Gerador de imagem Amazon Titan G1 é um modelo de texto para imagem de última geração, disponível via Rocha Amazônica, que é capaz de entender prompts que descrevem vários objetos em vários contextos e capturar esses detalhes relevantes nas imagens que gera. Ele está disponível nas regiões da AWS Leste dos EUA (Norte da Virgínia) e Oeste dos EUA (Oregon) e pode executar tarefas avançadas de edição de imagens, como corte inteligente, pintura interna e alterações de plano de fundo. No entanto, os usuários gostariam de adaptar o modelo a características exclusivas em conjuntos de dados personalizados nos quais o modelo ainda não foi treinado. Conjuntos de dados personalizados podem incluir dados altamente proprietários que sejam consistentes com as diretrizes de sua marca ou estilos específicos, como uma campanha anterior. Para atender a esses casos de uso e gerar imagens totalmente personalizadas, você pode ajustar o Amazon Titan Image Generator com seus próprios dados usando modelos personalizados para Amazon Bedrock.
Desde a geração de imagens até a edição delas, os modelos de texto para imagem têm amplas aplicações em todos os setores. Eles podem aumentar a criatividade dos funcionários e proporcionar a capacidade de imaginar novas possibilidades simplesmente com descrições textuais. Por exemplo, ele pode auxiliar o projeto e o planejamento de arquitetos e permitir uma inovação mais rápida, fornecendo a capacidade de visualizar vários projetos sem o processo manual de criá-los. Da mesma forma, pode ajudar no design em vários setores, como manufatura, design de moda no varejo e design de jogos, simplificando a geração de gráficos e ilustrações. Os modelos de texto para imagem também melhoram a experiência do cliente, permitindo publicidade personalizada, bem como chatbots visuais interativos e imersivos em casos de uso de mídia e entretenimento.
Nesta postagem, orientamos você no processo de ajuste fino do modelo Amazon Titan Image Generator para aprender duas novas categorias: Ron, o cachorro, e Smila, a gata, nossos animais de estimação favoritos. Discutimos como preparar seus dados para a tarefa de ajuste fino do modelo e como criar um trabalho de personalização de modelo no Amazon Bedrock. Por fim, mostramos como testar e implantar seu modelo ajustado com Taxa de transferência provisionada.
 |
 |
| Ron, o cachorro | Smila a gata |
Avaliando os recursos do modelo antes de ajustar um trabalho
Os modelos básicos são treinados em grandes quantidades de dados, portanto, é possível que seu modelo funcione bem imediatamente. É por isso que é uma boa prática verificar se você realmente precisa ajustar seu modelo para seu caso de uso ou se a engenharia imediata é suficiente. Vamos tentar gerar algumas imagens do cachorro Ron e do gato Smila com o modelo básico do Amazon Titan Image Generator, conforme mostrado nas capturas de tela a seguir.
