Introdução
O estresse é uma resposta natural do corpo e da mente a uma situação exigente ou desafiadora. É a maneira do corpo reagir a pressões externas ou pensamentos e sentimentos internos. O estresse pode ser desencadeado por uma variedade de fatores, como pressão relacionada ao trabalho, dificuldades financeiras, problemas de relacionamento, problemas de saúde ou eventos importantes da vida. Os insights de detecção de estresse, impulsionados pela ciência de dados e aprendizado de máquina, visam prever os níveis de estresse em indivíduos ou populações. Ao analisar uma variedade de fontes de dados, como medições fisiológicas, dados comportamentais e fatores ambientais, os modelos preditivos podem identificar padrões e fatores de risco associados ao estresse.

Essa abordagem proativa permite intervenção oportuna e suporte personalizado. A previsão do estresse tem potencial nos cuidados de saúde para detecção precoce e intervenção personalizada, bem como em ambientes ocupacionais para otimizar os ambientes de trabalho. Também pode informar iniciativas de saúde pública e decisões políticas. Com a capacidade de prever o estresse, esses modelos fornecem informações valiosas para melhorar o bem-estar e aumentar a resiliência em indivíduos e comunidades.
Este artigo foi publicado como parte do Blogatona de Ciência de Dados.
Índice
Visão geral da detecção de estresse usando aprendizado de máquina
A detecção de estresse usando aprendizado de máquina envolve coleta, limpeza e pré-processamento de dados. As técnicas de engenharia de recursos são aplicadas para extrair informações significativas ou criar novos recursos que possam capturar padrões relacionados ao estresse. Isso pode envolver a extração de medidas estatísticas, análise de domínio de frequência ou análise de séries temporais para capturar indicadores fisiológicos ou comportamentais de estresse. Recursos relevantes são extraídos ou projetados para melhorar o desempenho.

Os pesquisadores treinam modelos de aprendizado de máquina, como regressão logística, SVM, árvores de decisão, florestas aleatórias ou redes neurais, utilizando dados rotulados para classificar os níveis de estresse. Eles avaliam o desempenho dos modelos usando métricas como exatidão, precisão, recall e F1-score. A integração do modelo treinado em aplicativos do mundo real permite o monitoramento de estresse em tempo real. Monitoramento contínuo, atualizações e feedback do usuário são cruciais para melhorar a precisão.
É crucial considerar questões éticas e questões de privacidade ao lidar com dados pessoais sensíveis relacionados ao estresse. Consentimento informado adequado, anonimização de dados e procedimentos seguros de armazenamento de dados devem ser seguidos para proteger a privacidade e os direitos dos indivíduos. Considerações éticas, privacidade e segurança de dados são importantes durante todo o processo. A detecção de estresse baseada em aprendizado de máquina permite intervenção precoce, gerenciamento de estresse personalizado e melhoria do bem-estar.
descrição de dados
O conjunto de dados “estresse” contém informações relacionadas aos níveis de estresse. Sem a estrutura e as colunas específicas do conjunto de dados, posso fornecer uma visão geral da aparência de uma descrição de dados para um percentil.
O conjunto de dados pode conter variáveis numéricas que representam medições quantitativas, como idade, pressão arterial, frequência cardíaca ou níveis de estresse medidos em uma escala. Também pode incluir variáveis categóricas que representam características qualitativas, como gênero, categorias ocupacionais ou níveis de estresse classificados em diferentes categorias (baixo, médio, alto).
