Klient 360 (C360) zapewnia pełny i ujednolicony obraz interakcji i zachowań klienta we wszystkich punktach kontaktu i kanałach. Widok ten służy do identyfikowania wzorców i trendów w zachowaniach klientów, co może pomóc w podejmowaniu decyzji opartych na danych w celu poprawy wyników biznesowych. Możesz na przykład użyć C360 do segmentowania i tworzenia kampanii marketingowych, które z większym prawdopodobieństwem trafią do określonych grup klientów.
W 2022 r. AWS zleciło amerykańskiemu Centrum Produktywności i Jakości (APQC) przeprowadzenie badania w celu ilościowego określenia Wartość biznesowa klienta 360. Poniższy rysunek przedstawia niektóre wskaźniki uzyskane w badaniu. Organizacje korzystające z C360 osiągnęły skrócenie czasu trwania cyklu sprzedaży o 43.9%, wzrost wartości życiowej klienta o 22.8%, czas wprowadzenia produktu na rynek o 25.3% krótszy i poprawę oceny netto promotora (NPS) o 19.1%.

Bez C360 firmy stają w obliczu straconych szans, niedokładnych raportów i chaotycznych doświadczeń klientów, co prowadzi do ich odejścia. Jednak zbudowanie rozwiązania C360 może być skomplikowane. A Ankieta marketingowa Gartnera wykazało, że tylko 14% organizacji pomyślnie wdrożyło rozwiązanie C360 ze względu na brak konsensusu co do znaczenia widoku 360 stopni, wyzwania związane z jakością danych oraz brak wielofunkcyjnej struktury zarządzania danymi klientów.
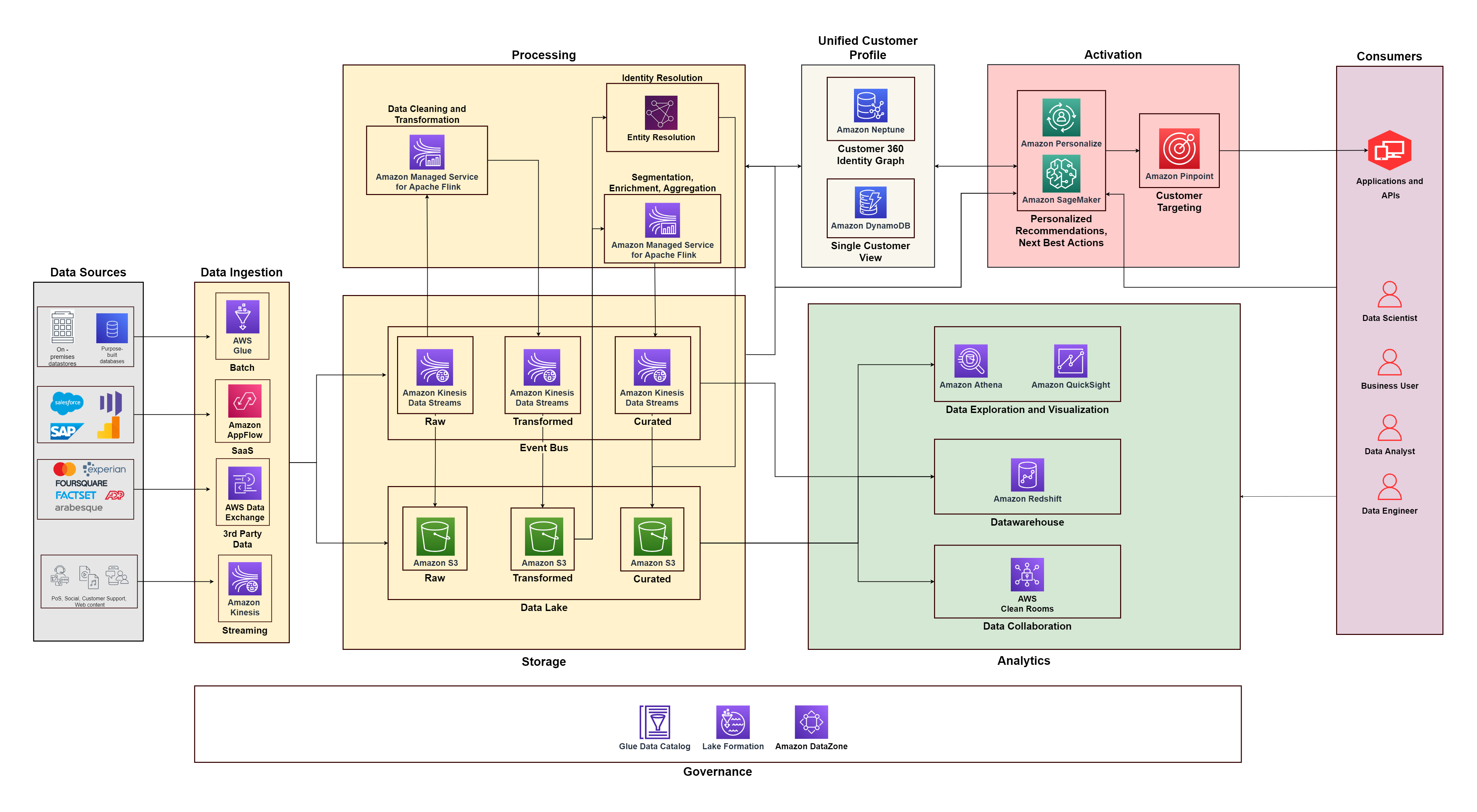
W tym poście omawiamy, w jaki sposób można wykorzystać specjalnie zaprojektowane usługi AWS do stworzenia kompleksowej strategii danych dla C360 w celu ujednolicenia i zarządzania danymi klientów, która sprosta tym wyzwaniom. Podzieliliśmy go na pięć filarów, na których opiera się C360: gromadzenie danych, ujednolicenie, analityka, aktywacja i zarządzanie danymi, wraz z architekturą rozwiązania, którą możesz wykorzystać do swojego wdrożenia.
