I dag er vi glade for å kunngjøre tilgjengeligheten av Llama 2-inferens og finjusteringsstøtte på AWS Trainium og AWS slutning tilfeller i Amazon SageMaker JumpStart. Å bruke AWS Trainium- og Inferentia-baserte forekomster, gjennom SageMaker, kan hjelpe brukere med å redusere finjusteringskostnadene med opptil 50 %, og redusere distribusjonskostnadene med 4.7 ganger, samtidig som forsinkelsen per token reduseres. Llama 2 er en autoregressiv generativ tekstspråkmodell som bruker en optimert transformatorarkitektur. Som en offentlig tilgjengelig modell er Llama 2 designet for mange NLP-oppgaver som tekstklassifisering, sentimentanalyse, språkoversettelse, språkmodellering, tekstgenerering og dialogsystemer. Finjustering og distribusjon av LLM-er, som Llama 2, kan bli kostbart eller utfordrende for å møte sanntidsytelse for å levere god kundeopplevelse. Trainium og AWS Inferentia, aktivert av AWS nevron programvareutviklingssett (SDK), tilbyr et høyytelses og kostnadseffektivt alternativ for opplæring og konklusjon av Llama 2-modeller.
I dette innlegget viser vi hvordan du distribuerer og finjusterer Llama 2 på Trainium- og AWS Inferentia-forekomster i SageMaker JumpStart.
Løsningsoversikt
I denne bloggen vil vi gå gjennom følgende scenarier:
- Distribuer Llama 2 på AWS Inferentia-forekomster i begge Amazon SageMaker Studio UI, med en ett-klikks distribusjonsopplevelse, og SageMaker Python SDK.
- Finjuster Llama 2 på Trainium-forekomster i både SageMaker Studio UI og SageMaker Python SDK.
- Sammenlign ytelsen til den finjusterte Llama 2-modellen med den til den forhåndstrente modellen for å vise effektiviteten av finjustering.
For å få hendene på, se GitHub eksempel notatbok.
Distribuer Llama 2 på AWS Inferentia-forekomster ved å bruke SageMaker Studio UI og Python SDK
I denne delen demonstrerer vi hvordan du distribuerer Llama 2 på AWS Inferentia-forekomster ved å bruke SageMaker Studio UI for en ett-klikks-distribusjon og Python SDK.
Oppdag Llama 2-modellen på SageMaker Studio UI
SageMaker JumpStart gir tilgang til både offentlig tilgjengelig og proprietær grunnmodeller. Foundation-modeller er ombord og vedlikeholdt fra tredjeparts og proprietære leverandører. Som sådan utgis de under forskjellige lisenser som angitt av modellkilden. Pass på å se gjennom lisensen for alle grunnmodeller du bruker. Du er ansvarlig for å gjennomgå og overholde alle gjeldende lisensvilkår og sørge for at de er akseptable for din brukssituasjon før du laster ned eller bruker innholdet.
Du kan få tilgang til Llama 2-grunnmodellene gjennom SageMaker JumpStart i SageMaker Studio UI og SageMaker Python SDK. I denne delen går vi gjennom hvordan du oppdager modellene i SageMaker Studio.
SageMaker Studio er et integrert utviklingsmiljø (IDE) som gir et enkelt nettbasert visuelt grensesnitt der du kan få tilgang til spesialbygde verktøy for å utføre alle utviklingstrinn for maskinlæring (ML), fra å forberede data til å bygge, trene og distribuere ML-en din. modeller. For mer informasjon om hvordan du kommer i gang og konfigurerer SageMaker Studio, se Amazon SageMaker Studio.
Etter at du er i SageMaker Studio, kan du få tilgang til SageMaker JumpStart, som inneholder ferdigtrente modeller, bærbare datamaskiner og forhåndsbygde løsninger, under Forhåndsbygde og automatiserte løsninger. For mer detaljert informasjon om hvordan du får tilgang til proprietære modeller, se Bruk proprietære grunnmodeller fra Amazon SageMaker JumpStart i Amazon SageMaker Studio.

Fra SageMaker JumpStart-landingssiden kan du søke etter løsninger, modeller, notatbøker og andre ressurser.
Hvis du ikke ser Llama 2-modellene, oppdater SageMaker Studio-versjonen din ved å slå av og starte på nytt. For mer informasjon om versjonsoppdateringer, se Slå av og oppdater Studio Classic-apper.