# Array
import numpy as np # Dataframe
import pandas as pd #Visualization
import matplotlib.pyplot as plt
import seaborn as sns # warnings
import warnings
warnings.filterwarnings('ignore') #Data Reading
stress_c= pd.read_csv('/human-stress-prediction/Stress.csv') # Copy
stress=stress_c.copy() # Data
stress.head()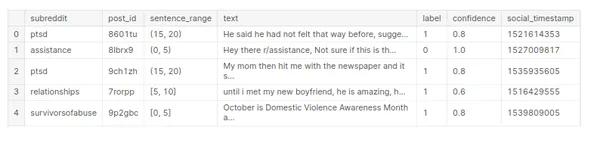
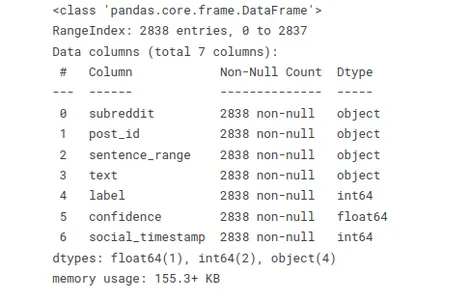
A função abaixo permite que você avalie rapidamente os tipos de dados e descubra valores ausentes ou nulos. Este resumo é útil ao trabalhar com grandes conjuntos de dados ou executar tarefas de limpeza e pré-processamento de dados.
# Info
stress.info()
Use o código stress.isnull().sum() para verificar valores nulos no conjunto de dados “stress” e calcular a soma dos valores nulos em cada coluna.
# Checking null values
stress.isnull().sum()

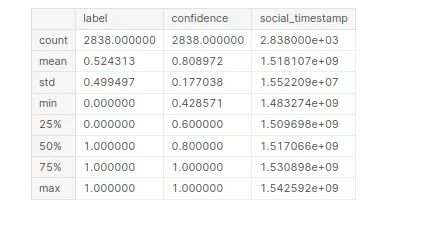
Para gerar informações estatísticas sobre o conjunto de dados “stress”. Ao compilar esse código, você obterá um resumo das estatísticas descritivas para cada coluna numérica no conjunto de dados.
# Statistical Information
stress.describe()
Análise Exploratória de Dados (EDA)
A Análise Exploratória de Dados (EDA) é uma etapa crucial na compreensão e análise de um conjunto de dados. Envolve explorar visualmente e resumir as principais características, padrões e relacionamentos dentro dos dados.
lst=['subreddit','label']
plt.figure(figsize=(15,12))
for i in range(len(lst)): plt.subplot(1,2,i+1) a=stress[lst[i]].value_counts() lbl=a.index plt.title(lst[i]+'_Distribution') plt.pie(x=a,labels=lbl,autopct="%.1f %%") plt.show()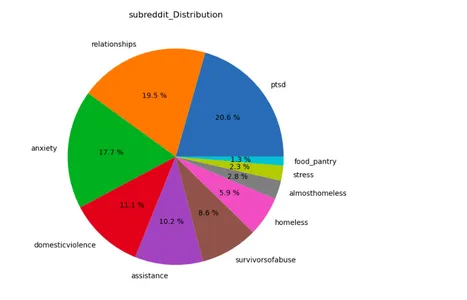
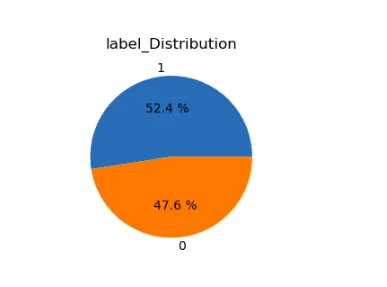
As bibliotecas Matplotlib e Seaborn criam um gráfico de contagem para o conjunto de dados “stress”. Ele visualiza a contagem de instâncias de estresse em diferentes subreddits, com os rótulos de estresse diferenciados por cores diferentes.
plt.figure(figsize=(20,12))
plt.title('Subreddit wise stress count')
plt.xlabel('Subreddit')
sns.countplot(data=stress,x='subreddit',hue='label',palette='gist_heat')
plt.show()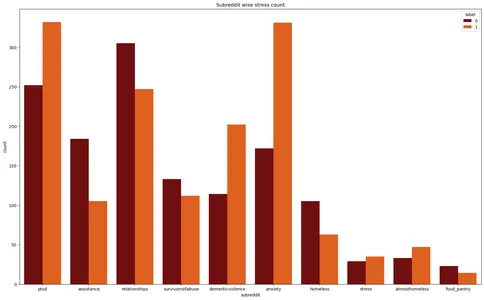
Pré-processamento de texto
O pré-processamento de texto refere-se ao processo de conversão de dados de texto bruto em um formato mais limpo e estruturado, adequado para tarefas de análise ou modelagem. Envolve especialmente uma série de etapas para remover ruído, normalizar texto e extrair recursos relevantes. Aqui adicionei todas as bibliotecas relacionadas a esse processamento de texto.