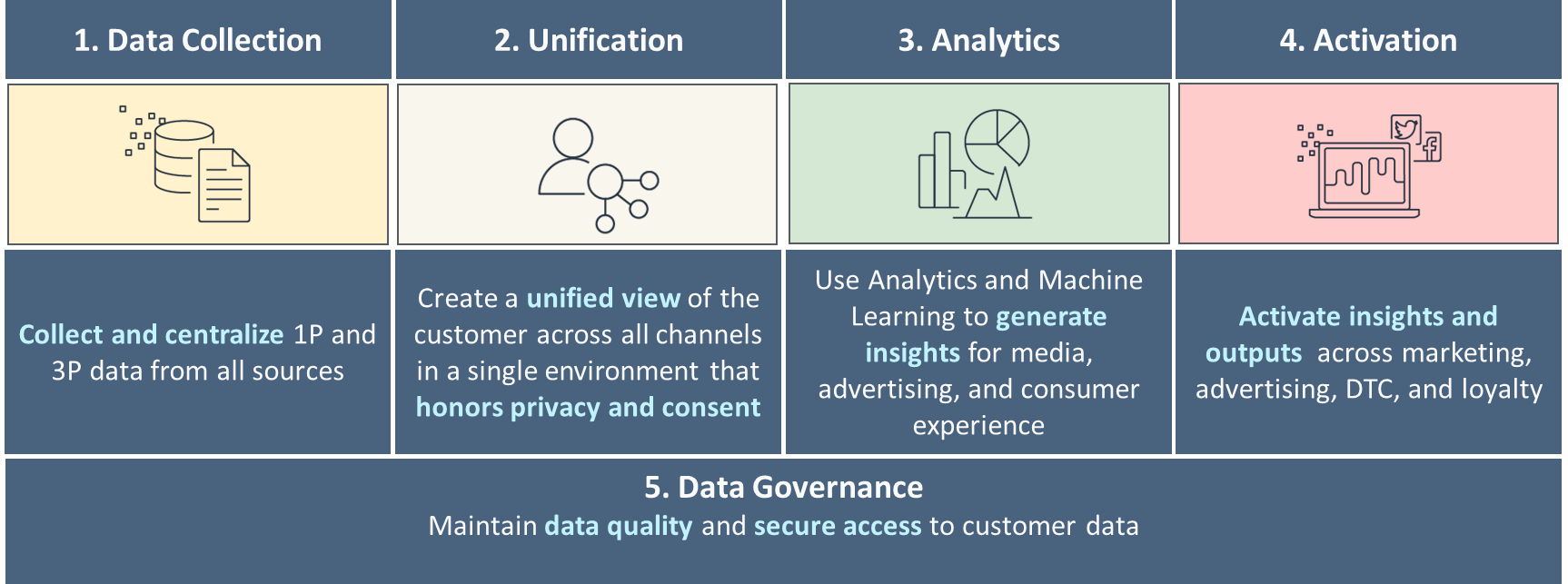
Pięć filarów dojrzałego C360
Rozpoczynając tworzenie C360, pracujesz z wieloma przypadkami użycia, typami danych klientów oraz użytkownikami i aplikacjami, które wymagają różnych narzędzi. Budowanie platformy C360 na odpowiednich zbiorach danych, dodawanie z czasem nowych zbiorów danych przy jednoczesnym zachowaniu jakości danych i zapewnianiu ich bezpieczeństwa wymaga kompleksowej strategii dotyczącej danych klientów. Musisz także zapewnić narzędzia, które ułatwią Twoim zespołom tworzenie produktów, które udoskonalą Twoje C360.
Zalecamy zbudowanie strategii dotyczącej danych wokół pięciu filarów C360, jak pokazano na poniższym rysunku. Zaczyna się od podstawowego gromadzenia danych, ujednolicania i łączenia danych z różnych kanałów związanych z unikalnymi klientami, a następnie przechodzi w kierunku podstawowej i zaawansowanej analityki na potrzeby podejmowania decyzji oraz spersonalizowanego zaangażowania za pośrednictwem różnych kanałów. W miarę dojrzewania w każdym z tych filarów postępujesz w kierunku reagowania na sygnały klientów w czasie rzeczywistym.
Poniższy diagram ilustruje architekturę funkcjonalną, która łączy w sobie elementy składowe aplikacji Platforma danych klientów na AWS z dodatkowymi komponentami użytymi do zaprojektowania kompleksowego rozwiązania C360. Jest to zgodne z pięcioma filarami, które omawiamy w tym poście.
Filar 1: Gromadzenie danych
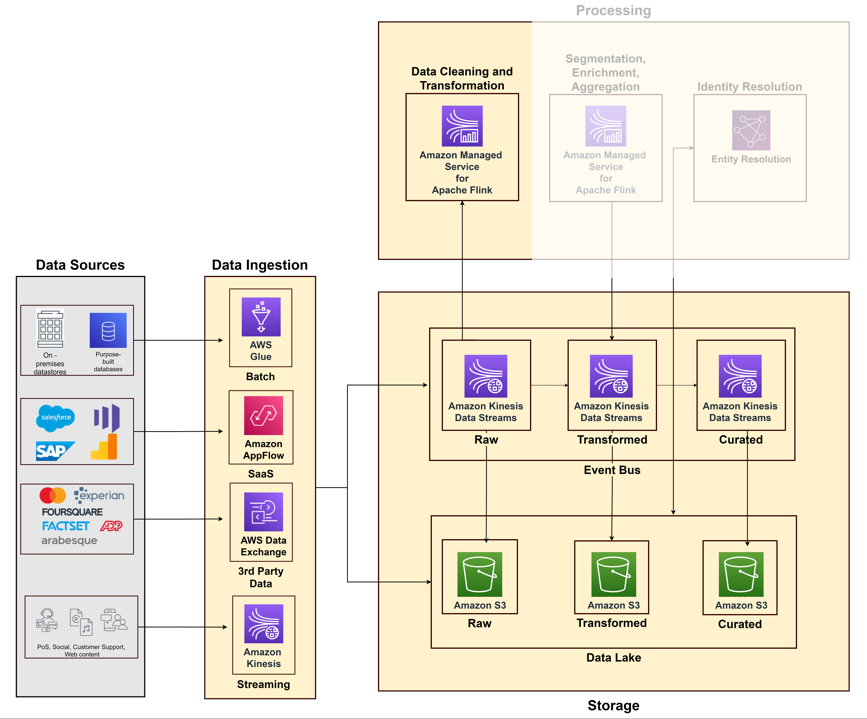
Rozpoczynając budowę platformy danych klientów, musisz zbierać dane z różnych systemów i punktów styku, takich jak systemy sprzedaży, obsługa klienta, internet i media społecznościowe oraz rynki danych. Pomyśl o filarze gromadzenia danych jako o połączeniu możliwości pozyskiwania, przechowywania i przetwarzania.
