Introduksjon
Dataintegrasjonsteknikkene ETL (Extract, Transform, Load) og ELT pipelines (Extract, Load, Transform) brukes begge til å overføre data fra ett system til et annet.
Informasjonen hentes fra én eller flere datakilder, transformeres til et målsystemkompatibelt format og lastes deretter inn i målsystemet som en del av ETL-prosessen. Et ETL-verktøy eller plattform som organiserer prosessen gjør ofte denne oppgaven. For å møte behovene til målsystemet, må data renses, valideres, integreres og forbedres under transformasjonsstadiet.
ELT-rørledningen innebærer på den annen side å fjerne data fra en eller flere datakilder, bringe dem inn i destinasjonssystemet og deretter endre dem der. Databaseadministrasjonsløsninger som kan behandle store datamengder, som SQL eller Apache Spark, kan brukes til denne operasjonen. Denne metoden er fordelaktig når datakilden må beholdes i sitt opprinnelige format, og målsystemet kan gjøre de nødvendige transformasjonene.
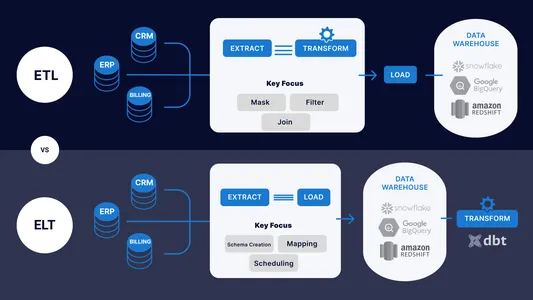
ETL og ELT rørledninger integrere data fra ulike systemer, inkludert databaser, applikasjoner og filer, for å generere en konsistent og enhetlig oversikt over dataene for analyse, rapportering og beslutningstaking.
Læringsmål
Ved slutten av denne artikkelen vil du kunne lære forskjellene mellom ETL og ELT Pipelines, deres fordeler og ulemper, og deres anvendelse i forskjellige tilfeller som Data Warehousing, Business Intelligence, Data Integration, etc. Man vil også lære om noen metoder for å designe vellykkede ETL/ELT-rørledninger, hvordan verktøy som Talend, Apache Nifi, Apache Spark osv. kan brukes, og hvilke strategier for overvåking og feilsøking som kan brukes for ETL- og ELT-pipeline.
Innholdsfortegnelse
Forskjeller mellom ETL- og ELT-rørledninger
| ETL (UTTREKK, TRANSFORMASJON OG LAST) | ELT (UTTREKK, LAST OG TRANSFORMASJON) |
| Informasjonen trekkes først ut fra kildesystemer, konverteres til et format som målsystemet kan bruke, og settes deretter inn i målsystemet. | Informasjonen lastes først data inn i destinasjonssystemet før de nødvendige endringer gjøres i dataene der. |
| ETL-rørledninger kan være mer nyttige når data må transformeres til et format som målsystemet ikke støtter. Dette fører til lang konverteringstid og mer maskinvare. | ELT fungerer ved å dele opp arbeidet i mindre partier og bruke parallell prosessering, og fungerer dermed raskere. |
| Skalerbarheten til ETL kan begrenses fordi den endrer data før den settes inn i et målsystem. | De er mer skalerbare ettersom det innebærer å laste data inn i et målsystem, som deretter transformeres ved hjelp av distribuerte dataverktøy som Hadoop eller Spark. |
| De er vanligvis enklere å vedlikeholde ettersom det muliggjør større kontroll over datakonsistens og kvalitet, noe som kan bidra til å redusere sjansen for feil og gjøre vedlikehold av rørledninger enklere over tid. | Når du bruker ELT-rørledninger, kan det være mer utfordrende å hjelpe til med å finne problemer og vedlikeholde rørledningen fordi data lastes inn i målsystemet før de transformeres. |
| Den bruker rimeligere enn proprietære ETL-systemer, som Hadoop og Spark, som bidrar til å redusere prosesseringskostnadene. | De er dyrere når det gjelder kostnader da den bruker åpen kildekode-teknologi. |
Avslutningsvis er valget mellom ETL- og ELT-rørledninger basert på de spesielle kravene til dataintegrasjonsprosjektet, slik som funksjonene til kilde- og målsystemene, datavolumet og kompleksiteten og kravene til ytelse og skalerbarhet.
