Introdução
No coração do ciência de dados mentiras estatísticas, que existem há séculos, mas continuam a ser fundamentalmente essenciais na era digital de hoje. Por que? Como os conceitos básicos de estatística são a espinha dorsal do análise de dados, permitindo-nos entender as grandes quantidades de dados gerados diariamente. É como conversar com dados, onde as estatísticas nos ajudam a fazer as perguntas certas e a compreender as histórias que os dados tentam contar.
Desde a previsão de tendências futuras e a tomada de decisões com base em dados até o teste de hipóteses e a medição do desempenho, as estatísticas são a ferramenta que alimenta os insights por trás das decisões baseadas em dados. É a ponte entre dados brutos e insights acionáveis, tornando-os uma parte indispensável da ciência de dados.
Neste artigo, compilei os 15 principais conceitos fundamentais de estatística que todo iniciante em ciência de dados deve saber!

Índice
1. Amostragem Estatística e Coleta de Dados
Aprenderemos alguns conceitos básicos de estatística, mas entender de onde vêm nossos dados e como os coletamos é essencial antes de mergulhar fundo no oceano de dados. É aqui que entram em jogo populações, amostras e várias técnicas de amostragem.
Imagine que queremos saber a altura média das pessoas em uma cidade. É prático medir todos, por isso pegamos um grupo menor (amostra) que representa a população maior. O truque está em como selecionamos esta amostra. Técnicas como amostragem aleatória, estratificada ou por conglomerados garantem que nossa amostra seja bem representada, minimizando vieses e tornando nossas descobertas mais confiáveis.
Ao compreender as populações e as amostras, podemos estender com confiança os nossos insights da amostra a toda a população, tomando decisões informadas sem a necessidade de pesquisar todos.
2. Tipos de dados e escalas de medição
Os dados vêm em vários sabores, e conhecer o tipo de dados com os quais você está lidando é crucial para escolher as ferramentas e técnicas estatísticas corretas.
Dados Quantitativos e Qualitativos
- Dados quantitativos: Esse tipo de dados tem tudo a ver com números. É mensurável e pode ser usado para cálculos matemáticos. Os dados quantitativos dizem-nos “quanto” ou “quantos”, como o número de utilizadores que visitam um website ou a temperatura numa cidade. É simples e objetivo, fornecendo uma imagem clara através de valores numéricos.
- Dados qualitativos: Por outro lado, os dados qualitativos tratam de características e descrições. É sobre “que tipo” ou “qual categoria”. Pense nisso como os dados que descrevem qualidades ou atributos, como a cor de um carro ou o gênero de um livro. Esses dados são subjetivos, baseados em observações e não em medições.
Quatro escalas de medição
- Escala nominal: Esta é a forma mais simples de medição usada para categorizar dados sem uma ordem específica. Os exemplos incluem tipos de culinária, grupos sanguíneos ou nacionalidade. Trata-se de rotulagem sem qualquer valor quantitativo.
- Escala ordinal: Os dados podem ser ordenados ou classificados aqui, mas os intervalos entre os valores não são definidos. Pense em uma pesquisa de satisfação com opções como satisfeito, neutro e insatisfeito. Diz-nos a ordem, mas não a distância entre as classificações.
- Escala de intervalo: O intervalo dimensiona os dados do pedido e quantifica a diferença entre as entradas. No entanto, não existe um ponto zero real. Um bom exemplo é a temperatura em Celsius; a diferença entre 10°C e 20°C é a mesma que entre 20°C e 30°C, mas 0°C não significa ausência de temperatura.
- Escala de razão: A escala mais informativa possui todas as propriedades de uma escala de intervalo mais um ponto zero significativo, permitindo uma comparação precisa de magnitudes. Os exemplos incluem peso, altura e renda. Aqui, podemos dizer que uma coisa é o dobro de outra.
3. Estatísticas descritivas
Imagine estatísticas descritivas como seu primeiro encontro com seus dados. Trata-se de conhecer o básico, os traços gerais que descrevem o que está à sua frente. A estatística descritiva possui dois tipos principais: medidas de tendência central e medidas de variabilidade.
Medidas de tendência central: Eles são como o centro de gravidade dos dados. Eles nos fornecem um valor único, típico ou representativo de nosso conjunto de dados.
