At AWS re: Invent 2023, anunciamos a disponibilidade geral de Bases de conhecimento para Amazon Bedrock. Com as bases de conhecimento do Amazon Bedrock, você pode conectar com segurança modelos de base (FMs) em Rocha Amazônica aos dados da sua empresa usando um modelo Retrieval Augmented Generation (RAG) totalmente gerenciado.
Para aplicações baseadas em RAG, a precisão das respostas geradas pelos FMs depende do contexto fornecido ao modelo. Os contextos são recuperados de armazenamentos de vetores com base nas consultas do usuário. No recurso lançado recentemente para bases de conhecimento do Amazon Bedrock, pesquisa híbrida, você pode combinar a pesquisa semântica com a pesquisa por palavra-chave. Porém, em muitas situações, pode ser necessário recuperar documentos criados em um período definido ou marcados com determinadas categorias. Para refinar os resultados da pesquisa, você pode filtrar com base nos metadados do documento para melhorar a precisão da recuperação, o que, por sua vez, leva a gerações de FM mais relevantes e alinhadas aos seus interesses.
Nesta postagem, discutimos o novo recurso de filtragem de metadados personalizados nas bases de conhecimento do Amazon Bedrock, que você pode usar para melhorar os resultados da pesquisa pré-filtrando suas recuperações de armazenamentos de vetores.
Visão geral da filtragem de metadados
Antes do lançamento da filtragem de metadados, todos os pedaços semanticamente relevantes até o máximo predefinido seriam retornados como contexto para o FM usar para gerar uma resposta. Agora, com filtros de metadados, você pode recuperar não apenas pedaços semanticamente relevantes, mas também um subconjunto bem definido desses pedaços relevantes com base em filtros de metadados aplicados e valores associados.
Com esse recurso, agora você pode fornecer um arquivo de metadados personalizado (cada um com até 10 KB) para cada documento na base de conhecimento. Você pode aplicar filtros às suas recuperações, instruindo o armazenamento de vetores a pré-filtrar com base nos metadados do documento e, em seguida, procurar documentos relevantes. Dessa forma, você tem controle sobre os documentos recuperados, principalmente se suas consultas forem ambíguas. Por exemplo, você pode usar documentos legais com termos semelhantes para contextos diferentes ou filmes com enredo semelhante lançados em anos diferentes. Além disso, ao reduzir o número de chunks pesquisados, você obtém vantagens de desempenho, como redução nos ciclos de CPU e custo de consulta ao armazenamento de vetores, além de melhoria na precisão.

Para usar o recurso de filtragem de metadados, você precisa fornecer arquivos de metadados juntamente com os arquivos de dados de origem com o mesmo nome do arquivo de dados de origem e .metadata.json sufixo. Os metadados podem ser string, número ou booleanos. A seguir está um exemplo do conteúdo do arquivo de metadados:
O recurso de filtragem de metadados das bases de conhecimento do Amazon Bedrock está disponível nas regiões da AWS Leste dos EUA (Norte da Virgínia) e Oeste dos EUA (Oregon).
A seguir estão casos de uso comuns para filtragem de metadados:
- Chatbot de documentos para uma empresa de software – Isso permite que os usuários encontrem informações sobre produtos e guias de solução de problemas. Filtros por sistema operacional ou versão do aplicativo, por exemplo, podem ajudar a evitar a recuperação de documentos obsoletos ou irrelevantes.
- Pesquisa conversacional do aplicativo de uma organização – Isso permite que os usuários pesquisem documentos, kanbans, transcrições de gravações de reuniões e outros ativos. Usando filtros de metadados em grupos de trabalho, unidades de negócios ou IDs de projetos, você pode personalizar a experiência de chat e melhorar a colaboração. Um exemplo seria “Qual é o status do projeto Sphinx e os riscos levantados”, onde os usuários podem filtrar documentos para um projeto específico ou tipo de fonte (como e-mail ou documentos de reunião).
- Pesquisa inteligente para desenvolvedores de software – Isso permite que os desenvolvedores procurem informações de um lançamento específico. Filtros por versão de lançamento e tipo de documento (como código, referência de API ou problema) podem ajudar a identificar documentos relevantes.
Visão geral da solução
Nas seções a seguir, demonstramos como preparar um conjunto de dados para usar como base de conhecimento e, em seguida, consultar com filtragem de metadados. Você pode consultar usando o Console de gerenciamento da AWS ou SDK.