# Regular Expression
import re # Handling string
import string # NLP tool
import spacy nlp=spacy.load('en_core_web_sm')
from spacy.lang.en.stop_words import STOP_WORDS # Importing Natural Language Tool Kit for NLP operations
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('omw-1.4') from nltk.stem import WordNetLemmatizer from wordcloud import WordCloud, STOPWORDS
from nltk.corpus import stopwords
from collections import Counter
Algumas técnicas comuns usadas no pré-processamento de texto incluem:
Limpeza de texto
- Remoção de caracteres especiais: remova pontuação, símbolos ou caracteres não alfanuméricos que não contribuam para o significado do texto.
- Remoção de números: Remova os dígitos numéricos se eles não forem relevantes para a análise.
- Minúsculas: converta todo o texto em minúsculas para garantir consistência na correspondência e análise de texto.
- Remoção de palavras de parada: Remova palavras comuns que não carregam muita informação, como “um”, “o”, “é”, etc.
tokenization
- Dividindo o texto em palavras ou tokens: divida o texto em palavras ou tokens individuais para se preparar para análises posteriores. Os pesquisadores podem conseguir isso empregando espaço em branco ou técnicas de tokenização mais avançadas, como a utilização de bibliotecas como NLTK ou spaCy.
Normalização
- Lematização: Reduzir as palavras à sua forma base ou de dicionário (lemas). Por exemplo, converter “running” e “run” para “run”.
- Stemming: reduza as palavras à sua forma básica removendo prefixos ou sufixos. Por exemplo, converter “running” e “run” para “run”.
- Removendo diacríticos: Remova acentos ou outros sinais diacríticos dos caracteres.
#defining function for preprocessing
def preprocess(text,remove_digits=True): text = re.sub('W+',' ', text) text = re.sub('s+',' ', text) text = re.sub("(?<!w)d+", "", text) text = re.sub("-(?!w)|(?<!w)-", "", text) text=text.lower() nopunc=[char for char in text if char not in string.punctuation] nopunc=''.join(nopunc) nopunc=' '.join([word for word in nopunc.split() if word.lower() not in stopwords.words('english')]) return nopunc
# Defining a function for lemitization
def lemmatize(words): words=nlp(words) lemmas = [] for word in words: lemmas.append(word.lemma_) return lemmas #converting them into string
def listtostring(s): str1=' ' return (str1.join(s)) def clean_text(input): word=preprocess(input) lemmas=lemmatize(word) return listtostring(lemmas)# Creating a feature to store clean texts
stress['clean_text']=stress['text'].apply(clean_text)
stress.head()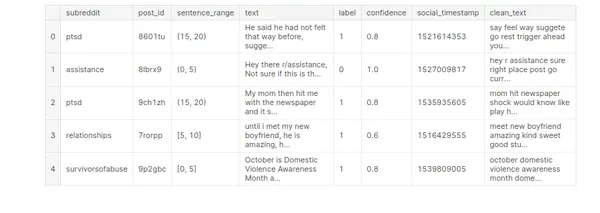
Construção de modelo de aprendizado de máquina
A construção de modelo de aprendizado de máquina é o processo de criação de uma representação ou modelo matemático que pode aprender padrões e fazer previsões ou decisões a partir de dados. Envolve treinar um modelo usando um conjunto de dados rotulado e, em seguida, usar esse modelo para fazer previsões sobre dados novos e não vistos.
Selecionar ou criar recursos relevantes a partir dos dados disponíveis. A engenharia de recursos visa extrair informações significativas dos dados brutos que podem ajudar o modelo a aprender padrões de maneira eficaz.