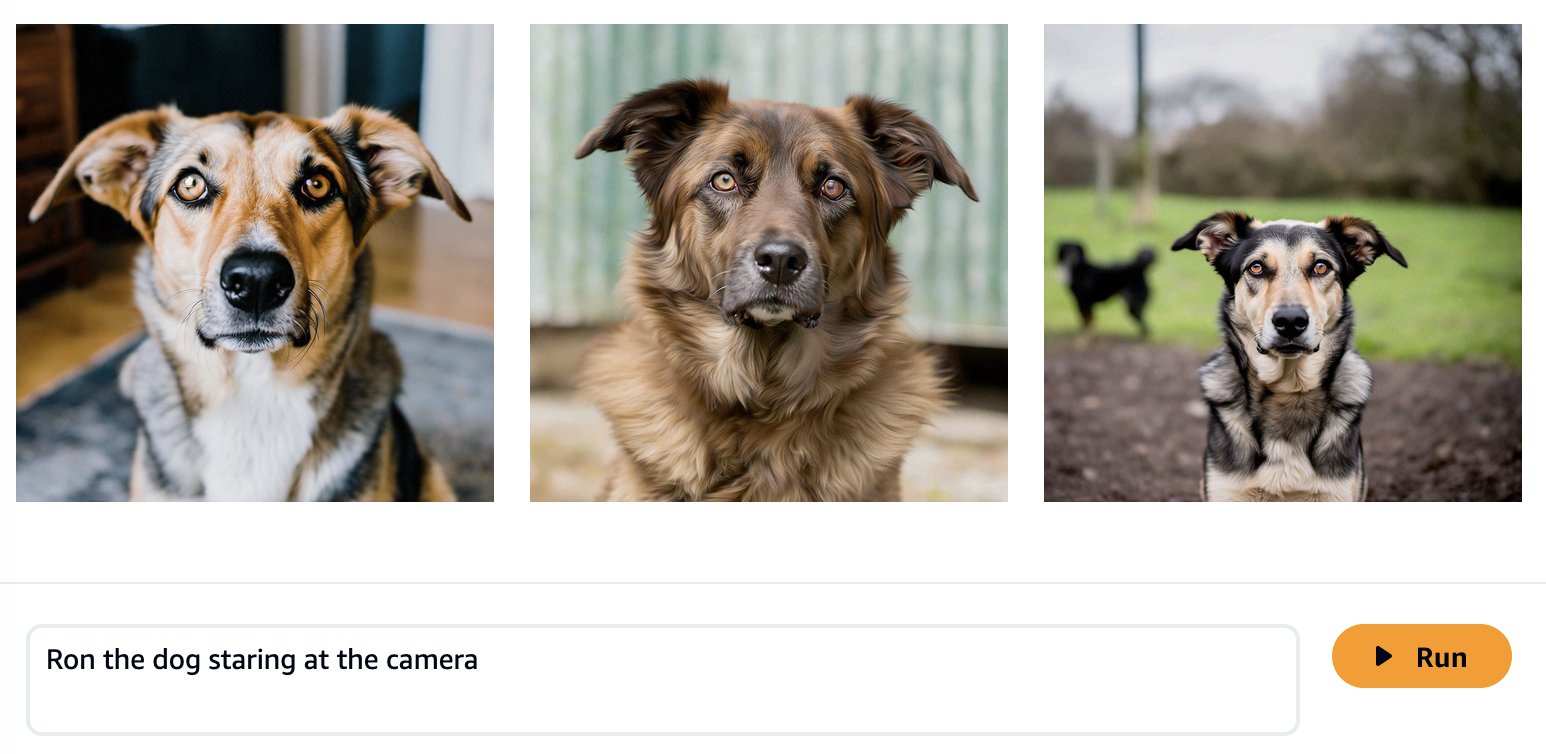

Como esperado, o modelo pronto para uso ainda não conhece Ron e Smila, e os resultados gerados mostram cães e gatos diferentes. Com alguma engenharia imediata, podemos fornecer mais detalhes para nos aproximarmos da aparência de nossos animais de estimação favoritos.


Embora as imagens geradas sejam mais parecidas com Ron e Smila, vemos que o modelo não consegue reproduzir a semelhança completa entre eles. Vamos agora começar um trabalho de ajuste fino com as fotos de Ron e Smila para obter resultados consistentes e personalizados.
Ajustando o Amazon Titan Image Generator
O Amazon Bedrock oferece uma experiência sem servidor para ajustar seu modelo Amazon Titan Image Generator. Você só precisa preparar seus dados e selecionar seus hiperparâmetros, e a AWS cuidará do trabalho pesado para você.
Quando você usa o modelo Amazon Titan Image Generator para fazer o ajuste fino, uma cópia desse modelo é criada na conta de desenvolvimento de modelo da AWS, de propriedade e gerenciada pela AWS, e um trabalho de personalização de modelo é criado. Este trabalho então acessa os dados de ajuste fino de um VPC e o modelo Amazon Titan tem seus pesos atualizados. O novo modelo é então salvo em um Serviço de armazenamento simples da Amazon (Amazon S3) localizado na mesma conta de desenvolvimento de modelo que o modelo pré-treinado. Agora ele pode ser usado para inferência apenas pela sua conta e não é compartilhado com nenhuma outra conta da AWS. Ao executar a inferência, você acessa esse modelo por meio de um computação de capacidade provisionada ou diretamente, usando inferência em lote para Amazon Bedrock. Independentemente da modalidade de inferência escolhida, seus dados permanecem em sua conta e não são copiados para nenhuma conta de propriedade da AWS ou usados para melhorar o modelo Amazon Titan Image Generator.