Fordeler og ulemper med ETL- og ELT-rørledninger
I enkelt og tydelig språk er fordelene og ulempene med ETL- og ELT-rørledninger for ulike brukstilfeller som følger:
Fordeler med ETL
- Når informasjon må konverteres til et format som målsystemet ikke støtter, er ETL nyttig.
- ETL kan kombinere data fra mange kilder til ett enkelt bilde for evaluering og beslutningstaking.
- ETL-rørledninger kan fås til å kjøre mer effektivt ved å bruke batch- og parallellbehandling.
Begrensninger for ETL
- ETL kan være arbeidskrevende og kreve mye maskinvareressurser, spesielt for sofistikerte transformasjoner og betydelige datavolumer.
- For å skape og anvende transformasjonslogikken kan ETL trenge spesialisttalenter.
- Fra det tidspunktet informasjonen samles inn og den er tilgjengelig for analyse, kan ETL-prosesser forårsake forsinkelser.
Fordeler med ELT
- Når målsystemet kan håndtere og transformere dataene i sitt opprinnelige format, kan ELT utføres mer effektivt og raskere.
- Når data må beholdes i sin opprinnelige form og bare endres for analyse og rapportering, er ELT nyttig.
- ELT kan bruke fleksibiliteten og datakapasiteten til moderne databasebehandlingssystemer.
Begrensninger for ELT
- Før du utfører transformasjoner, kan ELT trenge mye lagringsplass for å beholde dataene.
- Å skrive kompliserte SQL-spørringer kan kreve detaljert informasjon for datatransformasjoner ved bruk av ELT.
- Målsystemet kan bli mer komplekst på grunn av ELT, noe som gjør vedlikehold og vedlikehold vanskeligere.
Anvendelse av ETL Pipelines
Applikasjoner for datavarehus og dataanalyse bruker ofte ETL rørledninger. På enkelt og tydelig språk er følgende brukstilfeller for ETL-rørledninger:
- Datavarehus: I et datavarehus kombinerer ETL data fra flere kilder til en enhetlig visning. Dataene renses, settes inn i et standardformat og sjekkes for å garantere kvalitet og konsistens. ETL laster ofte data inn i datavarehuset for å opprettholde dataene oppdatert.
- Business Intelligence: ETL trekker ut informasjon fra transaksjonssystemer og laster den inn i et datavarehus eller datamarked i business intelligence-applikasjoner. For å muliggjøre rapportering og analyse, transformeres og konsolideres informasjonen. Innsamling, behandling og lasting av data i rapporteringssystemet er automatisert og planlagt ved hjelp av ETL.
- Dataintegrasjon: For å kombinere informasjon fra forskjellige kilder til et enkelt system, brukes ETL. Et eksempel er datafusjon fra mange databaser, regneark og filer. ETL brukes for å sikre at data er nøyaktige og enhetlige og for å endre dataene til et format som destinasjonssystemet kan bruke.
- Datamigrering: For å overføre informasjon fra ett system til et annet, brukes ETL i datamigrasjonsprosjekter. Dette kan innebære dataoverføringer fra et utdatert system til et nytt eller å kombinere data fra ulike systemer. ETL brukes under migreringsprosessen for å transformere og sjekke informasjonen.
Anvendelse av ELT-rørledninger
ELT (Extract, Load, Transform) prosesser er mye brukt i databehandling og analyse for å forberede store mengder data for senere bruk. Følgende er noen forenklede brukstilfeller:
- Datavarehus: ELT-rørledninger brukes ofte i datavarehus for å trekke ut data fra ulike kilder, inkludert databaser, skylagring og online APIer. Etter å ha blitt transformert legges dataene inn i et databasesystem for ytterligere analyse.
- Stordatabehandling: Å analysere enorme mengder data, inkludert slike datastrømmer eller loggfiler, bruker spesielt ELT-rørledninger. Informasjonen hentes først og plasseres i en distribuert database, slik som Hadoop, før den parallelliseres med blant annet Spark eller Hive.
