor
- Treinando o Modelo: Agora, você alimenta o algoritmo com as imagens rotuladas de maçãs e laranjas. O algoritmo analisa essas imagens e aprende a reconhecer as diferenças, como cor, formato e tamanho de maçãs e laranjas.
- Avaliação e teste: Para verificar se o seu modelo está funcionando corretamente, iremos alimentá-lo com algumas imagens não vistas e comparar as previsões com as reais.
A aprendizagem supervisionada pode ser dividida em dois tipos principais:
Classificação
Nas tarefas de classificação, o objetivo principal é atribuir pontos de dados a categorias específicas de um conjunto de classes discretas. Quando há apenas dois resultados possíveis, como “sim” ou “não”, “spam” ou “não spam”, “aceito” ou “rejeitado”, isso é chamado de classificação binária. No entanto, quando há mais de duas categorias ou turmas envolvidas, como a classificação dos alunos com base nas suas notas (por exemplo, A, B, C, D, F), torna-se um exemplo de problema de multiclassificação.
Regressão
Para problemas de regressão, você está tentando prever um valor numérico contínuo. Por exemplo, você pode estar interessado em prever as notas do exame final com base no seu desempenho anterior nas aulas. As pontuações previstas podem abranger qualquer valor dentro de um intervalo específico, normalmente de 0 a 100 no nosso caso.
Agora, temos uma compreensão básica do processo geral. Exploraremos os populares algoritmos de aprendizado de máquina supervisionado, seu uso e como funcionam:
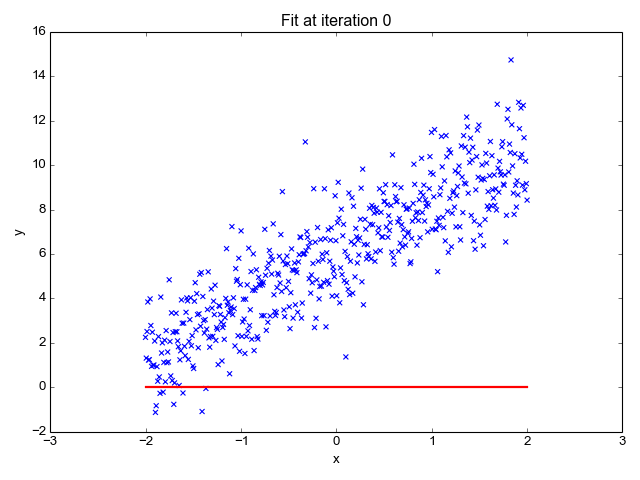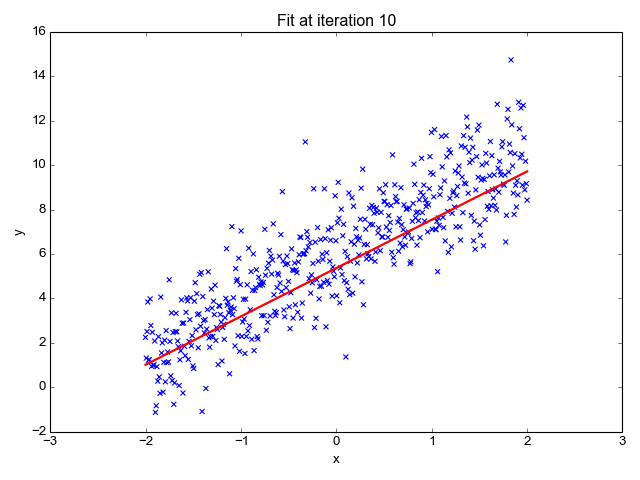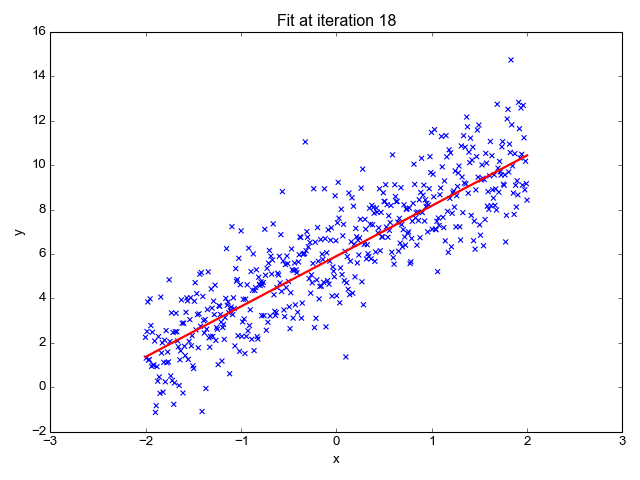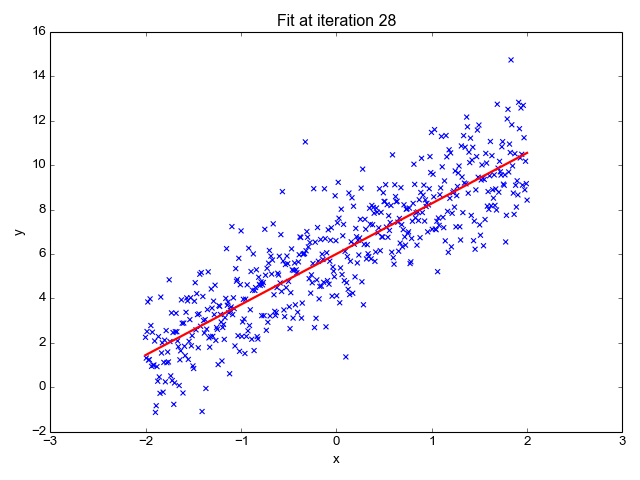
1. Regressão Linear
Como o nome sugere, é usado para tarefas de regressão como previsão de preços de ações, previsão de temperatura, estimativa da probabilidade de progressão de doenças, etc. Tentamos prever o alvo (variável dependente) usando o conjunto de rótulos (variáveis independentes). Ele pressupõe que temos uma relação linear entre nossos recursos de entrada e o rótulo. A ideia central gira em torno de prever a linha de melhor ajuste para nossos pontos de dados, minimizando o erro entre nossos valores reais e previstos. Esta reta é representada pela equação:
Onde,
- Y Saída prevista.
- X = Recurso de entrada ou matriz de recursos em regressão linear múltipla
- b0 = Interceptação (onde a linha cruza o eixo Y).
- b1 = Inclinação ou coeficiente que determina a inclinação da linha.
Estima a inclinação da linha (peso) e sua interceptação (viés). Esta linha pode ser usada posteriormente para fazer previsões. Embora seja o modelo mais simples e útil para o desenvolvimento das linhas de base, é altamente sensível a outliers que podem influenciar a posição da linha.
GIF ativado Primo.ai
2. Regressão Logística
Embora tenha regressão em seu nome, é fundamentalmente usado para problemas de classificação binária. Ele prevê a probabilidade de um resultado positivo (variável dependente) que está no intervalo de 0 a 1. Ao definir um limite (geralmente 0.5), classificamos os pontos de dados: aqueles com uma probabilidade maior que o limite pertencem à classe positiva, e vice versa. A regressão logística calcula esta probabilidade usando a função sigmóide aplicada à combinação linear dos recursos de entrada que é especificada como:
Onde,
- P(Y=1) = Probabilidade do ponto de dados pertencer à classe positiva
- X1,…,Xn = Recursos de entrada
- b0,….,bn = Pesos de entrada que o algoritmo aprende durante o treinamento
Esta função sigmóide está na forma de uma curva semelhante a S que transforma qualquer ponto de dados em uma pontuação de probabilidade dentro do intervalo de 0-1. Você pode ver o gráfico abaixo para uma melhor compreensão.
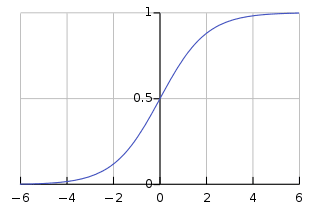
Imagem em Wikipedia
Um valor mais próximo de 1 indica uma maior confiança do modelo em sua previsão. Assim como a regressão linear, ela é conhecida por sua simplicidade, mas não podemos realizar a classificação multiclasse sem modificar o algoritmo original.