O diagrama a seguir ilustra esse fluxo de trabalho.
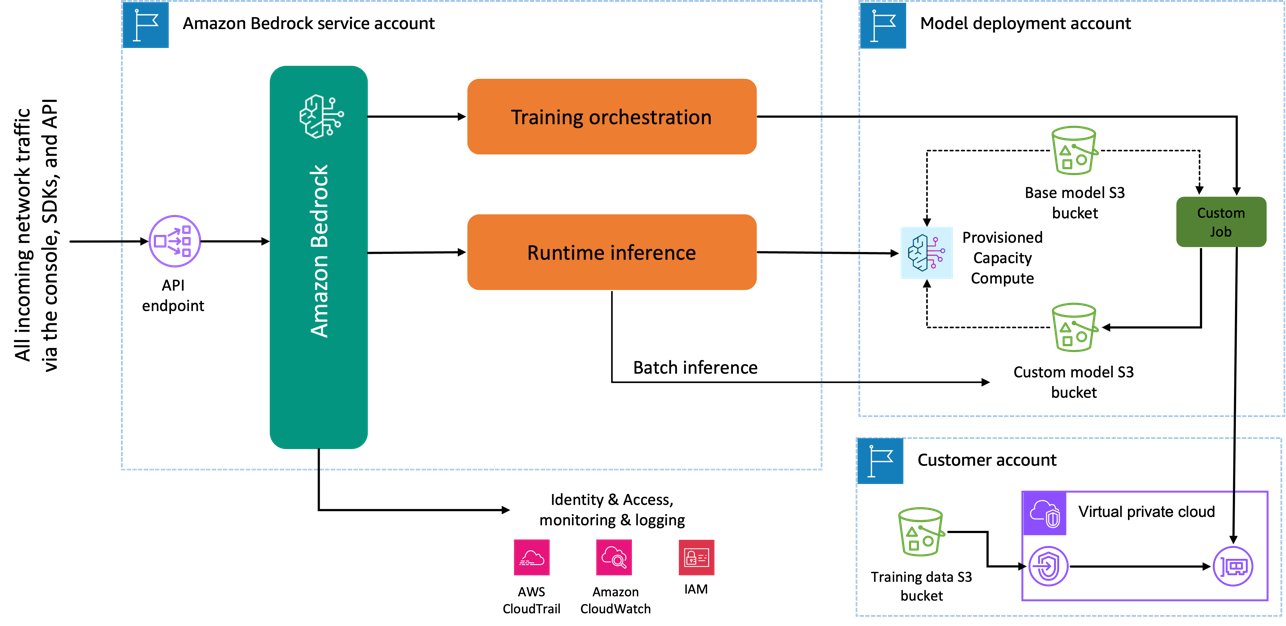
Privacidade de dados e segurança de rede
Seus dados usados para ajuste fino, incluindo prompts, bem como os modelos personalizados, permanecem privados em sua conta da AWS. Eles não são compartilhados nem usados para treinamento de modelos ou melhorias de serviço e não são compartilhados com fornecedores de modelos terceirizados. Todos os dados usados para ajuste fino são criptografados em trânsito e em repouso. Os dados permanecem na mesma região onde a chamada de API é processada. Você também pode usar AWS PrivateLink para criar uma conexão privada entre a conta da AWS onde seus dados residem e a VPC.