Significar: A média é calculada somando todos os valores e dividindo pelo número de valores. É como a avaliação geral de um restaurante com base em todas as avaliações. A fórmula matemática para a média é fornecida abaixo:

Mediana: O valor médio quando os dados são ordenados do menor para o maior. Se o número de observações for par, é a média dos dois números do meio. É usado para encontrar o ponto médio de uma ponte.
Se n for par, a mediana será a média dos dois números centrais.
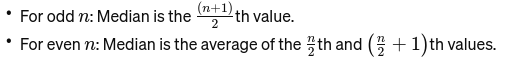
Modo: É o valor que ocorre com mais frequência em um conjunto de dados. Pense nisso como o prato mais popular em um restaurante.
Medidas de Variabilidade: Enquanto as medidas de tendência central nos levam ao centro, as medidas de variabilidade nos informam sobre a propagação ou dispersão.
Faixa de Medição: A diferença entre os valores mais altos e mais baixos. Dá uma ideia básica da propagação.
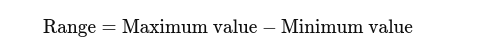
Variação: Mede a que distância cada número do conjunto está da média e, portanto, de todos os outros números do conjunto. Para uma amostra, é calculado como:
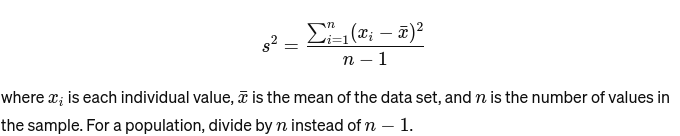
Desvio padrão: A raiz quadrada da variância fornece uma medida da distância média da média. É como avaliar a consistência do tamanho do bolo de um padeiro. É representado como:
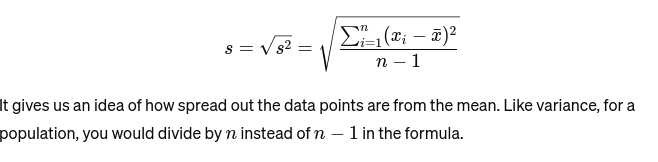
Antes de passarmos para o próximo conceito básico de estatística, aqui está um Guia para iniciantes em análise estatística para você!
4. Visualização de dados
Visualização de dados é a arte e a ciência de contar histórias com dados. Transforma resultados complexos de nossa análise em algo tangível e compreensível. É crucial para a análise exploratória de dados, onde o objetivo é descobrir padrões, correlações e insights dos dados sem ainda tirar conclusões formais.
- Tabelas e gráficos: Começando com o básico, gráficos de barras, gráficos de linhas e gráficos de pizza fornecem insights básicos sobre os dados. Eles são o ABC da visualização de dados, essenciais para qualquer contador de histórias de dados.
Temos um exemplo de gráfico de barras (esquerda) e gráfico de linhas (direita) abaixo.
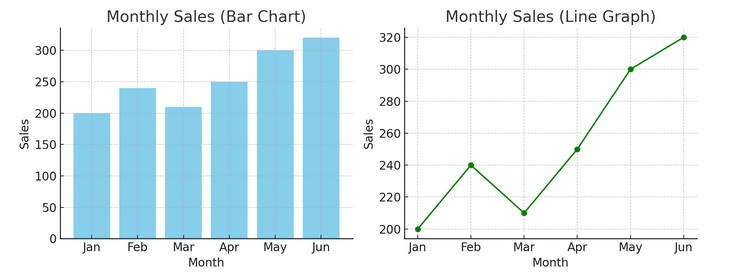
- Visualizações avançadas: À medida que nos aprofundamos, mapas de calor, gráficos de dispersão e histogramas permitem análises mais detalhadas. Essas ferramentas ajudam a identificar tendências, distribuições e valores discrepantes.
Abaixo está um exemplo de gráfico de dispersão e histograma

As visualizações unem dados brutos e cognição humana, permitindo-nos interpretar e dar sentido a conjuntos de dados complexos rapidamente.
5. Noções básicas de probabilidade
Probabilidade é a gramática da linguagem das estatísticas. É sobre a chance ou probabilidade de eventos acontecerem. Compreender conceitos de probabilidade é essencial para interpretar resultados estatísticos e fazer previsões.
- Eventos Independentes e Dependentes:
- Eventos Independentes: O resultado de um evento não afeta o resultado de outro. Assim como jogar uma moeda, obter cara em um lançamento não altera as chances do próximo lançamento.