Prepare um conjunto de dados para bases de conhecimento do Amazon Bedrock
Para esta postagem, usamos um amostra de conjunto de dados sobre videogames fictícios para ilustrar como ingerir e recuperar metadados usando bases de conhecimento do Amazon Bedrock. Se você quiser acompanhar em sua própria conta AWS, baixe o arquivo.
Se quiser adicionar metadados aos seus documentos em uma base de conhecimento existente, crie os arquivos de metadados com o nome de arquivo e o esquema esperados e, em seguida, pule para a etapa de sincronização dos dados com a base de conhecimento para iniciar a ingestão incremental.
Em nosso conjunto de dados de amostra, o documento de cada jogo é um arquivo CSV separado (por exemplo, s3://$bucket_name/video_game/$game_id.csv) com as seguintes colunas:
title, description, genres, year, publisher, score
Os metadados de cada jogo possuem o sufixo .metadata.json (por exemplo, s3://$bucket_name/video_game/$game_id.csv.metadata.json) com o seguinte esquema:
Crie uma base de conhecimento para Amazon Bedrock
Para obter instruções sobre como criar uma nova base de conhecimento, consulte Crie uma base de conhecimento. Para este exemplo, usamos as seguintes configurações:
- No Configurar fonte de dados página, sob Estratégia de fragmentação, selecione Sem fragmentação, porque você já pré-processou os documentos na etapa anterior.
- No Modelo de incorporações seção, escolha Incorporações Titan G1 – Texto.
- No Banco de dados de vetores seção, escolha Crie rapidamente um novo armazenamento de vetores. O recurso de filtragem de metadados está disponível para todos os armazenamentos de vetores suportados.
Sincronize o conjunto de dados com a base de conhecimento
Depois de criar a base de conhecimento e seus arquivos de dados e arquivos de metadados estarem em um Serviço de armazenamento simples da Amazon (Amazon S3), você poderá iniciar a ingestão incremental. Para obter instruções, consulte Sincronize para incorporar suas fontes de dados na base de conhecimento.
Consulta com filtragem de metadados no console do Amazon Bedrock
Para usar as opções de filtragem de metadados no console do Amazon Bedrock, conclua as seguintes etapas:
- No console do Amazon Bedrock, escolha Bases de conhecimento no painel de navegação.
- Escolha a base de conhecimento que você criou.
- Escolha Base de conhecimento de teste.
- Escolha o configurações ícone e expanda Filtros.
- Insira uma condição usando o formato: chave = valor (por exemplo, gêneros = Estratégia) e pressione Entrar.
- Para alterar a chave, o valor ou o operador, escolha a condição.
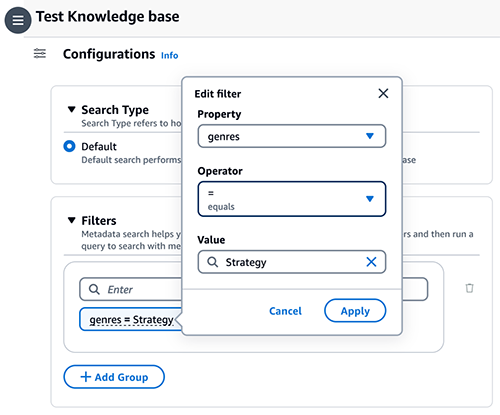
- Continue com as condições restantes (por exemplo, (gêneros = Estratégia E ano >= 2023) OU (classificação >= 9))

- Quando terminar, insira sua consulta na caixa de mensagem e escolha Execute.
Para esta postagem, inserimos a consulta “Um jogo de estratégia com gráficos bacanas lançado após 2023”.
Consulta com filtragem de metadados usando o SDK
Para usar o SDK, primeiro crie o cliente para o Agentes da Amazon Bedrock tempo de execução:
Em seguida, construa o filtro (a seguir estão alguns exemplos):
Passe o filtro para retrievalConfiguration da API de recuperação or Recuperar e gerar API:
A tabela a seguir lista algumas respostas com diferentes condições de filtragem de metadados.