Preparação de dados
Antes de criar um trabalho de personalização de modelo, você precisa prepare seu conjunto de dados de treinamento. O formato do seu conjunto de dados de treinamento depende do tipo de trabalho de personalização que você está criando (ajuste fino ou pré-treinamento contínuo) e da modalidade dos seus dados (texto para texto, texto para imagem ou imagem para incorporação). Para o modelo Amazon Titan Image Generator, você precisa fornecer as imagens que deseja usar para o ajuste fino e uma legenda para cada imagem. O Amazon Bedrock espera que suas imagens sejam armazenadas no Amazon S3 e que os pares de imagens e legendas sejam fornecidos em formato JSONL com várias linhas JSON.
Cada linha JSON é um exemplo que contém uma referência de imagem, o URI S3 para uma imagem e uma legenda que inclui um prompt textual para a imagem. Suas imagens devem estar no formato JPEG ou PNG. O código a seguir mostra um exemplo do formato:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Como “Ron” e “Smila” são nomes que também poderiam ser usados em outros contextos, como o nome de uma pessoa, adicionamos os identificadores “Ron, o cachorro” e “Smila, a gata” ao criar o prompt para ajustar nosso modelo . Embora não seja um requisito para o fluxo de trabalho de ajuste fino, essas informações adicionais fornecem mais clareza contextual para o modelo quando ele está sendo customizado para as novas classes e evitarão a confusão de '“Ron the dog” com uma pessoa chamada Ron e “ Smila the cat” com a cidade Smila na Ucrânia. Usando essa lógica, as imagens a seguir mostram uma amostra do nosso conjunto de dados de treinamento.
 |
 |
 |
| Ron, o cachorro, deitado em uma cama branca | Ron, o cachorro, sentado no chão de cerâmica | Ron, o cachorro, deitado no banco do carro |
 |
 |
 |
| Smila, a gata deitada em um sofá | Smila, a gata olhando para a câmera, deitada em um sofá | Smila, a gata deitada em uma caixa de transporte para animais de estimação |
Ao transformar nossos dados para o formato esperado pelo trabalho de customização, obtemos a seguinte estrutura de exemplo:
{"image-ref": "/ron_01.jpg", "caption": "Ron, o cachorro deitado em uma cama branca"} {"image-ref": "/ron_02.jpg", "caption": "Ron, o cachorro sentado no chão de cerâmica"} {"image-ref": "/ron_03.jpg", "caption": "Ron, o cachorro deitado na cadeirinha do carro"} {"image-ref": "/smila_01.jpg", "caption": "Smila, a gata deitada no sofá"} {"image-ref": "/smila_02.jpg", "caption": "Smila a gata sentada ao lado da janela ao lado de uma estátua de gato"} {"image-ref": "/smila_03.jpg", "caption": "Smila, a gata deitada em uma caixa de transporte para animais de estimação"}
Depois de criarmos nosso arquivo JSONL, precisamos armazená-lo em um bucket S3 para iniciar nosso trabalho de personalização. Os trabalhos de ajuste fino do Amazon Titan Image Generator G1 funcionarão com 5 a 10,000 imagens. Para o exemplo discutido neste post, usamos 60 imagens: 30 do cachorro Ron e 30 da gata Smila. Em geral, fornecer mais variedades do estilo ou classe que você está tentando aprender melhorará a precisão do seu modelo ajustado. No entanto, quanto mais imagens você usar para o ajuste fino, mais tempo será necessário para que o trabalho de ajuste fino seja concluído. O número de imagens utilizadas também influencia o preço do seu trabalho aprimorado. Referir-se Preços da Amazon Bedrock para obter mais informações.
