Modele dużych języków (LLM) są zazwyczaj szkolone na dużych, publicznie dostępnych zbiorach danych, które są niezależne od domeny. Na przykład, Lama Meta modele są trenowane na zbiorach danych, takich jak Wspólne przeszukiwanie, C4, Wikipedia i arXiv. Te zbiory danych obejmują szeroki zakres tematów i dziedzin. Chociaż powstałe modele dają zadziwiająco dobre wyniki w przypadku zadań ogólnych, takich jak generowanie tekstu i rozpoznawanie jednostek, istnieją dowody na to, że modele wytrenowane przy użyciu zbiorów danych specyficznych dla domeny mogą jeszcze bardziej poprawić wydajność LLM. Na przykład dane szkoleniowe używane do BloombergGPT to 51% dokumentów specyficznych dla domeny, w tym wiadomości finansowych, dokumentów i innych materiałów finansowych. Powstały LLM przewyższa LLM przeszkolony na zbiorach danych innych niż domeny, gdy jest testowany pod kątem zadań specyficznych dla finansów. Autorzy BloombergGPT doszli do wniosku, że ich model przewyższa wszystkie inne modele przetestowane w przypadku czterech z pięciu zadań finansowych. Model zapewnił jeszcze lepsze wyniki w testach pod kątem wewnętrznych zadań finansowych Bloomberga z dużym marginesem – aż o 60 punktów lepiej (na 100). Chociaż więcej informacji na temat kompleksowych wyników oceny można znaleźć w papier, następująca próbka pobrana z pliku BloombergGPT Artykuł może dać ci wgląd w korzyści płynące ze szkolenia LLM przy użyciu danych specyficznych dla domeny finansowej. Jak pokazano w przykładzie, model BloombergGPT dostarczył poprawnych odpowiedzi, podczas gdy inne modele niezwiązane z domeną miały problemy:
Ten post zawiera przewodnik po szkoleniu LLM specjalnie dla domeny finansowej. Zajmujemy się następującymi kluczowymi obszarami:
- Gromadzenie i przygotowywanie danych – Wytyczne dotyczące pozyskiwania i selekcji odpowiednich danych finansowych na potrzeby skutecznego szkolenia modelowego
- Ciągłe szkolenie wstępne a dostrajanie – Kiedy stosować każdą technikę, aby zoptymalizować wydajność LLM
- Skuteczne, ciągłe szkolenie wstępne – Strategie usprawniające ciągły proces szkolenia przygotowawczego, oszczędzające czas i zasoby
To stanowisko łączy wiedzę zespołu badawczego w dziedzinie nauk stosowanych w Amazon Finance Technology i ogólnoświatowego zespołu specjalistów AWS dla globalnej branży finansowej. Część treści opiera się na papierze Skuteczne, ciągłe szkolenie wstępne w zakresie budowania modeli dużych języków specyficznych dla domeny.
Zbieranie i przygotowywanie danych finansowych
Ciągłe szkolenie wstępne domeny wymaga wielkoskalowego, wysokiej jakości zestawu danych specyficznego dla domeny. Poniżej przedstawiono główne etapy sprawdzania zbioru danych domeny:
- Zidentyfikuj źródła danych – Potencjalne źródła danych dla korpusu domen obejmują otwartą sieć, Wikipedię, książki, media społecznościowe i dokumenty wewnętrzne.
- Filtry danych domeny – Ponieważ ostatecznym celem jest selekcja korpusu domeny, może być konieczne zastosowanie dodatkowych kroków w celu odfiltrowania próbek, które nie są istotne dla domeny docelowej. Zmniejsza to bezużyteczny korpus do ciągłego szkolenia wstępnego i zmniejsza koszty szkolenia.
- Przetwarzanie wstępne – Można rozważyć serię etapów wstępnego przetwarzania, aby poprawić jakość danych i efektywność uczenia. Na przykład niektóre źródła danych mogą zawierać znaczną liczbę zakłóconych tokenów; deduplikację uważa się za przydatny krok w poprawie jakości danych i obniżeniu kosztów szkoleń.
