Com o Bases de conhecimento para Amazon Bedrock, você pode conectar com segurança modelos de base (FMs) em Rocha Amazônica aos dados da sua empresa para Retrieval Augmented Generation (RAG). O acesso a dados adicionais ajuda o modelo a gerar respostas mais relevantes, específicas ao contexto e precisas, sem retreinar os FMs.
Nesta postagem, discutimos dois novos recursos das bases de conhecimento do Amazon Bedrock específicos para o RetrieveAndGenerate API: configurando o número máximo de resultados e criando prompts personalizados com um modelo de prompt da base de conhecimento. Agora você pode escolhê-las como opções de consulta junto com o tipo de pesquisa.
Visão geral e benefícios dos novos recursos
A opção de número máximo de resultados oferece controle sobre o número de resultados de pesquisa a serem recuperados do armazenamento de vetores e transmitidos ao FM para gerar a resposta. Isso permite personalizar a quantidade de informações básicas fornecidas para geração, fornecendo assim mais contexto para questões complexas ou menos para questões mais simples. Ele permite que você busque até 100 resultados. Esta opção ajuda a melhorar a probabilidade do contexto relevante, melhorando assim a precisão e reduzindo a alucinação da resposta gerada.
O modelo de prompt da base de conhecimento personalizado permite substituir o modelo de prompt padrão pelo seu próprio para personalizar o prompt enviado ao modelo para geração de resposta. Isso permite personalizar o tom, o formato de saída e o comportamento do FM quando ele responde à pergunta de um usuário. Com esta opção, você pode ajustar a terminologia para melhor corresponder ao seu setor ou domínio (como saúde ou jurídico). Além disso, você pode adicionar instruções personalizadas e exemplos adaptados aos seus fluxos de trabalho específicos.
Nas seções a seguir, explicamos como você pode usar esses recursos com o Console de gerenciamento da AWS ou SDK.
Pré-requisitos
Para acompanhar esses exemplos, você precisa ter uma base de conhecimento existente. Para obter instruções sobre como criar um, consulte Crie uma base de conhecimento.
Configure o número máximo de resultados usando o console
Para usar a opção de número máximo de resultados usando o console, conclua as etapas a seguir:
- No console do Amazon Bedrock, escolha Bases de conhecimento no painel de navegação esquerdo.
- Selecione a base de conhecimento que você criou.
- Escolha Base de conhecimento de teste.
- Escolha o ícone de configuração.
- Escolha Sincronizar fonte de dados antes de começar a testar sua base de conhecimento.

- Debaixo configurações, Por Tipo de pesquisa, selecione um tipo de pesquisa com base no seu caso de uso.
Para esta postagem, usamos a pesquisa híbrida porque combina pesquisa semântica e de texto para fornecer maior precisão. Para saber mais sobre pesquisa híbrida, consulte As bases de conhecimento do Amazon Bedrock agora oferecem suporte à pesquisa híbrida.
- Expandir Número máximo de pedaços de origem e defina seu número máximo de resultados.

Para demonstrar o valor do novo recurso, mostramos exemplos de como você pode aumentar a precisão da resposta gerada. Nós costumavamos Documento Amazon 10K para 2023 como dados de origem para a criação da base de conhecimento. Usamos a seguinte consulta para experimentação: “Em que ano a receita anual da Amazon aumentou de US$ 245 bilhões para US$ 434 bilhões?”
A resposta correta para esta consulta é “A receita anual da Amazon aumentou de US$ 245 bilhões em 2019 para US$ 434 bilhões em 2022”, com base nos documentos da base de conhecimento. Usamos Claude v2 como FM para gerar a resposta final com base nas informações contextuais recuperadas da base de conhecimento. Claude 3 Sonnet e Claude 3 Haiku também são suportados como a geração FMs.
Executamos outra consulta para demonstrar a comparação da recuperação com diferentes configurações. Usamos a mesma consulta de entrada (“Em que ano a receita anual da Amazon aumentou de US$ 245 bilhões para US$ 434 bilhões?”) e definimos o número máximo de resultados como 5.
Conforme mostrado na captura de tela a seguir, a resposta gerada foi “Desculpe, não posso ajudá-lo com esta solicitação”.