Ajustando o Amazon Titan Image Generator
Agora que temos nossos dados de treinamento prontos, podemos iniciar um novo trabalho de customização. Esse processo pode ser feito por meio do console Amazon Bedrock ou de APIs. Para usar o console Amazon Bedrock, conclua as seguintes etapas:
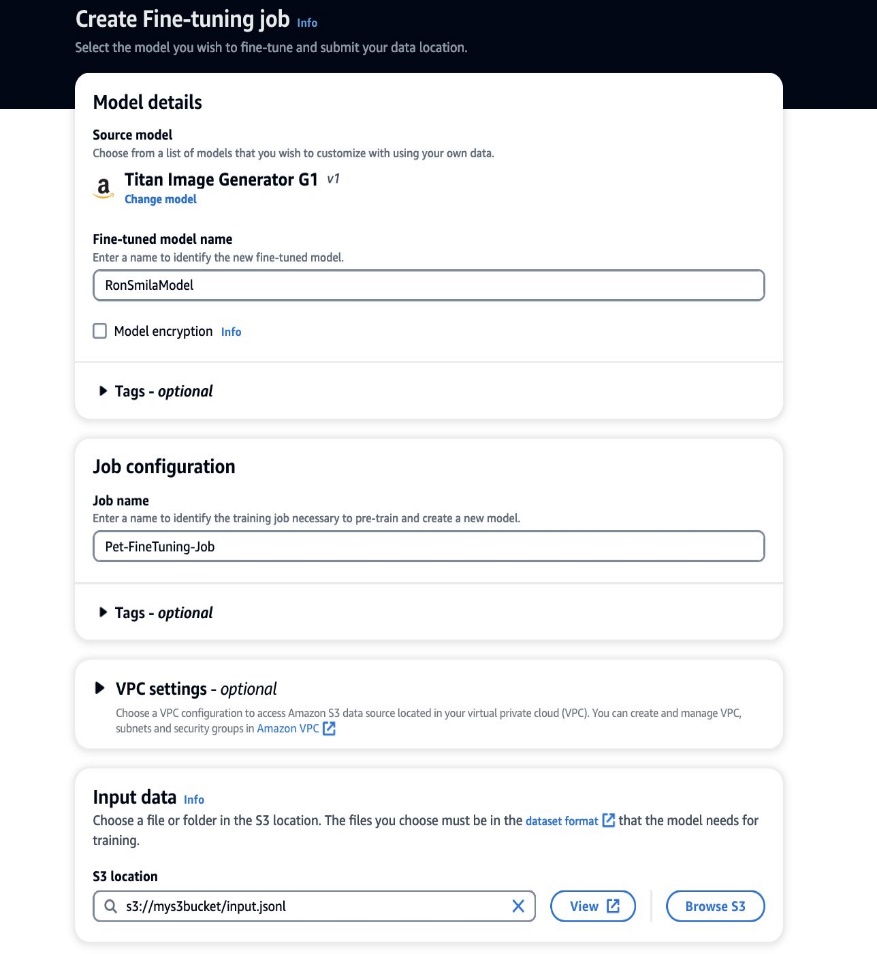
- No console do Amazon Bedrock, escolha Modelos personalizados no painel de navegação.
- No Personalizar modelo menu, escolha Crie um trabalho de ajuste fino.
- Escolha Nome do modelo ajustado, insira um nome para seu novo modelo.
- Escolha Configuração do trabalho, insira um nome para o trabalho de treinamento.
- Escolha Dados de entrada, insira o caminho S3 dos dados de entrada.
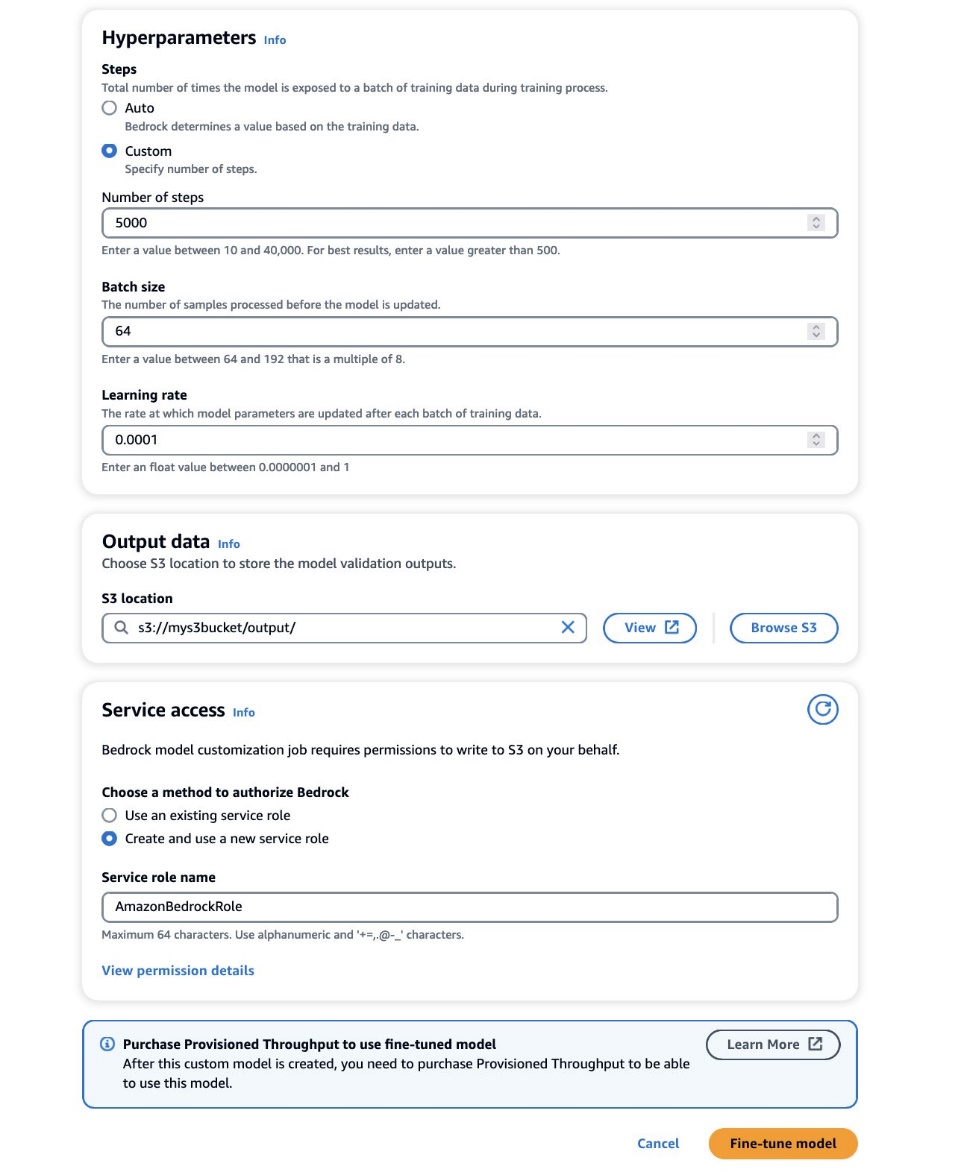
- No Hiperparâmetros seção, forneça valores para o seguinte:
- Número de passos – O número de vezes que o modelo é exposto a cada lote.
- Tamanho do batch – O número de amostras processadas antes da atualização dos parâmetros do modelo.
- Taxa de Aprendizagem – A taxa na qual os parâmetros do modelo são atualizados após cada lote. A escolha destes parâmetros depende de um determinado conjunto de dados. Como orientação geral, recomendamos que você comece fixando o tamanho do lote em 8, a taxa de aprendizado em 1e-5 e defina o número de etapas de acordo com o número de imagens utilizadas, conforme detalhado na tabela a seguir.
| Número de imagens fornecidas | 8 | 32 | 64 | 1,000 | 10,000 |
| Número de etapas recomendadas | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Se os resultados do seu trabalho de ajuste fino não forem satisfatórios, considere aumentar o número de etapas se você não observar nenhum sinal do estilo nas imagens geradas, e diminuir o número de etapas se você observar o estilo nas imagens geradas, mas com artefatos ou desfoque. Se o modelo ajustado não conseguir aprender o estilo exclusivo do seu conjunto de dados mesmo após 40,000 etapas, considere aumentar o tamanho do lote ou a taxa de aprendizagem.
- No Dados de saída seção, insira o caminho de saída do S3 onde as saídas de validação, incluindo a perda de validação registrada periodicamente e as métricas de precisão, são armazenadas.
- No Acesso de serviço seção, gere um novo Gerenciamento de acesso e identidade da AWS (IAM) ou escolha uma função IAM existente com as permissões necessárias para acessar seus buckets S3.