Pozyskiwanie danych
Należy tworzyć potoki pozyskiwania w oparciu o takie czynniki, jak typy źródeł danych (lokalne magazyny danych, pliki, aplikacje SaaS, dane innych firm) i przepływ danych (nieograniczone strumienie lub dane wsadowe). AWS zapewnia różne usługi budowania potoków pozyskiwania danych:
- Klej AWS to bezserwerowa usługa integracji danych, która pobiera dane partiami z lokalnych baz danych i magazynów danych w chmurze. Łączy się z ponad 70 źródłami danych i pomaga budować potoki wyodrębniania, przekształcania i ładowania (ETL) bez konieczności zarządzania infrastrukturą potoków. Jakość danych kleju AWS sprawdza i ostrzega o słabych danych, dzięki czemu można łatwo wykryć i naprawić problemy, zanim zaszkodzą Twojej firmie.
- Przepływ aplikacji Amazon pozyskuje dane z aplikacji typu Software as a Service (SaaS), takich jak Google Analytics, Salesforce, SAP i Marketo, zapewniając elastyczność w zakresie pozyskiwania danych z ponad 50 aplikacji SaaS.
- Wymiana danych AWS ułatwia wyszukiwanie, subskrybowanie i wykorzystywanie danych stron trzecich do celów analitycznych. Możesz subskrybować produkty związane z danymi, które pomagają wzbogacić profile klientów, na przykład dane demograficzne, dane reklamowe i dane dotyczące rynków finansowych.
- Amazonka Kinesis pozyskuje zdarzenia przesyłane strumieniowo w czasie rzeczywistym z systemów punktów sprzedaży, dane dotyczące kliknięć z aplikacji mobilnych i stron internetowych oraz dane z mediów społecznościowych. Można również rozważyć użycie Przesyłanie strumieniowe zarządzane przez Amazon dla Apache Kafka (Amazon MSK) do strumieniowego przesyłania wydarzeń w czasie rzeczywistym.
Poniższy diagram ilustruje różne potoki pozyskiwania danych z różnych systemów źródłowych przy użyciu usług AWS.
Przechowywanie danych
Ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane dane wsadowe są przechowywane w magazynie obiektowym, ponieważ są one ekonomiczne i trwałe. Usługa Amazon Simple Storage (Amazon S3) to zarządzana usługa pamięci masowej z funkcjami archiwizacji, w której można przechowywać petabajty danych jedenaście „9” trwałości. Dane przesyłane strumieniowo o niskim opóźnieniu są przechowywane w Strumienie danych Amazon Kinesis do konsumpcji w czasie rzeczywistym. Umożliwia to natychmiastowe analizy i działania dla różnych dalszych konsumentów – jak widać w przypadku centrali Riot Games Autobus na wydarzenie Riot.
Przetwarzanie danych
Surowe dane są często zaśmiecone duplikatami i nieregularnymi formatami. Musisz to przetworzyć, aby było gotowe do analizy. Jeśli korzystasz z danych wsadowych i danych przesyłanych strumieniowo, rozważ użycie platformy, która może obsłużyć jedno i drugie. Wzór taki jak Architektura Kappy postrzega wszystko jako strumień, upraszczając potoki przetwarzania. Rozważ użycie Usługa zarządzana przez Amazon dla Apache Flink do obsługi prac związanych z przetwarzaniem. Dzięki usłudze zarządzanej dla Apache Flink możesz oczyścić i przekształcić dane przesyłane strumieniowo oraz skierować je do odpowiedniego miejsca docelowego w oparciu o wymagania dotyczące opóźnień. Możesz także zaimplementować wsadowe przetwarzanie danych za pomocą Amazon EMR w frameworkach open source, takich jak Apache Spark przy 3.5 razy lepszej wydajności niż wersja samodzielnie zarządzana. Decyzja dotycząca architektury dotycząca wykorzystania systemu przetwarzania wsadowego lub strumieniowego będzie zależeć od różnych czynników; jeśli jednak chcesz włączyć analizę danych klientów w czasie rzeczywistym, zalecamy użycie wzorca architektury Kappa.
Filar 2: Zjednoczenie
Aby powiązać różnorodne dane docierające z różnych punktów styku z unikalnym klientem, należy zbudować rozwiązanie do przetwarzania tożsamości, które identyfikuje anonimowe loginy, przechowuje przydatne informacje o klientach, łączy je z danymi zewnętrznymi w celu uzyskania lepszego wglądu i grupuje klientów w interesujące domeny. Chociaż rozwiązanie do przetwarzania tożsamości pomaga w budowaniu ujednoliconego profilu klienta, zalecamy rozważenie tego w ramach możliwości przetwarzania danych. Poniższy schemat ilustruje elementy takiego rozwiązania.