- Eventos Dependentes: O resultado de um evento afeta o resultado de outro. Por exemplo, se você comprar uma carta de um baralho e não substituí-la, suas chances de comprar outra carta específica mudam.
A probabilidade fornece a base para fazer inferências sobre os dados e é fundamental para a compreensão da significância estatística e dos testes de hipóteses.
6. Distribuições de probabilidade comuns
Distribuições de probabilidade são como espécies diferentes no ecossistema estatístico, cada uma adaptada ao seu nicho de aplicações.
- Distribuição normal: Muitas vezes chamada de curva em sino devido ao seu formato, essa distribuição é caracterizada por sua média e desvio padrão. É uma suposição comum em muitos testes estatísticos porque muitas variáveis são naturalmente distribuídas desta forma no mundo real.
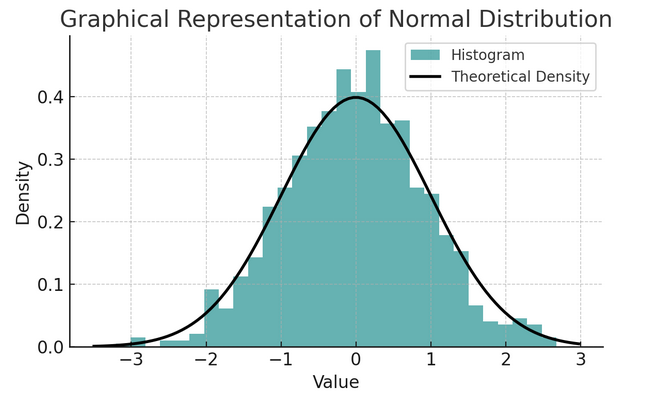
Um conjunto de regras conhecido como regra empírica ou regra 68-95-99.7 resume as características de uma distribuição normal, que descreve como os dados são distribuídos em torno da média.
Regra 68-95-99.7 (Regra Empírica)
Esta regra se aplica a uma distribuição perfeitamente normal e descreve o seguinte:
- 68% dos dados está dentro de um desvio padrão (σ) da média (μ).
- 95% dos dados está dentro de dois desvios padrão da média.
- Aproximadamente 99.7% dos dados está dentro de três desvios padrão da média.
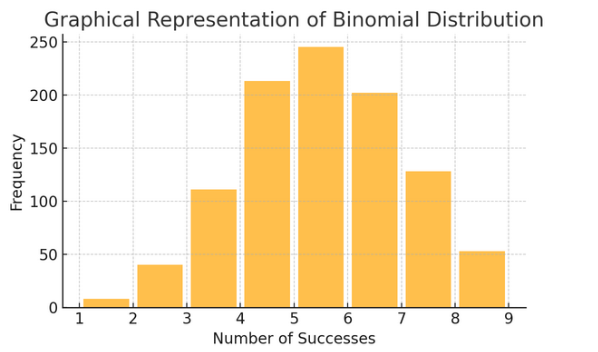
Distribuição binomial: Esta distribuição aplica-se a situações com dois resultados (como sucesso ou fracasso) repetidos várias vezes. Ajuda a modelar eventos como jogar uma moeda ou fazer um teste de verdadeiro/falso.
Distribuição de veneno conta o número de vezes que algo acontece em um intervalo ou espaço específico. É ideal para situações onde os eventos acontecem de forma independente e constante, como os e-mails diários que você recebe.
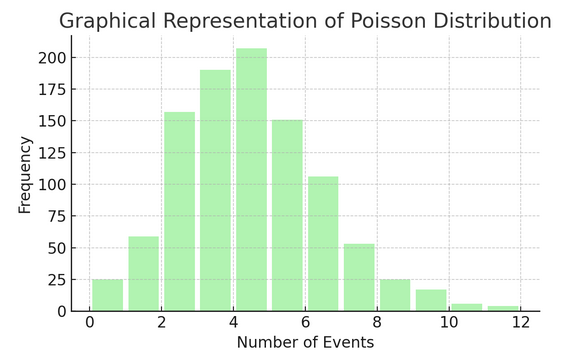
Cada distribuição tem seu próprio conjunto de fórmulas e características, e a escolha da distribuição certa depende da natureza dos seus dados e do que você está tentando descobrir. A compreensão dessas distribuições permite que estatísticos e cientistas de dados modelem fenômenos do mundo real e prevejam eventos futuros com precisão.