Aby opracować finansowe LLM, możesz skorzystać z dwóch ważnych źródeł danych: News CommonCrawl i zgłoszeń SEC. Zgłoszenie do SEC to sprawozdanie finansowe lub inny formalny dokument przedłożony amerykańskiej Komisji Papierów Wartościowych i Giełd (SEC). Spółki notowane na giełdzie są zobowiązane do regularnego składania różnych dokumentów. Powoduje to powstawanie dużej liczby dokumentów na przestrzeni lat. Wiadomości CommonCrawl to zbiór danych opublikowany przez CommonCrawl w 2016 roku. Zawiera artykuły z serwisów informacyjnych z całego świata.
Wiadomości CommonCrawl jest dostępny na Usługa Amazon Simple Storage (Amazon S3) w commoncrawl wiadro przy crawl-data/CC-NEWS/. Możesz uzyskać listę plików za pomocą Interfejs wiersza poleceń AWS (AWS CLI) i następujące polecenie:
In Skuteczne, ciągłe szkolenie wstępne w zakresie budowania modeli dużych języków specyficznych dla domeny, autorzy stosują podejście oparte na adresach URL i słowach kluczowych, aby odfiltrować artykuły z wiadomościami finansowymi od wiadomości ogólnych. W szczególności autorzy prowadzą listę ważnych serwisów informacyjnych finansowych i zestaw słów kluczowych związanych z wiadomościami finansowymi. Artykuł uznajemy za wiadomość finansową, jeśli pochodzi z serwisów informacyjnych finansowych lub jeśli w adresie URL pojawiają się słowa kluczowe. To proste, ale skuteczne podejście umożliwia identyfikację wiadomości finansowych nie tylko z serwisów informacyjnych finansowych, ale także z sekcji finansowych ogólnych serwisów informacyjnych.
Zgłoszenia do SEC są dostępne w Internecie za pośrednictwem bazy danych SEC EDGAR (elektroniczne gromadzenie, analiza i wyszukiwanie danych), która zapewnia otwarty dostęp do danych. Możesz zeskrobać opiłki bezpośrednio z EDGAR lub użyć API w Amazon Sage Maker z kilkoma linijkami kodu, na dowolny okres czasu i dla dużej liczby znaczników (tj. identyfikator przypisany przez SEC). Aby dowiedzieć się więcej, zob Odzyskiwanie dokumentów SEC.
W poniższej tabeli podsumowano najważniejsze szczegóły obu źródeł danych.
| . | Aktualności CommonCrawl | Złożenie do SEC |
| Pokrycie | 2016-2022 | 1993-2022 |
| Rozmiar | 25.8 miliarda słów | 5.1 miliarda słów |
Autorzy przechodzą przez kilka dodatkowych etapów wstępnego przetwarzania, zanim dane zostaną wprowadzone do algorytmu szkoleniowego. Po pierwsze, zauważamy, że zgłoszenia SEC zawierają zaszumiony tekst wynikający z usunięcia tabel i rycin, dlatego autorzy usuwają krótkie zdania, które są uważane za etykiety tabel lub rycin. Po drugie, stosujemy algorytm mieszający uwzględniający lokalizację, aby deduplikować nowe artykuły i zgłoszenia. W przypadku zgłoszeń SEC deduplikujemy na poziomie sekcji, a nie na poziomie dokumentu. Na koniec łączymy dokumenty w długi ciąg, tokenizujemy go i dzielimy tokenizację na fragmenty o maksymalnej długości wejściowej obsługiwanej przez trenowany model. Poprawia to wydajność ciągłego szkolenia wstępnego i zmniejsza koszty szkolenia.
Ciągłe szkolenie wstępne a dostrajanie
Większość dostępnych LLM ma charakter ogólny i brakuje im możliwości specyficznych dla domeny. Domenowe LLM wykazały znaczne wyniki w dziedzinach medycznych, finansowych i naukowych. Aby LLM mógł zdobyć wiedzę specyficzną dla domeny, istnieją cztery metody: szkolenie od podstaw, ciągłe szkolenie wstępne, dostrajanie instrukcji dotyczących zadań domeny oraz generowanie rozszerzone wyszukiwania (RAG).