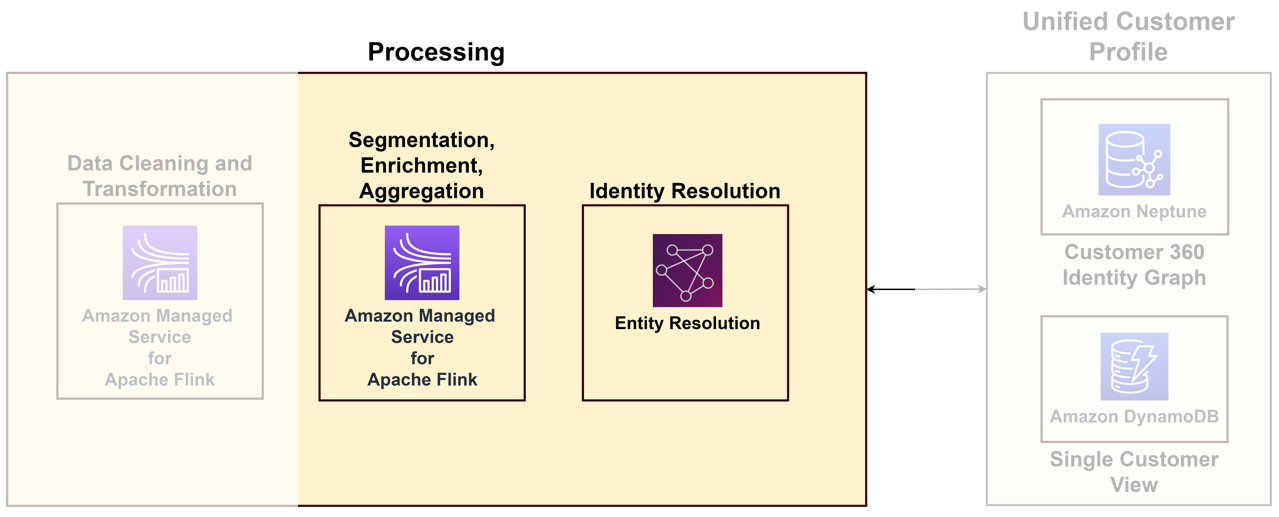
Kluczowe komponenty są następujące:
- Rozdzielczość tożsamości – Rozpoznawanie tożsamości to rozwiązanie deduplikacyjne, w którym rekordy są dopasowywane w celu identyfikacji unikalnego klienta i potencjalnego klienta poprzez połączenie wielu identyfikatorów, takich jak pliki cookie, identyfikatory urządzeń, adresy IP, identyfikatory e-mail i wewnętrzne identyfikatory przedsiębiorstwa ze znaną osobą lub anonimowym profilem przy użyciu funkcji ochrony prywatności zgodne metody. Można to osiągnąć za pomocą Rozdzielczość jednostki AWS, która umożliwia wykorzystanie reguł i technik uczenia maszynowego (ML). dopasowuj rekordy i identyfikuj tożsamości. Alternatywnie możesz budować grafy tożsamości za pomocą Amazon Neptun aby uzyskać jeden, ujednolicony widok swoich klientów.
- Agregacja profili – Możesz to zrobić, jeśli jednoznacznie zidentyfikujesz klienta budować aplikacje w usłudze zarządzanej dla Apache Flink do konsolidacji wszystkich metadanych, od nazwy po historię interakcji. Następnie przekształcasz te dane w zwięzły format. Zamiast pokazywać każdy szczegół transakcji, możesz zaoferować zagregowaną wartość wydatków i link do rekordu zarządzania relacjami z klientami (CRM). W przypadku interakcji z obsługą klienta podaj średni wynik CSAT i link do systemu call center, aby uzyskać głębszy wgląd w historię komunikacji.
- Wzbogacanie profilu – Po przypisaniu klienta do jednej tożsamości, ulepsz jego profil, korzystając z różnych źródeł danych. Wzbogacanie zazwyczaj polega na dodawaniu danych demograficznych, behawioralnych i geolokalizacyjnych. Możesz użyć produkty danych stron trzecich z AWS Marketplace dostarczane za pośrednictwem AWS Data Exchange aby uzyskać wgląd w dochody, wzorce konsumpcji, ocenę ryzyka kredytowego i wiele innych wymiarów w celu dalszego udoskonalenia obsługi klienta.
- Segmentacja klientów – Po jednoznacznej identyfikacji i wzbogaceniu profilu klienta można go segmentować na podstawie danych demograficznych, takich jak wiek, wydatki, dochód i lokalizacja, korzystając z aplikacji w usłudze Managed Service dla Apache Flink. W miarę postępów możesz włączyć Usługi AI umożliwiające bardziej precyzyjne techniki celowania.
Po przetworzeniu i segmentacji tożsamości potrzebna jest pamięć masowa do przechowywania unikalnego profilu klienta oraz zapewniania dodatkowych funkcji wyszukiwania i wysyłania zapytań, aby dalsi konsumenci mogli korzystać ze wzbogaconych danych klientów.
Poniższy diagram ilustruje filar unifikacji zapewniający ujednolicony profil klienta i pojedynczy widok klienta dla dalszych zastosowań.