# Vectorization
from sklearn.feature_extraction.text import TfidfVectorizer # Model Building
from sklearn.model_selection import GridSearchCV,StratifiedKFold, KFold,train_test_split,cross_val_score,cross_val_predict
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn import preprocessing
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier,RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier #Model Evaluation
from sklearn.metrics import confusion_matrix,classification_report, accuracy_score,f1_score,precision_score
from sklearn.pipeline import Pipeline # Time
from time import time# Defining target & feature for ML model building
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)Escolher um algoritmo de aprendizado de máquina apropriado ou arquitetura de modelo com base na natureza do problema e nas características dos dados. Modelos diferentes, como árvores de decisão, máquinas de vetores de suporte ou redes neurais, têm diferentes pontos fortes e fracos.
Treinando o modelo selecionado usando os dados rotulados. Esta etapa envolve alimentar o modelo com os dados de treinamento e permitir que ele aprenda os padrões e relacionamentos entre os recursos e a variável de destino.
# Self-defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Logistic regression def model_lr_tf(x_train, x_test, y_train, y_test): global acc_lr_tf,f1_lr_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = LogisticRegression() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_lr_tf=accuracy_score(y_test,y_pred) f1_lr_tf=f1_score(y_test,y_pred,average='weighted') print('Time :',time()-t0) print('Accuracy: ',acc_lr_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_lr_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by MultinomialNB def model_nb_tf(x_train, x_test, y_train, y_test): global acc_nb_tf,f1_nb_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = MultinomialNB() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_nb_tf=accuracy_score(y_test,y_pred) f1_nb_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_nb_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_nb_tf # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Decision Tree
def model_dt_tf(x_train, x_test, y_train, y_test): global acc_dt_tf,f1_dt_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = DecisionTreeClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_dt_tf=accuracy_score(y_test,y_pred) f1_dt_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_dt_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_dt_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by KNN def model_knn_tf(x_train, x_test, y_train, y_test): global acc_knn_tf,f1_knn_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = KNeighborsClassifier() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_knn_tf=accuracy_score(y_test,y_pred) f1_knn_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_knn_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Random Forest def model_rf_tf(x_train, x_test, y_train, y_test): global acc_rf_tf,f1_rf_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = RandomForestClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_rf_tf=accuracy_score(y_test,y_pred) f1_rf_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_rf_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Adaptive Boosting def model_ab_tf(x_train, x_test, y_train, y_test): global acc_ab_tf,f1_ab_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = AdaBoostClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_ab_tf=accuracy_score(y_test,y_pred) f1_ab_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_ab_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) Avaliação de modelo
A avaliação do modelo é uma etapa crucial no aprendizado de máquina para avaliar o desempenho e a eficácia de um modelo treinado. Envolve medir o quão bem os vários modelos se generalizam para dados não vistos e se atendem aos objetivos desejados. Avalie o desempenho do modelo treinado nos dados de teste. Calcule as métricas de avaliação, como exatidão, precisão, recuperação e pontuação F1 para avaliar a eficácia do modelo na detecção de estresse. A avaliação do modelo fornece informações sobre os pontos fortes e fracos do modelo e sua adequação para a tarefa pretendida.