W tradycyjnych modelach dostrajanie jest zwykle używane do tworzenia modeli specyficznych dla zadania dla domeny. Oznacza to utrzymywanie wielu modeli do wielu zadań, takich jak wyodrębnianie jednostek, klasyfikacja zamiarów, analiza tonacji lub odpowiadanie na pytania. Wraz z pojawieniem się LLM potrzeba utrzymywania oddzielnych modeli stała się przestarzała poprzez stosowanie technik takich jak uczenie się w kontekście lub podpowiadanie. Oszczędza to wysiłek wymagany do utrzymania stosu modeli dla powiązanych, ale odrębnych zadań.
Intuicyjnie możesz szkolić LLM od podstaw, korzystając z danych specyficznych dla domeny. Chociaż większość pracy związanej z tworzeniem domenowych LLM skupiała się na szkoleniu od podstaw, jest to zbyt drogie. Na przykład koszty modelu GPT-4 ponad $ 100 milionów szkolić. Modele te są szkolone na kombinacji otwartych danych domeny i danych domeny. Ciągłe szkolenie wstępne może pomóc modelom w zdobyciu wiedzy specyficznej dla domeny bez ponoszenia kosztów wstępnego szkolenia od zera, ponieważ wstępnie szkolisz istniejącą LLM z otwartą domeną tylko na danych domeny.
Dzięki dostrajaniu instrukcji do zadania nie można zmusić modelu do uzyskania wiedzy o domenie, ponieważ LLM pozyskuje jedynie informacje o domenie zawarte w zestawie danych dostrajających instrukcje. O ile nie zostanie wykorzystany bardzo duży zbiór danych do dostrajania instrukcji, zdobycie wiedzy dziedzinowej nie wystarczy. Pozyskiwanie wysokiej jakości zestawów danych dotyczących instrukcji jest zwykle wyzwaniem i jest powodem, aby w pierwszej kolejności korzystać z LLM. Ponadto dostrojenie instrukcji w jednym zadaniu może mieć wpływ na wykonanie innych zadań (jak widać w ten papier). Jednak dostrajanie instrukcji jest bardziej opłacalne niż którakolwiek z alternatywnych metod szkolenia przedszkoleniowego.
Poniższy rysunek porównuje tradycyjne dostrajanie specyficzne dla zadania. a paradygmat uczenia się w kontekście w LLM.
 RAG to najskuteczniejszy sposób kierowania LLM w celu generowania odpowiedzi opartych na domenie. Chociaż może kierować modelem w celu generowania odpowiedzi, dostarczając fakty z domeny jako informacje pomocnicze, nie nabywa języka specyficznego dla domeny, ponieważ LLM nadal opiera się na stylu języka spoza domeny w celu generowania odpowiedzi.
RAG to najskuteczniejszy sposób kierowania LLM w celu generowania odpowiedzi opartych na domenie. Chociaż może kierować modelem w celu generowania odpowiedzi, dostarczając fakty z domeny jako informacje pomocnicze, nie nabywa języka specyficznego dla domeny, ponieważ LLM nadal opiera się na stylu języka spoza domeny w celu generowania odpowiedzi.
Ciągłe szkolenie wstępne stanowi środek pomiędzy szkoleniem wstępnym a dopracowywaniem instrukcji pod względem kosztów, a jednocześnie stanowi silną alternatywę dla zdobywania wiedzy i stylu specyficznego dla danej dziedziny. Może zapewnić ogólny model, na podstawie którego można przeprowadzić dalsze dostrajanie instrukcji na podstawie ograniczonych danych instrukcji. Ciągłe szkolenie wstępne może być opłacalną strategią w wyspecjalizowanych dziedzinach, w których zestaw dalszych zadań jest duży lub nieznany, a dane dotyczące dostrajania instrukcji oznakowanych są ograniczone. W innych scenariuszach bardziej odpowiednie może być dostrajanie instrukcji lub RAG.
Aby dowiedzieć się więcej na temat dostrajania, RAG i uczenia modeli, zobacz Dostosuj model fundamentu, Generowanie rozszerzone odzyskiwania (RAG), Trenuj model z Amazon SageMakerodpowiednio. W tym poście skupimy się na skutecznym, ciągłym szkoleniu wstępnym.