3. Árvores de Decisão
Ao contrário dos dois algoritmos acima, as árvores de decisão podem ser usadas para tarefas de classificação e regressão. Possui uma estrutura hierárquica igual aos fluxogramas. Em cada nó, uma decisão sobre o caminho é tomada com base em alguns valores de características. O processo continua a menos que cheguemos ao último nó que representa a decisão final. Aqui estão algumas terminologias básicas que você deve conhecer:
- Nó raiz: O nó superior que contém todo o conjunto de dados é chamado de nó raiz. Em seguida, selecionamos o melhor recurso usando algum algoritmo para dividir o conjunto de dados em 2 ou mais subárvores.
- Nós internos: Cada nó interno representa um recurso específico e uma regra de decisão para decidir a próxima direção possível para um ponto de dados.
- Nós de folha: Os nós finais que representam um rótulo de classe são chamados de nós folha.
Prevê os valores numéricos contínuos para as tarefas de regressão. À medida que o tamanho do conjunto de dados aumenta, ele captura o ruído que leva ao sobreajuste. Isso pode ser resolvido podando a árvore de decisão. Removemos ramificações que não melhoram significativamente a precisão de nossas decisões. Isso ajuda a manter nossa árvore focada nos fatores mais importantes e evita que ela se perca nos detalhes.
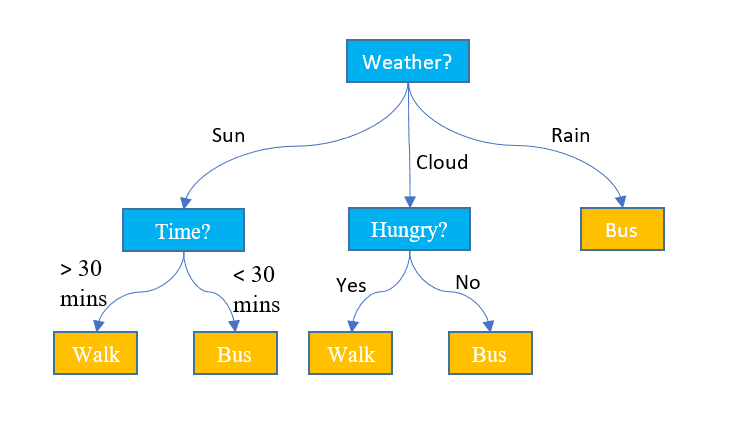
Imagem por Jake Hoare no Displayr
4. Floresta Aleatória
A floresta aleatória também pode ser usada para tarefas de classificação e regressão. É um grupo de árvores de decisão trabalhando juntas para fazer a previsão final. Você pode pensar nisso como um comitê de especialistas tomando uma decisão coletiva. Veja como funciona:
- Amostragem de Dados: Em vez de coletar todo o conjunto de dados de uma vez, ele coleta amostras aleatórias por meio de um processo chamado bootstrapping ou bagging.
- Seleção de recursos: Para cada árvore de decisão em uma floresta aleatória, apenas o subconjunto aleatório de características é considerado para a tomada de decisão, em vez do conjunto completo de características.
- Votação: Para classificação, cada árvore de decisão na floresta aleatória vota e a classe com maior número de votos é selecionada. Para regressão, calculamos a média dos valores obtidos de todas as árvores.
Embora reduza o efeito do overfitting causado por árvores de decisão individuais, é computacionalmente caro. Uma palavra que você lerá com frequência na literatura é que a floresta aleatória é um método de aprendizado conjunto, o que significa que combina vários modelos para melhorar o desempenho geral.
5. Máquinas de vetor de suporte (SVM)
É usado principalmente para problemas de classificação, mas também pode lidar com tarefas de regressão. Tenta encontrar o melhor hiperplano que separa as classes distintas usando a abordagem estatística, ao contrário da abordagem probabilística da regressão logística. Podemos usar o SVM linear para dados linearmente separáveis. No entanto, a maioria dos dados do mundo real não são lineares e usamos truques do kernel para separar as classes. Vamos nos aprofundar em como funciona:
- Seleção de hiperplano: Na classificação binária, o SVM encontra o melhor hiperplano (linha 2-D) para separar as classes enquanto maximiza a margem. Margem é a distância entre o hiperplano e os pontos de dados mais próximos do hiperplano.
