Krones fornece a cervejarias, engarrafadoras de bebidas e produtores de alimentos em todo o mundo máquinas individuais e linhas de produção completas. Todos os dias, milhões de garrafas de vidro, latas e recipientes PET passam pelas linhas da Krones. As linhas de produção são sistemas complexos com muitos erros possíveis que podem paralisar a linha e diminuir o rendimento da produção. A Krones deseja detectar a falha o mais cedo possível (às vezes até antes que ela aconteça) e notificar os operadores da linha de produção para aumentar a confiabilidade e o rendimento. Então, como detectar uma falha? A Krones equipa suas linhas com sensores para coleta de dados, que podem então ser avaliados em relação às regras. A Krones, como fabricante da linha, bem como o operador da linha, tem a possibilidade de criar regras de monitoramento para máquinas. Portanto, os engarrafadores de bebidas e outros operadores podem definir a sua própria margem de erro para a linha. No passado, a Krones usava um sistema baseado em um banco de dados de séries temporais. Os principais desafios eram que este sistema era difícil de depurar e também as consultas representavam o estado atual das máquinas, mas não as transições de estado.
Este post mostra como a Krones construiu uma solução de streaming para monitorar suas linhas, com base em Amazon Kinesis e Serviço gerenciado da Amazon para Apache Flink. Esses serviços totalmente gerenciados reduzem a complexidade da criação de aplicativos de streaming com o Apache Flink. O serviço gerenciado para Apache Flink gerencia os componentes subjacentes do Apache Flink que fornecem estado durável do aplicativo, métricas, logs e muito mais, e o Kinesis permite processar dados de streaming de maneira econômica em qualquer escala. Se você quiser começar com seu próprio aplicativo Apache Flink, confira o Repositório GitHub para amostras usando as APIs Java, Python ou SQL do Flink.
Visão geral da solução
O monitoramento de linha da Krones faz parte do Orientação de chão de fábrica da Krones sistema. Fornece suporte na organização, priorização, gestão e documentação de todas as atividades da empresa. Isso permite notificar um operador se a máquina estiver parada ou se forem necessários materiais, independentemente de onde o operador esteja na linha. Regras comprovadas de monitoramento de condições já estão integradas, mas também podem ser definidas pelo usuário por meio da interface do usuário. Por exemplo, se um determinado ponto de dados monitorado violar um limite, poderá haver uma mensagem de texto ou um acionador para uma ordem de manutenção na linha.
O sistema de monitoramento de condições e avaliação de regras é construído na AWS, usando serviços analíticos da AWS. O diagrama a seguir ilustra a arquitetura.
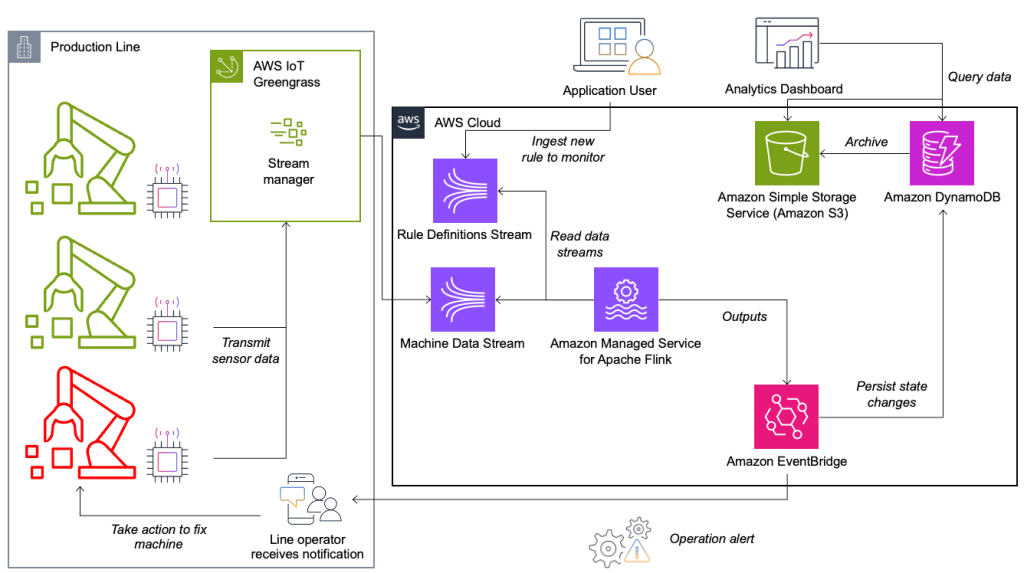
Quase todos os aplicativos de streaming de dados consistem em cinco camadas: fonte de dados, ingestão de fluxo, armazenamento de fluxo, processamento de fluxo e um ou mais destinos. Nas seções a seguir, nos aprofundamos em cada camada e em detalhes como funciona a solução de monitoramento de linha, construída pela Krones.