# Evaluating Models print('********************Logistic Regression*********************')
print('n')
model_lr_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
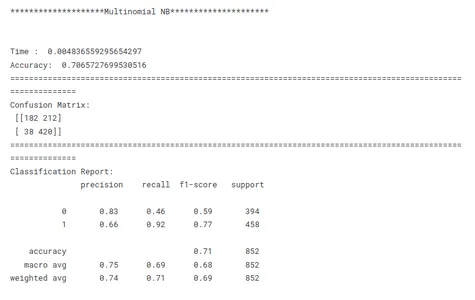
print('********************Multinomial NB*********************')
print('n')
model_nb_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
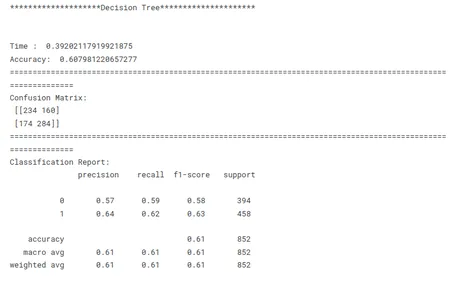
print('********************Decision Tree*********************')
print('n')
model_dt_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
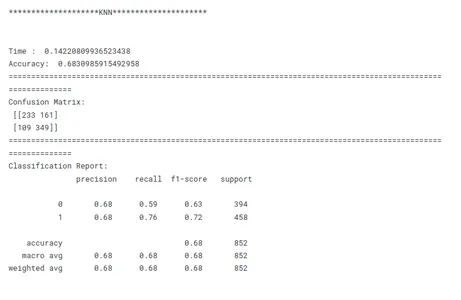
print('********************KNN*********************')
print('n')
model_knn_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
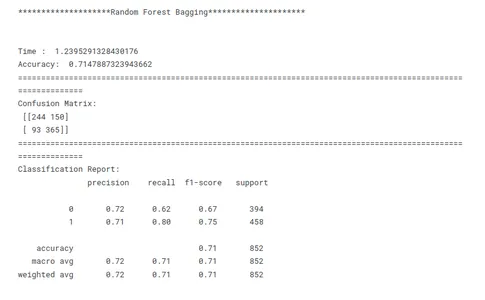
print('********************Random Forest Bagging*********************')
print('n')
model_rf_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
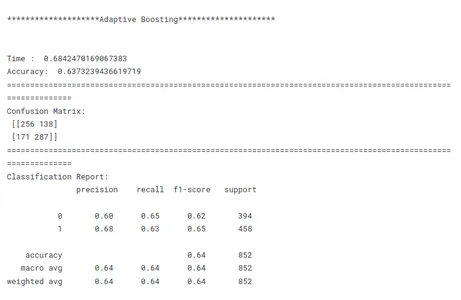
print('********************Adaptive Boosting*********************')
print('n')
model_ab_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')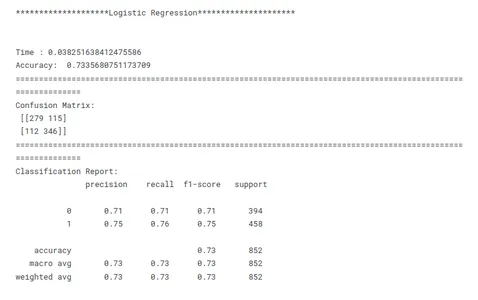
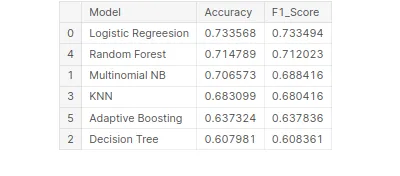
Comparação de desempenho do modelo
Esta é uma etapa crucial no aprendizado de máquina para identificar o modelo de melhor desempenho para uma determinada tarefa. Ao comparar modelos, é importante ter um objetivo claro em mente. Seja maximizando a precisão, otimizando a velocidade ou priorizando a interpretabilidade, as métricas e técnicas de avaliação devem estar alinhadas com o objetivo específico.
A consistência é fundamental na comparação de desempenho do modelo. O uso de métricas de avaliação consistentes em todos os modelos garante uma comparação justa e significativa. Também é importante dividir os dados em conjuntos de treinamento, validação e teste de forma consistente em todos os modelos. Ao garantir que os modelos sejam avaliados nos mesmos subconjuntos de dados, os pesquisadores permitem uma comparação justa de seu desempenho.
Considerando esses fatores acima, os pesquisadores podem realizar uma comparação abrangente e justa do desempenho do modelo, o que levará a decisões informadas sobre a seleção do modelo para o problema específico em questão.