- Truque do kernel: Para dados linearmente inseparáveis, empregamos um truque de kernel que mapeia o espaço de dados original em um espaço de alta dimensão onde eles podem ser separados linearmente. Os kernels comuns incluem kernels lineares, polinomiais, de base radial (RBF) e sigmóides.
- Maximização de margem: O SVM também tenta melhorar a generalização do modelo aumentando a margem de maximização.
- Classificação: Uma vez treinado o modelo, as previsões podem ser feitas com base em sua posição em relação ao hiperplano.
O SVM também possui um parâmetro denominado C que controla o compromisso entre maximizar a margem e manter o erro de classificação ao mínimo. Embora eles possam lidar bem com dados não lineares e de alta dimensão, escolher o kernel e o hiperparâmetro corretos não é tão fácil quanto parece.
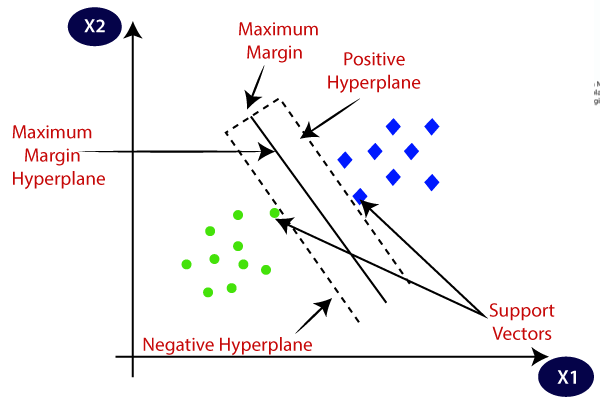
Imagem em Ponto Java
6. k-vizinhos mais próximos (k-NN)
K-NN é o algoritmo de aprendizagem supervisionada mais simples usado principalmente para tarefas de classificação. Ele não faz nenhuma suposição sobre os dados e atribui ao novo ponto de dados uma categoria com base em sua semelhança com os existentes. Durante a fase de treinamento, mantém todo o conjunto de dados como ponto de referência. Em seguida, calcula a distância entre o novo ponto de dados e todos os pontos existentes usando uma métrica de distância (por exemplo, distância Eucilinedain). Com base nessas distâncias, identifica os K vizinhos mais próximos desses pontos de dados. Em seguida, contamos a ocorrência de cada classe nos K vizinhos mais próximos e atribuímos a classe que aparece com mais frequência como previsão final.
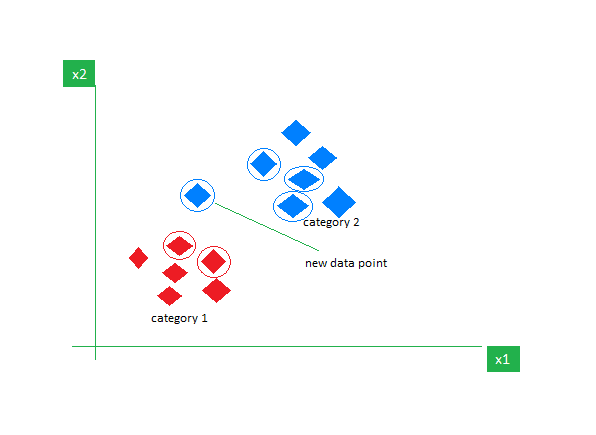
Imagem em GeeksparaGeeks
Escolher o valor certo de K requer experimentação. Embora seja robusto para dados ruidosos, não é adequado para conjuntos de dados de grandes dimensões e tem um custo elevado associado devido ao cálculo da distância de todos os pontos de dados.
Ao concluir este artigo, gostaria de encorajar os leitores a explorar mais algoritmos e tentar implementá-los do zero. Isso fortalecerá sua compreensão de como as coisas funcionam nos bastidores. Aqui estão alguns recursos adicionais para ajudá-lo a começar:
Kanwal Mehreen é um aspirante a desenvolvedor de software com grande interesse em ciência de dados e aplicações de IA na medicina. Kanwal foi selecionado como o Google Generation Scholar 2022 para a região APAC. Kanwal adora compartilhar conhecimento técnico escrevendo artigos sobre tópicos de tendências e é apaixonado por melhorar a representação das mulheres na indústria de tecnologia.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- ChartPrime. Eleve seu jogo de negociação com ChartPrime. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