Metodologia skutecznego ciągłego szkolenia przygotowawczego
Ciągłe szkolenie przygotowawcze składa się z następującej metodologii:
- Ciągłe szkolenie wstępne dostosowane do domeny (DACP) - Na papierze Skuteczne, ciągłe szkolenie wstępne w zakresie budowania modeli dużych języków specyficznych dla domeny, autorzy stale wstępnie szkolą zestaw modeli języka Pythia w korpusie finansowym, aby dostosować go do domeny finansów. Celem jest utworzenie finansowych LLM poprzez wprowadzenie danych z całej domeny finansowej do modelu o otwartym kodzie źródłowym. Ponieważ korpus szkoleniowy zawiera wszystkie wybrane zbiory danych w domenie, powstały model powinien zdobywać wiedzę dotyczącą finansów, stając się w ten sposób wszechstronnym modelem do różnych zadań finansowych. W rezultacie powstają modele FinPythia.
- Ciągłe szkolenie wstępne adaptacyjne do zadań (TACP) – Autorzy wstępnie szkolą modele na podstawie oznaczonych i nieoznaczonych danych zadań, aby dostosować je do konkretnych zadań. W pewnych okolicznościach programiści mogą preferować modele zapewniające lepszą wydajność w przypadku grupy zadań w domenie, a nie model ogólny dla domeny. TACP zaprojektowano jako ciągłe szkolenie wstępne, mające na celu poprawę wydajności w zakresie określonych zadań, bez wymagań dotyczących oznakowanych danych. W szczególności autorzy stale wstępnie szkolą modele open source na tokenach zadań (bez etykiet). Podstawowe ograniczenie TACP polega na konstruowaniu LLM specyficznych dla zadania zamiast podstawowych LLM, ze względu na wyłączne wykorzystanie nieoznakowanych danych zadań do szkolenia. Chociaż DACP wykorzystuje znacznie większy korpus, jest zbyt drogi. Aby zrównoważyć te ograniczenia, autorzy proponują dwa podejścia, których celem jest zbudowanie fundamentów LLM specyficznych dla danej domeny, przy jednoczesnym zachowaniu doskonałej wydajności w zakresie docelowych zadań:
- Wydajny, zadaniowy DACP (ETS-DACP) – Autorzy proponują wybranie podzbioru korpusu finansowego, który jest bardzo podobny do danych zadania, wykorzystując osadzanie podobieństwa. Ten podzbiór służy do ciągłego szkolenia wstępnego, aby uczynić go bardziej efektywnym. W szczególności autorzy stale wstępnie szkolą LLM o otwartym kodzie źródłowym na małym korpusie wyodrębnionym z korpusu finansowego, który jest bliski docelowym zadaniom w dystrybucji. Może to pomóc w poprawie wydajności zadań, ponieważ przyjmujemy model dystrybucji tokenów zadań, mimo że dane oznaczone etykietami nie są wymagane.
- Wydajny, niezależny od zadań DACP (ETA-DACP) – Autorzy proponują użycie wskaźników takich jak zakłopotanie i entropia typu tokena, które nie wymagają danych zadaniowych w celu wybrania próbek z korpusu finansowego w celu skutecznego ciągłego szkolenia wstępnego. To podejście ma na celu radzenie sobie ze scenariuszami, w których dane zadań są niedostępne lub preferowane są bardziej wszechstronne modele domeny dla szerszej domeny. Autorzy przyjmują dwa wymiary, aby wybrać próbki danych, które są ważne dla uzyskania informacji o domenie z podzbioru danych domeny przed uczeniem: nowość i różnorodność. Nowość, mierzona zakłopotaniem zarejestrowanym przez docelowy model, odnosi się do informacji, których LLM wcześniej nie widział. Dane o dużej nowości wskazują na nową wiedzę dla LLM i takie dane są postrzegane jako trudniejsze do nauczenia. To aktualizuje ogólne LLM o intensywną wiedzę dziedzinową podczas ciągłego szkolenia wstępnego. Z drugiej strony różnorodność obejmuje różnorodność dystrybucji typów tokenów w korpusie domeny, co zostało udokumentowane jako przydatna funkcja w badaniach programów nauczania dotyczących modelowania języka.