# Creating tabular format for better comparison
tbl=pd.DataFrame()
tbl['Model']=pd.Series(['Logistic Regreesion','Multinomial NB', 'Decision Tree','KNN','Random Forest','Adaptive Boosting'])
tbl['Accuracy']=pd.Series([acc_lr_tf,acc_nb_tf,acc_dt_tf,acc_knn_tf, acc_rf_tf,acc_ab_tf])
tbl['F1_Score']=pd.Series([f1_lr_tf,f1_nb_tf,f1_dt_tf,f1_knn_tf, f1_rf_tf,f1_ab_tf])
tbl.set_index('Model')
# Best model on the basis of F1 Score
tbl.sort_values('F1_Score',ascending=False)
Validação cruzada para evitar overfitting
A validação cruzada é de fato uma técnica valiosa para ajudar a evitar o overfitting ao treinar modelos de aprendizado de máquina. Ele fornece uma avaliação robusta do desempenho do modelo usando vários subconjuntos de dados para treinamento e teste. Ele ajuda a avaliar a capacidade de generalização do modelo, estimando seu desempenho em dados não vistos.
# Using cross validation method to avoid overfitting
import statistics as st
vector = TfidfVectorizer() x_train_v = vector.fit_transform(x_train)
x_test_v = vector.transform(x_test) # Model building
lr =LogisticRegression()
mnb=MultinomialNB()
dct=DecisionTreeClassifier(random_state=1)
knn=KNeighborsClassifier()
rf=RandomForestClassifier(random_state=1)
ab=AdaBoostClassifier(random_state=1)
m =[lr,mnb,dct,knn,rf,ab]
model_name=['Logistic R','MultiNB','DecTRee','KNN','R forest','Ada Boost'] results, mean_results, p, f1_test=list(),list(),list(),list() #Model fitting,cross-validating and evaluating performance def algor(model): print('n',i) pipe=Pipeline([('model',model)]) pipe.fit(x_train_v,y_train) cv=StratifiedKFold(n_splits=5) n_scores=cross_val_score(pipe,x_train_v,y_train,scoring='f1_weighted', cv=cv,n_jobs=-1,error_score='raise') results.append(n_scores) mean_results.append(st.mean(n_scores)) print('f1-Score(train): mean= (%.3f), min=(%.3f)) ,max= (%.3f), stdev= (%.3f)'%(st.mean(n_scores), min(n_scores), max(n_scores),np.std(n_scores))) y_pred=cross_val_predict(model,x_train_v,y_train,cv=cv) p.append(y_pred) f1=f1_score(y_train,y_pred, average = 'weighted') f1_test.append(f1) print('f1-Score(test): %.4f'%(f1)) for i in m: algor(i) # Model comparison By Visualizing fig=plt.subplots(figsize=(20,15))
plt.title('MODEL EVALUATION BY CROSS VALIDATION METHOD')
plt.xlabel('MODELS')
plt.ylabel('F1 Score')
plt.boxplot(results,labels=model_name,showmeans=True)
plt.show() 
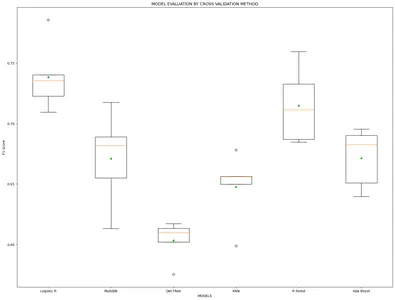
Como as pontuações dos modelos F1 estão chegando bastante semelhantes em ambos os métodos. Então agora estamos aplicando o método Leave One Out para construir o modelo de melhor desempenho.