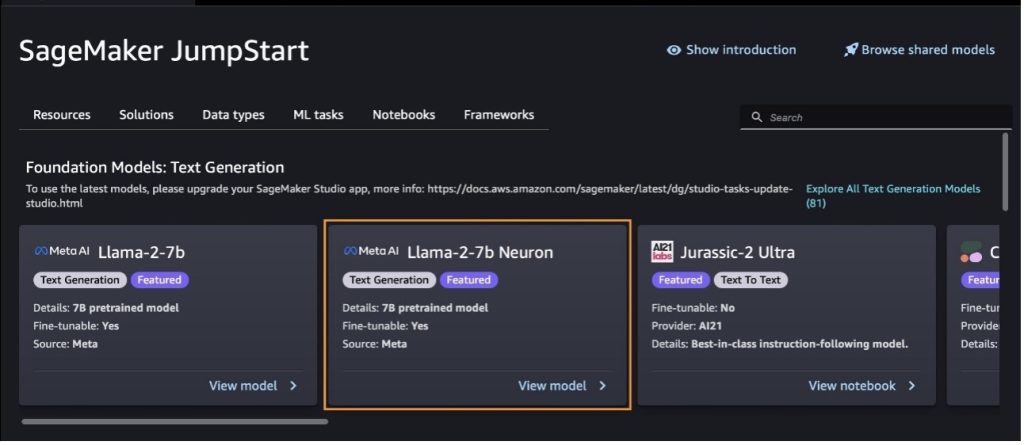
Du kan også finne andre modellvarianter ved å velge Utforsk alle tekstgenerasjonsmodeller eller søker etter llama or neuron i søkefeltet. Du vil kunne se Llama 2 Neuron-modellene på denne siden.

Distribuer Llama-2-13b-modellen med SageMaker Jumpstart
Du kan velge modellkortet for å se detaljer om modellen, for eksempel lisens, data som brukes til å trene, og hvordan du bruker den. Du kan også finne to knapper, Distribuer og Åpne notatboken, som hjelper deg med å bruke modellen ved å bruke dette eksemplet uten kode.
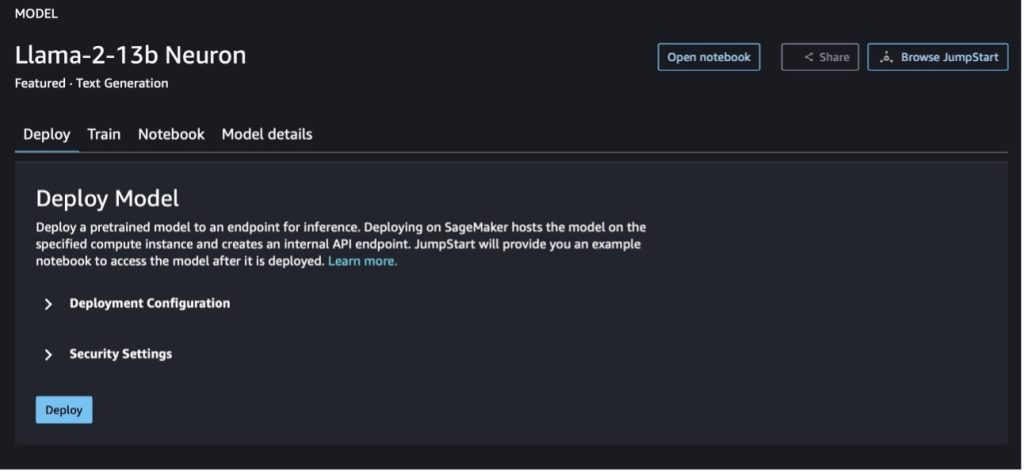
Når du velger en av knappene, vil et popup-vindu vise sluttbrukerlisensavtalen og retningslinjene for akseptabel bruk (AUP) som du kan bekrefte.
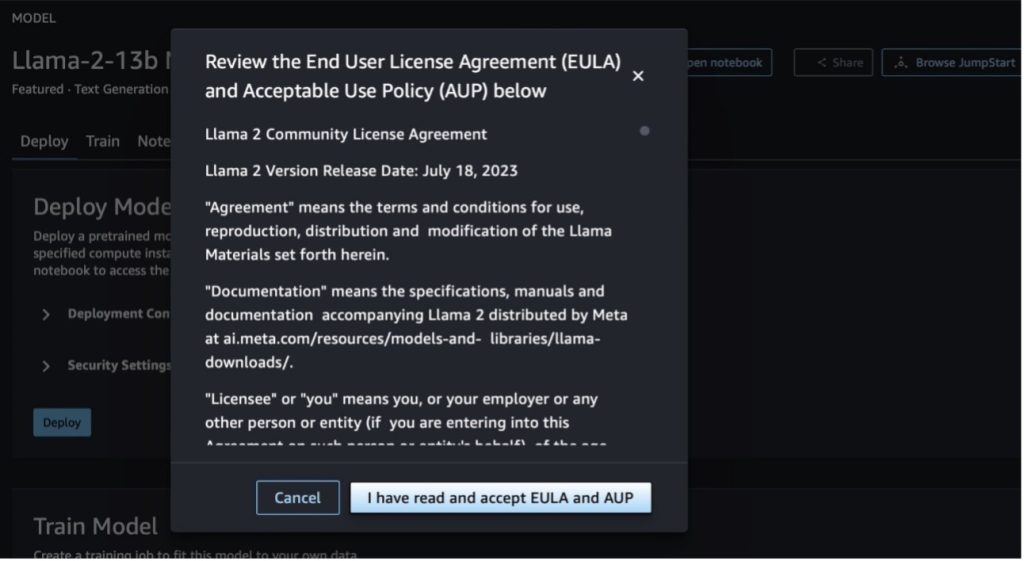
Etter at du har anerkjent retningslinjene, kan du distribuere endepunktet til modellen og bruke den via trinnene i neste avsnitt.