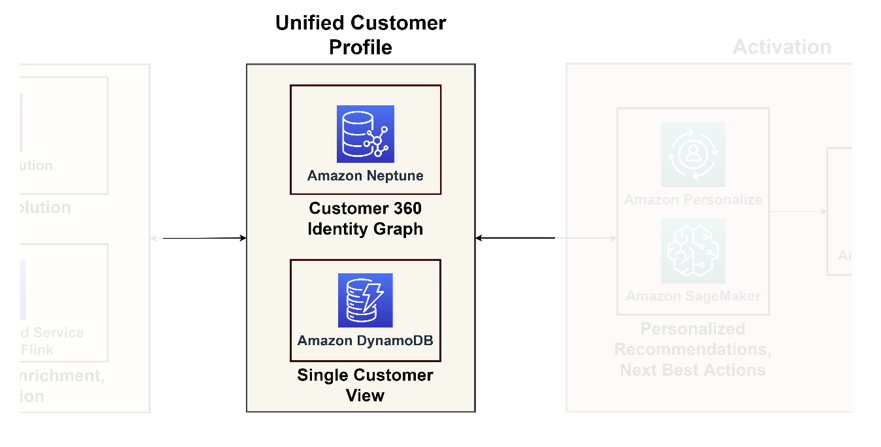
Ujednolicony profil klienta
Grafowe bazy danych przodują w modelowaniu interakcji i relacji z klientami, oferując kompleksowy obraz podróży klienta. Jeśli masz do czynienia z miliardami profili i interakcji, możesz rozważyć użycie Neptune, zarządzanej usługi bazy danych grafów na platformie AWS. Organizacje takie jak Zeta i Activision z powodzeniem wykorzystali Neptun do przechowywania i wysyłania zapytań o miliardy unikalnych identyfikatorów miesięcznie oraz miliony zapytań na sekundę z czasem odpowiedzi wynoszącym milisekundy.
Widok pojedynczego klienta
Chociaż grafowe bazy danych zapewniają szczegółowe informacje, w przypadku zwykłych aplikacji mogą być skomplikowane. Rozsądnie jest skonsolidować te dane w jednym widoku klienta, służącym jako główny punkt odniesienia dla dalszych aplikacji, od platform e-commerce po systemy CRM. Ten skonsolidowany widok działa jako łącznik pomiędzy platformą danych a aplikacjami zorientowanymi na klienta. Do takich celów zalecamy użycie Amazon DynamoDB ze względu na możliwości adaptacji, skalowalność i wydajność, czego efektem jest aktualna i wydajna baza danych klientów. Ta baza danych przyjmie wiele zapytań zwrotnych z systemów aktywacji, które zdobywają nowe informacje o klientach i przekazują im informacje zwrotne.
Filar 3: Analityka
Filar analityczny definiuje możliwości, które pomagają generować spostrzeżenia na podstawie danych klientów. Twoja strategia analityczna dotyczy szerszych potrzeb organizacji, a nie tylko C360. Możesz używać tych samych funkcji do raportowania finansowego, pomiaru wydajności operacyjnej, a nawet zarabiania na zasobach danych. Twórz strategie w oparciu o sposób, w jaki Twoje zespoły eksplorują dane, przeprowadzają analizy, przetwarzają dane pod kątem dalszych wymagań i wizualizują dane na różnych poziomach. Zaplanuj, w jaki sposób możesz umożliwić swoim zespołom korzystanie z ML w celu przejścia od analiz opisowych do analiz nakazowych.
Połączenia Nowoczesna architektura danych AWS pokazuje sposób na zbudowanie specjalnie zaprojektowanej, bezpiecznej i skalowalnej platformy danych w chmurze. Wyciągnij z tego wnioski, aby tworzyć możliwości wykonywania zapytań w jeziorze danych i hurtowni danych.
Poniższy diagram przedstawia możliwości analityczne w podziale na eksplorację danych, wizualizację, magazynowanie danych i współpracę w zakresie danych. Przekonajmy się, jaką rolę pełni każdy z tych komponentów w kontekście C360.

Eksploracja danych
Eksploracja danych pomaga odkryć niespójności, wartości odstające lub błędy. Wykrywając je na wczesnym etapie, Twoje zespoły mogą zapewnić lepszą integrację danych w C360, co z kolei prowadzi do dokładniejszych analiz i prognoz. Weź pod uwagę osoby eksplorujące dane, ich umiejętności techniczne i czas potrzebny na wgląd. Na przykład analitycy danych, którzy potrafią pisać SQL, mogą bezpośrednio wysyłać zapytania do danych znajdujących się w Amazon S3, używając Amazonka Atena. Użytkownicy zainteresowani eksploracją wizualną mogą to zrobić za pomocą DataBrew kleju AWS. Z których mogą korzystać naukowcy lub inżynierowie zajmujący się danymi Studio Amazon EMR or Studio Amazon SageMaker do eksplorowania danych z notesu i do obsługi małej ilości kodu, możesz użyć Pogromca danych Amazon SageMaker. Ponieważ te usługi bezpośrednio wysyłają zapytania do zasobników S3, możesz eksplorować dane po ich wylądowaniu w jeziorze danych, skracając czas potrzebny na uzyskanie wglądu.
Wizualizacja
Przekształcanie złożonych zbiorów danych w intuicyjne wizualizacje odkrywa ukryte wzorce w danych i ma kluczowe znaczenie w przypadkach użycia C360. Dzięki tej możliwości można projektować raporty dla różnych poziomów odpowiadające różnym potrzebom: raporty wykonawcze zawierające przeglądy strategiczne, raporty zarządcze podkreślające wskaźniki operacyjne oraz szczegółowe raporty zawierające szczegółowe informacje. Taka przejrzystość wizualna pomaga Twojej organizacji podejmować świadome decyzje na wszystkich poziomach, koncentrując perspektywę klienta.
Poniższy diagram przedstawia przykładowy wbudowany pulpit nawigacyjny C360 Amazon QuickSight. QuickSight oferuje skalowalne możliwości wizualizacji bezserwerowej. Możesz skorzystać z integracji ML w celu uzyskania zautomatyzowanych spostrzeżeń, takich jak prognozowanie i wykrywanie anomalii lub wysyłanie zapytań w języku naturalnym Amazon Q w QuickSight, bezpośrednią łączność danych z różnych źródeł oraz cena za sesję. Dzięki QuickSight jest to możliwe osadzaj dashboardy w zewnętrznych witrynach i aplikacjachi PRZYPRAWA silnik umożliwia szybką, interaktywną wizualizację danych na dużą skalę. Poniższy zrzut ekranu przedstawia przykładowy pulpit nawigacyjny C360 zbudowany w oparciu o QuickSight.