Essa autorização permite que o Amazon Bedrock recupere conjuntos de dados de entrada e validação do bucket designado e armazene saídas de validação perfeitamente no bucket S3.
- Escolha Modelo de ajuste fino.
Com as configurações corretas definidas, o Amazon Bedrock treinará seu modelo personalizado.
Implante o Amazon Titan Image Generator ajustado com taxa de transferência provisionada
Depois de criar o modelo personalizado, o Provisioned Throughput permite alocar uma taxa fixa e predeterminada de capacidade de processamento ao modelo personalizado. Essa alocação fornece um nível consistente de desempenho e capacidade para lidar com cargas de trabalho, o que resulta em melhor desempenho em cargas de trabalho de produção. A segunda vantagem do Provisioned Throughput é o controle de custos, porque o preço padrão baseado em token com modo de inferência sob demanda pode ser difícil de prever em grandes escalas.
Quando o ajuste fino do seu modelo for concluído, este modelo aparecerá no Modelos personalizados' página no console do Amazon Bedrock.
Para adquirir o rendimento provisionado, selecione o modelo personalizado que você acabou de ajustar e escolha Taxa de transferência provisionada de compra.
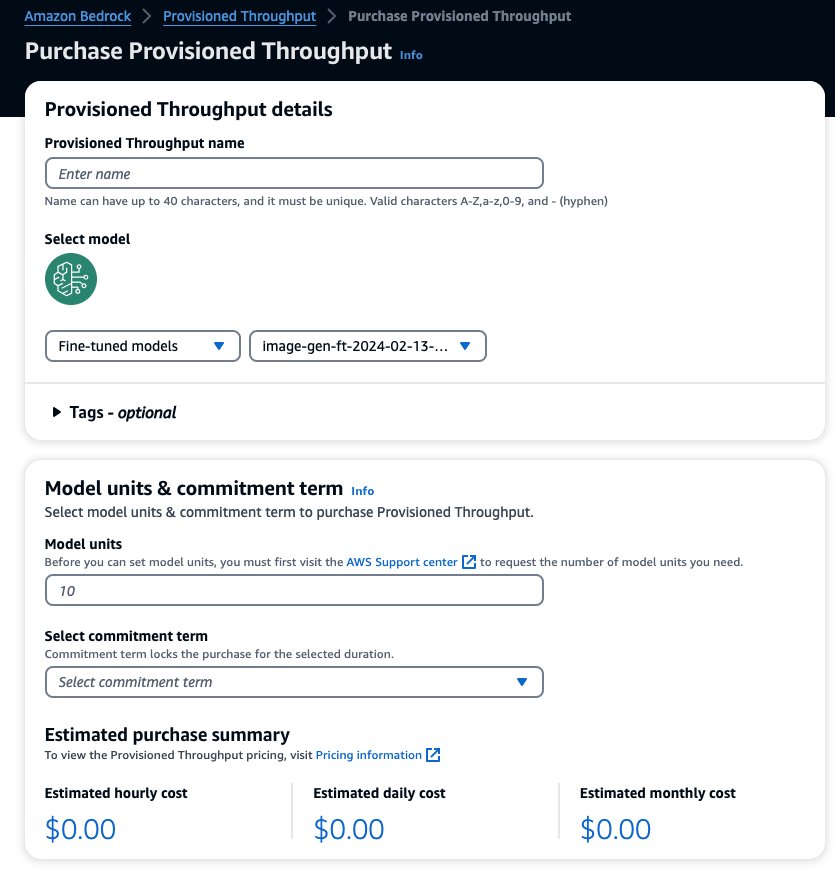
Isso preenche previamente o modelo selecionado para o qual você deseja adquirir o rendimento provisionado. Para testar seu modelo ajustado antes da implantação, defina as unidades do modelo com o valor 1 e defina o termo de compromisso como Sem compromisso. Isso permite que você comece a testar rapidamente seus modelos com prompts personalizados e verifique se o treinamento é adequado. Além disso, quando novos modelos ajustados e novas versões estiverem disponíveis, você poderá atualizar o rendimento provisionado, desde que o atualize com outras versões do mesmo modelo.