Distribuer Llama 2 Neuron-modellen via Python SDK
Når du velger Distribuer og godkjenne vilkårene, vil modellimplementeringen starte. Alternativt kan du distribuere gjennom eksempelnotisboken ved å velge Åpne notatboken. Eksempelnotisboken gir ende-til-ende veiledning om hvordan du kan distribuere modellen for slutninger og rydde opp i ressurser.
For å distribuere eller finjustere en modell på Trainium- eller AWS Inferentia-forekomster, må du først ringe PyTorch Neuron (fakkel-nevronx) for å kompilere modellen til en Neuron-spesifikk graf, som vil optimalisere den for Inferentias NeuronCores. Brukere kan instruere kompilatoren til å optimalisere for lavest ventetid eller høyest gjennomstrømning, avhengig av formålet med applikasjonen. I JumpStart forhåndskompilerte vi Neuron-grafene for en rekke konfigurasjoner, slik at brukere kan nippe til kompileringstrinn, noe som muliggjør raskere finjustering og distribusjon av modeller.
Merk at den forhåndskompilerte Neuron-grafen er laget basert på en spesifikk versjon av Neuron Compiler-versjonen.
Det er to måter å distribuere LIama 2 på AWS Inferentia-baserte forekomster. Den første metoden bruker den forhåndsbygde konfigurasjonen, og lar deg distribuere modellen på bare to linjer med kode. I den andre har du større kontroll over konfigurasjonen. La oss starte med den første metoden, med den forhåndsbygde konfigurasjonen, og bruke den forhåndstrente Llama 2 13B Neuron Model, som et eksempel. Følgende kode viser hvordan du distribuerer Llama 13B med bare to linjer:
For å utføre slutninger på disse modellene, må du spesifisere argumentet accept_eula å være True som en del av model.deploy() anrop. Ved å sette dette argumentet til å være sant, erkjenner du at du har lest og godtatt EULA for modellen. EULA finner du i modellkortets beskrivelse eller fra Meta nettsted.
Standard forekomsttype for Llama 2 13B er ml.inf2.8xlarge. Du kan også prøve andre støttede modell-ID-er:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(chatmodell)meta-textgenerationneuron-llama-2-13b-f(chatmodell)
Alternativt, hvis du vil ha mer kontroll over distribusjonskonfigurasjonene, som kontekstlengde, tensorparallellgrad og maksimal rullende batchstørrelse, kan du endre dem via miljøvariabler, som vist i denne delen. Den underliggende Deep Learning Container (DLC) for distribusjonen er Large Model Inference (LMI) NeuronX DLC. Miljøvariablene er som følger:
- OPTION_N_POSITIONS – Maksimalt antall input- og output-tokens. For eksempel hvis du kompilerer modellen med
OPTION_N_POSITIONSsom 512, så kan du bruke et input-token på 128 (input prompt-størrelse) med et maksimalt output-token på 384 (totalen av input og output tokens må være 512). For det maksimale utdata-tokenet er enhver verdi under 384 greit, men du kan ikke gå utover det (for eksempel input 256 og output 512). - OPTION_TENSOR_PARALLEL_DEGREE – Antall NeuronCores for å laste modellen i AWS Inferentia-forekomster.
- OPTION_MAX_ROLLING_BATCH_SIZE – Maksimal batchstørrelse for samtidige forespørsler.
- OPTION_DTYPE – Datotypen for å laste modellen.
Sammenstillingen av Neuron-grafen avhenger av kontekstlengden (OPTION_N_POSITIONS), tensor parallell grad (OPTION_TENSOR_PARALLEL_DEGREE), maksimal batchstørrelse (OPTION_MAX_ROLLING_BATCH_SIZE), og datatype (OPTION_DTYPE) for å laste modellen. SageMaker JumpStart har forhåndskompilert nevrongrafer for en rekke konfigurasjoner for de foregående parameterne for å unngå kompilering under kjøretid. Konfigurasjonene til forhåndskompilerte grafer er oppført i tabellen nedenfor. Så lenge miljøvariablene faller inn i en av følgende kategorier, vil kompilering av nevrongrafer hoppes over.
| LIama-2 7B og LIama-2 7B Chat | ||||
| Forekomsttype | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B og LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Følgende er et eksempel på distribusjon av Llama 2 13B og innstilling av alle tilgjengelige konfigurasjoner.