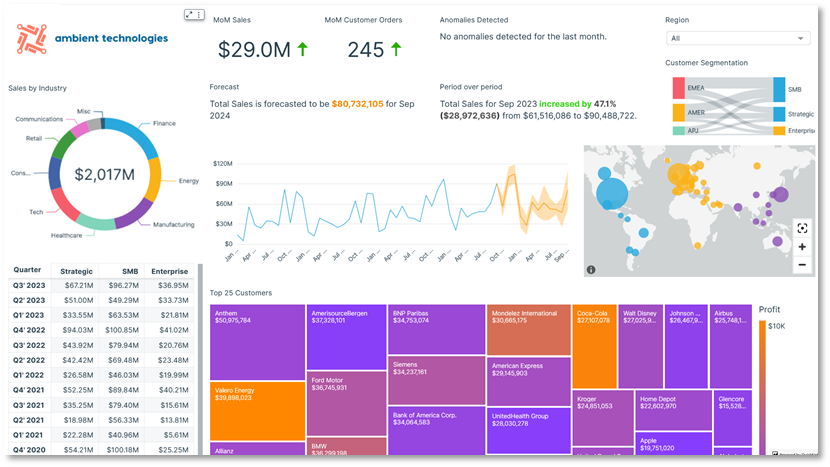
Hurtownia danych
Hurtownie danych skutecznie konsolidują ustrukturyzowane dane z różnorodnych źródeł i obsługują zapytania analityczne od dużej liczby jednoczesnych użytkowników. Hurtownie danych mogą zapewnić ujednolicony, spójny widok ogromnej ilości danych klientów w przypadkach użycia C360. Amazonka Przesunięcie ku czerwieni wychodzi naprzeciw tej potrzebie, umiejętnie obsługując duże ilości danych i różnorodne obciążenia. Zapewnia silną spójność między zbiorami danych, umożliwiając organizacjom uzyskiwanie wiarygodnych, kompleksowych informacji o swoich klientach, co jest niezbędne do podejmowania świadomych decyzji. Amazon Redshift oferuje wgląd w czasie rzeczywistym i możliwości analizy predykcyjnej w celu analizowania danych od terabajtów do petabajtów. Z Amazon Redshift ML, możesz osadzić uczenie maszynowe na danych przechowywanych w hurtowni danych przy minimalnym nakładzie pracy na rozwój. Bezserwerowe Amazon Redshift upraszcza tworzenie aplikacji i ułatwia firmom wdrażanie bogatych funkcji analizy danych.
Współpraca w zakresie danych
Można bezpiecznie współpracować i analizować zbiorowe zbiory danych od partnerów bez udostępniania lub kopiowania danych źródłowych Czyste pokoje AWS. Możesz łączyć różne dane z różnych kanałów zaangażowania i zbiorów danych partnerów, aby uzyskać 360-stopniowy obraz swoich klientów. AWS Clean Rooms może ulepszyć C360, umożliwiając takie zastosowania, jak optymalizacja marketingu w wielu kanałach, zaawansowana segmentacja klientów i personalizacja zgodna z prywatnością. Dzięki bezpiecznemu łączeniu zbiorów danych zapewnia bogatszy wgląd i solidną ochronę danych, spełniając potrzeby biznesowe i standardy regulacyjne.
Filar 4: Aktywacja
Wartość danych maleje wraz z upływem czasu, co prowadzi do wyższych kosztów alternatywnych. W ankiecie prowadzone przez Intersystems75% ankietowanych organizacji uważa, że przedwczesne dane ograniczają możliwości biznesowe. W innym badaniu 58% organizacji (spośród 560 respondentów Rady Doradczej HBR i czytelników) stwierdziło, że zaobserwowało wzrost utrzymania i lojalności klientów dzięki analizie klientów w czasie rzeczywistym.
Dojrzałość w C360 możesz osiągnąć, gdy zbudujesz umiejętność działania w czasie rzeczywistym w oparciu o wszystkie spostrzeżenia zdobyte z poprzednich filarów, o których mówiliśmy. Na przykład na tym poziomie dojrzałości możesz oddziaływać na nastroje klientów w oparciu o automatycznie uzyskany kontekst, dzięki wzbogaconemu profilowi klienta i zintegrowanym kanałom. W tym celu należy wdrożyć nakazowe podejmowanie decyzji dotyczących sposobu uwzględnienia nastrojów klienta. Aby móc to robić na dużą skalę, przy podejmowaniu decyzji należy korzystać z usług AI/ML. Poniższy diagram ilustruje architekturę aktywowania spostrzeżeń przy użyciu uczenia maszynowego na potrzeby analiz preskryptywnych i usług AI na potrzeby targetowania i segmentacji.
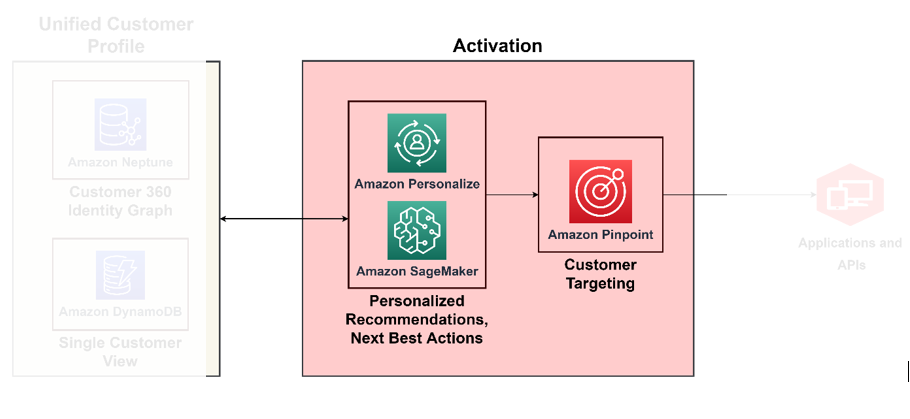
Użyj ML jako mechanizmu decyzyjnego
Dzięki ML możesz poprawić ogólną jakość obsługi klienta — możesz tworzyć predykcyjne modele zachowań klientów, projektować hiperspersonalizowane oferty i kierować reklamy do odpowiedniego klienta z odpowiednią zachętą. Możesz je zbudować za pomocą Amazon Sage Maker, który obejmuje pakiet usług zarządzanych mapowanych na cykl życia nauki o danych, w tym zarządzanie danymi, trenowanie modeli, hosting modeli, wnioskowanie o modelach, wykrywanie dryftu modelu i przechowywanie funkcji. Dzięki SageMaker możesz to zrobić buduj i wdrażaj modele uczenia maszynowego, wprowadzając je z powrotem do aplikacji, aby zapewnić właściwą wiedzę właściwej osobie we właściwym czasie.
