Imagem do editor
Houve um aumento bem documentado em cargos relacionados à Diversidade, Equidade e Inclusão nos últimos 3 a 5 anos. Os analistas de DEI podem gastar seu tempo rastreando, analisando e respondendo a perguntas como:
- Como os salários se comparam entre os sexos?
- Como nossos departamentos se classificam em termos de diversidade racial?
- Quais cargos e títulos são os menos diversos?
Embora os Analistas DEI se concentrem em responder a diferentes tipos de perguntas dos Analistas de Negócios, eles ainda usam as mesmas técnicas e habilidades técnicas.
Classes protegidas são tipicamente categórico: Sexo, Raça, Etnia e Idade (geralmente a idade é dividida em categorias)
Numérico dados, como salário, podem ser agregados em classes protegidas com
- Média
- Mediana
- Mínimo
- Máximo
Quando você analisa a combinação de um Categórico e de um Numérico variáveis, o SQL facilita bastante:
SELECT ethnicity, AVG(salary) as AVG_SALARY, MEDIAN(salary) as MEDIAN_SALARY FROM HRDATA GROUP BY ethnicity
| Etnia | AVG_SALÁRIO | MEDIAN_SALÁRIO |
| Branco | $68,513 | $60,050 |
| Africano americano | $67,691 | $55,114 |
| Asiático | $68,842 | $65,632 |
Mas que métodos existem para analisar Categórico e Categórico variáveis juntas? As opções padrão são bastante limitadas:
- Modo (mais comum)
- Contagem Distinta
SELECT department, COUNT(1) AS employees, COUNT(DISTINCT ethnicity) AS DISTINCT_ETHNICITY, MODE(ethnicity) AS MOST_COMMON_ETHNICITY FROM HRDATA GROUP BY ethnicity
| Departamento | Colaboradores | Gêneros distintos | Gênero mais comum |
| Vendas | 100 | 2 | Masculino |
| IT | 100 | 2 | Masculino |
À primeira vista, os departamentos parecem ser muito semelhantes. Mas como você diria a diferença entre:
- vendas tem 99 funcionários do sexo masculino e 1 empregada
- Tem 51 funcionários do sexo masculino e 49 funcionárias
Certamente, consideraríamos o último mais diversificado, mas como saberíamos isso rapidamente usando SQL?
Estou aqui para ensiná-lo sobre uma função de agregação subestimada chamada Entropia, o que nos ajudará a quantificar exatamente a diversidade de cada departamento.
| Departamento | Colaboradores | Gêneros distintos | Gênero mais comum | Entropia |
| Vendas | 100 | 2 | Masculino | 0.08 |
| IT | 100 | 2 | Masculino | 0.99 |
Infelizmente, não é tão fácil quanto simplesmente fazer SELECT Department, ENTROPY(ethnicity), mas vou ensinar a lógica SQL, bem como adicioná-la ao código aberto Gerador SQL 5000, para que você possa gerar esse SQL sempre que precisar.
Dr.Rich Huebner fornece alguns dados de exemplo de RH sobre Kaggle. com que podemos usar para explorar algumas das formas de analisar a Diversidade.
Vamos começar consultando os dados para comparar a Posição com a Corrida. Começaremos com o básico: Count, Count Distinct e Mode.