Poniższy rysunek porównuje przykład ETS-DACP (po lewej) i ETA-DACP (po prawej).

Przyjmujemy dwa schematy próbkowania, aby aktywnie wybierać punkty danych z wyselekcjonowanego korpusu finansowego: próbkowanie twarde i próbkowanie miękkie. W tym pierwszym przypadku najpierw rankinguje się korpus finansowy według odpowiednich wskaźników, a następnie wybiera się k najlepszych próbek, gdzie k jest z góry określone na podstawie budżetu szkoleniowego. W tym ostatnim przypadku autorzy przypisują wagi próbkowania każdemu punktowi danych zgodnie z wartościami metryki, a następnie losowo wybierają k punktów danych, aby spełnić budżet szkoleniowy.
Wynik i analiza
Autorzy oceniają powstałe finansowe LLM w zakresie szeregu zadań finansowych, aby zbadać skuteczność ciągłego szkolenia wstępnego:
- Bank wyrażeń finansowych – Zadanie klasyfikacji nastrojów w wiadomościach finansowych.
- FiQA SA – Zadanie klasyfikacji nastrojów oparte na aspektach w oparciu o wiadomości finansowe i nagłówki gazet.
- Nagłówek – Zadanie klasyfikacji binarnej sprawdzające, czy nagłówek podmiotu finansowego zawiera określone informacje.
- NER – Zadanie wyodrębnienia wskazanego podmiotu finansowego w oparciu o sekcję raportów SEC dotyczącą oceny ryzyka kredytowego. Słowa w tym zadaniu są oznaczone PER, LOC, ORG i MISC.
Ponieważ finansowe LLM są dostosowane do instrukcji, autorzy oceniają modele w ustawieniu 5-stopniowym dla każdego zadania ze względu na solidność. FinPythia 6.9B przewyższa Pythię 6.9B średnio o 10% w czterech zadaniach, co pokazuje skuteczność ciągłego szkolenia wstępnego specyficznego dla danej domeny. W przypadku modelu 1B poprawa jest mniej głęboka, ale wydajność nadal poprawia się średnio o 2%.
Poniższy rysunek ilustruje różnicę w wydajności przed i po DACP w obu modelach.

Poniższy rysunek przedstawia dwa przykłady jakościowe wygenerowane przez Pythia 6.9B i FinPythia 6.9B. W przypadku dwóch pytań związanych z finansami, dotyczących menedżera inwestora i terminu finansowego, Pythia 6.9B nie rozumie tego terminu ani nie rozpoznaje nazwy, natomiast FinPythia 6.9B poprawnie generuje szczegółowe odpowiedzi. Przykłady jakościowe pokazują, że ciągłe szkolenie wstępne umożliwia LLM zdobywanie wiedzy dziedzinowej w trakcie procesu.