Nå som vi har distribuert Llama-2-13b-modellen, kan vi kjøre inferens med den ved å påkalle endepunktet. Følgende kodebit demonstrerer bruk av støttede slutningsparametere for å kontrollere tekstgenerering:
- maks lengde – Modellen genererer tekst til utdatalengden (som inkluderer inndatakontekstlengden) når
max_length. Hvis det er spesifisert, må det være et positivt heltall. - max_new_tokens – Modellen genererer tekst til utdatalengden (ekskludert inndatakontekstlengden) når
max_new_tokens. Hvis det er spesifisert, må det være et positivt heltall. - antall_bjelker – Dette indikerer antall stråler som brukes i det grådige søket. Hvis spesifisert, må det være et heltall større enn eller lik
num_return_sequences. - no_repeat_ngram_size – Modellen sikrer at en sekvens av ord av
no_repeat_ngram_sizegjentas ikke i utgangssekvensen. Hvis det er spesifisert, må det være et positivt heltall større enn 1. - temperatur – Dette kontrollerer tilfeldigheten i utgangen. En høyere temperatur resulterer i en utgangssekvens med ord med lav sannsynlighet; en lavere temperatur resulterer i en utgangssekvens med høysannsynlighetsord. Hvis
temperaturelik 0, resulterer det i grådig dekoding. Hvis spesifisert, må det være en positiv flyte. - tidlig_stopping - Hvis
True, er tekstgenereringen fullført når alle strålehypotesene når slutten av setningstokenet. Hvis det er spesifisert, må det være boolsk. - do_sample - Hvis
True, modellen prøver neste ord i henhold til sannsynligheten. Hvis det er spesifisert, må det være boolsk. - topp_k – I hvert trinn av tekstgenerering prøver modellen kun fra
top_kmest sannsynlige ord. Hvis det er spesifisert, må det være et positivt heltall. - topp_s – I hvert trinn av tekstgenerering prøver modellen fra det minste mulige settet med ord med en kumulativ sannsynlighet for
top_p. Hvis spesifisert, må det være en flyte mellom 0–1. - stoppe – Hvis det er spesifisert, må det være en liste over strenger. Tekstgenerering stopper hvis en av de angitte strengene genereres.
Følgende kode viser et eksempel:
Produksjon:
For mer informasjon om parametrene i nyttelasten, se detaljerte parametere.
Du kan også utforske implementeringen av parametrene i bærbare for å legge til mer informasjon om koblingen til notatboken.
Finjuster Llama 2-modeller på Trainium-forekomster ved å bruke SageMaker Studio UI og SageMaker Python SDK
Generative AI-fundamentmodeller har blitt et hovedfokus i ML og AI, men deres brede generalisering kan komme til kort i spesifikke domener som helsetjenester eller finansielle tjenester, der unike datasett er involvert. Denne begrensningen fremhever behovet for å finjustere disse generative AI-modellene med domenespesifikke data for å forbedre ytelsen på disse spesialiserte områdene.
Nå som vi har distribuert den ferdigtrente versjonen av Llama 2-modellen, la oss se på hvordan vi kan finjustere denne til domenespesifikke data for å øke nøyaktigheten, forbedre modellen når det gjelder raske fullføringer, og tilpasse modellen til din spesifikke forretningsbruk og data. Du kan finjustere modellene ved å bruke enten SageMaker Studio UI eller SageMaker Python SDK. Vi diskuterer begge metodene i denne delen.
Finjuster Llama-2-13b Neuron-modellen med SageMaker Studio
I SageMaker Studio, naviger til Llama-2-13b Neuron-modellen. På Distribuer fanen, kan du peke på Amazon enkel lagringstjeneste (Amazon S3) bøtte som inneholder opplærings- og valideringsdatasettene for finjustering. I tillegg kan du konfigurere distribusjonskonfigurasjon, hyperparametre og sikkerhetsinnstillinger for finjustering. Velg deretter Tog å starte opplæringsjobben på en SageMaker ML-instans.
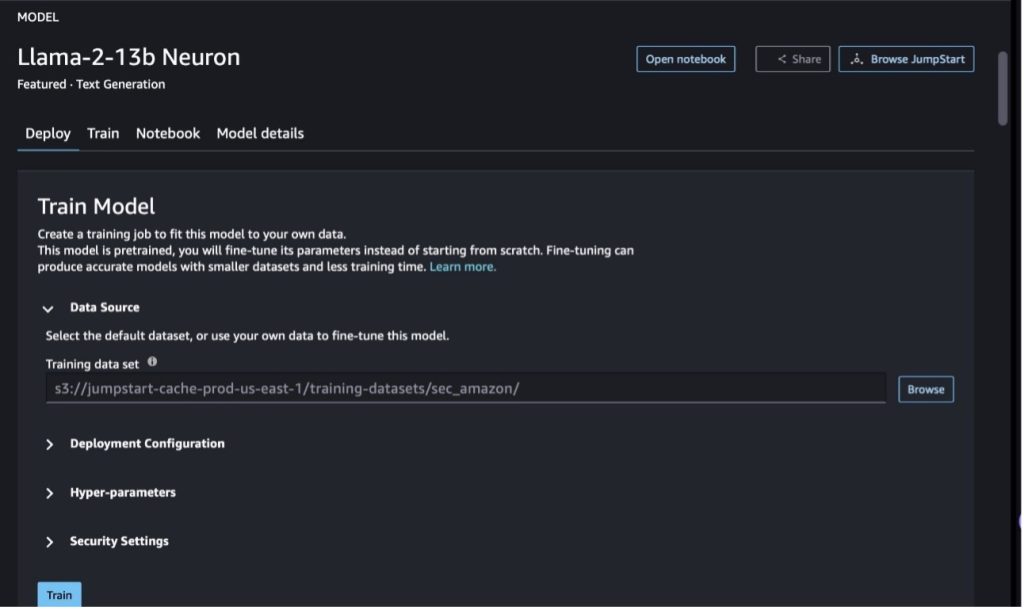
For å bruke Llama 2-modeller må du godta EULA og AUP. Det vil dukke opp når du velger Tog. Velg Jeg har lest og godtar EULA og AUP for å starte finjusteringsjobben.