A seguir, definimos os resultados máximos como 12 e fazemos a mesma pergunta. A resposta gerada é “o aumento da receita anual da Amazon de US$ 245 bilhões em 2019 para US$ 434 bilhões em 2022”.

Conforme mostrado neste exemplo, podemos recuperar a resposta correta com base no número de resultados recuperados. Se você quiser saber mais sobre a atribuição da fonte que constitui o resultado final, escolha Mostrar detalhes da fonte para validar a resposta gerada com base na base de conhecimento.
Personalize um modelo de prompt da base de conhecimento usando o console
Você também pode personalizar o prompt padrão com seu próprio prompt com base no caso de uso. Para fazer isso no console, execute as seguintes etapas:
- Repita as etapas da seção anterior para começar a testar sua base de conhecimento.
- permitir Gerar respostas.

- Selecione o modelo de sua preferência para geração de resposta.
Usamos o modelo Claude v2 como exemplo neste post. O modelo Claude 3 Sonnet and Haiku também está disponível para geração.
- Escolha Aplicar para prosseguir.

Depois de escolher o modelo, uma nova seção chamada Modelo de prompt da base de conhecimento aparece abaixo configurações.
- Escolha Editar para começar a personalizar o prompt.
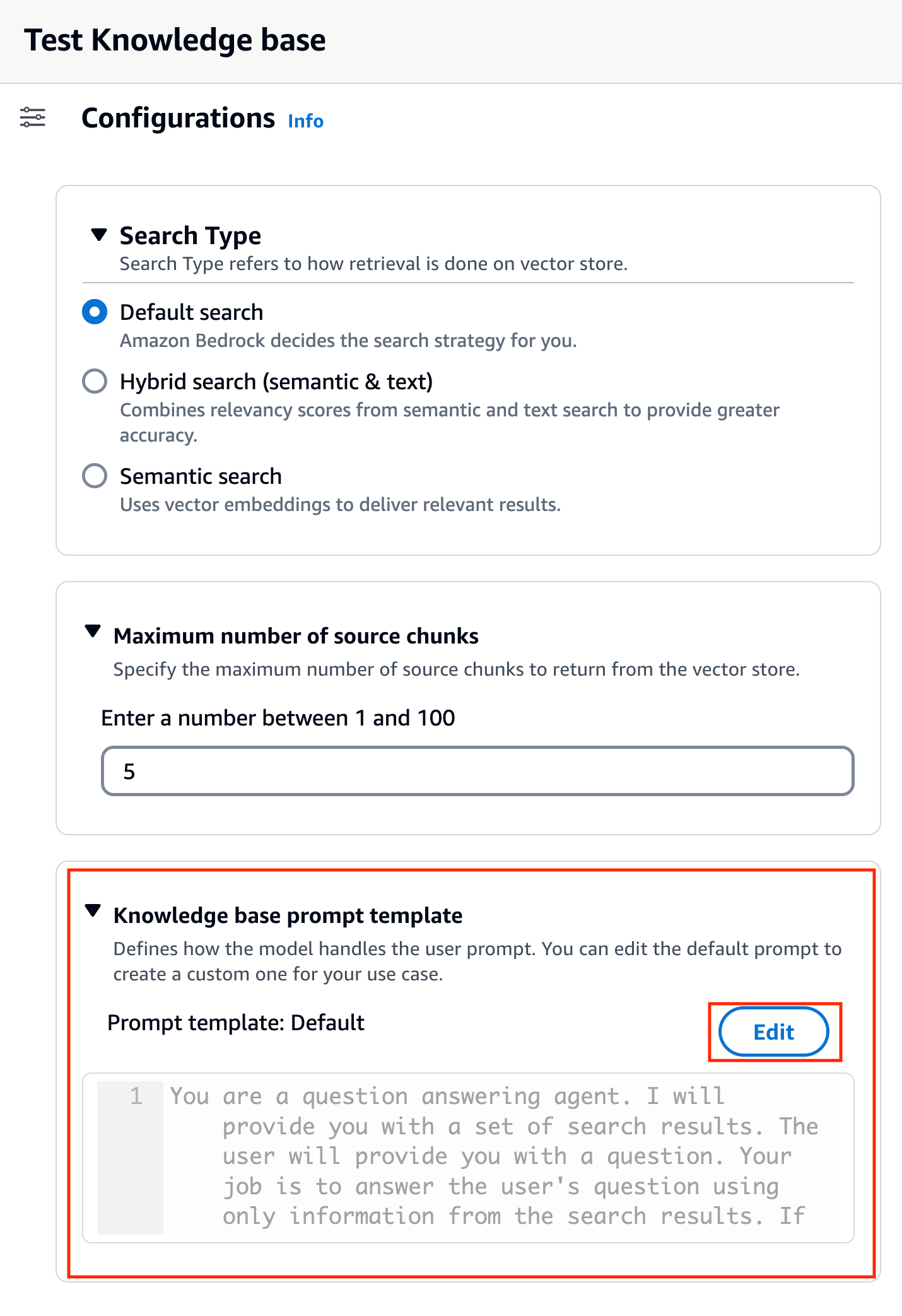
- Ajuste o modelo de prompt para personalizar como você deseja usar os resultados recuperados e gerar conteúdo.
Para esta postagem, demos alguns exemplos de criação de um “sistema de IA de consultor financeiro” usando relatórios financeiros da Amazon com prompts personalizados. Para obter as melhores práticas em engenharia imediata, consulte Diretrizes imediatas de engenharia.
Agora personalizamos o modelo de prompt padrão de diversas maneiras diferentes e observamos as respostas.
Vamos primeiro tentar uma consulta com o prompt padrão. Perguntamos “Qual foi a receita da Amazon em 2019 e 2021?” A seguir mostramos nossos resultados.