SELECT POSITION, COUNT(1) AS employees, COUNT(DISTINCT RACEDESC) AS DISTINCT_RACE, MODE(RACEDESC) AS MOST_COMMON_RACE FROM HR_DATA WHERE DATEOFTERMINATION IS NULL /*active employees*/
GROUP BY POSITION
ORDER BY 2 DESC
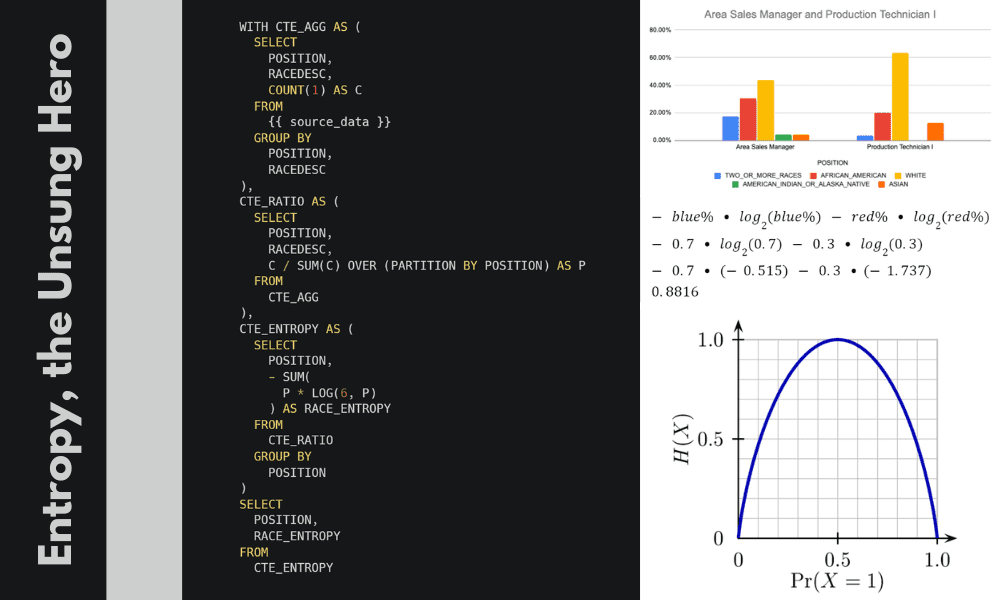
Olhando para os resultados, as 3 posições mais populares parecem ser muito semelhantes em diversidade:
Então, como classificaríamos esses 3 departamentos em termos de diversidade? É aqui que entra a Entropia.
O que é Entropia?
Antes de continuarmos, vamos dedicar um minuto para entender o que é Entropia e como podemos interpretá-la. O conceito de entropia está profundamente enraizado no estudo da teoria da informação e tem muitas aplicações diferentes, incluindo aprendizado de máquina, termodinâmica e criptografia. Portanto, se você procurar a definição, pode ser confuso.
No entanto, a definição mais simples de entropia é algo como isto: A entropia é uma medida numérica para descrever o quão diverso algo é.
Considere um saco de bolinhas que só tem duas cores: vermelho e azul.
Agora, imagine que contamos as bolinhas do saco e descobrimos que havia 99 azuis e apenas 1 vermelha. Esta situação não é muito diversa, então a entropia da bolsa é baixa.
Em seguida, imagine uma sacola com 50 bolinhas azuis e 50 vermelhas. Esta bolsa é muito diversa, na verdade não poderia ser mais diversa. Uma sacola com 51 bolinhas azuis e 49 vermelhas é ligeiramente menos diversos. Portanto, esta bolsa tem alta entropia.
Assim,
- Uma sacola com 100 bolinhas azuis e 0 bolinhas azuis é a menos diversa: Entropia = 0
- Uma sacola com 50 bolinhas azuis e 50 bolinhas vermelhas é a mais diversa: Entropia = 1
Portanto, a entropia atinge um máximo de 1 em 50/50. Aqui está um gráfico comum de como a Entropia muda com a % Azul das bolinhas de gude:
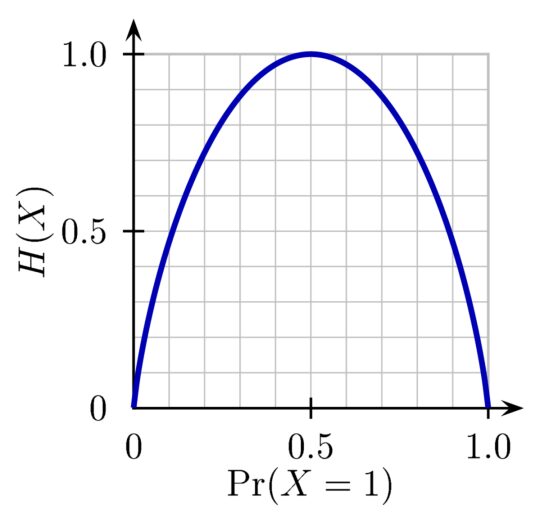
Crédito: https://commons.wikimedia.org/wiki/File:Binary_entropy_plot.png
Para calcular a entropia, calculamos a porcentagem de cada cor e lembramos da fórmula:

Então, para uma sacola com 70% de bolinhas azuis, construímos a fórmula assim:

Quando você estende isso para mais de 2 opções, basta alterar a base do log para corresponder ao número de possibilidades.