- Maskinlæring: Databehandling for maskinlæringsapplikasjoner kan gjøres via ELT-rørledninger. For å gjøre dette må data samles inn fra ulike kilder, ryddes opp og transformeres for å være klare for modellering, og deretter lastes inn i et rammeverk for maskinlæring som TensorFlow eller PyTorch.
- Business Intelligence: For å gi dashbord og rapporter for forretningsbrukere, kan ELT-pipelines samle inn og transformere data fra ulike kilder, inkludert kundedata, salgsdata og nettanalyse.
Teknikker for å designe en effektiv ETL- eller ELT-rørledning
Utvinning, last og transformering, eller ETL, rørledningsdesign sikrer at databehandlingsoppgaver fullføres raskt og nøyaktig. Følgende er noen metoder for å designe vellykkede ETL/ELT-rørledninger:
- Datapartisjonering: Datapartisjonering deler store datasett i mer håndterbare deler for parallell behandling. Ved å begrense mengden data som må behandles på en gang, kan partisjonering bidra til å øke hastigheten og effektiviteten til databehandlingen.
- Data rensing: Datarensing innebærer å lokalisere og løse feil eller inkonsekvenser i dataene. Teknikker for rengjøring av data kan innebære
- Sletting av duplikat eller irrelevant informasjon
- Korrigere stave- eller grammatiske problemer
- Sikre datakonsistens på tvers av ulike kilder
- Datatransformasjon: Datatransformasjon er å endre formatet eller organiseringen av data. Varierende datatyper, kombinering eller sammenslåing av databaser og innsamling eller evaluering av informasjon er noen eksempler på datatransformasjonsprosedyrer.
- Inkrementell lasting: Ved å bruke total lasting behandles bare dataene som er endret eller lagt til siden forrige behandlingskjøring. Spesielt for store datasett kan inkrementell lasting hjelpe til med å redusere mengden tid og ressurser som kreves for databehandling.
- Jobbplanlegging: Basert på variabler, inkludert tilgjengelige data, behandlingstid og tilgjengelige ressurser, innebærer denne prosessen å lage en effektiv tidsplan for å utføre ETL/ELT-prosesser. Et effektivt program kan forkorte den totale behandlingstiden, og garantere rettidig og korrekt databehandling.
Programvare kalt ETL- og ELT-verktøy brukes til dataintegrasjon, prosessering og transformasjon. Følgende er en forenklet sammenligning av noen velkjente ETL- og ELT-verktøy:
- Talent: Talend er en åpen kildekode-dataintegrerings- og transformasjonsplattform som tilbyr en rekke koblinger og elementer for datatransformasjon. Det gir et enkelt brukergrensesnitt og støtter både dra-og-slipp- og programmeringsmetoder. Den gir muligheter som er relevante for utvikling og informasjonskvalitetskontroller og støtter batch- og sanntidsbehandling.
- Informatikk: En avansert analytisk integrasjon og transformasjonsoperasjon kan støttes av det kommersielle ETL-produktet Informatica. Det gir en visuell utviklingsplattform og mange koblinger for forskjellige datakilder. Coherence tilbyr funksjoner som datastyring, datamanipulering og dataintegritet.
- Apache NiFi: Apache NiFi er et åpen kildekode ELT-verktøy for dataflytstyring kalt Apache NiFi. Den inkluderer en rekke datainntaks-, transformasjons- og rutingprosessorer og tilbyr et nettbasert brukergrensesnitt. Dataopprinnelse og avstamningsegenskaper leveres av Apache NiFi, som også tilbyr sanntids databehandling.
- Apache Spark: ETL og ELT kan utføres ved hjelp av Apache Spark, en åpen og distribuert datateknologi. Den tillater bulk og faktisk databehandling og tilbyr rask databehandling. Spark tilbyr maskinlæring, grafanalyse og kringkastingsfunksjoner og støtter ulike programmeringsspråk.
Rollen til dataintegrasjon og datakvalitet
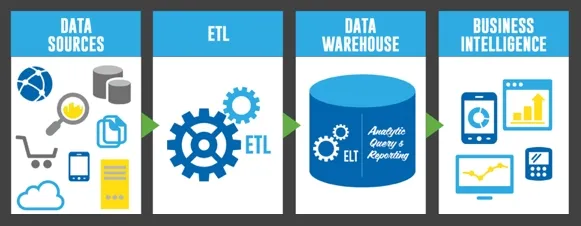
Å kombinere data fra flere kilder for å gi et enhetlig bilde av dataene er kjent som dataintegrasjon. Data fra mange kilder kobles sammen ved hjelp av ETL (Extract, Transform, Load) og ELT (Extract, Load, Transform) rørledninger for å lage et datavarehus eller datainnsjø.