7. Testando hipóteses
Pense testando hipóteses como trabalho de detetive em estatística. É um método para testar se uma teoria específica sobre nossos dados pode ser verdadeira. Este processo começa com duas hipóteses opostas:
- Hipótese Nula (H0): Esta é a suposição padrão, sugerindo que há efeito ou diferença. Está dizendo: “Não é novidade aqui”.
- Al “hipótese alternativa (H1 ou Ha): Isto desafia o status quo, propondo um efeito ou uma diferença. Ele afirma: “Algo está acontecendo interessante”.
Exemplo: Testar se um novo programa de dieta leva à perda de peso em comparação com não seguir nenhuma dieta.
- Hipótese Nula (H0): O novo programa de dieta não leva à perda de peso (não há diferença na perda de peso entre aqueles que seguem o novo programa de dieta e aqueles que não o fazem).
- Hipótese Alternativa (H1): O novo programa de dieta leva à perda de peso (diferença na perda de peso entre quem o segue e quem não o segue).
O teste de hipóteses envolve escolher entre esses dois com base nas evidências (nossos dados).
Níveis de erro e significância tipo I e II:
- Erro tipo I: Isso acontece quando rejeitamos incorretamente a hipótese nula. Ele condena uma pessoa inocente.
- Erro Tipo II: Isso ocorre quando não conseguimos rejeitar uma hipótese nula falsa. Isso permite que uma pessoa culpada fique em liberdade.
- Nível de significância (α): Este é o limite para decidir quanta evidência é suficiente para rejeitar a hipótese nula. Geralmente é definido em 5% (0.05), indicando um risco de 5% de erro Tipo I.
8. Intervalos de confiança
Intervalos de confiança forneça um intervalo de valores dentro dos quais esperamos que o parâmetro populacional válido (como uma média ou proporção) caia com um certo nível de confiança (geralmente 95%). É como prever o resultado final de uma equipe esportiva com margem de erro; estamos dizendo: “Estamos 95% confiantes de que a pontuação verdadeira estará dentro dessa faixa”.
Construir e interpretar intervalos de confiança nos ajuda a compreender a precisão de nossas estimativas. Quanto maior o intervalo, nossa estimativa é menos precisa e vice-versa.
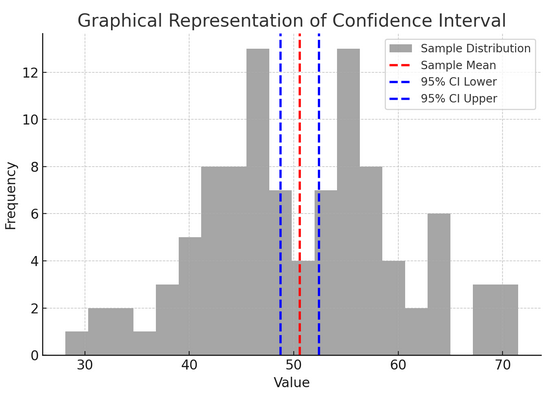
A figura acima ilustra o conceito de intervalo de confiança (IC) em estatísticas, usando uma distribuição amostral e seu intervalo de confiança de 95% em torno da média amostral.
Aqui está uma análise dos componentes críticos na figura:
- Distribuição da amostra (histograma cinza): Isso representa a distribuição de 100 pontos de dados gerados aleatoriamente a partir de uma distribuição normal com média de 50 e desvio padrão de 10. O histograma representa visualmente como os pontos de dados estão espalhados em torno da média.
- Média amostral (linha tracejada vermelha): Esta linha indica o valor médio (médio) dos dados de amostra. Serve como estimativa pontual em torno da qual construímos o intervalo de confiança. Neste caso, representa a média de todos os valores amostrais.
- Intervalo de confiança de 95% (linhas tracejadas azuis): Estas duas linhas marcam os limites inferior e superior do intervalo de confiança de 95% em torno da média amostral. O intervalo é calculado usando o erro padrão da média (EPM) e um escore Z correspondente ao nível de confiança desejado (1.96 para 95% de confiança). O intervalo de confiança sugere que temos 95% de confiança de que a média da população se encontra dentro deste intervalo.
9. Correlação e causalidade
Correlação e causalidade muitas vezes se confundem, mas são diferentes:
- Correlação: Indica um relacionamento ou associação entre duas variáveis. Quando um muda, o outro tende a mudar também. A correlação é medida por um coeficiente de correlação que varia de -1 a 1. Um valor mais próximo de 1 ou -1 indica um relacionamento forte, enquanto 0 sugere ausência de vínculos.
