
Imagem gerada com Ideograma.ai
Então, você pode ouvir todos esses termos do banco de dados vetorial. Alguns podem entender sobre isso, e outros não. Não se preocupe se você não conhece eles, pois os bancos de dados vetoriais só se tornaram um tópico mais proeminente nos últimos anos.
Os bancos de dados vetoriais ganharam popularidade graças à introdução da IA generativa ao público, especialmente o LLM.
Muitos produtos LLM, como GPT-4 e Gemini, ajudam nosso trabalho, fornecendo capacidade de geração de texto para nossa entrada. Bem, os bancos de dados vetoriais realmente desempenham um papel nesses produtos LLM.
Mas como funcionava o banco de dados vetorial? E quais são suas relevâncias no LLM?
A pergunta acima é o que responderíamos neste artigo. Bem, vamos explorá-los juntos.
Um banco de dados vetorial é um armazenamento de banco de dados especializado projetado para armazenar, indexar e consultar dados vetoriais. Muitas vezes é otimizado para dados vetoriais de alta dimensão, pois geralmente é a saída para o modelo de aprendizado de máquina, especialmente LLM.
No contexto de um banco de dados vetorial, o vetor é uma representação matemática dos dados. Cada vetor consiste em uma matriz de pontos numéricos que representam a posição dos dados. O vetor é frequentemente usado no LLM para representar os dados de texto, pois um vetor é mais fácil de processar do que os dados de texto.
No espaço LLM, o modelo pode ter uma entrada de texto e transformar o texto em um vetor de alta dimensão representando as características semânticas e sintáticas do texto. Este processo é o que chamamos de Incorporação. Em termos mais simples, incorporação é um processo que transforma texto em vetores com dados numéricos.
A incorporação geralmente usa um modelo de rede neural chamado modelo de incorporação para representar o texto no espaço de incorporação.
Vamos usar um texto de exemplo: “I Love Data Science”. Representá-los com o modelo OpenAI text-embedding-3-small resultaria em um vetor com 1536 dimensões.
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
O número dentro do vetor é a coordenada dentro do espaço de incorporação do modelo. Juntos, eles formariam uma representação única do significado da frase proveniente do modelo.
O banco de dados vetorial seria então responsável por armazenar essas saídas do modelo incorporado. O usuário poderá então consultar, indexar e recuperar o vetor conforme necessário.
Talvez isso seja introdução suficiente e vamos entrar em uma prática mais técnica. Tentaríamos estabelecer e armazenar vetores com um banco de dados de vetores de código aberto chamado Tecer.
Weaviate é um banco de dados vetorial escalável de código aberto que serve como uma estrutura para armazenar nosso vetor. Podemos executar o Weaviate em instâncias como Docker ou usar o Weaviate Cloud Services (WCS).
Para começar a usar o Weaviate, precisamos instalar os pacotes usando o seguinte código:
pip install weaviate-client
Para facilitar as coisas, usaríamos um cluster sandbox do WCS para atuar como nosso banco de dados de vetores. Weaviate oferece um cluster gratuito de 14 dias que podemos usar para armazenar nossos vetores sem registrar qualquer método de pagamento. Para fazer isso, você precisa se registrar em seu Consola WCS inicialmente.