A partir do resultado, descobrimos que ele está gerando uma resposta de formato livre com base no conhecimento recuperado. As citações também são listadas para referência.
Digamos que queremos dar instruções extras sobre como formatar a resposta gerada, como padronizá-la como JSON. Podemos adicionar estas instruções como uma etapa separada após recuperar as informações, como parte do modelo de prompt:
A resposta final tem a estrutura necessária.

Ao personalizar o prompt, você também pode alterar o idioma da resposta gerada. No exemplo a seguir, instruímos o modelo a fornecer uma resposta em espanhol.

Depois de remover $output_format_instructions$ no prompt padrão, a citação da resposta gerada é removida.
Nas seções a seguir, explicamos como você pode usar esses recursos com o SDK.
Configure o número máximo de resultados usando o SDK
Para alterar o número máximo de resultados com o SDK, use a sintaxe a seguir. Para este exemplo, a consulta é “Em que ano a receita anual da Amazon aumentou de US$ 245 bilhões para US$ 434 bilhões?” A resposta correta é “A receita anual da Amazon aumenta de US$ 245 bilhões em 2019 para US$ 434 bilhões em 2022”.
A 'numberOfResults'opção em'retrievalConfiguration'permite que você selecione o número de resultados que deseja recuperar. A saída do RetrieveAndGenerate A API inclui a resposta gerada, a atribuição da fonte e os blocos de texto recuperados.
A seguir estão os resultados para diferentes valores de 'numberOfResults'parâmetros. Primeiro, definimos numberOfResults = 5.
Então nós definimos numberOfResults = 12.
Personalize o modelo de prompt da base de conhecimento usando o SDK
Para personalizar o prompt usando o SDK, usamos a consulta a seguir com diferentes modelos de prompt. Para este exemplo, a consulta é “Qual foi a receita da Amazon em 2019 e 2021?”
A seguir está o modelo de prompt padrão:
A seguir está o modelo de prompt personalizado:
Com o modelo de prompt padrão, obtemos a seguinte resposta:
![]()
Se quiser fornecer instruções adicionais sobre o formato de saída da geração de resposta, como padronizar a resposta em um formato específico (como JSON), você poderá personalizar o prompt existente fornecendo mais orientações. Com nosso modelo de prompt personalizado, obtemos a seguinte resposta.