Du kan se statusen til treningsjobben din for den finjusterte modellen under på SageMaker-konsollen ved å velge Treningsjobber i navigasjonsruten.
Du kan enten finjustere Llama 2 Neuron-modellen din ved å bruke dette eksemplet uten kode, eller finjustere via Python SDK, som vist i neste avsnitt.
Finjuster Llama-2-13b Neuron-modellen via SageMaker Python SDK
Du kan finjustere datasettet med domenetilpasningsformatet eller instruksjonsbasert finjustering format. Følgende er instruksjonene for hvordan treningsdataene skal formateres før de sendes til finjustering:
- Input - A
trainkatalog som inneholder enten en JSON-linjer (.jsonl) eller tekst (.txt) formatert fil.- For JSON-linjer (.jsonl)-filen er hver linje et eget JSON-objekt. Hvert JSON-objekt skal være strukturert som et nøkkelverdi-par, der nøkkelen skal være
text, og verdien er innholdet i ett treningseksempel. - Antall filer under togkatalogen skal være lik 1.
- For JSON-linjer (.jsonl)-filen er hver linje et eget JSON-objekt. Hvert JSON-objekt skal være strukturert som et nøkkelverdi-par, der nøkkelen skal være
- Produksjon – En trent modell som kan brukes for slutninger.
I dette eksemplet bruker vi en delmengde av Dolly datasett i et instruksjonsinnstillingsformat. Dolly-datasettet inneholder omtrent 15,000 2.0 instruksjonsfølgende poster for ulike kategorier, for eksempel svar på spørsmål, oppsummering og informasjonsutvinning. Den er tilgjengelig under Apache XNUMX-lisensen. Vi bruker information_extraction eksempler for finjustering.
- Last inn Dolly-datasettet og del det opp i
train(for finjustering) ogtest(for evaluering):
- Bruk en ledetekstmal for å forhåndsbehandle dataene i et instruksjonsformat for opplæringsjobben:
- Undersøk hyperparametrene og overskriv dem for ditt eget bruk:
- Finjuster modellen og start en SageMaker-treningsjobb. Finjusteringsmanusene er basert på neuronx-nemo-megatron repository, som er modifiserte versjoner av pakkene nemo og Apex som er tilpasset for bruk med Neuron- og EC2 Trn1-forekomster. De neuronx-nemo-megatron repository har 3D (data, tensor og pipeline) parallellitet slik at du kan finjustere LLM-er i skala. De støttede Trainium-forekomstene er ml.trn1.32xlarge og ml.trn1n.32xlarge.
- Til slutt, distribuer den finjusterte modellen i et SageMaker-endepunkt:
Sammenlign svar mellom de forhåndstrente og finjusterte Llama 2 Neuron-modellene
Nå som vi har tatt i bruk den forhåndstrente versjonen av Llama-2-13b-modellen og finjustert den, kan vi se noen av ytelsessammenlikningene av prompte fullføringene fra begge modellene, som vist i tabellen nedenfor. Vi tilbyr også et eksempel for å finjustere Llama 2 på et SEC-arkiveringsdatasett i .txt-format. For detaljer, se GitHub eksempel notatbok.
| Sak | Innganger | Grunnsannhet | Svar fra ikke-finjustert modell | Svar fra finjustert modell |
| 1 | Nedenfor er en instruksjon som beskriver en oppgave, sammen med et input som gir videre kontekst. Skriv et svar som utfyller forespørselen på riktig måte.nn### Instruksjon:n Trekk ut universitetene Moret studerte ved og hans uteksamineringsår for hver, og sett dem i en punktliste.nn### Input:nMoret ble født i 1953 i Vevey, Sveits , og tok sine lavere studier ved École Polytechnique Fédérale de Lausanne (EPFL), og ble uteksaminert i 1975. Han fortsatte med masterstudier ved University of Tennessee, og oppnådde en Ph.D. i 1980. Deretter begynte han på fakultetet ved University of New Mexico, hvor han ble til 2006, da han flyttet til EPFL. Han trakk seg fra EPFL i desember 2016.nnI 1996 grunnla Moret ACM Journal of Experimental Algorithmics, og han forble sjefredaktør for tidsskriftet til 2003. I 2001 grunnla Moret Workshop in Algorithms for Bioinformatics (WABI) og er fortsatt på Styringskomité for konferansen.nnI 2018 ble Moret valgt som stipendiat i International Society for Computational Biology, for sine fremragende bidrag til feltene beregningsbiologi og bioinformatikk.nn### Respons:n | * École Polytechnique Fédérale de Lausanne (EPFL) (uteksaminert 1975)n* University of Tennessee (uteksaminert 1980) | Moret studerte ved École Polytechnique Fédérale de Lausanne (EPFL) og University of Tennessee, og ble uteksaminert i henholdsvis 1975 og 1980.nn### Hint:nn- Bruk "split"-funksjonen til å dele inndataene i en liste med setninger.n- Bruk "splitt"-funksjonen for å dele hver setning i en liste med ord.n- Bruk "splitte"-funksjonen for å dele | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexico- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Nedenfor er en instruksjon som beskriver en oppgave, sammen med et input som gir ytterligere kontekst. Skriv et svar som utfyller forespørselen på riktig måte.n |