Kvaliteten på dataene måler datanøyaktighet, helhet, konsistens og validitet. Datakvalitet er avgjørende for å sette ETL- og ELT-rørledninger for å garantere at de integrerte dataene er trygge og praktiske.
For å si det på en annen måte, er datakvalitet som å bekrefte at puslespillet passer sammen og ikke er skadet eller mangler. Derimot er dataintegrasjon som å gjøre delene av et puslespill sammen for å se hele bildet. Prosessene som setter sammen puslespillet og sikrer at de er orientert og plassert i riktig rekkefølge er kjent som ETL- og ELT-rørledninger.
Strategier for overvåking og feilsøking
Det er viktig å spore og fikse problemer med ETL (Extract, Transform, Load) og ELT (Extract, Load, Transform) rørledninger for å garantere effektiv og effektiv drift av dataintegrasjonsprosessen. Her er noen metoder for å holde øye med ting og feilsøke:
- Problemer med tidlig varsling: Sett opp advarsler og meldinger for å motta varsler når en pipeline svikter eller støter på problemer. Dette gjør at du kan løse problemer så snart de oppstår og løse dem før de forverres.
- Overvåk pipelineytelse: Overvåking av pipelineytelse innebærer å holde oversikt over parametere, inkludert databehandlingstid, dataoverføringshastigheter og ressursbruk. Dette kan hjelpe til med rørledningsoptimalisering og oppdagelse av hindringer.
- Logg rørledningsaktiviteter: Logg rørledningsoperasjoner for å spore utvikling av dataintegrering og identifisere problemer eller feil. Dessuten kan logger brukes til overholdelse og revisjonsformål.
- Gjennomfør regelmessige tester: Test regelmessig for å sikre at rørledningen fungerer som den skal. Dette kan hjelpe deg med å oppdage problemer før de blir dyre nedetid.
- Samarbeide med interessenter: Arbeid sammen med interessenter: For å finne og fikse problemer, arbeid sammen med interessenter som datavitere, ingeniører og forretningsbrukere. Du kan løse problemer og korrekt forstå informasjonshåndteringsprosessen som et resultat.
konklusjonen
Et prosjekts spesielle krav og krav vil avgjøre om det skal brukes ETL eller ETL pipeline. ETL fungerer godt for småskalaprosjekter som krever manuell tilpasning og intervensjon i hvert arbeidsflytstadium. På den annen side er en ETL-pipeline bedre egnet til massive prosjekter med enorme mengder data som trenger automatisering og standardisering for å sikre korrekthet og effektivitet.
Avslutningsvis er ETL og ETL pipeline to relaterte, men distinkte konsepter. En ETL-pipeline er en automatisert arbeidsflyt som kontrollerer hele ETL-prosessen fra begynnelse til slutt. ETL er en tre-trinns dataintegrasjonsprosess. Prosjektets størrelse, kompleksitet og etterspørsel etter tilpasning og automatisering vil avgjøre det beste alternativet.

Nøkkelfunksjoner
- Innledningsvis har vi sett en oversikt over forskjellene mellom ETL- og ELT-rørledninger, inkludert databehandlingsrekkefølge og ytelsesimplikasjoner.
- Og deretter forstå fordelene og ulempene med ETL- og ELT-rørledninger for forskjellige brukstilfeller.
- Teknikkene for å designe en effektiv ETL- eller ELT-pipeline inkluderer også datapartisjonering, datarensing og datatransformasjon.
- Sammenligning av populære ETL- og ELT-verktøy, inkludert Talend, Informatica, Apache NiFi og Apache Spark.
- Forstå rollen til dataintegrasjon og datakvalitet i ETL- og ELT-rørledninger.
- Strategier for overvåking og feilsøking av ETL- og ELT-rørledninger og sammenligning av begge.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/03/difference-between-etl-and-elt-pipelines/