A 'promptTemplate'opção em'generationConfiguration'permite personalizar o prompt para melhor controle sobre a geração de respostas.
Conclusão
Nesta postagem, apresentamos dois novos recursos nas bases de conhecimento do Amazon Bedrock: ajuste do número máximo de resultados de pesquisa e personalização do modelo de prompt padrão para o RetrieveAndGenerate API. Demonstramos como configurar esses recursos no console e via SDK para melhorar o desempenho e a precisão da resposta gerada. Aumentar os resultados máximos fornece informações mais abrangentes, enquanto personalizar o modelo de prompt permite ajustar as instruções do modelo básico para melhor alinhá-lo com casos de uso específicos. Essas melhorias oferecem maior flexibilidade e controle, permitindo oferecer experiências personalizadas para aplicativos baseados em RAG.
Para obter recursos adicionais para começar a implementar em seu ambiente AWS, consulte o seguinte:
Sobre os autores
 Sandeep Singh é cientista sênior de dados de IA generativa na Amazon Web Services, ajudando empresas a inovar com IA generativa. Ele é especialista em IA generativa, inteligência artificial, aprendizado de máquina e design de sistemas. Ele é apaixonado por desenvolver soluções de última geração baseadas em IA/ML para resolver problemas de negócios complexos para diversos setores, otimizando a eficiência e a escalabilidade.
Sandeep Singh é cientista sênior de dados de IA generativa na Amazon Web Services, ajudando empresas a inovar com IA generativa. Ele é especialista em IA generativa, inteligência artificial, aprendizado de máquina e design de sistemas. Ele é apaixonado por desenvolver soluções de última geração baseadas em IA/ML para resolver problemas de negócios complexos para diversos setores, otimizando a eficiência e a escalabilidade.
 Suyin Wang é arquiteto de soluções especialista em IA/ML na AWS. Ela tem formação interdisciplinar em aprendizado de máquina, serviços de informações financeiras e economia, além de anos de experiência na construção de aplicativos de ciência de dados e aprendizado de máquina que resolveram problemas de negócios do mundo real. Ela gosta de ajudar os clientes a identificar as questões de negócios certas e a construir as soluções certas de IA/ML. Nas horas vagas, ela adora cantar e cozinhar.
Suyin Wang é arquiteto de soluções especialista em IA/ML na AWS. Ela tem formação interdisciplinar em aprendizado de máquina, serviços de informações financeiras e economia, além de anos de experiência na construção de aplicativos de ciência de dados e aprendizado de máquina que resolveram problemas de negócios do mundo real. Ela gosta de ajudar os clientes a identificar as questões de negócios certas e a construir as soluções certas de IA/ML. Nas horas vagas, ela adora cantar e cozinhar.
 Sherry Ding é arquiteto sênior de soluções especializadas em inteligência artificial (IA) e aprendizado de máquina (ML) na Amazon Web Services (AWS). Ela tem vasta experiência em aprendizado de máquina com doutorado em ciência da computação. Ela trabalha principalmente com clientes do setor público em vários desafios de negócios relacionados à IA/ML, ajudando-os a acelerar sua jornada de aprendizado de máquina na Nuvem AWS. Quando não está atendendo os clientes, ela gosta de atividades ao ar livre.
Sherry Ding é arquiteto sênior de soluções especializadas em inteligência artificial (IA) e aprendizado de máquina (ML) na Amazon Web Services (AWS). Ela tem vasta experiência em aprendizado de máquina com doutorado em ciência da computação. Ela trabalha principalmente com clientes do setor público em vários desafios de negócios relacionados à IA/ML, ajudando-os a acelerar sua jornada de aprendizado de máquina na Nuvem AWS. Quando não está atendendo os clientes, ela gosta de atividades ao ar livre.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