- Causação: Isso implica que mudanças em uma variável causam diretamente mudanças em outra. É uma afirmação mais robusta do que a correlação e requer testes rigorosos.
Só porque duas variáveis estão correlacionadas não significa que uma causa a outra. Este é um caso clássico de não confundir “correlação” com “causalidade”.
10. Regressão Linear Simples
simples regressão linear é uma forma de modelar a relação entre duas variáveis ajustando uma equação linear aos dados observados. Uma variável é considerada uma variável explicativa (independente) e a outra é uma variável dependente.
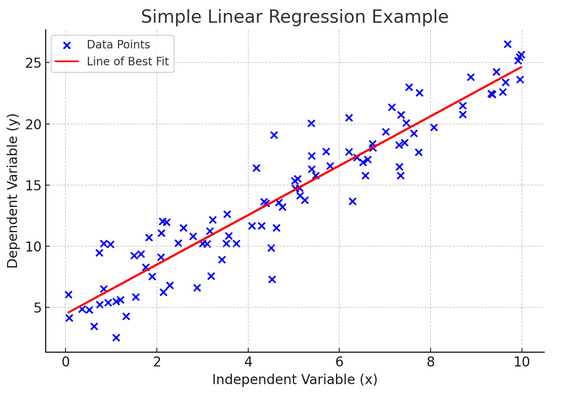
A regressão linear simples nos ajuda a entender como as mudanças na variável independente afetam a variável dependente. É uma ferramenta poderosa para previsão e fundamental para muitos outros modelos estatísticos complexos. Ao analisar a relação entre duas variáveis, podemos fazer previsões informadas sobre como elas irão interagir.
A regressão linear simples assume uma relação linear entre a variável independente (variável explicativa) e a variável dependente. Se a relação entre estas duas variáveis não for linear, então os pressupostos da regressão linear simples podem ser violados, levando potencialmente a previsões ou interpretações imprecisas. Assim, verificar uma relação linear nos dados é essencial antes de aplicar a regressão linear simples.
11. Regressão Linear Múltipla
Pense na regressão linear múltipla como uma extensão da regressão linear simples. Ainda assim, em vez de tentar prever um resultado com um cavaleiro de armadura brilhante (preditor), você tem uma equipe inteira. É como passar de um jogo de basquete individual para um esforço de equipe inteira, onde cada jogador (preditor) traz habilidades únicas. A ideia é ver como diversas variáveis juntas influenciam um único resultado.
Porém, com uma equipe maior surge o desafio de gerenciar relacionamentos, conhecido como multicolinearidade. Ocorre quando os preditores estão muito próximos uns dos outros e compartilham informações semelhantes. Imagine dois jogadores de basquete constantemente tentando dar o mesmo arremesso; eles podem atrapalhar um ao outro. A regressão pode dificultar a visualização da contribuição única de cada preditor, distorcendo potencialmente a nossa compreensão de quais variáveis são significativas.
12. Regressão Logística
Embora a regressão linear preveja resultados contínuos (como temperatura ou preços), regressão logística é usado quando o resultado é definitivo (como sim/não, vitória/perda). Imagine tentar prever se uma equipe vencerá ou perderá com base em vários fatores; a regressão logística é sua estratégia ideal.
Ele transforma a equação linear para que sua saída fique entre 0 e 1, representando a probabilidade de pertencer a uma determinada categoria. É como ter uma lente mágica que converte pontuações contínuas numa visão clara do tipo “isto ou aquilo”, permitindo-nos prever resultados categóricos.
