Como centros de atendimento ao paciente e administração médica, os hospitais muitas vezes gerenciam grandes quantidades de papelada e documentação. A dependência tradicional da entrada manual de dados consome um tempo valioso e introduz o risco de erros que podem ter consequências críticas.
O software de reconhecimento óptico de caracteres (OCR) é uma maravilha tecnológica que está remodelando a forma como os hospitais lidam com os processos de documentação. O software OCR surgiu como um divisor de águas, oferecendo soluções para alguns dos desafios mais urgentes que as instituições de saúde enfrentam.
Quais são esses desafios?
- Muita papelada: Os hospitais são inundados diariamente com papelada, desde registros de pacientes e receitas médicas até documentos de cobrança e formulários de seguros. Este dilúvio de papel representa um pesadelo logístico e dificulta a recuperação rápida e precisa de informações cruciais.
- Garantindo a precisão dos dados: A precisão é fundamental na área da saúde e erros nas informações dos pacientes ou nos registros médicos podem ter consequências graves. A entrada manual de dados está sujeita a erros humanos, levando a interpretações errôneas, erros de transcrição e comprometendo a segurança do paciente.
- Lidando com questões de conformidade e segurança: O setor de saúde opera sob estruturas regulatórias rígidas, com a Lei de Portabilidade e Responsabilidade de Seguros de Saúde (HIPAA) como pedra angular para proteger a privacidade e a segurança dos dados dos pacientes. A conformidade com a HIPAA não é negociável para as instituições de saúde e qualquer lapso na adesão pode resultar em consequências graves.
Numa área onde o tempo pode ser uma questão de vida ou morte, a necessidade de uma gestão documental simplificada é mais premente do que nunca.
Aqui estão os 10 principais softwares de OCR para hospitais em 2024.
Automatize a entrada manual de dados usando o software de OCR baseado em IA da Nanonet. Capture dados de documentos instantaneamente e automatize fluxos de trabalho de dados. Reduza os tempos de resposta e elimine o esforço manual.
O que é OCR para hospitais?
O software OCR, ou software de reconhecimento óptico de caracteres, converte diferentes tipos de documentos em texto legível por máquina. Nos hospitais, o software OCR é crucial na digitalização e gerenciamento de grandes quantidades de papelada e documentos associados ao atendimento ao paciente, administração e processos de saúde.
Aqui estão os principais recursos e funcionalidades do software OCR para hospitais:
- Digitalização de Documentos
O software OCR permite que os hospitais convertam documentos físicos, como registros de pacientes, prontuários médicos, prescrições e informações de faturamento, em formatos digitais. Este processo de digitalização facilita o armazenamento, a recuperação e o compartilhamento de informações cruciais sobre saúde. - Extração de Texto
Uma das principais funções do OCR é extrair texto de documentos ou imagens digitalizados. No ambiente de saúde, isto é particularmente útil para capturar detalhes importantes de notas manuscritas, documentos impressos ou formulários, contribuindo para uma gestão de dados mais eficiente. - Precisão de dados
O software OCR minimiza erros associados à entrada manual de dados. A automatização da extração de texto de documentos reduz o risco de erros de transcrição, garantindo que as informações do paciente sejam registradas e mantidas com precisão. - Eficiência do fluxo de trabalho
Agilizar os processos administrativos é essencial em um ambiente hospitalar. O software OCR aumenta a eficiência do fluxo de trabalho ao automatizar o manuseio de documentos, permitindo que os profissionais de saúde se concentrem mais no atendimento ao paciente e menos na papelada. - Pesquisa e recuperação
Os documentos digitalizados tornam-se pesquisáveis, permitindo a recuperação rápida e fácil de informações. A equipe de saúde pode localizar com eficiência registros específicos de pacientes ou informações médicas relevantes, contribuindo para uma tomada de decisão mais rápida e um melhor atendimento ao paciente. - Conformidade e Segurança
O software OCR ajuda os hospitais a aderir aos padrões regulatórios, incluindo aqueles descritos nas leis de privacidade de saúde, como a HIPAA. Ele garante o manuseio seguro de informações confidenciais do paciente, com recursos como criptografia, controles de acesso e redação de informações de saúde protegidas (PHI). - Integração com sistemas de registros eletrônicos de saúde (EHR)
Muitas soluções de OCR são projetadas para integração perfeita com sistemas de Registros Eletrônicos de Saúde (EHR). Esta integração facilita a transferência suave de informação digitalizada para a infraestrutura do hospital, promovendo uma abordagem coesa e centralizada à gestão de dados de saúde. - Equipe de facilitação linguística
Os hospitais geralmente lidam com documentos em vários idiomas. O software OCR com suporte linguístico robusto pode processar e extrair com precisão texto de documentos escritos em diferentes idiomas, garantindo a inclusão na documentação de saúde.