Fonte de dados
Os dados são coletados por um serviço executado em um dispositivo de ponta que lê diversos protocolos como Siemens S7 ou OPC/UA. Os dados brutos são pré-processados para criar uma estrutura JSON unificada, o que facilita o processamento posterior no mecanismo de regras. Uma amostra de carga convertida em JSON pode ter a seguinte aparência:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Ingestão de fluxo
AWS IoT Greengrass é um tempo de execução de borda e serviço de nuvem da Internet das Coisas (IoT) de código aberto. Isso permite que você atue localmente nos dados e agregue e filtre dados do dispositivo. O AWS IoT Greengrass fornece componentes pré-construídos que podem ser implantados na borda. A solução de linha de produção usa o componente stream manager, que pode processar dados e transferi-los para destinos AWS, como Análise de IoT da AWS, Serviço de armazenamento simples da Amazon (Amazon S3) e Kinesis. O gerenciador de stream armazena em buffer e agrega registros e, em seguida, envia-os para um stream de dados do Kinesis.
Armazenamento de fluxo
A tarefa do armazenamento de fluxo é armazenar mensagens em buffer de maneira tolerante a falhas e disponibilizá-las para consumo para um ou mais aplicativos consumidores. Para conseguir isso na AWS, as tecnologias mais comuns são Kinesis e Amazon Managed Streaming para Apache Kafka (Amazon MSK). Para armazenar os dados dos nossos sensores das linhas de produção, a Krones escolhe o Kinesis. Kinesis é um serviço de streaming de dados sem servidor que funciona em qualquer escala com baixa latência. Os fragmentos em um fluxo de dados do Kinesis são uma sequência de registros de dados identificada exclusivamente, em que um fluxo é composto por um ou mais fragmentos. Cada fragmento tem 2 MB/s de capacidade de leitura e 1 MB/s de capacidade de gravação (com no máximo 1,000 registros/s). Para evitar atingir esses limites, os dados devem ser distribuídos entre os fragmentos da forma mais uniforme possível. Cada registro enviado ao Kinesis possui uma chave de partição, que é usada para agrupar dados em um fragmento. Portanto, você deseja ter um grande número de chaves de partição para distribuir a carga uniformemente. O gerenciador de fluxo em execução no AWS IoT Greengrass oferece suporte a atribuições aleatórias de chaves de partição, o que significa que todos os registros terminam em um fragmento aleatório e a carga é distribuída uniformemente. Uma desvantagem das atribuições aleatórias de chaves de partição é que os registros não são armazenados em ordem no Kinesis. Explicamos como resolver isso na próxima seção, onde falamos sobre marcas d’água.