Amazon Personalizuj obsługuje rekomendacje kontekstowe, dzięki którym możesz poprawić trafność rekomendacji, generując je w kontekście – na przykład typu urządzenia, lokalizacji lub pory dnia. Twój zespół może rozpocząć pracę bez wcześniejszego doświadczenia w zakresie uczenia maszynowego, korzystając z interfejsów API w celu tworzenia zaawansowanych możliwości personalizacji za pomocą kilku kliknięć. Aby uzyskać więcej informacji, zobacz Dostosuj swoje rekomendacje, promując określone produkty za pomocą reguł biznesowych z Amazon Personalizuj.
Aktywuj kanały marketingu, reklamy, sprzedaży bezpośredniej i lojalności
Teraz, gdy wiesz, kim są Twoi klienci i do kogo się zwrócić, możesz opracować rozwiązania umożliwiające prowadzenie kampanii targetowanych na dużą skalę. Z Amazonka Wskażmożesz personalizować i segmentować komunikację, aby angażować klientów wieloma kanałami. Możesz na przykład użyć Amazon Pinpoint do budować angażujące doświadczenia klientów za pośrednictwem różnych kanałów komunikacji, takich jak e-mail, SMS, powiadomienia push i powiadomienia w aplikacji.
Filar 5: Zarządzanie danymi
Ustanowienie odpowiedniego zarządzania, które równoważy kontrolę i dostęp, zapewnia użytkownikom zaufanie do danych. Wyobraź sobie oferowanie promocji na produkty, których klient nie potrzebuje, lub bombardowanie niewłaściwych klientów powiadomieniami. Zła jakość danych może prowadzić do takich sytuacji i ostatecznie skutkować odejściem klientów. Musisz zbudować procesy, które weryfikują jakość danych i podejmują działania naprawcze. Jakość danych kleju AWS może pomóc w budowaniu rozwiązań sprawdzających jakość danych w stanie spoczynku i podczas przesyłania, w oparciu o predefiniowane reguły.
Aby skonfigurować wielofunkcyjną strukturę zarządzania danymi klientów, potrzebujesz możliwości zarządzania danymi i udostępniania ich w całej organizacji. Z Strefa danych Amazonaadministratorzy i stewardowie danych mogą zarządzać dostępem do danych i zarządzać dostępem do nich, a konsumenci, tacy jak inżynierowie danych, badacze danych, menedżerowie produktów, analitycy i inni użytkownicy biznesowi, mogą odkrywać te dane, wykorzystywać je i współpracować z nimi w celu uzyskania wglądu. Usprawnia dostęp do danych, umożliwiając wyszukiwanie i wykorzystywanie danych klientów, promuje współpracę zespołową dzięki udostępnionym zasobom danych i zapewnia spersonalizowaną analizę za pośrednictwem aplikacji internetowej lub interfejsu API w portalu. Formacja AWS Lake zapewnia bezpieczny dostęp do danych, gwarantując, że właściwe osoby zobaczą właściwe dane z właściwych powodów, co ma kluczowe znaczenie dla skutecznego zarządzania międzyfunkcyjnego w każdej organizacji. Metadane biznesowe są przechowywane i zarządzane przez Amazon DataZone, w oparciu o metadane techniczne i informacje o schemacie, które są zarejestrowane w Katalog danych kleju AWS. Te metadane techniczne są również wykorzystywane zarówno przez inne usługi zarządzania, takie jak Lake Formation i Amazon DataZone, jak i usługi analityczne, takie jak Amazon Redshift, Athena i AWS Glue.

Dostosowanie to wszystko razem
Korzystając z poniższego diagramu jako odniesienia, możesz tworzyć projekty i zespoły w celu budowania i obsługi różnych możliwości. Na przykład zespół zajmujący się integracją danych może skupić się na filarze gromadzenia danych — można następnie dopasować role funkcjonalne, takie jak architekci i inżynierowie danych. Możesz zbudować swoje praktyki analityczne i analityki danych, aby skupić się odpowiednio na filarach analitycznych i aktywacyjnych. Można wtedy stworzyć wyspecjalizowany zespół do przetwarzania tożsamości klienta i budowania jednolitego spojrzenia na klienta. Możesz utworzyć zespół ds. zarządzania danymi, składający się ze stewardów danych z różnych funkcji, administratorów bezpieczeństwa i decydentów ds. zarządzania danymi, aby projektować i automatyzować zasady.