O melhor software de OCR para hospitais em 2024
Vejamos alguns dos melhores OCR para hospitais disponíveis.
1. nanonets
Nanonets se destaca como uma excelente solução de software de OCR para hospitais, oferecendo uma abordagem personalizada para enfrentar os desafios únicos enfrentados na documentação de saúde.
Seus algoritmos avançados de aprendizado de máquina são excelentes na extração precisa de texto de diversos documentos médicos, incluindo notas manuscritas e formulários complexos. A excepcional precisão dos dados da Nanonets garante a transcrição precisa dos registros dos pacientes, minimizando o risco de erros e apoiando os profissionais de saúde na prestação de cuidados ideais.
Um dos principais pontos fortes da Nanonets é sua integração perfeita com sistemas de registros eletrônicos de saúde (EHR), agilizando sem esforço a transição dos fluxos de trabalho em papel para os digitais. Os robustos recursos de segurança do software, incluindo criptografia e redação de PII, alinham-se aos rigorosos requisitos de conformidade das regulamentações de saúde, como a HIPAA.
As Nanonets não apenas revolucionam o gerenciamento de documentos hospitalares, aumentando a eficiência e a precisão dos dados, mas também capacitam as instituições de saúde a atender aos padrões regulatórios e priorizar a confidencialidade dos pacientes.
Introdução às Nanonets
Prós:
- UI moderno
- Lida com grandes volumes de documentos
- Preço razoável
- FÁCIL DE USAR
- Extração de dados zero-shot ou zero-training
- Captura cognitiva de dados - resultando em intervenção mínima
- Não requer equipe interna de desenvolvedores
- Algoritmos/modelos podem ser treinados/retreinados
- Excelente documentação e suporte
- Muitas opções de personalização
- Grande variedade de opções de integração
- OCR multilíngue preciso
- Integração bidirecional perfeita com vários softwares de contabilidade
- Ótima API de OCR para desenvolvedores
Contras:
- A IU de captura de tabela pode ser melhor
Comece com os extratores de OCR pré-treinados da Nanonets ou Construa o seu próprio modelos de OCR personalizados. Você também pode agendar uma demonstração para saber mais sobre o nosso OCR casos de uso!

2. ABBYY Flexicaptura
ABBYY FlexiCapture é uma solução OCR que se destaca na captura e digitalização de dados de vários documentos médicos. Com seus sofisticados algoritmos de aprendizado de máquina, o FlexiCapture garante alta precisão na extração de texto, tornando-o ideal para transcrever registros de pacientes, prescrições e outros documentos relacionados à saúde.
ABBYY FlexiCapture for Invoices – Vídeo de demonstração
Prós:
- Reconhece imagens muito bem
- Resultado de cópia impressa fácil de armazenar no sistema
- Integra-se bem com sistemas ERP
- Automatiza a extração de dados de documentos (até certo ponto)
Contras:
- A configuração inicial pode ser difícil e complexa
- Processamento automático de DOCUMENTOS MÉDICOS não configurado
- Sem modelos prontos
- Difícil de personalizar
- Sem recursos disponíveis
- Poderia ter melhor integração com soluções RPA
- Baixa precisão com imagens / documentos de baixa resolução
- As verificações de lote são retidas mesmo que haja um erro apenas em uma seção específica
- Mensagens de erro de item de linha aparecem mesmo para itens que devem ser ignorados
- A API RESTful não está disponível na versão local
3. ABBYY FineReader
O FineReader foi projetado principalmente para usuários individuais e pequenas empresas, oferecendo recursos poderosos de OCR para converter documentos digitalizados, imagens e PDFs em formatos editáveis e pesquisáveis. É uma excelente opção para digitalizar documentos impressos, extrair texto de livros ou converter conteúdo em papel em formatos eletrônicos. Embora o FineReader seja versátil e fácil de usar, pode faltar alguns recursos avançados de automação e captura de dados essenciais para o processamento de documentos complexos e em grande escala, comuns em ambientes de saúde.
O ABBYY FineReader pode ser usado para converter documentos médicos impressos em formatos digitais ou extrair texto de livros médicos.