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1) vector = TfidfVectorizer()
x_train = vector.fit_transform(x_train)
x_test = vector.transform(x_test)
model_lr_tf=LogisticRegression() model_lr_tf.fit(x_train,y_train)
y_pred=model_lr_tf.predict(x_test)
# Model Evaluation conf=confusion_matrix(y_test,y_pred)
acc_lr=accuracy_score(y_test,y_pred)
f1_lr=f1_score(y_test,y_pred,average='weighted') print('Accuracy: ',acc_lr)
print('F1 Score: ',f1_lr)
print(10*'===========')
print('Confusion Matrix: n',conf)
print(10*'===========')
print('Classification Report: n',classification_report(y_test,y_pred))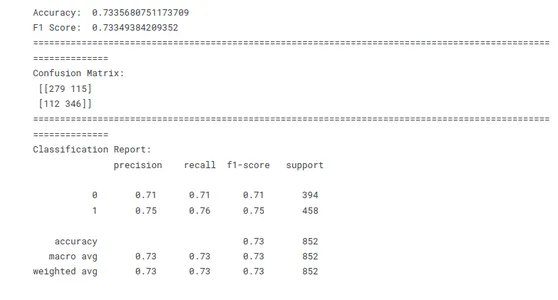
Nuvens de palavras de palavras tônicas e não tônicas
O conjunto de dados contém mensagens de texto ou documentos rotulados como estressados ou não estressados. O código percorre os dois rótulos para criar uma nuvem de palavras para cada rótulo usando a biblioteca WordCloud e exibir a visualização da nuvem de palavras. Cada nuvem de palavras representa as palavras mais usadas na respectiva categoria, com palavras maiores indicando maior frequência. A escolha do mapa de cores ('inverno', 'outono', 'magma', 'Viridis', 'plasma') determina o esquema de cores das nuvens de palavras. As visualizações resultantes fornecem uma representação concisa das palavras mais frequentes associadas a mensagens ou documentos com e sem ênfase.
Aqui estão as nuvens de palavras que representam palavras estressadas e não estressadas comumente associadas à detecção de estresse:
for label, cmap in zip([0,1], ['winter', 'autumn', 'magma', 'viridis', 'plasma']): text = stress.query('label == @label')['text'].str.cat(sep=' ') plt.figure(figsize=(12, 9)) wc = WordCloud(width=1000, height=600, background_color="#f8f8f8", colormap=cmap) wc.generate_from_text(text) plt.imshow(wc) plt.axis("off") plt.title(f"Words Commonly Used in ${label}$ Messages", size=20) plt.show()

Predição
Os novos dados de entrada são pré-processados e os recursos são extraídos para corresponder às expectativas do modelo. A função de previsão é então usada para gerar previsões com base nos recursos extraídos. Por fim, as previsões são impressas ou utilizadas conforme necessário para análise posterior ou tomada de decisão.
data=["""I don't have the ability to cope with it anymore. I'm trying, but a lot of things are triggering me, and I'm shutting down at work, just finding the place I feel safest, and staying there for an hour or two until I feel like I can do something again. I'm tired of watching my back, tired of traveling to places I don't feel safe, tired of reliving that moment, tired of being triggered, tired of the stress, tired of anxiety and knots in my stomach, tired of irrational thought when triggered, tired of irrational paranoia. I'm exhausted and need a break, but know it won't be enough until I journey the long road through therapy. I'm not suicidal at all, just wishing this pain and misery would end, to have my life back again."""] data=vector.transform(data)
model_lr_tf.predict(data)
data=["""In case this is the first time you're reading this post... We are looking for people who are willing to complete some online questionnaires about employment and well-being which we hope will help us to improve services for assisting people with mental health difficulties to obtain and retain employment. We are developing an employment questionnaire for people with personality disorders; however we are looking for people from all backgrounds to complete it. That means you do not need to have a diagnosis of personality disorder – you just need to have an interest in completing the online questionnaires. The questionnaires will only take about 10 minutes to complete online. For your participation, we’ll donate £1 on your behalf to a mental health charity (Young Minds: Child & Adolescent Mental Health, Mental Health Foundation, or Rethink)"""] data=vector.transform(data)
model_lr_tf.predict(data)
Conclusão
A aplicação de técnicas de aprendizado de máquina na previsão dos níveis de estresse fornece insights personalizados para o bem-estar mental. Ao analisar uma variedade de fatores, como medições numéricas (pressão arterial, frequência cardíaca) e características categóricas (por exemplo, gênero, ocupação), os modelos de aprendizado de máquina podem aprender padrões e fazer previsões sobre um nível de estresse individual. Com a capacidade de detectar e monitorar com precisão os níveis de estresse, o aprendizado de máquina contribui para o desenvolvimento de estratégias e intervenções proativas para gerenciar e melhorar o bem-estar mental.