Marcas d'água
A marca d'água é um mecanismo usado para rastrear e medir o progresso do tempo do evento em um fluxo de dados. A hora do evento é o carimbo de data/hora de quando o evento foi criado na origem. A marca d'água indica o progresso oportuno do aplicativo de processamento de fluxo, portanto, todos os eventos com carimbo de data/hora anterior ou igual são considerados processados. Essas informações são essenciais para que o Flink avance o tempo do evento e acione cálculos relevantes, como avaliações de janela. O atraso permitido entre o horário do evento e a marca d'água pode ser configurado para determinar quanto tempo esperar pelos dados atrasados antes de considerar uma janela concluída e avançar a marca d'água.
A Krones possui sistemas em todo o mundo e precisava lidar com atrasos devido a perdas de conexão ou outras restrições de rede. Eles começaram monitorando as chegadas atrasadas e definindo o tratamento tardio padrão do Flink para o valor máximo que viram nesta métrica. Eles enfrentaram problemas com a sincronização de horário dos dispositivos de ponta, o que os levou a uma forma mais sofisticada de marca d'água. Eles construíram uma marca d'água global para todos os remetentes e usaram o valor mais baixo como marca d'água. Os carimbos de data/hora são armazenados em um HashMap para todos os eventos recebidos. Quando as marcas d'água são emitidas periodicamente, é utilizado o menor valor deste HashMap. Para evitar a paralisação das marcas d’água por falta de dados, eles configuraram um idleTimeOut parâmetro, que ignora carimbos de data/hora anteriores a um determinado limite. Isso aumenta a latência, mas proporciona forte consistência de dados.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Processamento de fluxo
Depois que os dados são coletados dos sensores e ingeridos no Kinesis, eles precisam ser avaliados por um mecanismo de regras. Uma regra neste sistema representa o estado de uma única métrica (como temperatura) ou de uma coleção de métricas. Para interpretar uma métrica, mais de um ponto de dados é usado, o que é um cálculo com estado. Nesta seção, nos aprofundamos no estado chaveado e no estado de transmissão no Apache Flink e como eles são usados para construir o mecanismo de regras Krones.
Controlar fluxo e padrão de estado de transmissão
No Apache Flink, estado refere-se à capacidade do sistema de armazenar e gerenciar informações de forma persistente ao longo do tempo e das operações, permitindo o processamento de dados de streaming com suporte para cálculos com estado.
A padrão de estado de transmissão permite a distribuição de um estado para todas as instâncias paralelas de um operador. Portanto, todos os operadores possuem o mesmo estado e os dados podem ser processados utilizando esse mesmo estado. Esses dados somente leitura podem ser ingeridos usando um fluxo de controle. Um fluxo de controle é um fluxo de dados regular, mas geralmente com uma taxa de dados muito mais baixa. Esse padrão permite atualizar dinamicamente o estado em todos os operadores, permitindo que o usuário altere o estado e o comportamento do aplicativo sem a necessidade de reimplantação. Mais precisamente, a distribuição do estado é feita através da utilização de um fluxo de controle. Ao adicionar um novo registro no fluxo de controle, todos os operadores recebem esta atualização e passam a utilizar o novo estado para o processamento de novas mensagens.
Isso permite que os usuários do aplicativo Krones incorporem novas regras no aplicativo Flink sem reiniciá-lo. Isso evita tempo de inatividade e proporciona uma ótima experiência ao usuário, pois as alterações acontecem em tempo real. Uma regra cobre um cenário para detectar um desvio no processo. Às vezes, os dados da máquina não são tão fáceis de interpretar como podem parecer à primeira vista. Se um sensor de temperatura estiver enviando valores elevados, isso pode indicar um erro, mas também ser o efeito de um procedimento de manutenção contínuo. É importante contextualizar as métricas e filtrar alguns valores. Isto é conseguido por um conceito chamado agrupamento.
Agrupamento de métricas
O agrupamento de dados e métricas permite definir a relevância dos dados recebidos e produzir resultados precisos. Vamos examinar o exemplo na figura a seguir.