Processamento de documentos com o ABBYY FineReader Server – Vídeo de demonstração
Prós:
- Editor de OCR amigável com teclado para correções manuais
- Interface excepcionalmente clara
- Exporta para vários formatos
- Recurso único de comparação de documentos
Contras:
- Falta indexação de texto completo para pesquisas rápidas
- Requer uma curva de aprendizado
- O preço pode ser proibitivo
- Incapacidade de visualizar o histórico de alterações do documento
- Não é possível mesclar vários arquivos em um
- Pode exigir algum pós-processamento
- A interface do usuário pode ser esmagadora no início
- Lento para processar arquivos grandes
Precisa de um software de OCR para extração de imagem para texto ou extração de dados PDF? Confira Nanonets em ação!
Omnipage é um poderoso software de OCR de PDF que pode lidar com a automação de tarefas de processamento de documentos médicos de alto volume. O software está equipado com recursos avançados de OCR para extrair texto e dados de documentos digitalizados com precisão. Na área da saúde, esse recurso é crucial para capturar informações relevantes de diversas fontes, como registros médicos e prescrições.
Benefícios:
- Minimiza erros de fluxo de dados posteriores com extração de texto e dados altamente precisos de documentos médicos, como prescrições e relatórios de testes.
- Fornece uma ampla variedade de filtros e ferramentas integrados para melhorar a qualidade de documentos médicos digitalizados ou fotografados antes do OCR.
Limitações:
- A configuração dos fluxos de trabalho de automação de AP ou a integração de API envolve configurações complexas, inadequadas para usuários não técnicos.
- A interface tem uma curva de aprendizado acentuada e poderia ser mais intuitiva, dificultando a adoção hospitalar.
- A IU não é intuitiva e pode não ser adequada para profissionais de saúde ocupados.
5.IBM Datacap
IBM Datacap é um software robusto de captura e processamento de documentos. O Datacap ajuda as organizações de saúde a digitalizar registros de pacientes, prescrições e outros documentos, simplificando a captura, o reconhecimento e a classificação de documentos médicos. Com recursos avançados, como processamento inteligente e aprendizado de máquina alimentados por IA, o Datacap automatiza o manuseio de documentos complexos, aumentando a precisão e reduzindo a carga da entrada manual de dados.
A integração do Datacap com o IBM Cloud Pak for Business Automation fornece uma solução abrangente para gerenciamento de documentos de saúde. Ele suporta entrada multicanal, exportação para vários aplicativos e fluxos de trabalho de captura baseados em regras altamente adaptáveis.
Prós:
- Configura aplicativos complexos na captura de dados
- Mecanismo de digitalização
- FÁCIL DE USAR
Contras:
- Muito pouco suporte online
- IU poderia ser mais intuitiva
- A configuração pode ser complicada
- Devagar
- Criar um fluxo personalizado não é simples
- As confirmações em lote levam tempo
Comece a usar Nanonets para automação. Experimente os vários modelos de OCR ou solicite uma demonstração hoje mesmo. Descobrir como os casos de uso das Nanonets podem ser aplicados ao seu produto.
6. IA de documentos do Google
O Google Document AI é uma ferramenta poderosa de processamento de documentos que utiliza aprendizado de máquina para extrair informações valiosas de documentos não estruturados. A Document AI pode agilizar tarefas administrativas na área da saúde, automatizando a extração de dados cruciais de registros médicos, prescrições e faturas. Seus recursos avançados de processamento de linguagem natural e extração inteligente de dados contribuem para maior precisão e eficiência no manuseio de documentos.
Prós:
- Fácil de configurar
- Integra-se muito bem com outros serviços do Google
- Armazenamento de informação
- Velocidade
Contras:
- Módulos de IA carecem de documentação adequada
- A personalização de módulos e bibliotecas existentes é difícil
- Não é adequado para Python ou outras linguagens de codificação
- Documentação de API desatualizada
- Caro
- Não é adequado para implantações de nuvem híbrida
- Não é adequado para casos de uso que exigem algoritmos de IA personalizados
Texto AWS é um mecanismo de reconhecimento óptico de caracteres (OCR) da Amazon Web Services. Ele pode converter imagens e documentos digitalizados em texto legível por máquina, com aplicações em vários setores, incluindo saúde.
A versatilidade do Tesseract no reconhecimento de texto de vários tipos de documentos e idiomas aumenta a interoperabilidade nos sistemas de saúde. Ao automatizar a conversão de documentos em papel em formatos digitais, o AWS Tesseract contribui para aumentar a eficiência, melhorar a precisão dos dados e melhorar o atendimento geral aos pacientes nas instituições de saúde.
Prós:
- Modelo de faturamento de pagamento por uso
- FÁCIL DE USAR
- Funciona bem para tabelas e formulários
Contras:
- Não pode ser treinado
- Precisão variável
- Não se destina a documentos manuscritos
Quer extrair dados de documentos PDF, converter tabelas PDF em Excel ou automatizar a extração de tabelas? Confira o raspador de PDF Nanonets ou analisador de PDF para extrair dados de PDF ou analisar PDFs em grande escala!