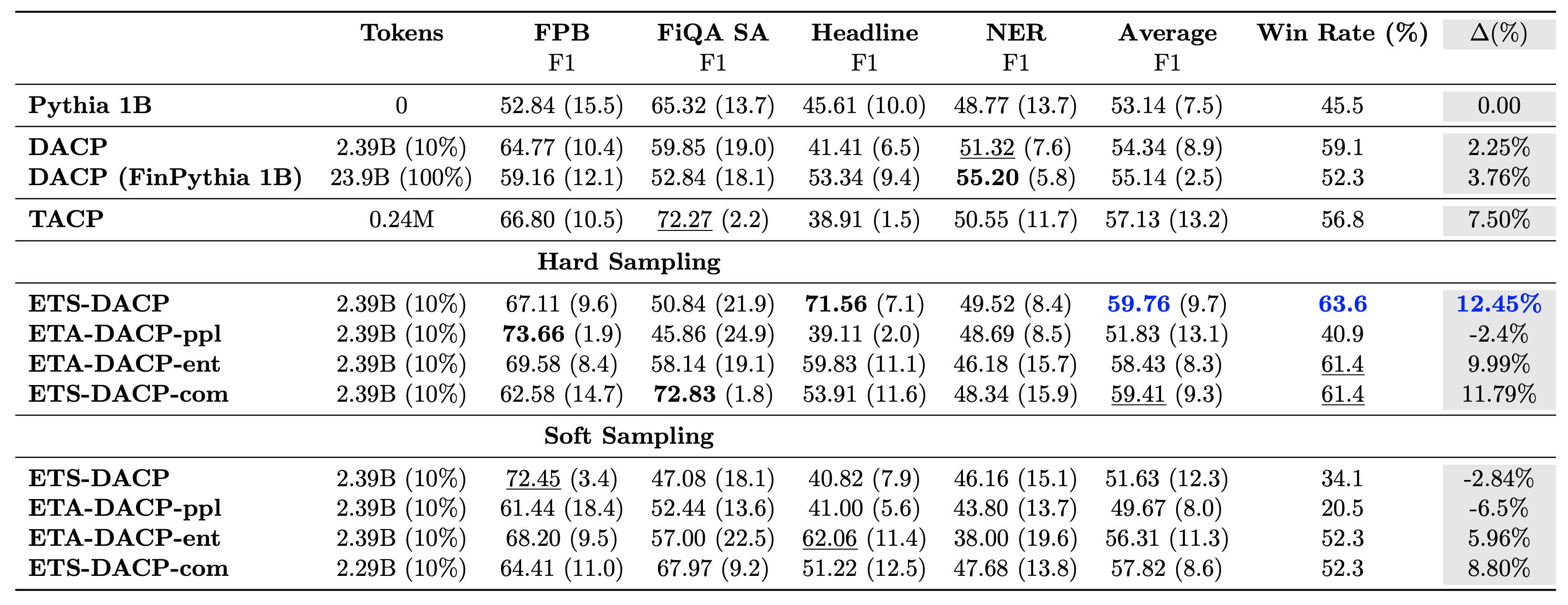
Poniższa tabela porównuje różne skuteczne podejścia do ciągłego szkolenia przedszkoleniowego. ETA-DACP-ppl to ETA-DACP oparty na zakłopotaniu (nowość), a ETA-DACP-ent oparty na entropii (różnorodność). ETS-DACP-com jest podobny do DACP z wyborem danych poprzez uśrednienie wszystkich trzech wskaźników. Oto kilka wniosków z wyników:
- Metody selekcji danych są skuteczne – Przewyższają standardowy ciągły trening przedtreningowy dzięki zaledwie 10% danych treningowych. Wydajne, ciągłe szkolenie wstępne, w tym DACP podobne do zadań (ETS-DACP), DACP niezależne od zadań oparte na entropii (ESA-DACP-ent) i DACP podobne do zadań oparte na wszystkich trzech metrykach (ETS-DACP-com) przewyższają standardowy DACP średnio, mimo że kształcą się jedynie w 10% korpusu finansowego.
- Selekcja danych uwzględniająca zadania sprawdza się najlepiej w przypadku badań małych modeli językowych – ETS-DACP rejestruje najlepszą średnią wydajność spośród wszystkich metod i, w oparciu o wszystkie trzy wskaźniki, rejestruje drugą najlepszą wydajność zadania. Sugeruje to, że wykorzystywanie nieoznaczonych danych dotyczących zadań jest nadal skutecznym podejściem do zwiększania wydajności zadań w przypadku LLM.
- Wybór danych niezależny od zadania zajmuje drugie miejsce – ESA-DACP-ent opiera się na podejściu do selekcji danych uwzględniającym zadania, co oznacza, że nadal moglibyśmy zwiększyć wydajność zadań poprzez aktywny wybór próbek wysokiej jakości niezwiązanych z konkretnymi zadaniami. Toruje drogę do budowania finansowych LLM dla całej domeny przy jednoczesnym osiągnięciu doskonałej wydajności zadań.
Kluczowym pytaniem dotyczącym ciągłego szkolenia wstępnego jest to, czy wpływa ono negatywnie na wykonywanie zadań spoza domeny. Autorzy oceniają także stale trenujący model w zakresie czterech szeroko stosowanych zadań ogólnych: ARC, MMLU, TruthQA i HellaSwag, które mierzą zdolność odpowiadania na pytania, rozumowania i kończenia pytań. Autorzy stwierdzają, że ciągłe szkolenie wstępne nie wpływa negatywnie na wyniki poza dziedziną. Więcej szczegółów znajdziesz w Skuteczne, ciągłe szkolenie wstępne w zakresie budowania modeli dużych języków specyficznych dla domeny.