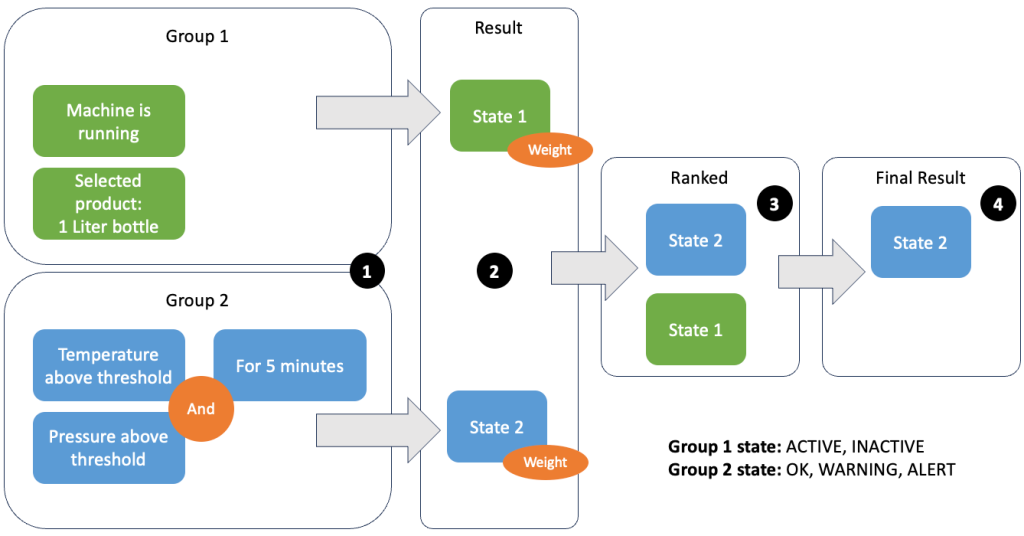
Na Etapa 1, definimos dois grupos de condições. O Grupo 1 coleta o estado da máquina e qual produto está passando pela linha. O Grupo 2 utiliza o valor dos sensores de temperatura e pressão. Um grupo de condições pode ter estados diferentes dependendo dos valores que recebe. Neste exemplo, o grupo 1 recebe dados de que a máquina está funcionando e a garrafa de um litro é selecionada como produto; isso dá a esse grupo o estado ACTIVE. O Grupo 2 possui métricas de temperatura e pressão; ambas as métricas estão acima de seus limites por mais de 5 minutos. Isso faz com que o grupo 2 esteja em uma WARNING estado. Isto significa que o grupo 1 relata que está tudo bem e o grupo 2 não. Na Etapa 2, os pesos são adicionados aos grupos. Isto é necessário em algumas situações, porque os grupos podem reportar informações contraditórias. Neste cenário, o grupo 1 relata ACTIVE e relatórios do grupo 2 WARNING, portanto não está claro para o sistema qual é o estado da linha. Após a soma dos pesos, os estados podem ser classificados, conforme mostrado no passo 3. Por fim, o estado com melhor classificação é escolhido como vencedor, conforme mostrado no Passo 4.
Depois que as regras forem avaliadas e o estado final da máquina for definido, os resultados serão processados posteriormente. A ação tomada depende da configuração da regra; pode ser uma notificação ao operador da linha para reabastecer materiais, fazer alguma manutenção ou apenas uma atualização visual no painel. Esta parte do sistema, que avalia métricas e regras e toma ações com base nos resultados, é chamada de motor de regras.
Dimensionando o mecanismo de regras
Ao permitir que os usuários criem suas próprias regras, o mecanismo de regras pode ter um grande número de regras que precisa avaliar, e algumas regras podem usar os mesmos dados do sensor que outras regras. Flink é um sistema distribuído que se adapta muito bem horizontalmente. Para distribuir um fluxo de dados para diversas tarefas, você pode usar o método keyBy() método. Isso permite particionar um fluxo de dados de maneira lógica e enviar partes dos dados para diferentes gerenciadores de tarefas. Isso geralmente é feito escolhendo uma chave arbitrária para obter uma carga distribuída uniformemente. Neste caso, Krones adicionou um ruleId ao ponto de dados e o usou como uma chave. Caso contrário, os pontos de dados necessários serão processados por outra tarefa. O fluxo de dados codificado pode ser usado em todas as regras como uma variável normal.