8. Analisador de documentos
Docparser é uma plataforma de análise de documentos e extração de dados que transforma documentos não estruturados, como faturas, formulários e recibos, em dados estruturados. O Docparser pode agilizar o processamento de documentos na área da saúde, extraindo automaticamente informações importantes de registros médicos, formulários de seguros e outros documentos relacionados à saúde. Seus recursos avançados de análise permitem a extração de campos de dados específicos, facilitando a digitalização precisa e eficiente das informações do paciente.
Prós:
- Configuração fácil
- Integração Zapier
Contras:
- Os webhooks falham ocasionalmente
- Requer algum treinamento para aprender as regras de análise
- Modelos insuficientes
- OCR zonal abordagem - não pode lidar com modelos desconhecidos
- IU poderia ser melhor
- Lento para carregar páginas
- A documentação poderia ser melhor
9.Adobe Acrobat DC
Adobe Acrobat é uma família abrangente de software e serviços desenvolvidos pela Adobe Inc. para criar, editar, converter e gerenciar arquivos PDF (Portable Document Format). O reconhecimento óptico de caracteres é uma funcionalidade do Adobe Acrobat que converte documentos ou imagens em papel digitalizados em texto editável e pesquisável.
Com o Adobe Acrobat OCR, os usuários podem reconhecer e extrair texto de documentos digitalizados, possibilitando editar, pesquisar e manipular o conteúdo de arquivos PDF. Este recurso é particularmente útil em cenários onde o documento original só existe em formatos de imagem não editáveis, permitindo maior flexibilidade e acessibilidade ao trabalhar com informações baseadas em texto.
Prós:
- Estabilidade/compatibilidade
- FÁCIL DE USAR
Contras:
- Caro
- Não é um software OCR exclusivo
- Pesado no sistema
- Ocupa muito espaço no disco rígido
- Difícil de integrar com serviços como Sharepoint ou Dropbox
- Requer uma licença Adobe Creative Cloud
10. Klippa
A Klippa usa OCR (reconhecimento óptico de caracteres) avançado e tecnologias de aprendizado de máquina para identificar, classificar e extrair com precisão informações relevantes de documentos não estruturados, reduzindo a entrada manual de dados e o risco de erros.
As aplicações da Klippa na área da saúde podem levar ao aumento da eficiência, maior precisão no gerenciamento de dados e maior conformidade com os padrões regulatórios.
Prós:
- Configuração rápida
- Grande apoio
- Excelente API para desenvolvedores
- Documentação de API clara e concisa
- Conecta-se bem com programas de contabilidade
- Preços competitivos
- Integrações
Contras:
- O reconhecimento de OCR pode ser melhor
- Personalizações de modelos limitadas
- Personalizações de marca branca limitadas
- Ajustes em massa não suportados
- O IVA geralmente não é exibido corretamente
- O aplicativo trava frequentemente
- Não é possível treinar o modelo OCR
- O processo de seleção não é simples, pois há muitas opções
Nanoredes API OCR tem muitos interessantes casos de uso que poderiam otimizar o desempenho do seu negócio, economizar custos,, e impulsionar o crescimento. Descobrir como os casos de uso das Nanonets podem ser aplicados ao seu produto.
Outras menções notáveis incluem Muito-fi, Readiris, Infrator, Rossum & Hípatos. Além disso, confira os principais alternativas para nanonets.