Uma vez dentro da plataforma WCS, selecione Criar um Cluster e insira o nome do seu Sandbox. A IU deve ser semelhante à imagem abaixo.
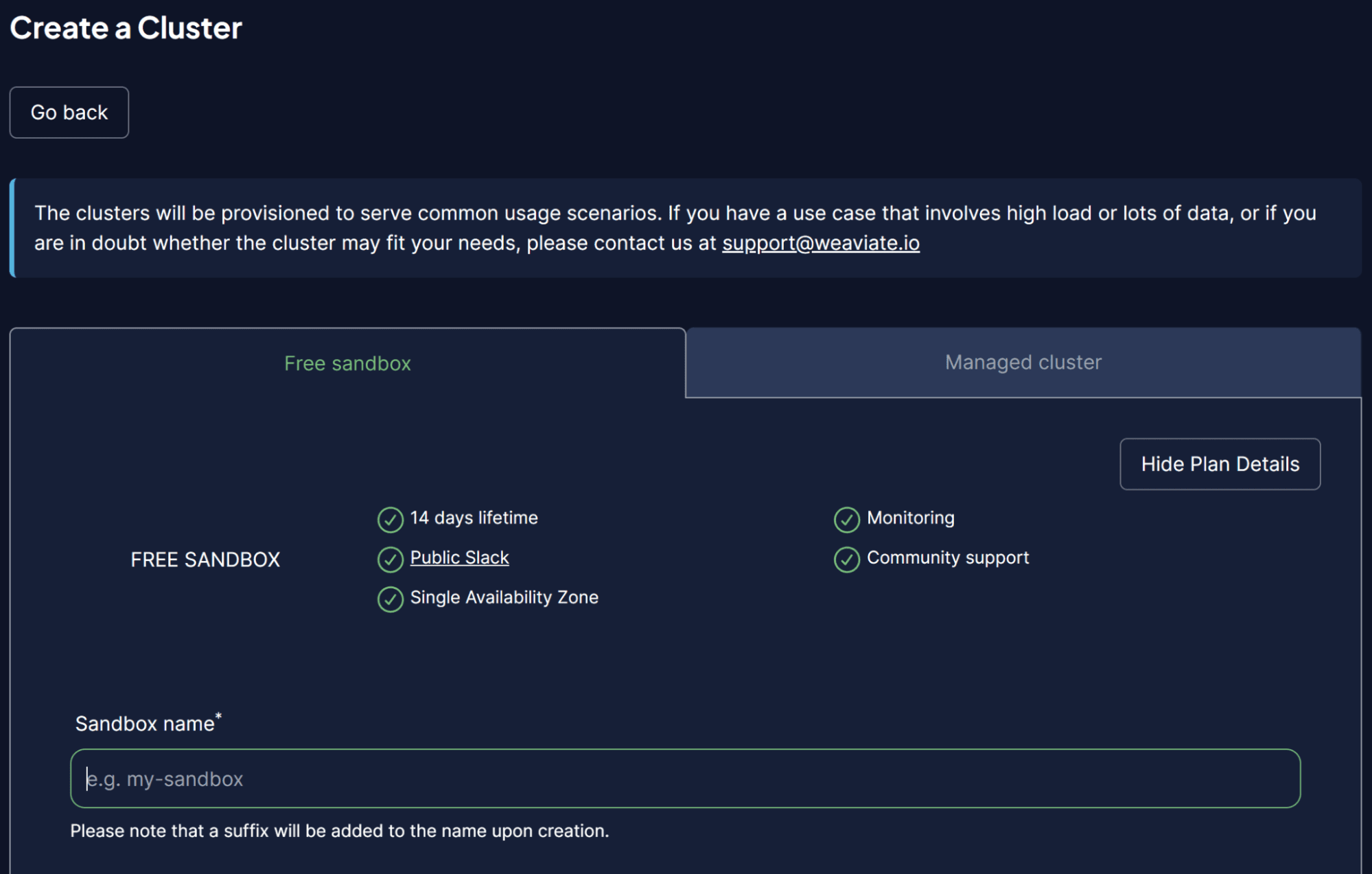
Imagem do autor
Não se esqueça de habilitar a autenticação, pois também queremos acessar este cluster através da chave API WCS. Depois que o cluster estiver pronto, encontre a chave API e a URL do cluster, que usaremos para acessar o banco de dados de vetores.
Quando tudo estiver pronto, simularemos o armazenamento de nosso primeiro vetor no banco de dados de vetores.
Para o exemplo de armazenamento do banco de dados vetorial, eu usaria o Coleção de livros conjunto de dados de exemplo do Kaggle. Eu usaria apenas as 100 primeiras linhas e 3 colunas (título, descrição, introdução).
import pandas as pd
data = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
Vamos deixar de lado nossos dados e conectar-nos ao nosso banco de dados de vetores. Primeiro, precisamos configurar uma conexão remota usando a chave API e o URL do seu cluster.
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
Depois de configurar sua variável de cliente, nos conectaremos ao Weaviate Cloud Service e criaremos uma classe para armazenar o vetor. Classe no Weaviate é a coleta de dados ou análogos ao nome da tabela em um banco de dados relacional.
import weaviate.classes as wvc
client.connect()
book_collection = client.collections.create(
name="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
No código acima, nos conectamos ao Weaviate Cluster e criamos uma classe BookCollection. O objeto de classe também usa o modelo de incorporação OpenAI text2vec para vetorizar os dados de texto e o módulo generativo OpenAI.
Vamos tentar armazenar os dados de texto em um banco de dados vetorial. Para fazer isso, você pode usar o seguinte código.
sent_to_vdb = data.to_dict(orient='records')
book_collection.data.insert_many(sent_to_vdb)
Imagem do autor
Acabamos de armazenar com sucesso nosso conjunto de dados no banco de dados de vetores! Quão fácil é isso?
Agora, você pode estar curioso sobre os casos de uso de bancos de dados vetoriais com LLM. É isso que discutiremos a seguir.
Alguns casos de uso em que o LLM pode ser aplicado com banco de dados vetorial. Vamos explorá-los juntos.
Pesquisa semântica
A Pesquisa Semântica é um processo de busca de dados usando o significado da consulta para recuperar resultados relevantes, em vez de depender apenas da pesquisa tradicional baseada em palavras-chave.
O processo envolve a utilização da incorporação do modelo LLM da consulta e a realização de pesquisa de similaridade de incorporação em nosso armazenamento incorporado no banco de dados de vetores.
Vamos tentar usar o Weaviate para realizar uma pesquisa semântica baseada em uma consulta específica.
book_collection = client.collections.get("BookCollection")
client.connect()
response = book_collection.query.near_text(
query="childhood story,
limit=2
)
No código acima, tentamos realizar uma pesquisa semântica com Weaviate para encontrar os dois principais livros intimamente relacionados à consulta história de infância. A pesquisa semântica usa o modelo de incorporação OpenAI que configuramos anteriormente. O resultado é o que você pode ver abaixo.