Destinos
Quando uma regra muda de estado, as informações são enviadas para um stream do Kinesis e depois via Amazon Event Bridge aos consumidores. Um dos consumidores cria uma notificação do evento que é transmitida para a linha de produção e alerta o pessoal para agir. Para poder analisar as mudanças no estado da regra, outro serviço grava os dados em um Amazon DynamoDB tabela para acesso rápido e um TTL está em vigor para transferir o histórico de longo prazo para o Amazon S3 para relatórios adicionais.
Conclusão
Neste post, mostramos como a Krones construiu um sistema de monitoramento de linha de produção em tempo real na AWS. O serviço gerenciado para Apache Flink permitiu que a equipe da Krones começasse rapidamente, concentrando-se no desenvolvimento de aplicativos em vez de na infraestrutura. Os recursos em tempo real do Flink permitiram que a Krones reduzisse o tempo de inatividade da máquina em 10% e aumentasse a eficiência em até 5%.
Se você deseja construir seus próprios aplicativos de streaming, confira os exemplos disponíveis no site. Repositório GitHub. Se você deseja estender seu aplicativo Flink com conectores personalizados, consulte Facilitando a construção de conectores com Apache Flink: apresentando o coletor assíncrono. O Async Sink está disponível no Apache Flink versão 1.15.1 e posterior.
Sobre os autores
 Floriano Mair é arquiteto de soluções sênior e especialista em streaming de dados na AWS. Ele é um tecnólogo que ajuda clientes na Europa a ter sucesso e inovar, resolvendo desafios de negócios usando serviços da Nuvem AWS. Além de trabalhar como Arquiteto de Soluções, Florian é um alpinista apaixonado e escalou algumas das montanhas mais altas da Europa.
Floriano Mair é arquiteto de soluções sênior e especialista em streaming de dados na AWS. Ele é um tecnólogo que ajuda clientes na Europa a ter sucesso e inovar, resolvendo desafios de negócios usando serviços da Nuvem AWS. Além de trabalhar como Arquiteto de Soluções, Florian é um alpinista apaixonado e escalou algumas das montanhas mais altas da Europa.
 Emil Dietl é líder técnico sênior na Krones, especializado em engenharia de dados, com área-chave em Apache Flink e microsserviços. Seu trabalho frequentemente envolve o desenvolvimento e manutenção de software de missão crítica. Fora da vida profissional, ele valoriza profundamente passar bons momentos com sua família.
Emil Dietl é líder técnico sênior na Krones, especializado em engenharia de dados, com área-chave em Apache Flink e microsserviços. Seu trabalho frequentemente envolve o desenvolvimento e manutenção de software de missão crítica. Fora da vida profissional, ele valoriza profundamente passar bons momentos com sua família.
 Simon Peyer é arquiteto de soluções na AWS baseado na Suíça. Ele é um realizador prático e apaixonado por conectar tecnologia e pessoas usando os serviços da Nuvem AWS. Um foco especial para ele é o streaming de dados e as automações. Além do trabalho, Simon gosta da família, da vida ao ar livre e de fazer caminhadas nas montanhas.
Simon Peyer é arquiteto de soluções na AWS baseado na Suíça. Ele é um realizador prático e apaixonado por conectar tecnologia e pessoas usando os serviços da Nuvem AWS. Um foco especial para ele é o streaming de dados e as automações. Além do trabalho, Simon gosta da família, da vida ao ar livre e de fazer caminhadas nas montanhas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