Resultados de ajuste fino
Para nossa tarefa de personalizar o modelo do cachorro Ron e do gato Smila, os experimentos mostraram que os melhores hiperparâmetros eram 5,000 passos com um tamanho de lote de 8 e uma taxa de aprendizado de 1e-5.
A seguir estão alguns exemplos de imagens geradas pelo modelo customizado.
 |
 |
 |
| Ron, o cachorro, vestindo uma capa de super-herói | Ron, o cachorro na lua | Ron, o cachorro, em uma piscina com óculos de sol |
 |
 |
 |
| Smila, a gata na neve | Smila, a gata em preto e branco, olhando para a câmera | Smila, a gata com um chapéu de Natal |
Conclusão
Nesta postagem, discutimos quando usar o ajuste fino em vez de projetar seus prompts para geração de imagens de melhor qualidade. Mostramos como ajustar o modelo Amazon Titan Image Generator e implantar o modelo personalizado no Amazon Bedrock. Também fornecemos diretrizes gerais sobre como preparar seus dados para ajuste fino e definir hiperparâmetros ideais para uma personalização de modelo mais precisa.
Como próximo passo, você pode adaptar o seguinte exemplo ao seu caso de uso para gerar imagens hiperpersonalizadas usando o Amazon Titan Image Generator.
Sobre os autores
 Tanque Maira Ladeira é cientista sênior de dados de IA generativa na AWS. Com experiência em aprendizado de máquina, ela tem mais de 10 anos de experiência arquitetando e construindo aplicações de IA com clientes de todos os setores. Como líder técnica, ela ajuda os clientes a acelerar a obtenção de valor comercial por meio de soluções generativas de IA no Amazon Bedrock. Nas horas vagas, Maira gosta de viajar, brincar com sua gata Smila e passar o tempo com a família em algum lugar quentinho.
Tanque Maira Ladeira é cientista sênior de dados de IA generativa na AWS. Com experiência em aprendizado de máquina, ela tem mais de 10 anos de experiência arquitetando e construindo aplicações de IA com clientes de todos os setores. Como líder técnica, ela ajuda os clientes a acelerar a obtenção de valor comercial por meio de soluções generativas de IA no Amazon Bedrock. Nas horas vagas, Maira gosta de viajar, brincar com sua gata Smila e passar o tempo com a família em algum lugar quentinho.
 Daniel Mitchell é arquiteto de soluções especialista em IA/ML na Amazon Web Services. Ele está focado em casos de uso de visão computacional e em ajudar clientes em toda a EMEA a acelerar sua jornada de ML.
Daniel Mitchell é arquiteto de soluções especialista em IA/ML na Amazon Web Services. Ele está focado em casos de uso de visão computacional e em ajudar clientes em toda a EMEA a acelerar sua jornada de ML.
 Bharathi Srinivasan é cientista de dados na AWS Professional Services, onde adora criar coisas interessantes no Amazon Bedrock. Ela é apaixonada por gerar valor comercial a partir de aplicativos de aprendizado de máquina, com foco em IA responsável. Além de criar novas experiências de IA para os clientes, Bharathi adora escrever ficção científica e desafiar-se com esportes de resistência.
Bharathi Srinivasan é cientista de dados na AWS Professional Services, onde adora criar coisas interessantes no Amazon Bedrock. Ela é apaixonada por gerar valor comercial a partir de aplicativos de aprendizado de máquina, com foco em IA responsável. Além de criar novas experiências de IA para os clientes, Bharathi adora escrever ficção científica e desafiar-se com esportes de resistência.
 Achin Jain é Cientista Aplicado da equipe Amazon Artificial General Intelligence (AGI). Ele tem experiência em modelos de texto para imagem e está focado na construção do Amazon Titan Image Generator.
Achin Jain é Cientista Aplicado da equipe Amazon Artificial General Intelligence (AGI). Ele tem experiência em modelos de texto para imagem e está focado na construção do Amazon Titan Image Generator.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