| 2 | Nedenfor er en instruksjon som beskriver en oppgave, sammen med et input som gir videre kontekst. Skriv et svar som fullfører forespørselen på riktig måte.nn### Instruksjon:nIdentifiser attributtene til Dionysos fra avsnittet. Vis resultatene i et kommadelt format.nn### Input:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnGud for vin, fruktbarhet, fester, festivaler, galskap, kaos, drukkenskap, drukkenskap, ecsta teater. Han er den to ganger fødte sønnen til Zevs og Semele, ved at Zevs rev ham fra mors liv og sydde Dionysos inn i hans eget lår og bar ham til han var klar til å bli født. I kunsten er han avbildet som enten en eldre skjeggete gud (spesielt før 430 f.Kr.) eller en feminin, langhåret ungdom (spesielt etter 430 f.Kr.). Hans attributter inkluderer thyrsus, en drikkebeger, vinranken og en eføykrone. Han er ofte i selskap med sine thiasos, en gruppe ledsagere inkludert satyrer, maenads og hans gamle lærer Silenus. Konsorten til Dionysos var Ariadne. Det ble en gang antatt at Dionysius var et senere tillegg til det greske pantheon, men oppdagelsen av Linear B-tavler bekrefter hans status som en guddom fra en tidlig periode. Bacchus var et annet navn for ham på gresk, og kom i vanlig bruk blant romerne. Hans hellige dyr inkluderer delfiner, slanger, tigre og esler.nn### Respons:n | thyrsus, et drikkebeger, vinranken, en eføykrone | Dionysos (Διόνυσος, Diónusos)nn Gud for vin, fruktbarhet, fester, festivaler, galskap, kaos, drukkenskap, vegetasjon, ekstase og teater. Han er den to ganger-fødte sønnen til Zevs og Semele, ved at Zevs rev ham fra mors liv og sydde Dionysos inn i hans eget lår | thyrsus, en drikkebeger, vinranken, en krone av ivynn Nedenfor er en instruksjon som beskriver en oppgave, sammen med et innspill som gir ytterligere kontekst. Skriv et svar som fullfører forespørselen på riktig måte.nn### Instruksjon:nHva er forskjellen mellom Parthian og Arsacid Empire?nn### Input:nThe Parthian Empire, også kjent som Arsacid Empire var et |
| 3 | Nedenfor er en instruksjon som beskriver en oppgave, sammen med et input som gir videre kontekst. Skriv et svar som utfyller forespørselen på riktig måte.nn### Instruksjon:nHvorfor inneholder hovedstaden i Usbekistan det største greske samfunnet?nn### Inndata:nGrekerne i Usbekistan teller omtrent 9,000. Samfunnet består av grekere fra Russland som ble deportert med makt fra det landet til Usbekistan på 1940-tallet, og politiske flyktninger fra Hellas. Omtrent 30,000 11,000 grekere bodde i landet før andre verdenskrig og ytterligere 40,000 1960 ankom etter den greske borgerkrigen og nederlaget til Den demokratiske hæren i Hellas. Antallet deres har sunket fra et høydepunkt på rundt 19 571 på XNUMX-tallet. Hovedårsaken er emigrasjon til Hellas etter slutten av den kalde krigen da lover tillot retur av alle etniske grekere som var blitt forvist av politiske årsaker etter den greske borgerkrigen. Det største greske samfunnet i landet er i hovedstaden Tasjkent, hvor de fleste av de greske politiske flyktningene ble flyttet av sovjetiske myndigheter. I gamle tider var den sørlige delen av landet en del av det hellenistiske seleukideriket, men de få greske samfunnene der har siden assimilert seg. Den viktigste organisasjonen som representerer etniske grekere er den greske kulturforeningen i Tasjkent. Aktivitetene til denne organisasjonen inkluderer undervisning i gresk språk (XNUMX klasser med totalt XNUMX elever, klasser for voksne) og undervisning i greske danser og musikk.nn### Respons:n | De fleste av de greske politiske flyktningene i Usbekistan ble flyttet av sovjetiske myndigheter til hovedstaden Tasjkent. | n“`nHovedstaden i Usbekistan inneholder det største greske samfunnet fordi grekerne i Usbekistan teller omtrent 9,000. Samfunnet består av grekere fra Russland som ble deportert med makt fra det landet til Usbekistan på 1940-tallet, og politiske flyktninger fra Hellas. Omtrent 30,000 11,00 grekere bodde i landet før andre verdenskrig og ytterligere XNUMX XNUMX | Hovedstaden i Usbekistan inneholder det største greske samfunnet fordi det var der de fleste av de greske politiske flyktningene ble flyttet av sovjetiske myndigheter etter å ha blitt deportert fra Hellas.nn Nedenfor er en instruksjon som beskriver en oppgave, sammen med et innspill som gir videre kontekst. Skriv et svar som fullfører forespørselen på riktig måte.nn### Instruksjon:nHva er forskjellen mellom Parthian og Arsacid Empire?nn### Input:n |
Vi kan se at svarene fra den finjusterte modellen viser en betydelig forbedring i presisjon, relevans og klarhet sammenlignet med svarene fra den forhåndstrente modellen. I noen tilfeller vil det kanskje ikke være nok å bruke den forhåndsopplærte modellen for brukssaken, så finjustering av den ved hjelp av denne teknikken vil gjøre løsningen mer personlig tilpasset datasettet ditt.