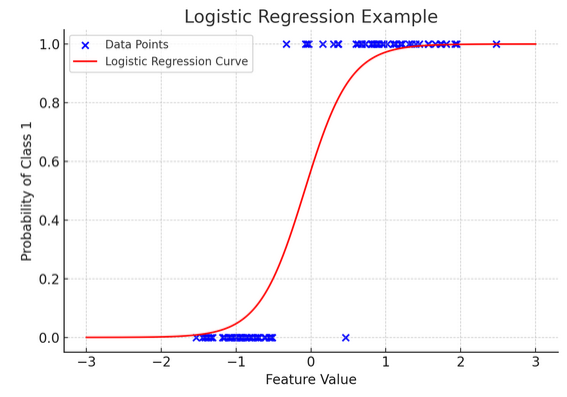
A representação gráfica ilustra um exemplo de regressão logística aplicada a um conjunto de dados de classificação binária sintética. Os pontos azuis representam os pontos de dados, com sua posição ao longo do eixo x indicando o valor do recurso e o eixo y indicando a categoria (0 ou 1). A curva vermelha representa a previsão do modelo de regressão logística da probabilidade de pertencer à classe 1 (por exemplo, “vitória”) para diferentes valores de características. Como você pode ver, a curva transita suavemente da probabilidade da classe 0 para a classe 1, demonstrando a capacidade do modelo de prever resultados categóricos com base em um recurso contínuo subjacente.
A fórmula para regressão logística é dada por:

Esta fórmula utiliza a função logística para transformar o resultado da equação linear numa probabilidade entre 0 e 1. Esta transformação permite-nos interpretar os resultados como probabilidades de pertencer a uma determinada categoria com base no valor da variável independente xx.
13. Testes ANOVA e Qui-Quadrado
ANOVA (Análise de Variância) e Testes Qui-Quadrado são como detetives no mundo da estatística, ajudando-nos a resolver diversos mistérios. EUt nos permite comparar médias entre vários grupos para ver se pelo menos um é estatisticamente diferente. Pense nisso como uma degustação de amostras de vários lotes de biscoitos para determinar se algum lote tem um sabor significativamente diferente.
Por outro lado, o teste Qui-Quadrado é utilizado para dados categóricos. Isso nos ajuda a entender se existe uma associação significativa entre duas variáveis categóricas. Por exemplo, existe uma relação entre o gênero musical favorito de uma pessoa e sua faixa etária? O teste Qui-Quadrado ajuda a responder a essas questões.
14. O Teorema do Limite Central e sua Importância na Ciência de Dados
A Teorema do Limite Central (CLT) é um princípio estatístico fundamental que parece quase mágico. Diz-nos que se retirarmos amostras suficientes de uma população e calcularmos as suas médias, essas médias formarão uma distribuição normal (a curva em sino), independentemente da distribuição original da população. Isto é incrivelmente poderoso porque nos permite fazer inferências sobre populações mesmo quando não sabemos a sua distribuição exacta.
Na ciência de dados, o CLT sustenta muitas técnicas, permitindo-nos usar ferramentas projetadas para dados normalmente distribuídos, mesmo quando nossos dados inicialmente não atendem a esses critérios. É como encontrar um adaptador universal para métodos estatísticos, tornando muitas ferramentas poderosas aplicáveis em mais situações.
15. Troca de polarização-variância
In modelagem preditiva e aprendizado de máquina, compensação de viés-variância é um conceito crucial que destaca a tensão entre dois tipos principais de erros que podem fazer com que nossos modelos dêem errado. Viés refere-se a erros de modelos excessivamente simplistas que não captam bem as tendências subjacentes. Imagine tentar encaixar uma linha reta em uma estrada curva; você vai errar o alvo. Por outro lado, as variações de modelos muito complexos capturam ruído nos dados como se fossem um padrão real – como traçar cada curva e virar em uma trilha acidentada, pensando que esse é o caminho a seguir.
A arte consiste em equilibrar esses dois para minimizar o erro total, encontrando o ponto ideal onde seu modelo está correto – complexo o suficiente para capturar os padrões precisos, mas simples o suficiente para ignorar o ruído aleatório. É como afinar uma guitarra; não soará bem se estiver muito apertado ou solto. A compensação entre viés e variância é encontrar o equilíbrio perfeito entre esses dois. A compensação entre viés e variância é a essência do ajuste de nossos modelos estatísticos para obter o melhor desempenho na previsão de resultados com precisão.
Conclusão
Desde a amostragem estatística até à compensação entre viés e variância, estes princípios não são meras noções académicas, mas ferramentas essenciais para uma análise criteriosa de dados. Eles equipam os aspirantes a cientistas de dados com as habilidades necessárias para transformar vastos dados em insights acionáveis, enfatizando as estatísticas como a espinha dorsal da tomada de decisões e da inovação baseadas em dados na era digital.
Perdemos algum conceito básico de estatística? Deixe-nos saber na seção de comentários abaixo.
Explore o nosso guia de estatísticas de ponta a ponta para que a ciência de dados conheça o assunto!
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