Exploramos os insights do uso de aprendizado de máquina na previsão de estresse e seu potencial para revolucionar nossa abordagem para lidar com esse problema crítico.
- Previsões precisas: os algoritmos de aprendizado de máquina analisam grandes quantidades de dados históricos para prever com precisão as ocorrências de estresse, fornecendo informações e previsões valiosas.
- Detecção Precoce: o aprendizado de máquina pode detectar sinais de alerta desde o início, permitindo medidas proativas e suporte oportuno em áreas vulneráveis.
- Planejamento aprimorado e alocação de recursos: O aprendizado de máquina permite a previsão de intensidades e pontos críticos nas ruas, otimizando a alocação de recursos, como serviços de emergência e instalações médicas.
- Segurança Pública Aprimorada: Alertas e avisos oportunos emitidos por meio de previsões de aprendizado de máquina capacitam os indivíduos a tomar as precauções necessárias, reduzindo o impacto das ruas e melhorando a segurança pública.
Em conclusão, esta análise de previsão de estresse fornece informações valiosas sobre os níveis de estresse e sua previsão usando aprendizado de máquina. Use as descobertas para desenvolver ferramentas e intervenções para o gerenciamento do estresse, promovendo bem-estar geral e melhor qualidade de vida.
Perguntas Frequentes
A: 1. Avaliação objetiva: fornece uma abordagem objetiva e baseada em dados para avaliar os níveis de estresse, eliminando possíveis vieses que possam surgir em avaliações subjetivas.
2. AMPLIAR: os algoritmos de aprendizado de máquina podem processar grandes volumes de dados de texto com eficiência, tornando-os escaláveis para analisar uma ampla variedade de expressões textuais.
3. Monitoramento em tempo real: Ao automatizar a detecção de estresse, permite o monitoramento em tempo real dos níveis de estresse, permitindo intervenções e suporte oportunos.
4. Insights e pesquisas: pode revelar percepções e tendências relacionadas ao estresse, contribuindo para a compreensão dos gatilhos, impactos e possíveis intervenções do estresse.
A: 1. Publicações nas redes sociais: conteúdo textual de plataformas como Twitter, Facebook ou fóruns online onde os indivíduos expressam seus pensamentos e emoções.
2. Registros de bate-papo: dados de conversação de aplicativos de mensagens, sistemas de suporte online ou chatbots de saúde mental.
3. Pesquisas ou questionários on-line: Respostas textuais a perguntas relacionadas ao estresse ou bem-estar mental.
4. Registros Eletrônicos de Saúde: Notas clínicas ou narrativas de pacientes que contêm informações relevantes sobre experiências relacionadas ao estresse.
R: 1. As expressões textuais de estresse podem variar muito entre os indivíduos, dificultando a captura de todos os indicadores e padrões relevantes.
2. A compreensão do contexto é crucial na detecção de estresse, pois o mesmo texto pode ser lido de forma diferente dependendo do contexto e do indivíduo.
3. A aquisição de dados rotulados para modelos de aprendizado de máquina de treinamento pode consumir muito tempo e muitos recursos, exigindo informações de especialistas ou julgamentos subjetivos.
4. Garantir a privacidade dos dados, confidencialidade e tratamento ético de informações confidenciais de saúde mental é fundamental ao trabalhar com dados de texto relacionados ao estresse.
A mídia mostrada neste artigo não é propriedade da Analytics Vidhya e é usada a critério do Autor.
Relacionado
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- EVM Finanças. Interface unificada para finanças descentralizadas. Acesse aqui.
- Grupo de Mídia Quântica. IR/PR Amplificado. Acesse aqui.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/06/machine-learning-unlocks-insights-for-stress-detection/