Rydd opp
Etter at du har fullført opplæringsjobben og ikke vil bruke de eksisterende ressursene lenger, slett ressursene ved å bruke følgende kode:
konklusjonen
Utrullingen og finjusteringen av Llama 2 Neuron-modeller på SageMaker viser et betydelig fremskritt når det gjelder å administrere og optimalisere generative AI-modeller i stor skala. Disse modellene, inkludert varianter som Llama-2-7b og Llama-2-13b, bruker Neuron for effektiv trening og slutning om AWS Inferentia og Trainium-baserte forekomster, og forbedrer ytelsen og skalerbarheten deres.
Muligheten til å distribuere disse modellene gjennom SageMaker JumpStart UI og Python SDK tilbyr fleksibilitet og brukervennlighet. Neuron SDK, med støtte for populære ML-rammeverk og høyytelsesfunksjoner, muliggjør effektiv håndtering av disse store modellene.
Finjustering av disse modellene på domenespesifikke data er avgjørende for å forbedre deres relevans og nøyaktighet i spesialiserte felt. Prosessen, som du kan utføre gjennom SageMaker Studio UI eller Python SDK, gir mulighet for tilpasning til spesifikke behov, noe som fører til forbedret modellytelse når det gjelder raske fullføringer og svarkvalitet.
Til sammenligning kan de forhåndstrente versjonene av disse modellene, selv om de er kraftige, gi mer generiske eller repeterende svar. Finjustering skreddersyr modellen til spesifikke kontekster, noe som resulterer i mer nøyaktige, relevante og mangfoldige svar. Denne tilpasningen er spesielt tydelig når man sammenligner svar fra forhåndstrente og finjusterte modeller, der sistnevnte viser en merkbar forbedring i kvalitet og spesifisitet av utdata. Avslutningsvis representerer utrullingen og finjusteringen av Neuron Llama 2-modeller på SageMaker et robust rammeverk for å administrere avanserte AI-modeller, og tilbyr betydelige forbedringer i ytelse og anvendelighet, spesielt når de er skreddersydd til spesifikke domener eller oppgaver.
Kom i gang i dag ved å referere til eksempel SageMaker bærbare.
For mer informasjon om distribusjon og finjustering av ferdigtrente Llama 2-modeller på GPU-baserte forekomster, se Finjuster Llama 2 for tekstgenerering på Amazon SageMaker JumpStart og Llama 2 foundation-modeller fra Meta er nå tilgjengelig i Amazon SageMaker JumpStart.
Forfatterne vil gjerne anerkjenne de tekniske bidragene til Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne og Mike James.
Om forfatterne
 Xin Huang er Senior Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker innebygde algoritmer. Han fokuserer på å utvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er innen naturlig språkbehandling, forklarbar dyp læring på tabelldata og robust analyse av ikke-parametrisk rom-tid-klynger. Han har publisert mange artikler i ACL, ICDM, KDD-konferanser og Royal Statistical Society: Series A.
Xin Huang er Senior Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker innebygde algoritmer. Han fokuserer på å utvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er innen naturlig språkbehandling, forklarbar dyp læring på tabelldata og robust analyse av ikke-parametrisk rom-tid-klynger. Han har publisert mange artikler i ACL, ICDM, KDD-konferanser og Royal Statistical Society: Series A.
 Nitin Eusebius er senior Enterprise Solutions Architect ved AWS, erfaren innen programvareteknikk, Enterprise Architecture og AI/ML. Han er dypt lidenskapelig opptatt av å utforske mulighetene til generativ AI. Han samarbeider med kunder for å hjelpe dem med å bygge godt utformede applikasjoner på AWS-plattformen, og er dedikert til å løse teknologiutfordringer og bistå med deres skyreise.
Nitin Eusebius er senior Enterprise Solutions Architect ved AWS, erfaren innen programvareteknikk, Enterprise Architecture og AI/ML. Han er dypt lidenskapelig opptatt av å utforske mulighetene til generativ AI. Han samarbeider med kunder for å hjelpe dem med å bygge godt utformede applikasjoner på AWS-plattformen, og er dedikert til å løse teknologiutfordringer og bistå med deres skyreise.
 Madhur Prashant jobber i det generative AI-rommet hos AWS. Han er lidenskapelig opptatt av skjæringspunktet mellom menneskelig tenkning og generativ AI. Hans interesser ligger i generativ AI, spesielt å bygge løsninger som er hjelpsomme og ufarlige, og mest av alt optimale for kundene. Utenom jobben elsker han å gjøre yoga, gå tur, tilbringe tid med tvillingen sin og spille gitar.