| pergunta | Filtragem de metadados | Documentos recuperados | Observações |
| “Um jogo de estratégia com gráficos legais lançado depois de 2023” | Off |
* Viking Saga: The Sea Raider, ano: 2023, gêneros: Estratégia * Castelo Medieval: Cerco e Conquista, ano:2022, gêneros: Estratégia * Revolução Cibernética: Ascensão das Máquinas, ano:2022, gêneros: Estratégia |
2/5 jogos atendem à condição (gêneros = Estratégia e ano >= 2023) |
| On | * Viking Saga: The Sea Raider, ano: 2023, gêneros: Estratégia * Fantasy Kingdoms: Chronicles of Eldoria, ano: 2023, gêneros: Estratégia |
2/2 jogos atendem à condição (gêneros = Estratégia e ano >= 2023) |
Além dos metadados personalizados, você também pode filtrar usando prefixos S3 (que são metadados integrados, portanto, você não precisa fornecer nenhum arquivo de metadados). Por exemplo, se você organizar os documentos do jogo em prefixos por editora (por exemplo, s3://$bucket_name/video_game/$publisher/$game_id.csv), você pode filtrar pelo editor específico (por exemplo, neo_tokyo_games) usando a seguinte sintaxe:
limpar
Para limpar seus recursos, conclua as seguintes etapas:
- Exclua a base de conhecimento:
- No console do Amazon Bedrock, escolha Bases de conhecimento para Orquestração no painel de navegação.
- Escolha a base de conhecimento que você criou.
- Tome nota do Gerenciamento de acesso e identidade da AWS (IAM) nome da função de serviço no Visão geral da base de conhecimento seção.
- No Banco de dados de vetores seção, anote o ARN da coleção.
- Escolha Apagare digite delete para confirmar.
- Exclua o banco de dados vetorial:
- No Serviço Amazon OpenSearch console, escolha Coleções para Serverless no painel de navegação.
- Insira o ARN da coleção que você salvou na barra de pesquisa.
- Selecione a coleção e escolha Apagar.
- Digite confirmar no prompt de confirmação e escolha Apagar.
- Exclua a função de serviço do IAM:
- No console IAM, escolha Setores no painel de navegação.
- Procure o nome da função que você anotou anteriormente.
- Selecione a função e escolha Apagar.
- Insira o nome da função no prompt de confirmação e exclua a função.
- Exclua o conjunto de dados de amostra:
- No console do Amazon S3, navegue até o bucket do S3 que você usou.
- Selecione o prefixo e os arquivos e escolha Apagar.
- Digite excluir permanentemente no prompt de confirmação para excluir.
Conclusão
Nesta postagem, abordamos o recurso de filtragem de metadados nas bases de conhecimento do Amazon Bedrock. Você aprendeu como adicionar metadados personalizados a documentos e usá-los como filtros ao recuperar e consultar documentos usando o console do Amazon Bedrock e o SDK. Isso ajuda a melhorar a precisão do contexto, tornando as respostas às consultas ainda mais relevantes e, ao mesmo tempo, reduzindo o custo de consulta ao banco de dados vetorial.
Para recursos adicionais, consulte o seguinte:
Sobre os autores
 Corvo Lee é arquiteto sênior de soluções do GenAI Labs baseado em Londres. Ele é apaixonado por projetar e desenvolver protótipos que usam IA generativa para resolver problemas de clientes. Ele também acompanha os mais recentes desenvolvimentos em IA generativa e técnicas de recuperação, aplicando-as a cenários do mundo real.
Corvo Lee é arquiteto sênior de soluções do GenAI Labs baseado em Londres. Ele é apaixonado por projetar e desenvolver protótipos que usam IA generativa para resolver problemas de clientes. Ele também acompanha os mais recentes desenvolvimentos em IA generativa e técnicas de recuperação, aplicando-as a cenários do mundo real.
 Ahmed Ewis é arquiteto de soluções sênior no AWS GenAI Labs, ajudando clientes a criar protótipos generativos de IA para resolver problemas de negócios. Quando não está colaborando com os clientes, gosta de brincar com os filhos e cozinhar.
Ahmed Ewis é arquiteto de soluções sênior no AWS GenAI Labs, ajudando clientes a criar protótipos generativos de IA para resolver problemas de negócios. Quando não está colaborando com os clientes, gosta de brincar com os filhos e cozinhar.
 Chris Pecora é cientista de dados de IA generativa na Amazon Web Services. Ele é apaixonado por construir produtos e soluções inovadores, ao mesmo tempo que se concentra na ciência obcecada pelo cliente. Quando não está realizando experimentos e acompanhando os últimos desenvolvimentos em GenAI, ele adora passar tempo com seus filhos.
Chris Pecora é cientista de dados de IA generativa na Amazon Web Services. Ele é apaixonado por construir produtos e soluções inovadores, ao mesmo tempo que se concentra na ciência obcecada pelo cliente. Quando não está realizando experimentos e acompanhando os últimos desenvolvimentos em GenAI, ele adora passar tempo com seus filhos.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-metadata-filtering-to-improve-retrieval-accuracy/