Aqui está uma rápida comparação de todos os softwares OCR listados acima em alguns recursos e parâmetros cruciais do software OCR:
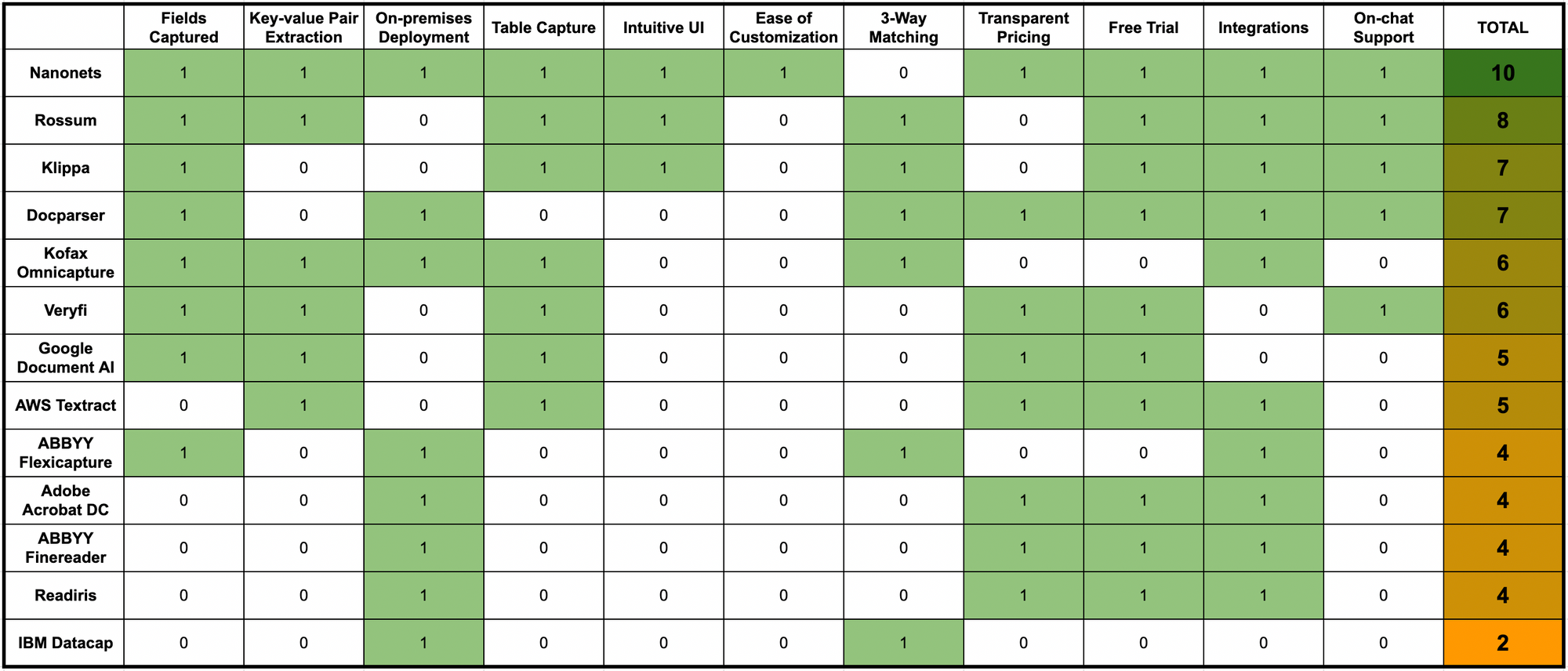
Por que Nanonets é o software de OCR mais abrangente para hospitais?
O software Nanonets OCR é fácil e flexível de configurar, exigindo apenas cerca de um dia. O plataforma de automação inteligente alças dados não estruturados sem muita dificuldade, e a IA também lida restrições de dados comuns com facilidade.
Os benefícios do Nanonets OCR em hospitais vão além de melhor precisão, experiência e escalabilidade.
- Captura e entrada de dados—O OCR Nanonets pode ser usado para capturar com precisão dados de prescrições, faturas, dados médicos legados e muito mais em segundos. Os dados extraídos podem ser conectados diretamente a qualquer software de gestão hospitalar, reduzindo a necessidade de entrada manual de dados e melhorando a precisão.
- Documentação e armazenamento— O Nanonets OCR pode criar facilmente cópias digitais e editáveis de todos os documentos médicos. Esses documentos podem então ser facilmente armazenados e recuperados sempre que necessário.
- Controle de qualidade-O OCR da Nanonets pode fornecer várias etapas de aprovação antes que um documento seja inserido no sistema ou enviado para aprovação. Isso ajuda a identificar erros antecipadamente e reduz os recursos e custos necessários para retrabalho.
- Interface amigável: Nanonets possui uma interface intuitiva e fácil de usar, tornando-o acessível a profissionais de saúde sem amplo treinamento técnico.
Existe algum software de OCR gratuito para hospitais?
Executando em mecanismos de OCR de código aberto (como o Tesseract), essas soluções gratuitas ajudam a converter fotos, PDFs, TIFFs ou documentos digitalizados em formatos de texto digital editáveis. Embora possam não ser capazes de processar registros médicos complexos em grande escala, eles são adequados para extrair texto de documentos simples com formatação direta.
O software OCR gratuito falha regularmente ao processar documentos manuscritos, tabelas com várias colunas, itens de linhas longas ou imagens/digitalizações de baixa qualidade.
Aqui estão algumas ferramentas gratuitas de reconhecimento óptico de caracteres para sua consideração:
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://nanonets.com/blog/ocr-for-hospitals/