Madhur Prashant jobber i det generative AI-rommet hos AWS. Han er lidenskapelig opptatt av skjæringspunktet mellom menneskelig tenkning og generativ AI. Hans interesser ligger i generativ AI, spesielt å bygge løsninger som er hjelpsomme og ufarlige, og mest av alt optimale for kundene. Utenom jobben elsker han å gjøre yoga, gå tur, tilbringe tid med tvillingen sin og spille gitar.
 Dewan Choudhury er en programvareutviklingsingeniør med Amazon Web Services. Han jobber med Amazon SageMakers algoritmer og JumpStart-tilbud. Bortsett fra å bygge AI/ML-infrastrukturer, brenner han også for å bygge skalerbare distribuerte systemer.
Dewan Choudhury er en programvareutviklingsingeniør med Amazon Web Services. Han jobber med Amazon SageMakers algoritmer og JumpStart-tilbud. Bortsett fra å bygge AI/ML-infrastrukturer, brenner han også for å bygge skalerbare distribuerte systemer.
 Hao Zhou er en forsker med Amazon SageMaker. Før det jobbet han med å utvikle maskinlæringsmetoder for svindeldeteksjon for Amazon Fraud Detector. Han er lidenskapelig opptatt av å bruke maskinlæring, optimalisering og generative AI-teknikker på ulike problemer i den virkelige verden. Han har en doktorgrad i elektroteknikk fra Northwestern University.
Hao Zhou er en forsker med Amazon SageMaker. Før det jobbet han med å utvikle maskinlæringsmetoder for svindeldeteksjon for Amazon Fraud Detector. Han er lidenskapelig opptatt av å bruke maskinlæring, optimalisering og generative AI-teknikker på ulike problemer i den virkelige verden. Han har en doktorgrad i elektroteknikk fra Northwestern University.
 Qing Lan er en programvareutviklingsingeniør i AWS. Han har jobbet med flere utfordrende produkter i Amazon, inkludert høyytelses ML-slutningsløsninger og høyytelses loggingssystem. Qings team lanserte den første milliardparametermodellen i Amazon Advertising med svært lav ventetid. Qing har inngående kunnskap om infrastrukturoptimalisering og Deep Learning-akselerasjon.
Qing Lan er en programvareutviklingsingeniør i AWS. Han har jobbet med flere utfordrende produkter i Amazon, inkludert høyytelses ML-slutningsløsninger og høyytelses loggingssystem. Qings team lanserte den første milliardparametermodellen i Amazon Advertising med svært lav ventetid. Qing har inngående kunnskap om infrastrukturoptimalisering og Deep Learning-akselerasjon.
 Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana-Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens, og har publisert mange artikler på NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker innebygde algoritmer og hjelper til med å utvikle maskinlæringsalgoritmer. Han fikk sin doktorgrad fra University of Illinois Urbana-Champaign. Han er en aktiv forsker innen maskinlæring og statistisk inferens, og har publisert mange artikler på NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP-konferanser.
 Dr. Li Zhang er en hovedproduktsjef-teknisk for Amazon SageMaker JumpStart og Amazon SageMaker innebygde algoritmer, en tjeneste som hjelper dataforskere og maskinlæringsutøvere å komme i gang med å trene og distribuere modellene sine, og bruker forsterkende læring med Amazon SageMaker. Hans tidligere arbeid som ledende forskningsmedarbeider og mesteroppfinner ved IBM Research har vunnet test of time paper-prisen hos IEEE INFOCOM.
Dr. Li Zhang er en hovedproduktsjef-teknisk for Amazon SageMaker JumpStart og Amazon SageMaker innebygde algoritmer, en tjeneste som hjelper dataforskere og maskinlæringsutøvere å komme i gang med å trene og distribuere modellene sine, og bruker forsterkende læring med Amazon SageMaker. Hans tidligere arbeid som ledende forskningsmedarbeider og mesteroppfinner ved IBM Research har vunnet test of time paper-prisen hos IEEE INFOCOM.
 Kamran Khan, Sr Technical Business Development Manager for AWS Inferentina/Trianium hos AWS. Han har over ti års erfaring med å hjelpe kunder med å distribuere og optimalisere dyplæringstrening og slutningsarbeidsbelastninger ved å bruke AWS Inferentia og AWS Trainium.
Kamran Khan, Sr Technical Business Development Manager for AWS Inferentina/Trianium hos AWS. Han har over ti års erfaring med å hjelpe kunder med å distribuere og optimalisere dyplæringstrening og slutningsarbeidsbelastninger ved å bruke AWS Inferentia og AWS Trainium.
 Joe Senerchia er senior produktsjef i AWS. Han definerer og bygger Amazon EC2-instanser for dyp læring, kunstig intelligens og høyytelses dataarbeidsbelastninger.
Joe Senerchia er senior produktsjef i AWS. Han definerer og bygger Amazon EC2-instanser for dyp læring, kunstig intelligens og høyytelses dataarbeidsbelastninger.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