Wnioski
Ten post oferował wgląd w gromadzenie danych i strategie ciągłego szkolenia wstępnego w zakresie szkolenia LLM w dziedzinie finansów. Możesz rozpocząć szkolenie własnych LLM w zakresie zadań finansowych Szkolenie Amazon SageMaker or Amazońska skała macierzysta dzisiaj.
O autorach
 Yong Xie jest naukowcem stosowanym w Amazon FinTech. Koncentruje się na opracowywaniu dużych modeli językowych i aplikacji generatywnej AI dla finansów.
Yong Xie jest naukowcem stosowanym w Amazon FinTech. Koncentruje się na opracowywaniu dużych modeli językowych i aplikacji generatywnej AI dla finansów.
 Karana Aggarwala jest starszym naukowcem w Amazon FinTech, specjalizującym się w generatywnej sztucznej inteligencji w zastosowaniach finansowych. Karan ma rozległe doświadczenie w analizie szeregów czasowych i NLP, ze szczególnym uwzględnieniem uczenia się na ograniczonych, oznakowanych danych
Karana Aggarwala jest starszym naukowcem w Amazon FinTech, specjalizującym się w generatywnej sztucznej inteligencji w zastosowaniach finansowych. Karan ma rozległe doświadczenie w analizie szeregów czasowych i NLP, ze szczególnym uwzględnieniem uczenia się na ograniczonych, oznakowanych danych
 Aitzaza Ahmada jest menedżerem ds. nauk stosowanych w firmie Amazon, gdzie kieruje zespołem naukowców tworzących różne zastosowania uczenia maszynowego i generatywnej sztucznej inteligencji w finansach. Jego zainteresowania badawcze obejmują NLP, generatywną sztuczną inteligencję i agentów LLM. Uzyskał stopień doktora inżynierii elektrycznej na Uniwersytecie Texas A&M.
Aitzaza Ahmada jest menedżerem ds. nauk stosowanych w firmie Amazon, gdzie kieruje zespołem naukowców tworzących różne zastosowania uczenia maszynowego i generatywnej sztucznej inteligencji w finansach. Jego zainteresowania badawcze obejmują NLP, generatywną sztuczną inteligencję i agentów LLM. Uzyskał stopień doktora inżynierii elektrycznej na Uniwersytecie Texas A&M.
 Qingwei Li jest specjalistą ds. uczenia maszynowego w Amazon Web Services. Uzyskał stopień doktora. w Operations Research po tym, jak złamał konto swojego doradcy na grant badawczy i nie dostarczył obiecanej Nagrody Nobla. Obecnie pomaga klientom z branży usług finansowych budować rozwiązania do uczenia maszynowego na platformie AWS.
Qingwei Li jest specjalistą ds. uczenia maszynowego w Amazon Web Services. Uzyskał stopień doktora. w Operations Research po tym, jak złamał konto swojego doradcy na grant badawczy i nie dostarczył obiecanej Nagrody Nobla. Obecnie pomaga klientom z branży usług finansowych budować rozwiązania do uczenia maszynowego na platformie AWS.
 Raghvender Arni kieruje Zespołem ds. Akceleracji Klienta (CAT) w AWS Industries. CAT to globalny, wielofunkcyjny zespół składający się z architektów chmur, inżynierów oprogramowania, analityków danych oraz ekspertów i projektantów AI/ML, który napędza innowacje poprzez zaawansowane prototypowanie i zapewnia doskonałość operacyjną chmury dzięki specjalistycznej wiedzy technicznej.
Raghvender Arni kieruje Zespołem ds. Akceleracji Klienta (CAT) w AWS Industries. CAT to globalny, wielofunkcyjny zespół składający się z architektów chmur, inżynierów oprogramowania, analityków danych oraz ekspertów i projektantów AI/ML, który napędza innowacje poprzez zaawansowane prototypowanie i zapewnia doskonałość operacyjną chmury dzięki specjalistycznej wiedzy technicznej.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