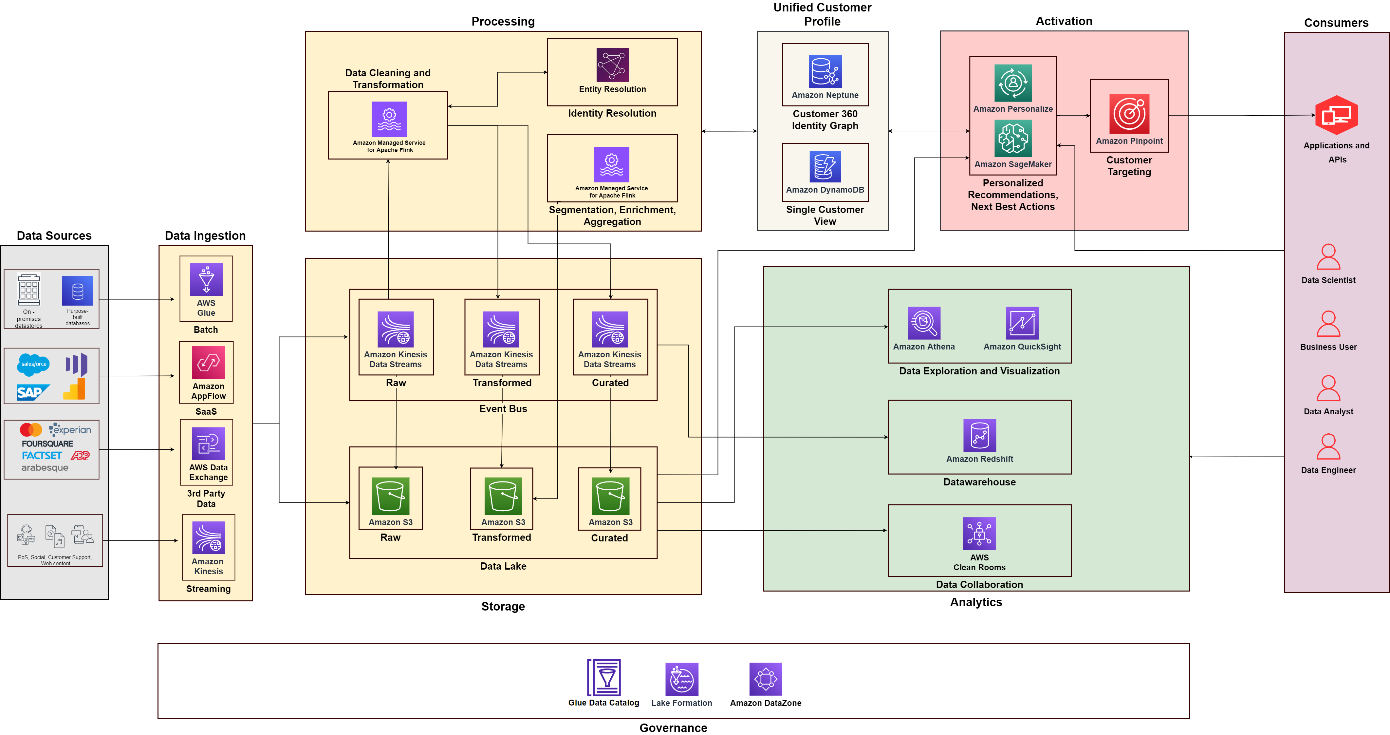
Wnioski
Budowanie solidnych możliwości platformy C360 ma kluczowe znaczenie dla uzyskania przez Twoją organizację wglądu w bazę klientów. Bazy danych AWS, usługi analityczne i AI/ML mogą pomóc usprawnić ten proces, zapewniając skalowalność i wydajność. Kierując się pięcioma filarami, które kierują Twoim myśleniem, możesz zbudować kompleksową strategię dotyczącą danych, która definiuje widok C360 w całej organizacji, zapewnia dokładność danych i ustanawia wielofunkcyjne zarządzanie danymi klientów. Możesz kategoryzować i ustalać priorytety produktów i funkcji, które musisz zbudować w ramach każdego filaru, wybrać odpowiednie narzędzie do zadania i budować umiejętności potrzebne w swoich zespołach.
Odwiedzić AWS dla historii klientów związanych z danymi aby dowiedzieć się, jak AWS zmienia podróż klientów, od największych przedsiębiorstw na świecie po rozwijające się start-upy.
O autorach
 Ismaila Makhloufa jest starszym specjalistą ds. rozwiązań architektonicznych w zakresie analizy danych w AWS. Ismail koncentruje się na projektowaniu rozwiązań dla organizacji w zakresie kompleksowej analizy danych, w tym przesyłania strumieniowego wsadowego i w czasie rzeczywistym, dużych zbiorów danych, hurtowni danych i obciążeń typu jezioro danych. Współpracuje przede wszystkim z organizacjami z branży handlu detalicznego, e-commerce, FinTech, HealthTech i podróży, aby osiągnąć ich cele biznesowe dzięki dobrze zaprojektowanym platformom danych.
Ismaila Makhloufa jest starszym specjalistą ds. rozwiązań architektonicznych w zakresie analizy danych w AWS. Ismail koncentruje się na projektowaniu rozwiązań dla organizacji w zakresie kompleksowej analizy danych, w tym przesyłania strumieniowego wsadowego i w czasie rzeczywistym, dużych zbiorów danych, hurtowni danych i obciążeń typu jezioro danych. Współpracuje przede wszystkim z organizacjami z branży handlu detalicznego, e-commerce, FinTech, HealthTech i podróży, aby osiągnąć ich cele biznesowe dzięki dobrze zaprojektowanym platformom danych.
 Sandipana Bhaumika (Sandi) jest starszym specjalistą ds. analityki i architektem rozwiązań w AWS. Pomaga klientom modernizować platformy danych w chmurze, aby bezpiecznie przeprowadzać analizy na dużą skalę, zmniejszać koszty operacyjne i optymalizować wykorzystanie pod kątem opłacalności i zrównoważonego rozwoju.
Sandipana Bhaumika (Sandi) jest starszym specjalistą ds. analityki i architektem rozwiązań w AWS. Pomaga klientom modernizować platformy danych w chmurze, aby bezpiecznie przeprowadzać analizy na dużą skalę, zmniejszać koszty operacyjne i optymalizować wykorzystanie pod kątem opłacalności i zrównoważonego rozwoju.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