Esta é uma operação bastante simples e eficiente para o SQL manipular.
O resultado final nos mostra que, embora nenhum dos cargos seja perfeitamente diverso, Gerente de Vendas de Área é mais diverso do que Técnico de Produção.
Podemos confirmar isso visualmente plotando isso em um gráfico.
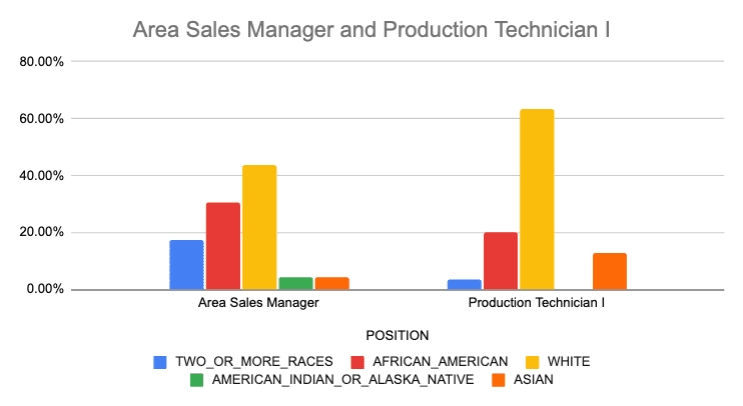
A entropia é um método útil para descrever a diversidade. Ele permite que você classifique ou classifique departamentos, cargos ou empresas combinando essas categorias com uma classe protegida, como raça ou gênero. Mesmo que a função não exista diretamente na maioria dos RDMBS, podemos facilmente construir o SQL para calculá-la. Acredito que seja importante para quem trabalha com Diversidade, Equidade e Inclusão usar esses cálculos ao analisar a força de trabalho de suas organizações. Além disso, tendo trabalhado com dados durante a maior parte da minha carreira, é ótimo ver que o poder do SQL funciona em todas as equipes informadas por dados, desde analistas de dados tradicionais até analistas de DEI.
Josh Berry (@Twitter) lidera o Customer Facing Data Science na Rasgo e está na profissão de dados e análise desde 2008. Josh passou 10 anos na Comcast, onde construiu a equipe de ciência de dados e foi um dos principais proprietários da loja de recursos Comcast desenvolvida internamente - uma das primeiras lojas de recursos para chegar ao mercado. Após a Comcast, Josh foi um líder crítico na construção de Customer Facing Data Science na DataRobot. Em seu tempo livre, Josh realiza análises complexas sobre tópicos interessantes, como beisebol, corridas de F1, previsões do mercado imobiliário e muito mais.
- Coinsmart. A melhor troca de Bitcoin e criptografia da Europa.Clique aqui
- Platoblockchain. Inteligência Metaverso Web3. Conhecimento Ampliado. Acesse aqui.
- Fonte: https://www.kdnuggets.com/2022/11/analyzing-diversity-inclusion-sql.html?utm_source=rss&utm_medium=rss&utm_campaign=analyzing-diversity-inclusion-with-sql