{'title': 'Act Your Age', 'description': 'A young girl is told over and over again to act her age.', 'intro': 'Colleen Archer has written for nHighlightsn. In this short story, a young girl is told over and over again to act her age.nAs you read, take notes on what Frances is doing when she is told to act her age. '}
{'title': 'The Anklet', 'description': 'A young woman must deal with unkind and spiteful treatment from her two older sisters.', 'intro': "Neil Philip is a writer and poet who has retold the best-known stories from nThe Arabian Nightsn for a modern day audience. nThe Arabian Nightsn is the English-language nickname frequently given to nOne Thousand and One Arabian Nightsn, a collection of folk tales written and collected in the Middle East during the Islamic Golden Age of the 8th to 13th centuries. In this tale, a poor young woman must deal with mistreatment by members of her own family.nAs you read, take notes on the youngest sister's actions and feelings."}
Como você pode ver, não há palavras diretas sobre histórias de infância no resultado acima. Porém, o resultado ainda está intimamente relacionado a uma história voltada para o público infantil.
Pesquisa Generativa
A Pesquisa Generativa poderia ser definida como uma aplicação de extensão da Pesquisa Semântica. A Pesquisa Generativa, ou Geração Aumentada de Recuperação (RAG), utiliza prompt LLM com a pesquisa semântica que recuperou dados do banco de dados vetorial.
Com o RAG, o resultado da pesquisa da consulta é processado para LLM, então os obtemos na forma que desejamos, em vez dos dados brutos. Vamos tentar uma implementação simples do RAG com banco de dados vetorial.
response = book_collection.generate.near_text(
query="childhood story",
limit=2,
grouped_task="Write a short LinkedIn post about these books."
)
print(response.generated)
O resultado pode ser conferido no texto abaixo.
Excited to share two captivating short stories that explore themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a young girl who is constantly told to act her age, while "The Anklet" by Neil Philip delves into the unkind treatment faced by a young woman from her older sisters. These thought-provoking tales will leave you reflecting on societal expectations and family dynamics. #ShortStories #Literature #BookRecommendations 📚
Como você pode ver, o conteúdo dos dados é o mesmo de antes, mas agora foi processado com OpenAI LLM para fornecer uma breve postagem no LinkedIn. Dessa forma, o RAG é útil quando desejamos uma saída de formulário específica a partir dos dados.
Resposta a perguntas com RAG
Em nosso exemplo anterior, usamos uma consulta para obter os dados que queríamos e o RAG processou esses dados na saída pretendida.
No entanto, podemos transformar a capacidade RAG numa ferramenta de resposta a perguntas. Podemos conseguir isso combinando-os com a estrutura LangChain.
Primeiro, vamos instalar os pacotes necessários.
pip install langchain
pip install langchain_community
pip install langchain_openai
Então, vamos tentar importar os pacotes e iniciar as variáveis necessárias para fazer o controle de qualidade com RAG funcionar.
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name = 'gpt-3.5-turbo-instruct', temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
client = weaviate.Client(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
No código acima, configuramos o LLM para a geração de texto, modelo de incorporação e conexão do cliente Weaviate.
A seguir, definimos a conexão do Weaviate com o banco de dados vetorial.
weaviate_vectorstore = Weaviate(client=client, index_name='BookCollection', text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
No código acima, torne o Weaviate Database BookCollection a ferramenta RAG que pesquisaria o recurso 'introdução' quando solicitado.
Em seguida, criaríamos uma Cadeia de Respostas a Perguntas a partir do LangChain com o código abaixo.
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
Agora tudo está pronto. Vamos testar o controle de qualidade com RAG usando o exemplo de código a seguir.
response = qa_chain.invoke(
"Who is the writer who write about love between two goldfish?")
print(response)
O resultado é mostrado no texto abaixo.
{'query': 'Who is the writer who write about love between two goldfish?', 'result': ' The writer is Grace Chua.'}
Com o banco de dados vetorial como local para armazenar todos os dados de texto, podemos implementar RAG para realizar controle de qualidade com LangChain. Quão legal é isso?
Um banco de dados vetorial é uma solução de armazenamento especializada projetada para armazenar, indexar e consultar dados vetoriais. É frequentemente usado para armazenar dados de texto e implementado em conjunto com Large Language Models (LLMs). Este artigo tentará uma configuração prática do banco de dados vetorial Weaviate, incluindo exemplos de casos de uso como pesquisa semântica, geração aumentada de recuperação (RAG) e resposta a perguntas com RAG.
Cornélio Yudha Wijaya é gerente assistente de ciência de dados e redator de dados. Enquanto trabalha em tempo integral na Allianz Indonésia, ele adora compartilhar dicas sobre Python e dados nas redes sociais e na mídia escrita. Cornellius escreve sobre uma variedade de tópicos de IA e aprendizado de máquina.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.kdnuggets.com/vector-databases-in-ai-and-llm-use-cases?utm_source=rss&utm_medium=rss&utm_campaign=vector-databases-in-ai-and-llm-use-cases

